STT(Speech-To-Text) 의 대표적인 모델 중 하나인 Whisper 에 대해
음성인식 회사의 현직자 관점에서 소개하고 설명합니다.
Robust Speech Recognition via Large-Scale Weak Supervision
https://arxiv.org/pdf/2212.04356.pdf
Whisper 모델 구조와 학습 데이터 구축을 다룬 논문입니다.
논문에서 요약한 Whisper 의 특장점은 다음과 같습니다.
Whisper : general-purpose speech recognition model
-
데이터셋별 fine-tuning 없이 안정적으로 작동하는 강력한 단일 음성 처리 시스템
-
trained on a large dataset of diverse audio
-
multitasking model
- multilingual speech recognition, speech translation, and language identification
-
Zero-shot
- 여러 데이터셋 / 도메인에 걸쳐 supervisd 방식으로 사전 학습된 음성 인식 시스템은 단일 소스에서 학습된 모델보다 robust 하고 hold-out 데이터셋에 훨씬 더 효과적으로 일반화된다.
-
Multilingual
- scaled to 680,000 hours of multilingual and multitask supervision
Model
아래 그림은 Whisper 의 모델 구조로, Transformer 를 베이스로 하고 있습니다.
(개인적으로 Whisper 가 WeNet 등의 다른 음성 프레임워크와 비교하여 더 진입 장벽이 낮았는데,
저는 NLP 중에서도 기계번역 태스크를 가장 많이 다뤄 보았는데
Whisper 는 기계번역 태스크와 동일하게 Transformer 모델을 이용하기 때문에
다른 모델 또는 프레임워크에 비해 상대적으로 모델 구조를 이해하기에 쉬웠습니다.
이 점은 저 이외에 다른 NLP 경력자분들도 비슷하게 느끼실 것 같습니다.)
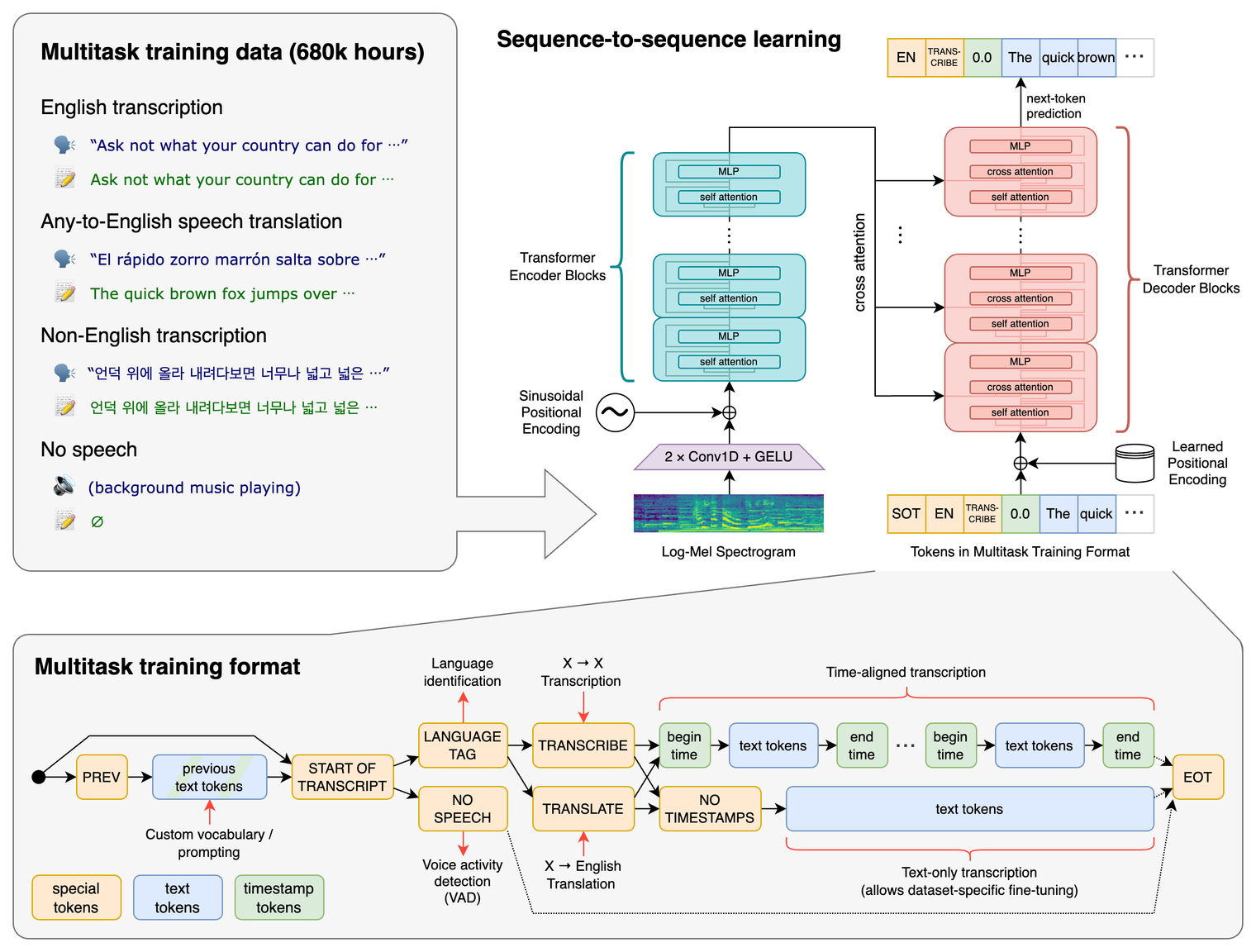
Multitask using Special Token
Whisper 는 하나의 모델로 다양한 작업을 수행하는데요,
즉, 하나의 모델에서 multitask 하려면 task specification이 필요합니다.
Whisper 는 아주 단순하게 decoder input data 에 token 을 추가하는 형태로 이를 구현했습니다.
-
⟨|startoftranscript|⟩: 예측의 시작을 나타낸다.- 먼저, 학습 셋의 각 언어(총 99개)에 대한 고유한 토큰으로 표현되는 말하는 언어를 예측한다.
-
⟨|nospeech|⟩: 오디오 세그먼트에 음성이 없는 경우 이를 나타내는 ⟨|nospeech|⟩ 토큰을 예측하도록 모델을 학습한다. -
⟨|transcribe|⟩/⟨|translate|⟩전사 또는 번역 지정 -
⟨|notimestamps|⟩: 각 케이스에 대한 ⟨|notimestamps|⟩ 토큰을 포함하여 타임스탬프를 예측할지 여부를 지정한다.
이 시점에서 task와 원하는 형식이 완전히 지정되고 출력이 시작된다. -
⟨|endoftranscript|⟩마지막 토큰 추가.
Usage
간단하게 한국어 STT를 측정하는 예시 코드입니다.
pre-trained 모델은 medium 을 이용합니다.
whisper audio.mp3 --language Korean --model mediumReference
OpenAI Whisper와 함께하는 음성 인식
(Whisper 사용법과 pre-trained 모델별 STT 결과까지 잘 정리한 블로그입니다.)
Faster-Whisper
https://github.com/SYSTRAN/faster-whisper
Transformer 모델을 위한 빠른 추론 엔진인 CTranslate2를 사용하여
OpenAI의 Whisper 모델을 다시 구현한 프레임워크입니다.
Whisper 와 비교하였을 때 장점은
- 보다 더 적은 메모리를 사용하면서도 동일한 정확도
- 속도가 최대 4배 빠름
- CPU와 GPU 모두에서 8비트 양자화를 사용하면 효율성이 더욱 향상될 수 있음
현업 서비스에서는 모델 inference 속도를 반드시 고려해야 하는데,
Whisper 를 그대로 서빙하기보다는 Faster-Whisper 를 사용하는 것을 추천합니다.
Usage
from faster_whisper import WhisperModel
model_size = "large-v3"
# Run on GPU with FP16
model = WhisperModel(model_size, device="cuda", compute_type="float16")
# or run on GPU with INT8
# model = WhisperModel(model_size, device="cuda", compute_type="int8_float16")
# or run on CPU with INT8
# model = WhisperModel(model_size, device="cpu", compute_type="int8")
segments, info = model.transcribe("audio.mp3", beam_size=5)
print("Detected language '%s' with probability %f" % (info.language, info.language_probability))
for segment in segments:
print("[%.2fs -> %.2fs] %s" % (segment.start, segment.end, segment.text))Tip
백엔드 프레임워크로 FastAPI 를 사용하면 파이썬 하나만으로 모델 predict 백엔드를 구축할 수 있어서
Faster-Whisper + FastAPI 조합을 추천하고 싶습니다.

FASTER-WHISPER 모델을 저의 커스텀 데이터로 학습할 수 있는 방법이 있을까요?