스터디명 : 20년차 AI 엔지니어에게 배우는 AI 에이전트의 모든 것
결과공유회 발표자료 : Travel Agent : 나만의 여행 비서 만들기
GitHub : GoToLearn-AI_Agent
스터디 개요
진행방식
- 팀 구성 : 정유선 멘토님 👩🏫 + 멘티 4인
- 주기 및 진행 방식 : 매주 토요일마다 온라인 스터디 진행
- 진행 기간 : 3/15(OT) - 5/17(데브콘 밋업)
활동 내역
- AI Agent 개념 및 프레임워크 (LangGraph, CrewAI) 이해
- 각자 주도적으로 프로젝트 주제 선정 & 구현
- 개발 진행상황 및 이슈는 함께 공유
- 20년차 대선배님의 아낌없는 실무 노하우 전수 & 피드백
프로젝트 내용 및 시행착오
한줄요약 : 벗어날 수 없는 OpenAI 유니버스
늪에 빠져버렸다..
두줄요약 : 효율적인 Agent 설계와 활용의 중요성 체감
Step 0 : Crew AI
사용 시 OpenAI 키 필수 → 빠른 포기
⚠️ 한계
CrewAI는 내부적으로 LangChain을 활용하여 다양한 LLM을 호출할 수 있지만,
Crew() 객체 생성 시점에 OpenAI API 키가 무조건 설정되어 있어야만 실행된다.
즉, 실제로 OpenRouter, DeepSeek 등 다른 모델을 쓰고 있어도,
다음과 같은 코드에서 OpenAI 키가 없으면 에러가 난다!
crew = Crew(
agents=[...],
tasks=[...],
...
)이는 내부에 키 유무를 강제 체크하는 validation 로직이 있기 때문이다.
✅ 해결 방법
1. 형식만 맞는 가짜 OpenAI 키 설정 (가장 간단한 방식)
실제로 OpenAI API를 사용하지 않더라도 환경 변수에 형식만 맞는 더미 키를 설정하면 CrewAI가 통과시킨다.
export OPENAI_API_KEY="sk-fake-key-just-for-crewai"또는 Python 코드 내에서 반드시 sk- 로 시작해야 하며, 그렇지 않으면 validation에서 다시 막힌다.
import os
os.environ["OPENAI_API_KEY"] = "sk-fake-key-just-for-crewai"2. 실제 OpenAI 키를 설정하되, 사용은 하지 않기
OpenAI 키가 있긴 하지만 실제로는 다른 모델(OpenRouter 등)을 사용하고자 할 경우 키를 설정만 해두고 LLM 설정만 다르게 하면 되는데,
CrewAI는 키의 존재 여부만 확인하며, 실제로 해당 키를 사용했는지는 따지지 않기 때문!
이렇게 우회하는 방법이 있지만..
나는 상용화/온프레미스 상황까지 고려해 설계하고 싶었기 때문에
OpenAI 키가 필수인 CrewAI 는 적합하지 않은 프레임워크라고 판단했다.
(지금 생각해 보니 어차피 OpenAI 유니버스를 벗어날 수 없는 이상
더미 OpenAI 키를 설정해서 그냥 CrewAI 로 개발하는 것도 좋았을 것 같다 😂)
Step 1 : Agent 기초
Mock Data 와 선형 구조로 구현한 간단한 Agent
앞선 이유로 CrewAI 대신 LangGraph 를 사용하기로 마음먹었고,
Mock Data 를 사용해 항공편을 예약하는 아주 간단한 선형 예제를 만들어 보았다.
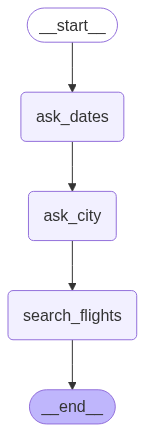
ask_dates: 여행 시작일과 종료일을 입력받아 특정 날짜 형식으로 변환ask_city: 여행할 도시를 입력받음search_flights: 입력받은 날짜와 도시에 운행하는 항공편을 탐색
⚠️ 한계
이렇게 아주 간단한 항공편 예약 Agent 를 만들었지만, 이대로 Agent 구축 프로젝트를 진행할 수는 없다고 판단한 이유는 다음과 같았다.
-
이 설계는 너무 단순한 선형 예제이므로 Agent 를 사용하는 의미가 없음
- Agent 가 아니라 LangChain 만으로도 충분히 더 간결한 코드와 구조로 구현 가능
- '복잡한 작업' 을 처리할 수 있는 Agent 의 강점을 살릴 수 없음
-
이미 항공편 예약 프로세스만으로 기획과 구현 리소스가 큼
- 항공편 예약은 단일 작업처럼 보이지만, 사실상 복수의 하위 태스크로 구성된 복합적 작업임
- 날짜 인식, 도시 인식 (NER, Parsing)
- 사용자 의도 분기 (왕복 vs 편도, 직항 선호 여부 등)
- 외부 API 호출 (예: Skyscanner, Kayak, Amadeus)
- 최종 선택지 제안 및 확인
이대로라면 항공편 예약 이외에 '여행 비서' 로서의 기능을 빠짐없이 수행하기 위해 들여야 하는 리소스가 너무 크기 때문에 스터디 기한 내에 개발하기 어려울 것 같고,
특히나 이러한 선형 설계만으로는 스터디의 목적인 'Agent' 를 충분히 활용해 보기가 어려울 것 같다!
Step 2 : Multi-Agent
Router, Fan-out 을 활용하는 Multi Agent 구현
조금 더 Agent 답게, 복잡한 작업을 수행할 수 있도록 구조를 바꿔 보았다.
Teddy 님의 LangGraph-HandsOn 코드와 설명을 참고하여 Router, Fan-out 적용했다.
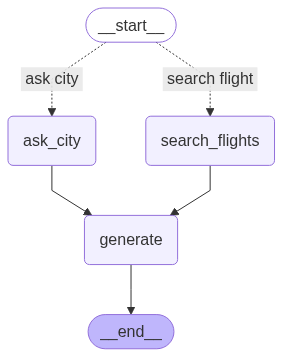
Routing
-
입력 쿼리나 상태에 따라 적절한 처리 경로나 구성 요소로 요청을 전달하는 메커니즘
-
특정 작업에 가장 적합한 모델이나 도구를 선택하고, 복잡한 워크플로우를 관리하며, 비용과 성능 균형을 최적화하는 데 필수적
-
Agent 의 경우
- 도구 선택을 하는 방식으로 라우팅
- 따라서, 도구에 대한 description 이 상세하게 작성되어야 합니다.
-
LLM.with_structured_output 의 경우
- Function Calling 을 사용하는 방식으로 라우팅
이번 설계에서는 질문 라우팅 노드를 구현하였으며,
사용자의 질문에 대해 question_router 를 호출하여 다음 2가지 중 적절한 Agent 로 라우팅한다.
ask_city: 여행할 도시 설정search_flights: 항공편 검색
적절한 Agent 를 수행한 이후에는generate에서 Agent 의 결과를 답변으로 생성한다.
Fan-Out / Fan-In
- Fan-Out
- 복잡한 LLM 워크플로우 관리를 위한 중요한 패턴
- 단일 입력을 여러 병렬 작업으로 분배하는 패턴으로, 하나의 프롬프트나 쿼리를 여러 LLM, 도구, 또는 처리 단계로 동시에 전송하여 다양한 관점이나 접근 방식을 얻을 수 있게 함
- 복잡한 문제를 더 작고 전문화된 하위 작업으로 분할하거나 동일한 작업에 대해 여러 모델의 결과를 비교할 때 유용함
- Fan-In
- Fan-out의 역과정으로, 여러 병렬 작업의 결과를 단일 출력이나 다음 단계로 통합
- 이는 다양한 모델이나 도구에서 생성된 결과를 종합하여 더 완전하고 정확한 최종 응답을 만들거나 여러 에이전트의 작업을 조정할 때 사용됨
이렇게 우선 사용자의 요청으로부터 의도(intent) 를 파악하고,
적절한 Agent 로 분기시켜(Routing) 요청을 처리할 수 있게 구현했다.
⚠️ 한계
- 순서가 보장되지 않은 복잡한 작업의 처리 불가
- 사용자가 예측 불가능한 입력을 주어도 처리할 수 있는 유연한 구조가 아님
Step 3 : Manus 클론 코딩
사용자의 요청에 유연하게 대응할 수 있는 Multi-Agent 구현
지금까지의 설계는 사용자가 예측 가능한 요청을 할 경우를 염두에 둔 것이고
그 반대의 경우라면, 심지어 구현되지 않은 Agent 가 필요한 경우까지 고려한다면?
모든 경우를 다 커버하기 위한 Agent 를 구현하고 설계에 반영할 수는 없을 테고,
좀 더 유연하게 사용자의 요청을 소화할 수 있는 방법은 없을까?
이러한 고민을 하던 중, Manus 라는 Multi-Agent 시스템을 발견했다.
아래 캡쳐는 Manus 홈페이지에서 제공하는 '4월 일본 여행' 일정을 작성해 주는 예시이다.
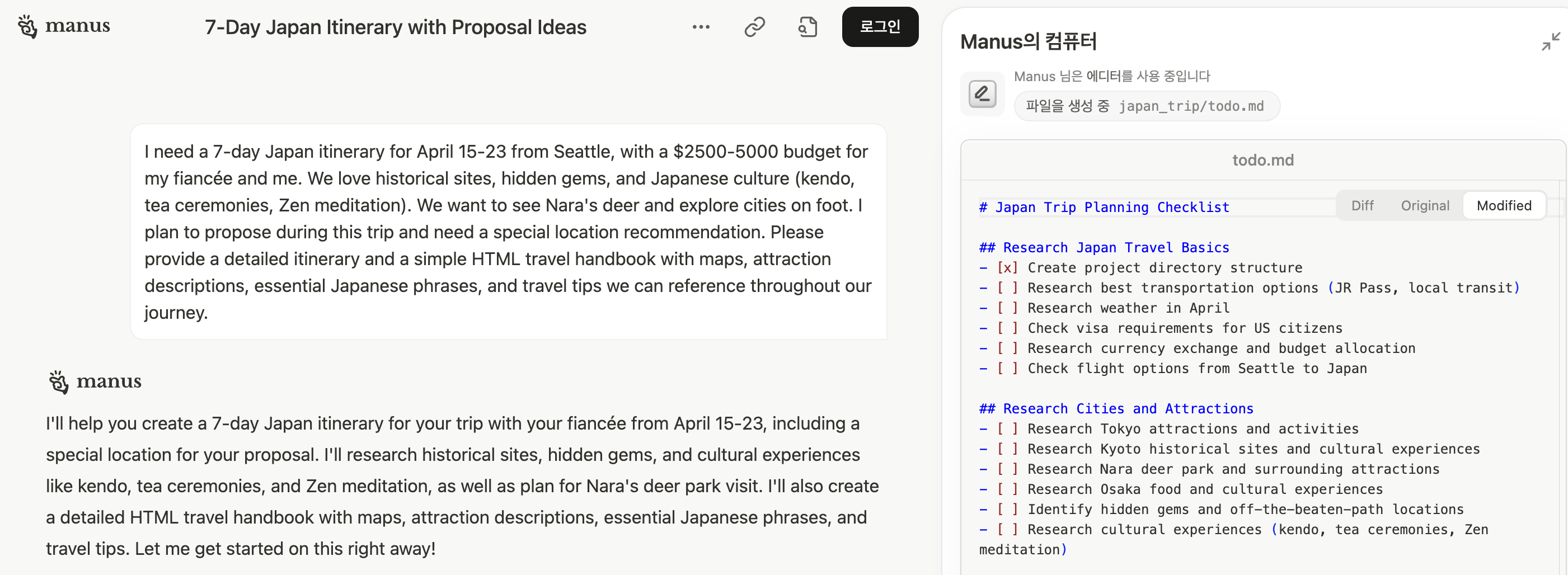
- Manus Flow 분석
- 사용자가 요구사항 입력 → LLM 이 세부 요구사항으로 분할해 task 를 작성 → 각 task 마다 Agent 가 동작하는 것으로 추정됨.
- Browser-Use 활용 (웹 브라우저를 제어하는 AI)
한 번 예제에서 확인되는 Flow 대로 동작하도록 똑같이 클론코딩을 해 보았다.
초기 설계
- 사용자의 요구사항을 리스트로 만든다.
- 각각의 리스트 항목에 대답한다. 우선 초기 모델이므로 LLM 만을 이용하여 항목에 대한 답을 작성한다.
- 작성한 답을 하나의 마크다운 파일에 작성한다.
초기 설계 노드 구성
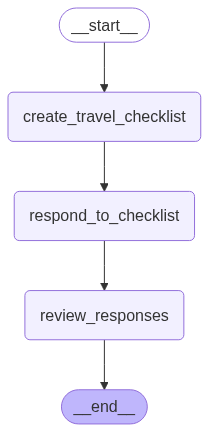
- extract_requirements
- 입력: 사용자 프롬프트
- 출력: 요구사항 리스트 항목들 (체크리스트 형태, 최대 10개)
- respond_to_checklist
- 입력: 요구사항 리스트 항목들
- 처리: 항목별로 LLM 호출하여 각 항목의 응답 생성
- 출력: 응답이 포함된 리스트
- review_responses
- 입력: 응답이 포함된 리스트
- 처리: LLM 의 답변을 마크다운 파일에 저장
- 출력: 최종 결과물
수행 시간 개선
2. respond_to_checklist 노드에서 각 체크리스트에 대한 답변을 LLM으로 작성한다.
다시 말해, 이 노드에서 최대 10회 LLM을 호출하는데, 단순히 for 문을 이용해 LLM을 호출하면 수행 시간이 너무 길어진다.
따라서 이 노드를 비동기 함수로 고쳐서 하나의 LLM이 답변할 때까지 기다리지 않도록 개선했고,
LLM 호출 방법을 배치로 전환해 3개의 체크리스트를 묶어서 LLM에 전달해 LLM의 호출 횟수를 기존 10회 ➡️ 4회로 줄였다.
import asyncio
from typing import List
async def async_respond_to_checklist_in_batches(state: TripPlanningState, batch_size: int = 3) -> TripPlanningState:
async def get_response(item):
if not item.strip():
return {"item": item, "response": ""}
return {
"item": item,
"response": (await llm.ainvoke(f"'{item}' 이 항목에 대해 자세히 조사해서 설명해 줘. 여행 전문가처럼 답변해 줘.")).content
}
checklist = state["checklist"]
all_responses = []
# 체크리스트를 배치 크기로 나누어 처리
for i in range(0, len(checklist), batch_size):
batch = checklist[i:i + batch_size]
print(f"📋 배치 {i//batch_size + 1} 처리 중... ({len(batch)}개 항목)")
# 현재 배치의 모든 항목을 병렬로 처리
batch_responses = await asyncio.gather(*[get_response(item) for item in batch])
all_responses.extend(batch_responses)
# 다음 배치 처리 전 잠시 대기 (API 레이트 리밋 방지)
if i + batch_size < len(checklist):
print(f"⏳ 다음 배치 처리를 위해 2초 대기...")
await asyncio.sleep(2)
print(f"✅ 총 {len(all_responses)}개 항목 처리 완료!")
return {
**state,
"checklist_with_responses": all_responses
}⚠️ 한계
- 체크리스트에 대한 답을 얻을 때 LLM에만 의존함
- 진정한 Agent 라면 tool 을 붙여서 웹서치 등으로 답을 가져오는 편이 더 좋지 않을까?
- 너무 많은 LLM을 호출하므로 API 비용이 많이 들고, 답변을 얻기까지의 소요 시간이 오래 걸림
- 혹은 여행지에 대한 정보 등을 미리 수집해 두고 RAG를 접목했어도 좋았을 것 같다.
- 여전히 100% 유연한 설계는 불가능
- 답변들을 작성한 후, 하나의 핸드북으로 만들기 위해 답변 취합 노드를 만드는 방법 이외에 유연한(혹은 철저한)설계로 해결할 수는 없을까?
- Manus 는 이걸 어떻게 구현했을까.. 🥲
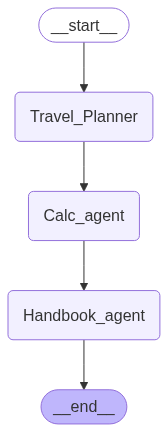
Step 4 : Tool 활용
tool 을 붙여서 정확하고 + 빠르고 + 신뢰도 높은 Agent 구축하기
지금까지 구현한 AI Agent 들의 공통적인 한계는 다음과 같다.
- 답변을 LLM에만 의존한다
- 할루시네이션, 최신 정보 반영 불가 등 이슈 발생
- 사용자의 요청에 유연하게 대응하기 위해서는 너무 설계가 복잡해진다
- 예를 들어, 사용자가 '멕시코시티의 정보와 날씨 정보를 알려 줘' 라고 요청했다면, tool 이 없는 경우 요청 전체를 LLM이 한번에 답변하거나(이 경우 실시간 정보를 참고하는 데에 한계가 있음), 사용자의 요청으로부터 의도를 파악해 각각 여행지 정보 제공 에이전트와 날씨 정보 검색 에이전트로 라우팅해야 한다.
물론 각각의 에이전트를 직접 구축해야 하므로 많은 리소스가 들고 설계가 복잡해진다!
- 예를 들어, 사용자가 '멕시코시티의 정보와 날씨 정보를 알려 줘' 라고 요청했다면, tool 이 없는 경우 요청 전체를 LLM이 한번에 답변하거나(이 경우 실시간 정보를 참고하는 데에 한계가 있음), 사용자의 요청으로부터 의도를 파악해 각각 여행지 정보 제공 에이전트와 날씨 정보 검색 에이전트로 라우팅해야 한다.
- 실시간 정보 (ex: 날씨 정보, 환율) 를 참고할 수 없다
- 물론 OpenAI 의 ChatGPT 를 사용하면 가능하지만, 사용할 LLM이 지정되어 있거나 온프레미스 환경이라면 사용 불가!
따라서 Agent 구조는 사용자에게 유용한 필수 기능만 수행하도록 간단하게 가져가되,
가능한 tool 을 최대한 많이 붙여서 유연하고 능동적인 Multi-Agent 로 개선해 보았다.
from langchain_community.tools.tavily_search import TavilySearchResults
tavily_search = TavilySearchResults(max_results=3)
# 웹 검색 도구 tavily의 이름과 설명을 설정합니다.
tavily_search.name = "tavily_search"
tavily_search.description = "Use this tool to search on the web using tavily"
...
from langchain_community.utilities import OpenWeatherMapAPIWrapper
from langchain_core.tools import Tool
weather_search = Tool(
name="weather_search",
func=OpenWeatherMapAPIWrapper().run,
description="Use this tool to search the weather of a city or country"
)우선 이렇게 tool 을 붙이고 나서, log 가 찍히도록 개선했다.
어떤 tool 이 호출되는지(사용자의 요청에 따라 호출되는 tool 이 있고 호출 안되는 tool 이 있음), 호출한 tool이 정상적으로 동작하는지 알아보기 위해 tool 호출 시 로그가 출력되도록 logging 함수로 각각의 tool 을 래핑했다.
from collections import defaultdict
import traceback
from langchain_core.tools import Tool
_call_counts = defaultdict(int)
def wrap_func_with_logging(original_func, tool_name):
def wrapped(input, *, config=None):
_call_counts[tool_name] += 1
call_id = _call_counts[tool_name]
print(f"[🛠️ {tool_name}] Call #{call_id} - Called with input: {repr(input)}")
try:
result = original_func(input)
# 결과에 에러가 포함되어 있는지 확인
result_str = str(result)
if result and not any(error_keyword in result_str for error_keyword in ['HTTPError', 'Error:', 'error:', 'Exception', 'Failed']):
print(f"[✅ {tool_name}] Call #{call_id} - Success. Result: {result_str[:300]}")
elif result:
print(f"[❌ {tool_name}] Call #{call_id} - API Error in result: {result_str[:300]}")
else:
print(f"[⚠️ {tool_name}] Call #{call_id} - No result returned.")
return result
except Exception as e:
print(f"[❌ {tool_name}] Call #{call_id} - Error: {e}")
print(traceback.format_exc())
raise
return wrapped
def logging_tool(func, name, description):
if callable(func) and not hasattr(func, "invoke"):
# 순수 함수형 도구
func = wrap_func_with_logging(func, name)
return Tool(name=name, func=func, description=description)
elif hasattr(func, "invoke"):
# LangChain-style Tool → 직접 감싸지 말고 아예 래핑된 Tool을 새로 정의
class WrappedTool(func.__class__):
def invoke(self, input, config=None):
_call_counts[name] += 1
call_id = _call_counts[name]
print(f"[🛠️ {name}] Call #{call_id} - Called with input: {repr(input)}")
try:
result = super().invoke(input, config=config)
# 결과에 에러가 포함되어 있는지 확인
result_str = str(result)
if result and not any(error_keyword in result_str for error_keyword in ['HTTPError', 'Error:', 'error:', 'Exception', 'Failed']):
print(f"[✅ {name}] Call #{call_id} - Success. Result: {result_str[:300]}")
elif result:
print(f"[❌ {name}] Call #{call_id} - API Error in result: {result_str[:300]}")
else:
print(f"[⚠️ {name}] Call #{call_id} - No result returned.")
return result
except Exception as e:
print(f"[❌ {name}] Call #{call_id} - Error: {e}")
print(traceback.format_exc())
raise
return WrappedTool(name=name, description=description)
else:
raise ValueError("func must be a callable or have an .invoke() method")
tool 정의에 logging 함수 래핑
from langchain_community.tools.tavily_search import TavilySearchResults
# 원래 tavily tool 정의는 다음 3줄이면 가능하지만
# tavily_search = TavilySearchResults(max_results=3)
# # 웹 검색 도구 tavily의 이름과 설명을 설정합니다.
# tavily_search.name = "tavily_search"
# tavily_search.description = "Use this tool to search on the web using tavily"
# 로그를 찍기 위해 logging_tool 함수로 래핑
tavily_search = logging_tool(
name="tavily_search",
func=TavilySearchResults(max_results=3),
description="Search with Tavily"
)
...
from langchain_community.tools import WikipediaQueryRun
from langchain_community.utilities import WikipediaAPIWrapper
wikipedia_search = logging_tool(
name="wikipedia_search",
func=WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper()).run,
description="Use this tool to search on the wikipedia"
)이제 어느 툴이 호출되어 정상적으로 실행되었는지 로그를 확인할 수 있다.
[🛠️ tavily_search] Call #1 - Called with input: {'name': 'tavily_search', 'args': {'query': 'cultural sites in Paris'}, 'id': 'call_tS6lSMPtFTYXpIdmtYzKUlZ3', 'type': 'tool_call'}
[🛠️ tavily_search] Call #2 - Called with input: {'name': 'tavily_search', 'args': {'query': 'architectural sites in Paris and nearby'}, 'id': 'call_oRFI5tzOqloH7Zwr4Bnimnkb', 'type': 'tool_call'}
[🛠️ tavily_search] Call #3 - Called with input: {'name': 'tavily_search', 'args': {'query': 'artistic sites in Paris'}, 'id': 'call_wZIAc2J9dATUd7Mrj8W8ztZB', 'type': 'tool_call'}
[❌ tavily_search] Call #2 - API Error in result: content="HTTPError('502 Server Error: Bad Gateway for url: https://api.tavily.com/search')" name='tavily_search' tool_call_id='call_oRFI5tzOqloH7Zwr4Bnimnkb' artifact={}
[❌ tavily_search] Call #3 - API Error in result: content="HTTPError('502 Server Error: Bad Gateway for url: https://api.tavily.com/search')" name='tavily_search' tool_call_id='call_wZIAc2J9dATUd7Mrj8W8ztZB' artifact={}
[✅ tavily_search] Call #1 - Success. Result: content='[{"title": "Places in Paris where you can explore world cultures", "url": "https://parisjetaime.com/eng/article/places-in-paris-where-you-can-explore-world-cultures-a723", "content": "Institutes, cultural centres and gardens · Musée du quai Branly - Jacques Chirac · Musée du Louvre · Philha
[✅ weather_search] Call #1 - Success. Result: In Paris, France, the current weather is as follows:
Detailed status: clear sky
Wind speed: 1.54 m/s, direction: 350°
Humidity: 85%
Temperature:
- Current: 12.35°C
- High: 13.28°C
- Low: 10.77°C
- Feels like: 11.86°C
Rain: {}
Heat index: None
Cloud cover: 0%⚠️ 한계
- LangGraph 에서 제공하는 tool 을 사용하려면 여전히 OpenAI key 가 필요하다!
- 온프레미스 환경에서는 여전히 사용 불가
- 벗어날 수 없는 OpenAI 생태계.. 🤿
- LangGraph 에서 제공하는 tool 의 종류와 기능에 한계가 있다
- 항공편 검색, 호텔 예약 tool 도 있었다면 편했을 텐데!
- 이래서 요즘 MCP가 핫하구나..! 직접 tool 을 만들어서 붙일 수 있으니까!
결과공유회 : 스터디 후기 발표
스터디를 모두 마치고 '데브콘 서울: 오월엔 만남 밋업' 행사에서 간단하게 내가 만든 여행 비서 에이전트에 대해 발표했다.
(스터디 일시/장소 : 5월17일(토) / 모두의 연구소 역삼점)
회고
피할 수 없는 할루시네이션
프로젝트를 진행하는 내내 도저히 할루시네이션을 피할 수가 없었다.
내가 시도했거나 참고한 할루시네이션 완화 방안은 다음과 같다.
-
프롬프트 개선
시스템 프롬프트를 좀 더 디테일하게 작성했더니 할루시네이션이 완화되었다.
하지만 프롬프트에서 고려하지 않은 사용자의 요청이 들어오면 여전히 할루시네이션이 발생할 가능성이 존재한다. -
RAG
결정적으로 다른 팀원들은 각자의 프로젝트에서 할루시네이션이 큰 이슈가 되지 않았는데,
그 이유는 각자 데이터 크롤링부터 시작해 최종적으로 RAG를 사용했기 때문이었다.
다만, 개발 단계에서 데이터 크롤링에 많은 시간과 노력을 투자한 팀원은 이런저런 이슈로 크롤링이 수월하지 않아 병목 현상을 겪었고
RAG를 안 한 나는 할루시네이션에 고통받았으니 Trade-off 인 셈인가.. 😇
기존 LLM 서비스와의 차별화 고려
이번 프로젝트에서 가장 중요하게 생각한 건 ‘상용화 가능성’이었다.
그래서 최대한 온프레미스 환경에서 동작할 수 있도록 구현해보려 했고 (결과적으로는 실패했지만…)
여기서 말하는 상용화란, 결국 사용자가 기꺼이 이 ‘여행 비서’를 실제로 사용하게 된다는 뜻이고,
그렇다면 당연히 ChatGPT보다 더 나은 무언가, 또는 차별화되는 요소가 있어야 한다고 생각했다.
예를 들면, ChatGPT보다 정보가 더 정확하다든지, 사용성이 더 좋다든지 하는 부분.
(어차피 ChatGPT도 웬만한 여행 비서 역할은 충분히 해내는데,
내가 만든 이 여행 비서를 굳이 써야 할 이유가 없다면, 그걸 누가 쓰겠는가?)
그렇기 때문에 여행 비서를 개발하면서 계속해서 ChatGPT 와 성능과 사용성을 비교했는데
ChatGPT 의 고질적인 문제는 역시 할루시네이션이었고,
할루시네이션은 아니지만 정확히 내 취향(성향) 을 고려해 딱 맞는 여행지를 추천해 주는 센스는 아직 50% 부족했으며
ChatGPT 가 여행 일정을 짜 주어도 결국 그 일정을 내 캘린더에 추가하고, 다시 한 번 제공된 여행 정보를 확인해야 하는 등 손이 가는 것은 마찬가지였다.
이러한 점들을 고려할 때, ChatGPT 즉 기존 LLM 서비스와 차별화하는 방안에 대해 고민한 내용은 다음과 같다.
(실제로 구현한 것은 아니고, 만약 프로젝트를 더 발전시킨다면 이렇게 개선할 것 같다.)
-
웹 검색 개선
나는 Tavily 와 Serper tool 을 이용해 웹 검색을 구현했으나,
만약 Browser-use 처럼 좀더 강력한 웹 검색 라이브러리를 사용했다면 더욱 정확한 정보를 검색해 올 수 있었을 테고,
이는 더 적은 할루시네이션을 일으켜 정확한 여행 정보를 제공하는 동시에
다량의 검색 결과를 이용해 여행 정보를 풍부하게 제공할 수 있었을 것 같다. -
개인 맞춤형 확장 툴 추가
적어도 ChatGPT 보다는 뭔가 유용한 점이 있어야 사용자들이 ChatGPT 대신 내 여행 비서를 사용할 것 같다.
다시 말해 기업이 서비스할 가치가 있는 에이전트를 개발해야 할 텐데,
아직 나는 현업에서 Agent 가 어떻게 쓰이는지 본 적이 없어서 아이디어가 떠오르지 않았다.
이에 대해 멘토님께서는 구글 캘린더와 같이 사용자의 개인정보에 접근할 수 있는 개인 맞춤형 확장 툴을 추가해 보라는 피드백을 주셨다. -
MCP(Model Context Protocol) 를 붙여서 Agent 기능 확장
나는 LangGraph 에서 이미 만들어서 제공하는 tool 만을 사용했고, 이 때문에 사용할 수 있는 tool 의 기능과 종류에 한계가 있었다.
만약 MCP 로 직접 tool 을 개발하고 Agent 에 붙인다면 더 다양한 기능을 사용할 수 있을 테고,
ChatGPT 보다 더욱 유용한 AI 여행 비서를 만들 수 있지 않았을까? -
도메인 특화 LLM 학습
특히 답변을 LLM에 의존하는 경우에 할루시네이션이 발생하는 점을 해결하고 싶었는데
이에 대해 멘토님께서 여행 데이터로 LLM을 파인튜닝하는 방법을 고려해 보라는 피드백을 주셨다.
만약 멘토님의 조언대로 도메인에 특화된 LLM을 학습해 사용한다면 답변의 정확도가 향상됨은 물론 더 매끄러운 답변이 생성되지 않을까?
성능 평가
RAG의 경우 RAGAS 를 이용해 지표를 계산하는 방법으로 성능 평가를 하고,
LLM을 이용해 성능 평가를 하는 경우도 있다.
그렇다면, AI Agent 는 어떻게 성능을 평가할까?
ChatGPT 에 냅다 물어보니 이렇게 알려줬다.

Agent 평가 방식은 다음 지표들이 있고
- 🎯 Task Success Rate (TSR) – 목표 달성률
- ⏱️ Efficiency Metrics (시간, step 수)
- 🔄 Action Accuracy (행동 정확성)
- 🧠 Planning Quality (계획 품질)
- 🤝 Collaboration Score (멀티에이전트일 때)
결론!

다음에 Agent 개발 프로젝트를 한다면 성능 평가도 꼭 해서 완성도를 높이고 싶다.
AI 여행 비서의 가치
여행 비서 말고 좀 더 비즈니스에 특화된 주제를 잡았더라면 더 좋은 경험이었을 것 같다.
나를 포함해 보통의 여행자들은 AI 여행 비서가 꼭 필요할까?
혹은 기업의 입장에서 생각할 때 상품화할 가치가 있는 아이템일까?
이 생각을 하며 기술블로그에 예전에 쓴 글을 뒤져보니 이미 답이 있었다!
DEVOCEAN OpenLab - Tech Day 후기
하림님(발표자)께서는 여행 스타트업의 팀장님이신 만큼 여행 도메인에 대한 시야가 넓고
그만큼 Agent 설계와 향후 상품화까지 구체적으로 고려하신 점이 인상깊었습니다.
1. 여행 준비, 왜 어려울까?
- 제한된 자원 내에서 완벽한 여행 계획 짜기가 어려움
- 변화하는 정보 형태 (정보 탐색 채널)
2. 여행 준비, Agent 로 해결해 보자
- Agent : 주변 환경을 인지하고 상호 작용하며, 목표를 달성하기 위해 자율적으로 행동하는 시스템
3. Travel Go, TGO
- TGO 팀장 Agent
- 사용자의 질의를 받아 적합한 Agent 에 역할 위임 (작업 할당)
- 장소 추천 Agent
- 질문 답변 Agent
- 일정표 생성 Agent
4. TGO 상품화
- 상품화 범위는 무궁무진!
- 광고 플랫폼 / 에이전트 구독료 / OTA&여행사 / 원클릭 결제 시스템 구축 등등이 후기대로 여행 비서 에이전트의 목표와 가치를 명확하게 잡고 Agent 를 설계했더라면 시행착오를 덜 겪었을텐데! 😂
충분한 시행착오를 겪으며 Multi-Agent 개발 요령이 생겼다!
효율적인 설계, 사용성, 수행 시간 등등 많은 고민을 하며 거의 매주 개발한 코드를 갈아엎고 새로 개발했다.
계속 갈아엎는 바람에 그동안 들인 시간과 노력에 비해 결과물이 조금 미약한데
그 대신 Multi-Agent 개발 과정에서 겪을 수 있는 이슈는 직접 다 겪었다.
이렇게 온몸으로 부딪치고 예상치 못한 이슈에 대해 고민하고 해결하며 나름대로의 노하우가 생긴 덕분에
최근에 Multi-Agent 를 활용하는 논문 1편을 단 3일만에 구현했다.
해당 논문의 리뷰와 코드는 곧 정리해서 이 블로그와 깃헙에 공개할 예정이다.
Future Work
개선하고 싶은 점은 많지만, 다음 한계 때문에 제일 먼저 MCP 추가를 해보고 싶다.
-
기능 구현의 한계
'Step 4 : Tool 활용' 에서 언급했듯이 나는 LangGraph 에서 이미 만들어서 제공하는 tool 만을 사용했고,
이 때문에 사용할 수 있는 tool 은 대부분 웹, 날씨, 위키피디아 등등 각종 검색 tool 이었기 때문에 기능 구현에 한계가 있었다. -
비용의 한계
게다가 이렇게 제공되는 tool 을 사용하기 위해서는 OpenAI key 가 필요했다.
온프레미스 환경에서 사용할 수도 없거니와, 만약 사용할 수 있는 환경이라 하더라도 tool 의 종류가 늘어나고 더 많이 사용할수록 서비스 비용이 급증할 것이다.
이러한 이슈를 직접 겪고 나니 왜 MCP가 Agent 에 꼭 필요한 기술인지 알 수 있었다.
최근 인프런의 LangGraph 강의를 제공받을 기회가 있었고, MCP 를 구현하는 강의 회차부터 먼저 수강했다.
이제 강의에서 배운 점을 토대로 직접 MCP 를 구현하는 일만 남았다! 🤓
Archive
우리 팀 후기
멘토님 후기 : AI agent 프로젝트
팀원 후기 :
고투런 2기 | AI agent 프로젝트 멘토링 기록
[AI agent 프로젝트] AI취업 도우미 구축
GoToLearn 2기 활동 후기 (운영진 작성)
[Review] 고투런 2기 온라인 OT 후기
[Review] Go To Learn 2기 1주차 활동 후기
[Review] Go To Learn 2기 2주차 활동 후기
[Review] Go To Learn 2기 3주차 활동 후기
[Review] Go To Learn 2기 4주차 활동 후기
[Review] Go To Learn 2기 마지막 주차 활동 후기
[Review] 2025-05-17 <데브콘 서울 : 오월엔 만남> 후기
[Review] 고투런 2기 운영 후기
