음성인식의 분야 중 'Speaker Recognition(화자 인식)' 과 'Speaker Diarization(화자 분할)' 에 대해 소개합니다.
Speaker Recognition (화자 인식)
입력받은 음성 데이터를 미리 저장된 데이터베이스와 비교하여 화자가 누구인지 식별하는 기술입니다.
-
Speaker Identification (화자 식별)
- 등록된 여러개의 목소리를 비교하여 화자 식별
-
Speaker Verification (화자 검증)
-
입력되는 목소리와의 일치 여부를 Pass/Fail 방식으로 판별
-
화자 검증 예시
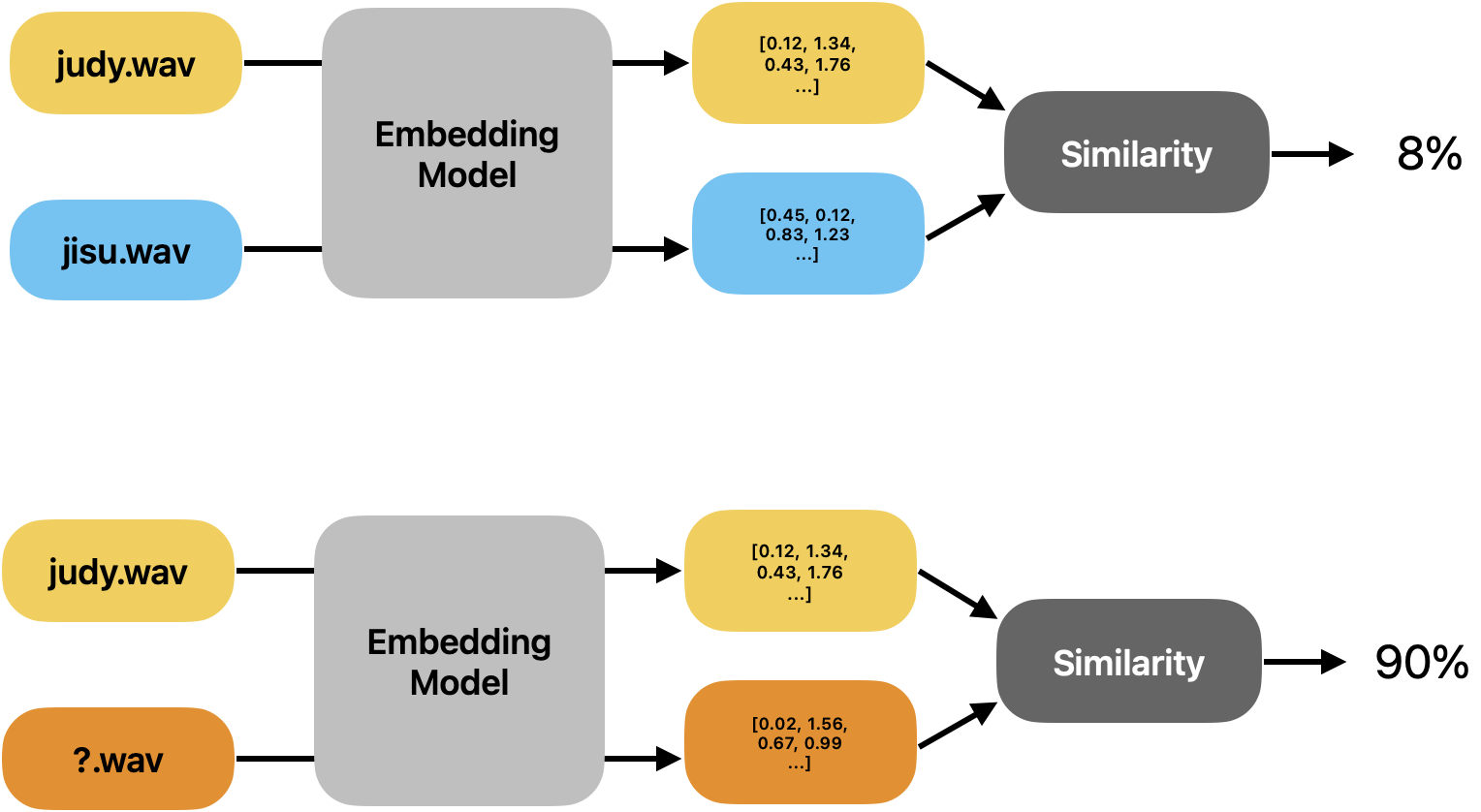
-
화자의 발화(음성) 을 임베딩으로 변환한 뒤, cosine similarity 등을 이용하여 유사도를 구합니다.
이 유사도가 threshold 보다 높으면 동일인으로, 낮으면 서로 다른 사람으로 간주합니다.
화자 인식 모델 (Embedding Model)
음성 데이터 임베딩 모델로 ResNet 기반 모델을 주로 사용합니다.
- ResNet base (ex : ResNet-34)
- SincNet
- x-vector
- ECAPA-TDNN
…
화자 인식 평가
-
EER (Equal Error Rate)
-
오인식률(FAR, False Acceptance Rate)과 오거부율(FRR, False Rejection Rate)이 같아지는 비율
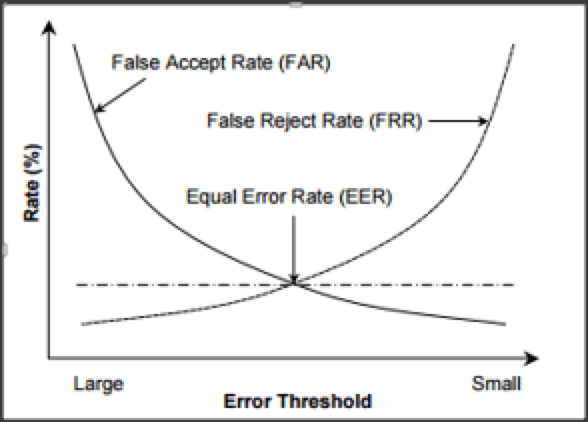
-
오인식률(FAR:False acceptance rate): 본인의 것이 아닌 생체인식 정보를 본인의 것으로 잘못 판단할 확률을 의미한다.
-
오거부률(FRR:False Rejection Rate): 본인의 생체정보를 본인이 아닌 것으로 잘못 판단할 확률을 말한다.
-
-
minDCF (minimum Detection Cost Function)
- 미국 국립표준기술연구소(NIST, National Institute of Standards Technology)에서 주관하는 화자인식 대회에서 사용하는 평가 지표
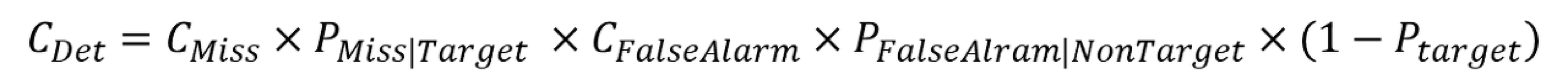
- 미국 국립표준기술연구소(NIST, National Institute of Standards Technology)에서 주관하는 화자인식 대회에서 사용하는 평가 지표
EER 과 minDCF 모두 에러가 차지하는 비율(확률)이므로 숫자(%) 가 작을수록 성능이 좋습니다.
(EER 계산 코드) https://github.com/YuanGongND/python-compute-eer
Speaker Diarization (화자 분할)
두 사람 이상이 대화를 하는 경우 각 화자를 구분하는 기술로,
'화자가 다르다는 것을 인식'하기 위한 기술입니다.
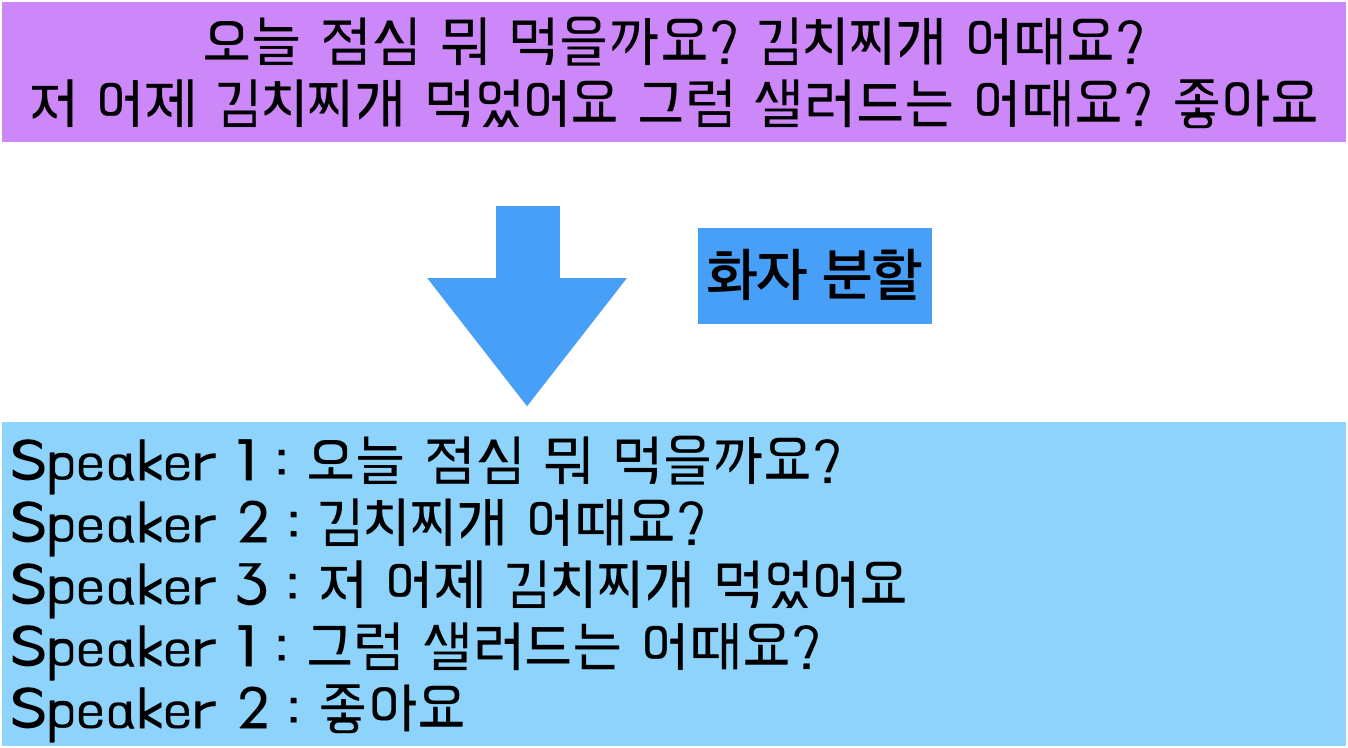
화자 분할 과정

https://sail.usc.edu/publications/files/Park-Diarization-CSL2022.pdf
-
Front-End Processing
음성 향상 / 잡음 / 반향 제거 등의 전처리를 수행하며
중첩되는 음성 영역을 각각 분리합니다. (Speech separation) -
Speech Activity Detection
= voice activity detection (VAD 라고 더 많이 사용하는 것 같아요)
실제 음성과 배경 소음(noise) 을 구분하여 실제 음성을 얻습니다. -
Segmentation (음성 분할)
입력 오디오 스트림을 여러 세그먼트로 나누어 화자 균일 세그먼트를 얻습니다.
아래 예시 그림의 경우, 3명의 화자의 음성을 균일하게 나누었습니다.

-
Speaker Embedding
각 세그먼트의 임베딩을 구합니다.
- i-vector, DNN-based embeddings…
- Clustering
각각의 임베딩 값을 k개의 클러스터로 레이블링합니다.
화자 분할의 경우 다음 2가지 클러스터링 방법을 이용합니다.
- Agglomerative hierarchical clustering (AHC)
- Spectral clustering
- Post Processing
최종적으로 결과를 더 잘 나타내기 위해 다시 한번 정제하는 과정입니다.
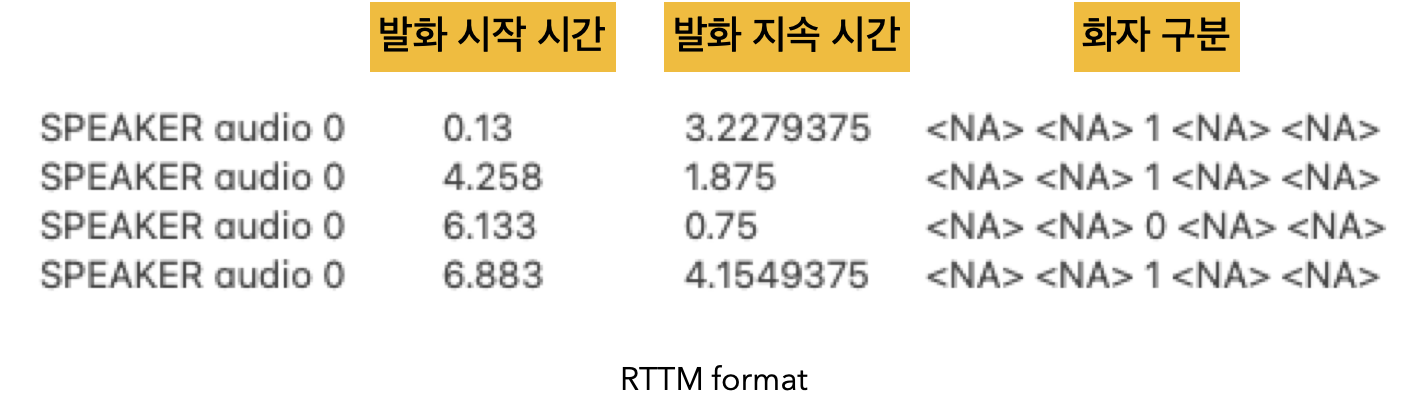
이 과정을 마치면 화자 분할의 공식(?!) 포맷인 'RTTM' 포맷에 맞춰 화자 분할 정보를 출력하는데요,
RTTM 파일로부터 '누가 언제부터 언제까지 말했는가' 를 알 수 있습니다.
화자 분할 평가
DER (Diarization Error Rate)
-
False Alarm (FA): 실제로는 없는 화자를 잘못 식별한 경우
-
Missed Detection (Miss): 실제로 존재하는 화자를 인식하지 못한 경우.
-
Speaker Error (Speaker): 화자를 잘못 구분하거나 잘못된 타임스탬프로 화자를 식별한 경우

-
RTTM format file 을 이용해 DER 계산

DER 또한 에러가 차지하는 비율(확률)이므로 숫자(%) 가 작을수록 성능이 좋습니다.
(DER 계산 코드) https://github.com/wq2012/SimpleDER
Reference
https://speech-ai.tistory.com/11
https://brunch.co.kr/@kakao-it/135
https://www.skelterlabs.com/blog/speechai
https://sail.usc.edu/publications/files/Park-Diarization-CSL2022.pdf
https://github.com/nryant/dscore
https://github.com/clovaai/voxceleb_trainer
https://github.com/pyannote/pyannote-audio
https://github.com/cvqluu/simple_diarizer
https://github.com/juanmc2005/diart
