
본 포스팅은 SK Devocean 오프라인 스터디 (5/8) 를 앞두고 작성했습니다.
파인튜닝 도구 XTuner를 이용한 Llama3 파인튜닝 전 단계로
우선 LLaMA-3 기반 모델 'LLaVA' 테스트를 수행했습니다.
궁극적인 목적은 llama3 기반모델로 한국어 파인튜닝 모델을 만들어 보는 것입니다.
- 월별 목표
- 5월(예측까지 돌리는 코드 개념 이해)
- 6월(필요한 데이터로 목적 달성)
- 7월(개별 내용 중 발표 과제 선정 및 특이사항 해결)
LLaVA : Large Language-and-Vision Assistant (Multimodal LLM)
LLaVA 소개
LLaVA 는 이미지와 텍스트를 입력으로 받는 멀티모달 대규모 언어 모델
LM에 Visual Encoder를 추가하고 파인튜닝하는 Visual Instruction Tuning 기법으로
LLM을 VLM(Vision-Language Model)으로 바꾸는 방법을 제시하였습니다.
Architecture (논문 발췌)
[Paper] Visual Instruction Tuning
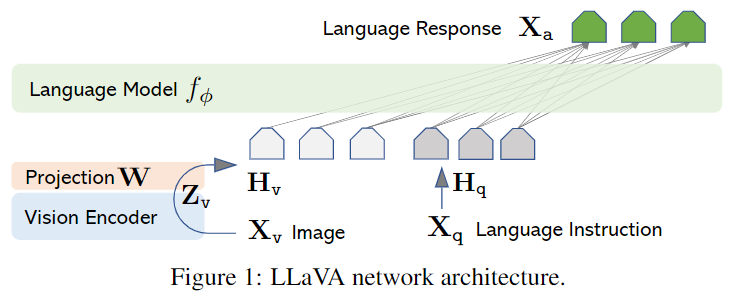
LLaVA의 주요 특징
멀티모달 학습 능력
LLaVA 모델은 이미지와 텍스트를 동시에 처리할 수 있는 멀티모달 학습 능력을 가지고 있습니다. 이를 통해, 시각적 컨텍스트가 포함된 자연어 처리 태스크를 더 효과적으로 수행할 수 있습니다.
유연한 아키텍처
LLaVA 모델은 다양한 사전 훈련 및 미세 조정 전략을 지원하여, 특정 응용 프로그램의 요구사항에 맞게 모델을 맞춤 설정할 수 있습니다. 예를 들어, LLaVA 모델은 Full LLM과 LoRA ViT와 같은 특정 전략을 사용하여 미세 조정을 수행할 수 있습니다.
고성능 및 최적화
LLaVA 모델은 고성능 컴퓨팅 환경에서 효율적으로 운영될 수 있도록 설계되었습니다. CLIP과 같은 비주얼 인코더와 함께 사용되며, 이는 모델이 높은 정확도와 빠른 추론 속도를 제공할 수 있게 합니다.
XTuner : LLM 파인튜닝 도구

XTuner 소개
XTuner는 Gemma 2, Mixtral 8x7B 2, Llama2 2를 비롯하여 InterLM2 1나 Qwen 1 등과 같은 다양한 LLM들을 지원합니다. 파인튜닝 방식 또한 전체 파인튜닝 외에도 LoRA 3/QLoRA 2과 같은 매개변수 효율적인 파인튜닝(PEFT, Parameter Efficient FineTuning) 기법들을 지원하며, 다양한 데이터셋과 파이프라인을 지원하는 도구입니다. XTuner의 주요 기능들은 다음과 같습니다:
XTuner의 주요 특징
🔥 Supports
| Models | SFT Datasets | Data Pipelines | Algorithms |
다양한 모델 지원
XTuner는 InternLM, Llama, Baichuan, Qwen, ChatGLM 등 다양한 대규모 언어 모델(Large Language Models, LLM)과 비주얼 언어 모델(Vision-Language Models, VLM)을 지원합니다. 이는 사용자가 필요에 따라 선택할 수 있는 폭넓은 옵션을 제공하며, 특정 프로젝트 요구에 맞게 모델을 선택할 수 있게 합니다.
고성능 연산 지원
XTuner는 FlashAttention과 Triton과 같은 고성능 연산자를 자동으로 사용하여 모델 훈련의 효율을 극대화합니다. 이 기능은 특히 대규모 데이터셋을 처리할 때 시간과 자원을 절약하면서도 높은 처리량을 달성할 수 있게 도와줍니다.
DeepSpeed 통합
DeepSpeed 1:rocket:와의 통합을 통해, XTuner는 다양한 최적화 기술을 쉽게 활용할 수 있습니다. ZeRO 최적화 기법을 포함한 DeepSpeed의 기능은 메모리 사용량을 줄이면서도 모델 성능은 유지하게 해줍니다. 이를 통해 더 큰 모델을 더 적은 자원으로 효과적으로 학습시킬 수 있습니다.
Data Pipelines (유연한 데이터 파이프라인)
XTuner는 다양한 형식의 데이터셋을 지원하는 잘 설계된 데이터 파이프라인을 제공합니다. 이 기능은 사용자가 오픈 소스 또는 맞춤형 데이터 형식을 자유롭게 사용할 수 있도록 하여, 더욱 유연한 데이터 처리가 가능하게 합니다.
- Incremental Pre-training
- Single-turn Conversation SFT
- Multi-turn Conversation SFT 3
다양한 미세 조정 전략
XTuner는 QLoRA, LoRA, 전체 매개변수 미세 조정(full-parameter fine-tune)과 같은 여러 가지 미세 조정 알고리즘을 지원합니다. 이를 통해 사용자는 프로젝트의 특성에 맞게 가장 적합한 미세 조정 전략을 선택할 수 있습니다.
Code
하드웨어 환경으로 Google Colab Pro+ 의 A100 GPU 를 사용했습니다.
필요 라이브러리 설치
먼저 필요한 라이브러리와 환경을 설정합니다. Python 환경에서 작업을 진행하며, 다음과 같은 명령어를 사용하여 필요한 패키지를 설치할 수 있습니다:
pip install 'lmdeploy>=0.4.0'
pip install git+https://github.com/haotian-liu/LLaVA.git모델 불러와서 사용하기
모델을 로드하고 초기 설정을 구성하는 과정은 다음과 같습니다.
이 예에서는 lmdeploy 라이브러리를 사용하여 채팅 기능을 구현하는 방법을 보여줍니다:
from lmdeploy import pipeline, ChatTemplateConfig
from lmdeploy.vl import load_image
# 모델과 채팅 템플릿을 설정
## LLaVA-Llama-3-8B-v1.1 모델 로드
## 멀티모달 입력을 처리할 수 있도록 설정
## pipe 객체는 이미지와 관련된 질문을 모델에 전달하여 모델이 주어진 이미지를 설명하게 합니다.
pipe = pipeline('xtuner/llava-llama-3-8b-v1_1-hf',
chat_template_config=ChatTemplateConfig(model_name='llama3'))
# 이미지 로드
image = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/tests/data/tiger.jpeg')
# 이미지 설명 요청
response = pipe(('describe this image', image))
print(response)결과

"In the image, a majestic tiger, adorned with a coat of black and orange stripes, is captured in a moment of tranquility. The tiger is lying on its side, its body stretched out on a carpet of lush green grass. Its head is comfortably resting on its front paws, embodying the essence of relaxation. The tiger's gaze is directed straight at the camera, creating an intense connection with the viewer. The background is a blurred landscape of green grass and trees, providing a natural backdrop to this serene scene. The image does not contain any discernible text. The relative position of the tiger to the background suggests it is the main subject of the image. The tiger's position on the grass and its direct gaze give the impression of it being aware of the camera's presence. The image captures a single moment in time, frozen in the midst of nature's beauty."
(원본 response (lmdeploy.messages.Response))
Response(text="In the image, a majestic tiger, adorned with a coat of black and orange stripes, is captured in a moment of tranquility. The tiger is lying on its side, its body stretched out on a carpet of lush green grass. Its head is comfortably resting on its front paws, embodying the essence of relaxation. The tiger's gaze is directed straight at the camera, creating an intense connection with the viewer. The background is a blurred landscape of green grass and trees, providing a natural backdrop to this serene scene. The image does not contain any discernible text. The relative position of the tiger to the background suggests it is the main subject of the image. The tiger's position on the grass and its direct gaze give the impression of it being aware of the camera's presence. The image captures a single moment in time, frozen in the midst of nature's beauty.", generate_token_len=177, input_token_len=590, session_id=0, finish_reason='stop', token_ids=[644, 279, 2217, 11, ...], logprobs=None)Reference
https://discuss.pytorch.kr/t/llm-xtuner-llama-3-llava/4194
https://huggingface.co/beomi/Llama-3-Open-Ko-8B
https://huggingface.co/xtuner/llava-llama-3-8b-v1_1
https://velog.io/@tm011899/LLaVA-%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0Visual-Instruction-Tuning
https://cocoa-t.tistory.com/entry/%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0-LLaVA-Large-Language-and-Vision-Assistant-Visual-Instruction-Tuning
