Sentence Alignment
앞서 PCF 글에서는 이미 만들어진 번역 모델 학습용 데이터셋(Parallel Corpus) 를 필터링하는 방법들을 소개하였는데요,
이번 글에서는 parallel corpus 를 만들기 위해 문장을 정렬하는 방법을 소개하겠습니다.
대부분의 parallel corpus 를 만드는 순서는 다음과 같습니다.
-
Raw data 수집
웹사이트(특히 뉴스 기사 사이트) 를 크롤링하거나 특정 도메인 문서 (법률, 특허 등) 를 파싱합니다.
파싱한 데이터는 document 또는 paragraph 형태로, 여러 개의 문장이 뭉쳐져 있는 형태입니다. -
문장 매칭 (Sentence alignment)
Document / paragraph 단위의 초기 파싱 데이터를 문장 단위로 쪼갠 뒤
source : target = 1 : 1 매칭시킵니다.
번역 모델은 문장 단위로 학습하기 때문이지요.
2번 과정에서 문장 단위 정렬(Alignment) 툴을 이용하여야 하는데, 그 이유는 다음 예시와 같습니다.
- 문장 분절 오류나 번역상 의역 등으로 인해 문장 갯수가 맞지 않는 경우
- 기타 문장 순서대로 1 : 1 매칭되지 않는 경우
- ex)
- (Source)
집에 가고 싶지만 이미 집이다 (문장 1개) - (Target)
I want to go home.
But I am already at home (문장 2개)
- (Source)
이번 글에서는 2번 과정, 즉 같은 뜻을 갖는 source 문장 : target 문장끼리 정렬하여 parallel corpus 를 생성하기 위한
문장 정렬 (Sentence Alignment) 툴 몇 가지를 소개하겠습니다.
(이 글에서 소개한 모든 예시 코드는 제 GitHub 에 있습니다.)
1. BleuAlign
An MT-based sentence alignment tool
Bleualign은 BLEU Score를 이용해서 두 개의 말뭉치들을 정렬하는 툴입니다.
동작 방법을 간단히 살펴보도록 하겠습니다.
(1) 다음과 같이 문장 단위로 분리된 한국어와 영어로 된 글이 있다고 가정합니다.
이때 같은 글에 대한 문장들이므로 비슷한 문장들이 많이 존재하며, 무조건 1:1 매칭이 되지는 않습니다.
한국어, 영어, 기계 번역 결과를 동시에 입력값으로 Bleualign에 넣어주면 문장 단위의 병렬 말뭉치가 출력됩니다.
같은 색깔의 박스들은 같은 문장의 다른 언어로 된 표현(Representation)들입니다.
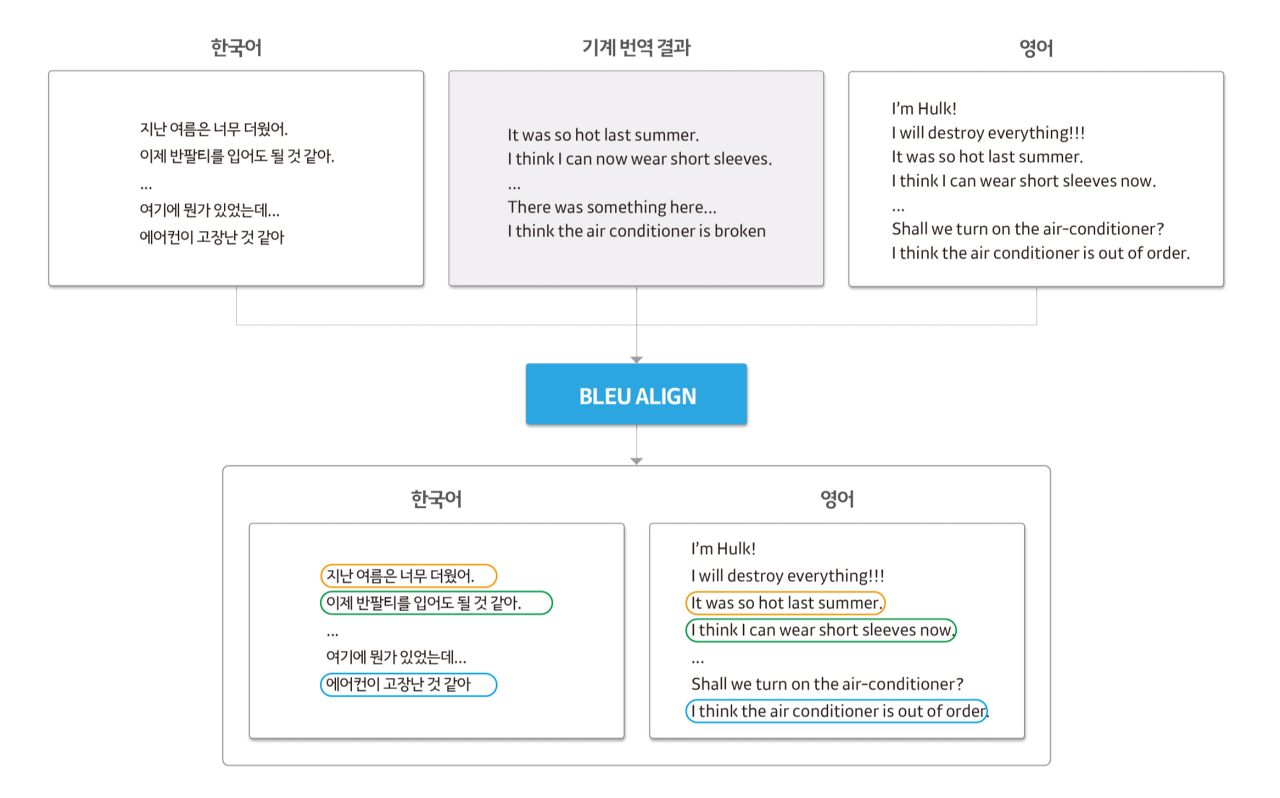
Bleualign 은 기계번역 결과와 영어 말뭉치를 통해 같은 문장을 찾게 되는데, 이때 비슷한 문장을 찾기 위해 BLEU Score를 사용합니다.
Bleualign 의 단점은 번역기(사전 학습된 번역 모델) 가 없다면 사용할 수 없는 점입니다.
개인적인 견해로 Back-Translation 으로 데이터셋을 얻은 뒤 Bleualign 을 적용하면 효과적일 것이라 생각합니다.
Back-Translation 을 이용하면 source - MT - target 모두 얻을 수 있는데,
이렇게 얻은 Triplet 에 Bleualign 을 바로 적용할 수 있기 때문입니다.
Practice
-
source - MT - target 데이터 파일을 준비합니다.

-
Bleualign 을 실행합니다.

-
Bleualign 실행이 끝나면 다음과 같이 source, target output 파일이 각각 생성됩니다.
생성된 output file 들은 src : tgt = 1:1 쌍을 이룹니다.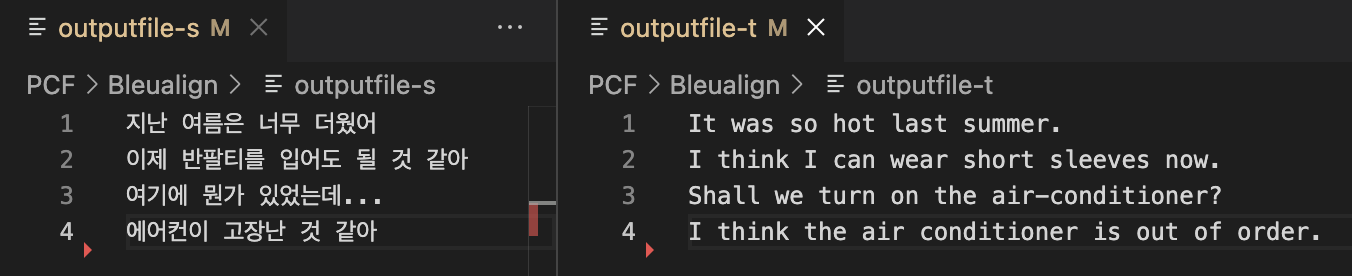
Ableualign
Bleualign은 N-gram Precision을 계산하는데 있어 한계를 지닙니다.
이에 Bleualign의 개선 버전인 Ableualign을 이용하면 비교적 간단한 아이디어로 많은 효과를 볼 수 있습니다.
Idea
BLEU에서는 N-gram Precision을 계산하는데 있어 정확히 매칭되는 것만 카운팅합니다.
'이쁘다'와 '예쁘다'는 분명히 비슷한 뜻인데 0, 1로만 구분해서 집계(Discrete Counting) 하기에 매칭이 되지 않는 결과가 발생합니다.
때문에 비슷한 단어에 대해 0과 1사이의 어떤 유사도(Similarity)를 연속적(Continuous)으로 부여하여 유사도를 구할 수 있다고 가정해 볼 때, ABLEU는 BLEU 수식에서 단 한 개만 바꾸면 됩니다.
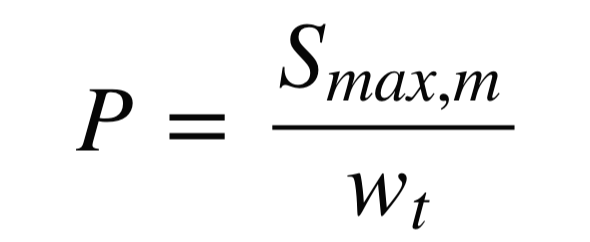
https://github.com/juneoh/ABLEUAlign
Reference
(BleuAlign, ABleuAlign) https://tech.kakaoenterprise.com/50
(BleuAlign) https://github.com/rsennrich/Bleualign
(AbleuAlign) https://github.com/juneoh/ABLEUAlign
2. VecAlign
Improved Sentence Alignment in Linear Time and Space
Vecalign은 다국어 문장 임베딩의 유사도를 활용하여 매우 긴 문서에서도 빠르고 정확하게 문장을 정렬해 주는 알고리즘입니다.
LASER 와 함께 사용하며, 기계 번역 시스템이나 사전 없이 약 100가지 언어를 지원합니다.
Vecalign 논문의 abstract 에서는 이렇게 설명하는데요,
Vecalign uses an approximation to Dynamic Programming based on Fast Dynamic Time Warping which is linear in time and space with respect to the number of sentences being aligned.
약간 의역하자면
Vecalign 알고리즘은 시간복잡도 및 공간복잡도가 선형, 즉 정렬되는 문장의 수와 수행 시간/공간이 비례하는 Approximate Dynamic Programming 기법을 이용합니다.

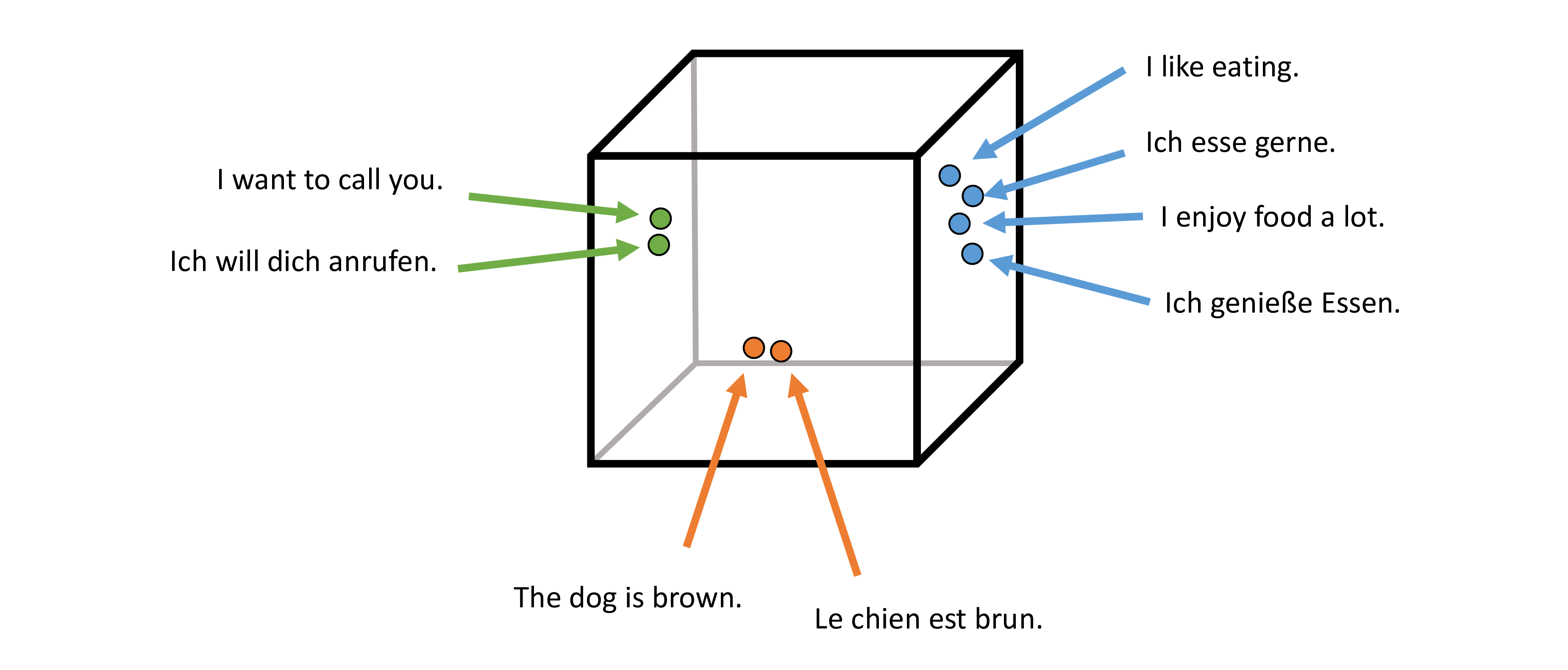
Vecalign 의 강점은 다 대 다 (N : M) 문장 매칭이 가능하다는 점입니다.
문장이 연속적으로 등장할 경우 여러 개의 문장들을 묶어서 매칭할 수 있습니다.

Example
src.ko 파일과 tgt.en 파일을 각각 준비합니다.
- 문장 중첩 (Overlap)
문장 정렬을 하기 전에 vecalign 의 overlap.py를 사용하여 문장을 중첩하고, 중첩 argument 를 설정하여 중첩 양을 지정해야 합니다. (-n)
중첩 방식은 각 파일을 순회하는 것으로, i번째 줄은 i번째 줄부터 시작하여 중첩되는 줄까지의 문장을 한 줄, 두 줄 병합하여 새로운 문장으로 작성하는 방식입니다.
python overlap.py -i paragraph/src.txt -o paragraph/overlap_src.txt -n 3
python overlap.py -i paragraph/tgt.txt -o paragraph/overlap_tgt.txt -n 3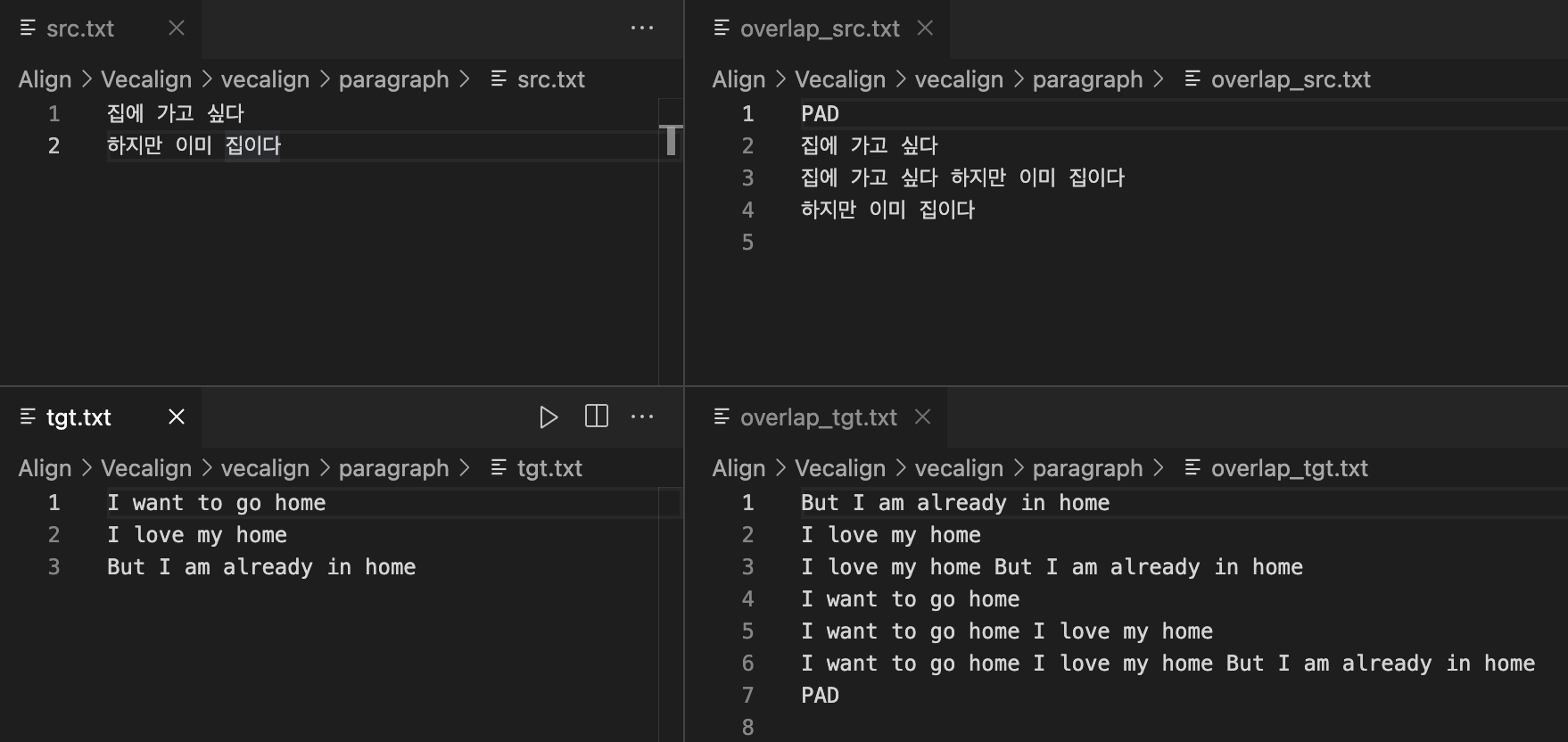
- LASER embedding
LASER 를 사용하여 overlap 을 생성한 텍스트를 임베딩합니다.
tasks/embed/embed.sh ../vecalign/paragraph/overlap_src.txt ../vecalign/paragraph/overlap_src.emb
tasks/embed/embed.sh ../vecalign/paragraph/overlap_tgt.txt ../vecalign/paragraph/overlap_tgt.embLASER 설치 및 추가 모델 다운로드는 다음을 참고합니다.
-
https://github.com/facebookresearch/LASER 리포지토리 클론
git clone https://github.com/facebookresearch/LASER.git -
LASER 환경변수 설정
export LASER="${HOME}/projects/laser" -
인코더 파일 다운로드
(laser2.pt 와 다수의 laser3 pretrained model 을 다운받을 것입니다.
각각의 .pt 모델에 해당하는 .spm (sentencepiece model), .cvocab 파일도 함께 다운로드됩니다.)
본 예제에서는 laser2.pt 만으로 충분합니다.bash ./nllb/download_models.sh -
SentencePiece 를 이용하기 위해 추가 툴을 설치합니다.
SentencePiece 설치가 원활하지 않을 경우 공식 리포지토리를 참고하여 설치합니다.
https://github.com/google/sentencepiecebash ./install_external_tools.sh
- Vecalign 적용
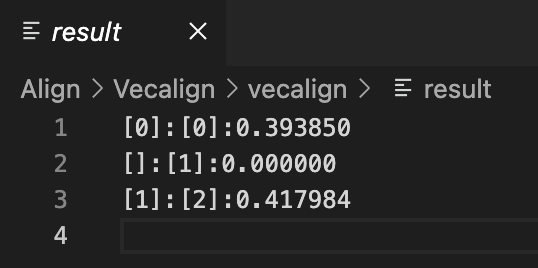
./vecalign.py \
--alignment_max_size 3 \
--src paragraph/src.txt \
--tgt paragraph/tgt.txt \
--src_embed paragraph/overlap_src.txt paragraph/overlap_src.emb \
--tgt_embed paragraph/overlap_tgt.txt paragraph/overlap_tgt.emb > result적용 결과 [source index] : [target index] : 유사도 순으로 정렬됩니다.
Reference
(Paper) https://aclanthology.org/D19-1136.pdf
(Toolkit) https://github.com/thompsonb/vecalign
(Usage) https://github.com/ToKliar/Sentence-Alignment-Algorithms/blob/23cbc173244578354b915e05ddeb4dc5fd0c04d0/%E5%BC%80%E6%BA%90%E5%B7%A5%E5%85%B7%E8%B0%83%E7%A0%94/vecalign.md
3. FAISS (Facebook AI Similarity Search)
library for efficient similarity search and clustering of dense vectors
Meta (구 Facebook) 에서는 다국어 연구를 활발하게 진행하는데요,
다국어 번역 모델인 M2M-100 개발 과정에서 parallel corpus 를 구축하기 위한 방법 중 하나로 LASER 와 FAISS 를 함께 이용하였습니다.
수많은 서로 다른 다국어 문장들 사이에서 의미적으로 유사한 문장들을 찾기 위해
LASER 로 먼저 임베딩 값을 구하고, FAISS 로 유사도를 측정하여 유사한 문장끼리 매칭하였습니다.
FAISS 는 dense vector 간 유사도를 매우 효율적으로 측정해 주기 때문에
번역 태스크뿐만이 아니라 문장 유사도 비교가 필요한 다른 태스크에도 널리 쓰이는데
이 글을 쓰기 위해 구글링해보니 챗봇과 클러스터링 태스크에 더 많이 쓰이는 것 같습니다 😉
검색기반 챗봇은 검색 성능과 속도가 매우 중요한데 FAISS 는 정말 빠르거든요.
numpy 나 torch 에서 제공해주는 cosine_similarity 보다도 훨씬 빠르다고 합니다. (출처)
Example
src.ko 파일과 tgt.en 파일을 각각 준비합니다.
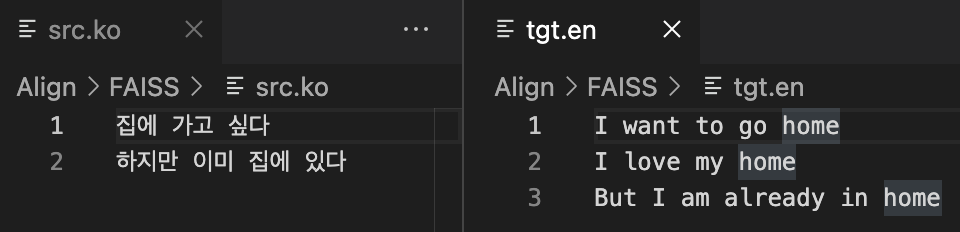
1. Query : Key = Source sentence : Target Document
하나의 Source 문장과 일치하는 target 문장을 target 문서 내에서 찾습니다.
import numpy as np
import faiss
from laserembeddings import Laser
# target 데이터 로드
with open('tgt.en', 'r', encoding='utf8') as f:
bitext = f.readlines()
# LASER 모델 로드
laser = Laser()
# 문장 임베딩 생성
embeddings = laser.embed_sentences(bitext, lang='en')
# Faiss 인덱스 생성
d = embeddings.shape[1]
index = faiss.IndexFlatIP(d)
index.add(embeddings)
# 검색할 쿼리 문장
query = '집에 가고 싶다'
# 쿼리 문장의 임베딩 생성
query_emb = laser.embed_sentences([query], lang='ko')[0]
# 검색
# 유사도 높은 순으로 top k 개의 문장 추출
D, I = index.search(np.array([query_emb]), k=1)
# 검색된 결과 출력
print("Query: ", query)
print("Key Sentence: ", bitext[I[0][0]])
print("Index: ", I[0][0])
2. Query : Key = Source Document : Target Document
이번에는 문서 : 문서 관계에서 매칭되는 문장 쌍을 찾습니다.
import numpy as np
import faiss
from laserembeddings import Laser
# src.txt와 tgt.txt 데이터 로드
with open('src.ko', 'r', encoding='utf8') as f:
src_lines = f.readlines()
with open('tgt.en', 'r', encoding='utf8') as f:
tgt_lines = f.readlines()
# LASER 모델 로드
laser = Laser()
# 문장 임베딩 생성
src_embeddings = laser.embed_sentences(src_lines, lang='ko')
tgt_embeddings = laser.embed_sentences(tgt_lines, lang='en')
# Faiss 인덱스 생성
d = src_embeddings.shape[1]
index = faiss.IndexFlatIP(d)
index.add(tgt_embeddings)
# src.txt의 각 문장에서 가장 유사한 문장 검색
for i, src_line in enumerate(src_lines):
# 쿼리 문장의 임베딩 생성
query_emb = laser.embed_sentences([src_line], lang='en')[0]
# 검색
# 유사도 높은 순으로 top k 개의 문장 추출
D, I = index.search(np.array([query_emb]), k=1)
# 검색된 결과 출력
print("Source sentence: ", src_line.strip())
print("Target sentence: ", tgt_lines[I[0][0]].strip())
print("Source index: ", i)
print("Target index: ", I[0][0])
print()
Reference
(LASER embedding file + FAISS)
https://github.com/akeele/fiskmo-parallel
(Additional)
[챗봇] faiss로 빠르게 유사도 검색하기(Similarity Search)
https://acdongpgm.tistory.com/286
Faiss 튜토리얼 : Similarity Search와 Clustering을 빠르게!
https://dongkyuk.github.io/tips/faiss/
결론
이 글에서는 다양한 Sentence Alignment 툴을 소개하였습니다.
다시 한번 기계번역 모델 학습용 데이터셋을 만드는 순서를 정리하면 다음과 같습니다.
- 2개의 언어로 작성된 웹사이트를 크롤링하거나 문서를 파싱하여 raw dataset 을 얻는다.
- Raw dataset 에 Sentence Alignment 를 적용하여 문장 : 문장 = 1 : 1 대응 쌍을 얻는다.
- 1:1 문장 쌍으로 새로 구축한 데이터셋에 PCF 를 적용하여 클린한 데이터셋을 얻는다
다음 시리즈에서는 이렇게 얻은 데이터셋을 이용하여 기계번역 모델을 만들기 위해
대표적인 기계번역 오픈소스 프레임워크와 각각의 학습 방법을 소개하겠습니다.
