OpenLLM스터디
1.[OpenLLM스터디] LLM 파인튜닝 도구 XTuner, Llama-3 기반 LLaVA 모델 공개

궁긍적인 목적은 llama3 기반모델로 한국어 파인튜닝 모델을 만들어 보는 겁니다. LLaVA : Large Language-and-Vision Assistant (Multimodal LLM) 이미지와 텍스트를 입력으로 받는 멀티모달 대규모 언어 모델 LM에 Visu
2.Steamlit 예제
Streamlit is an open-source Python framework for data scientists and AI/ML engineers to deliver dynamic data apps with only a few lines of code(개인적인)
3.LLaMA3를 이용한 문장 요약 실습 (HuggingFace 🤗)

Code 라이브러리 설치 HuggingFace Token 설정 토크나이저 및 모델 설정 템플릿 설정 및 모델 변수 설정 현재 하드웨어 체크 텍스트 요약 요약할 원본 텍스트 배경: 현재 대변검경검사에서는 적절한 정도관리물질이 없어 질관리가 미진한 실정이다. 본
4.🦙 Linux 로컬에서 Ollama 설치 및 테스트
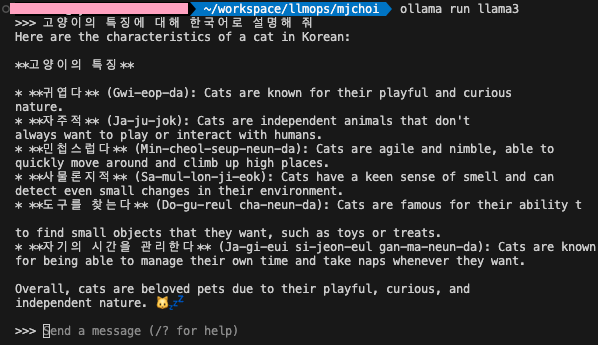
Get up and running with large language models locally.오픈소스 LLM 모델을 local에서 띄워서 구동하는 가장 손쉬운 방법windows, macos에서도 구동되기 때문에 너무나 간단하게 llama3, gemma, phi-3,
5.🦜🔗 LangChain 과 ChatGPT로 텍스트 파일 RAG 구현하기
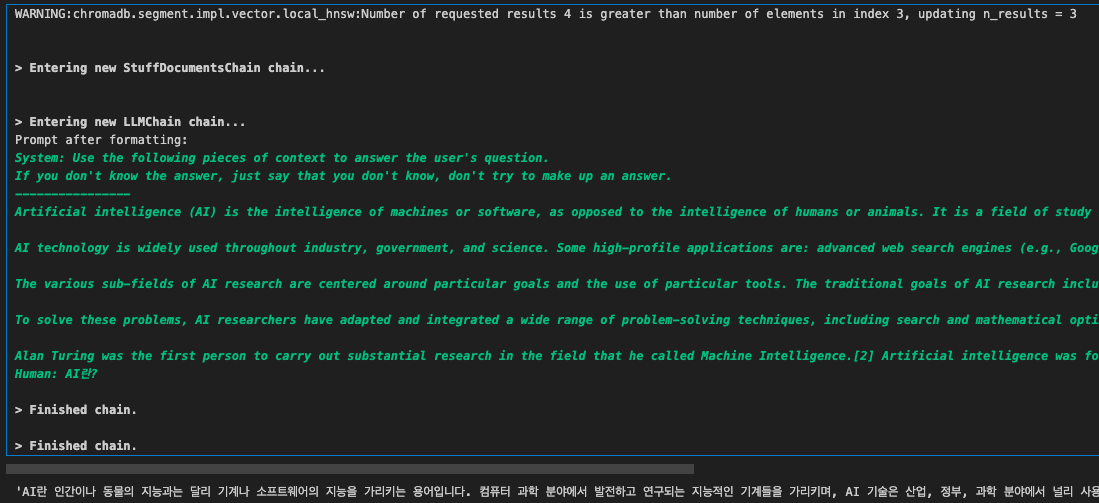
🦜🔗LangChain? = 검색 + 프롬프트 + 임베딩/저장 + 유사도 검색 + 랭킹 LLM과 외부 도구를 마치 사슬(체인)처럼 엮어 결합시켜 주는 프레임워크 LangChain 모듈 모델 I/O LLM에 전달될 프롬프트 생성 (PromptTemplate)
6.LLaMA3 - Korquard Fine-Tuning
AutoTrain Advancedhttps://github.com/huggingface/autotrain-advancedPyTorch 업데이트HuggingFace Access Token 설정KorQuAD v1.0 데이터 다운로드(dev)dev 데이터 불러오기K
7.LLaMA3 을 이용한 RAG 구축 + Ollama 사용법 정리
Llama3-KO 를 이용해 RAG 를 구현해 보겠습니다.RAG 에 사용할 PDF로 근로기준법을 다운로드하여 사용했습니다.https://www.law.go.kr/법령/근로기준법필요한 라이브러리 임포트Text(PDF) LoaderTextSplitterText V
8.LLaMA3 - 자영업 QA 챗봇 Fine-Tuning
환경 : Google colab pro+ A100파인튜닝을 하기 위한 기본 LLM 모델 및 데이터셋 설정데이터셋의 상위 200개만 추출너무 많은 데이터셋을 파인튜닝할 경우 CUDA Out of Memory하지만 데이터셋 200개는 너무 적은 것 아닐까? 🤔CUDA 메
9.[LLMOps] RunPod 사용법 정리 (2024ver, vscode 연동)
좌측 메뉴바의 MANAGE - Pods 를 클릭하면 구매 가능한 GPU 목록을 보여줍니다.저는 NVIDIA 의 A100 SXM 을 선택했습니다.gpu 선택파이토치를 이용하여 개발할 것이라면 Pod Template 중 Pytorch 를 선택합니다.pytorch 선택맨 하
10.DEVOCEAN OpenLab - Tech Day 후기
지난 4월, 운 좋게 데보션 OpenLab 스터디에 2개나 합격했습니다!LLM을 공부하고자 지원한 LLMOps 팀과 OpenLLM 팀에 합격하게 되었고,저 나름대로 최선을 다한 끝에 7월에 스터디를 완주할 수 있었습니다.그리고 이 스터디 결과 발표회인 Tech Day