[글또] 음성인식 시리즈
1.Speaker Recognition & Diarization

Speaker Recognition (화자 인식) 입력받은 음성 데이터를 미리 저장된 데이터베이스와 비교하여 화자가 누구인지 식별하는 기술 Speaker Identification (화자 식별) 등록된 여러개의 목소리를 비교하여 화자 식별 Speaker Veri
2.Speaker Diarization 오픈소스 프레임워크 소개
Speaker Diarization (화자 분할) 두 사람 이상이 대화를 하는 경우 각 화자를 구분하는 기술로, '화자가 다르다는 것을 인식'하기 위한 기술입니다. 이번 포스팅에서는 오픈소스 화자분할 프레임워크 3가지를 소개합니다. Pyannote https://
3.Whisper : Transformer base STT Model
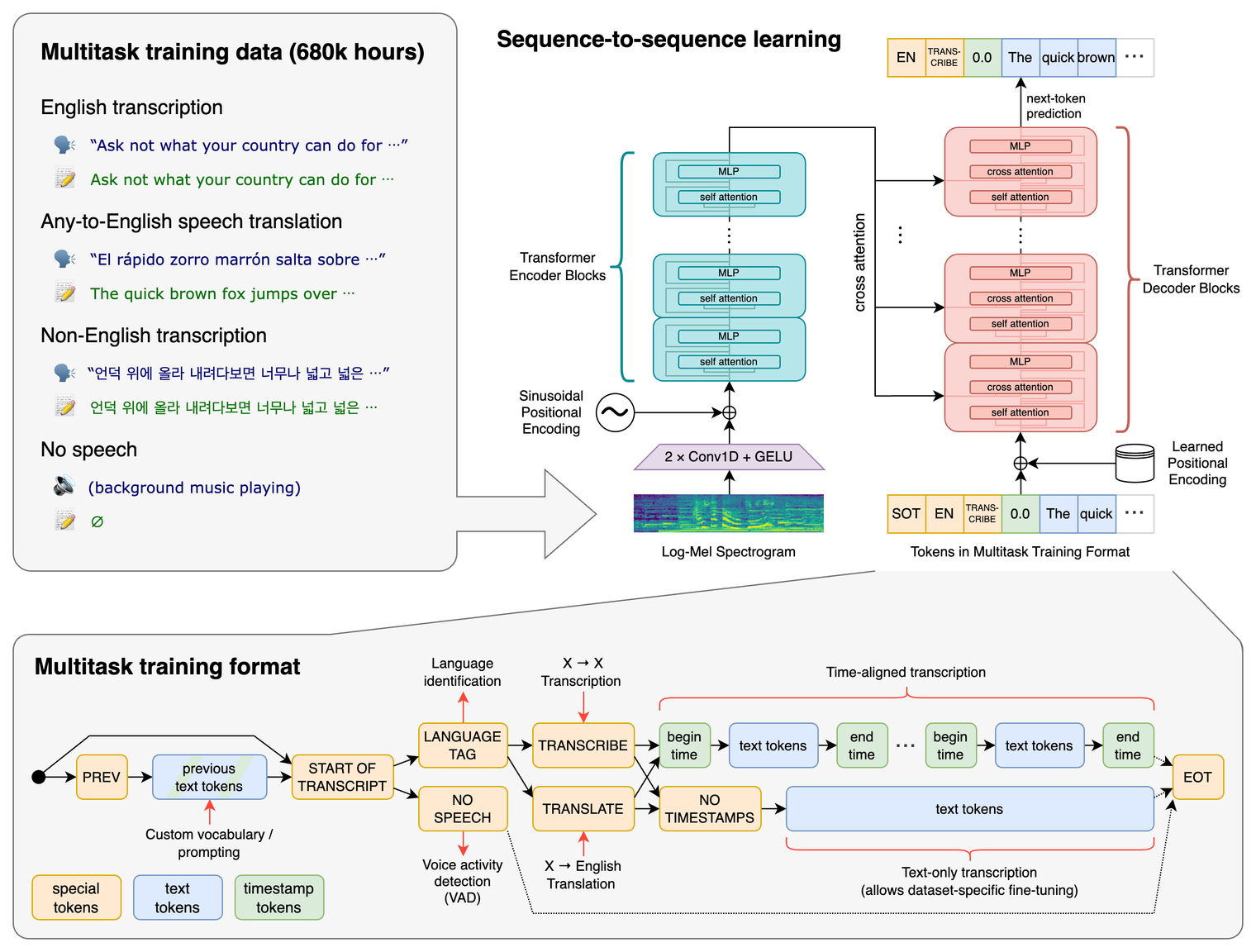
STT(Speech-To-Text) 의 대표적인 모델 중 하나인 Whisper 에 대해음성인식 회사의 현직자 관점에서 소개하고 설명합니다.https://arxiv.org/pdf/2212.04356.pdfWhisper 모델 구조와 학습 데이터 구축을 다룬 논문입
4.[글또] 음성 명령어 인식 라이브러리 소개 (JSGF, Voice2Json, Rhasspy)
Nugu, Google Assistant 등의 인공지능 스피커 및 음성 비서와 같은 각종 음성 인식 서비스는 사용자의 발화를 어떻게 명령어로 인식할까요? 사용자의 발화 명령어는 텍스트로 변환되고, 이 텍스트가 기존에 정의한 명령어라면 해당 명령을 수행합니다. 이렇게
5.[글또] 언어학과 인공지능 : 음성 개인비서의 장단점과 향후 발전 방향
본 포스팅은 K-Mooc 강의 '언어학과 인공지능' 과제로 작성하였습니다.스마트폰에 탑재되어 일상생활에 사용되고 있는 Siri, Google Assistant, Bixby 등과 같은 개인음성비서 중의 하나를 선택한 후, 이를 사용해서 적어도 5턴 이상의 대화(즉, 5회