안녕하세요! 글또 8기 AI 연구 채널의 최민주 입니다 🙋🏻♀️
지난 NMT 시리즈에서 NMT 학습용 데이터셋을 구축하기 위해 고려할 점에 대해 간단히 이야기하였습니다.
이번 글에서는 구축된 데이터셋의 완성도를 높이기 위한 방법 중 PCF (Parallel Corpus Filtering) 에 주목하여
가장 기본적이고 간단한 PCF 기법 몇 가지를 소개하겠습니다.
기계번역 모델을 학습할 때에는 1:1 로 매칭된 문장 쌍을 이용하는데요,
바로 이 1:1 문장 쌍을 모아서 만든 데이터셋이 Parallel Corpus 이고,
PCF는 Parallel Corpus Filtering, 한국어로 '병렬 코퍼스 필터링' 이라 부르며
정제와 다르게 학습 데이터에 부합하지 않다고 판단되면 문장 쌍을 모두 삭제하는 필터링 방식입니다.
이 글에서는 '언어의 종류에 상관없이 일괄적으로 적용 가능한 방법' 만을 소개합니다.
(LASER 의 경우 지원하는 언어가 200개 이상이므로 대부분의 언어에 적용 가능하여 이번 시리즈에서 소개합니다.)
*예시 코드는 제 GitHub 에서 참고하실 수 있습니다.
1. Rule-base
Simple is the Best
가장 간단하면서도 강력한 방법이며, 데이터셋 정제(필터링), 전처리 과정에서 꼭 필요한 작업입니다.
가장 기본적이면서도 필수적인 방법으로 문장 길이가 일정 범위 이내인 문장 쌍만 남기는 방법이 있습니다.
- 원문/번역문 최소/최대 길이 (charactor 갯수) 기준 필터링
- 원문/번역문 구성 word(token) 최소/최대 갯수 기준 필터링
문장 길이 기준 필터링을 응용하여 문장 길이 비율을 기준으로 필터링할 수도 있습니다.
- 번역문 길이가 원문 길이의 50% 이하인 문장 쌍 제거
('집에 가고 싶은데 이미 집에 있다. - I want.' 와 같은 미완성 쌍 제거)
Meta AI (구 Facebook AI) 에서는 'm2m-100' 다국어 번역 모델 학습 데이터셋을 구축하는 과정에서
다음과 같은 필터링 기준을 적용하였으니 참고하시면 좋겠습니다.
- 50% 이상의 구두점, 공백을 갖는 문장 제거
- 중복 데이터 제거
- 길이 비율이 어느 한 쪽의 3배 이상인 경우 제거
- 너무 문장이 긴 경우 (정확히는 단어가 250개 이상인 경우) 제거
- test 데이터셋에 있는 문장도 train 데이터셋에서 제거
더욱 세밀한 Rule-base 필터링이 필요한 경우 다음 필터링 기준도 참고할 수 있습니다.
(출처 : 병렬 코퍼스 필터링과 한국어에 최적화된 서브 워드 분절 기법을 이용한 기계번역)
- Source - Target 문장이 동일할 경우 제거
- 동일한 Source 문장이 다양한 Target 문장과 연결되어 있거나
반대로 동일한 Target 문장이 다양한 Sorce 문장과 연결된 경우 제거 - 한 문장에 해당 언어의 표기 문자가 아닌 문자가 50% 이상 포함되어 있거나
한 문장이 연결된 문장에 비해 표기 문자가 아닌 문자를 특히 많이(1:3 이상) 포함하고 있을 경우 제거 - 같은 단어가 반복되는 문장 제거
- 각 문장 속 언어를 추정하는 언어 식별 소프트웨어(language identification software)를
사용하여 알맞는 언어로 판단되지 않으면 제거
(파이썬 언어 감지 라이브러리 참고)
필터링 이외에 추가로 제각각인 데이터를 통일하여 데이터셋을 정제할 수도 있는데요,
같은 모양의 글자를 서로 다른 코드로 표현이 가능할 때 이를 하나의 코드로 정규화합니다.
- 유니코드 통일
- 원문 - 번역문 기호/숫자 통일 (1, ⑴, ①... -> '1' 로 통일)
Reference
https://arxiv.org/abs/2010.11125
https://koreascience.kr/article/CFKO201930060758842.pdf
2. BLEU Score (Bilingual Evaluation Understudy Score)
학습된 번역기와 평가 지표를 이용하는 손쉬운 필터링 방법
Source - Target - MT 3개의 언어 쌍 (Triplet) 데이터셋이 존재할 때 적용 가능한 방법입니다.
- Source (원문) : "집에 가고 싶다"
- Target (번역문/정답) : "I want to go home"
- MT (Machine Translation 즉 기계번역을 통해 생성된 번역문) : "I want home"
BLEU는 기계 번역 결과(MT)와 사람이 직접 번역한 결과(Target)가 얼마나 유사한지 비교하여 번역에 대한 성능을 측정하는 대표적인 방법입니다.
(번역 이외에도 Style Transfer 등 다른 Task 에서도 이용하는 평가 지표입니다.)
BLEU 의 장단점은 다음과 같습니다.
- 장점
- 언어에 구애받지 않고 사용할 수 있음
- 계산 속도가 빠름
- 단점 (한계)
- 문법 구조, 유의어 등을 고려하여 측정할 수 없음
MT와 Target 문장의 유사도를 측정하기 위해 N-gram 을 이용하는데요,
문장을 구성하는 단어들을 N-gram으로 만들고, 그 N-gram들이 서로 얼마나 매칭되는지를 보는 식으로 구성되며, 보통 3~4-gram까지 진행됩니다.
먼저 N-gram은 문장을 어떤 단위로 분할했을 때 인접한 N 개를 모은 것을 의미합니다.
간단하게 띄어쓰기를 단위로 한 3-gram을 구하면 다음과 같습니다.
예) 집에 가고 싶다'
3-gram: 'I want to', 'want to go', 'to go home'(이렇게 문장을 쪼개는 이유는 문장 간의 유사도를 측정할 때 문장의 일부로서 매칭을 해보기 위함입니다.)
BLEU score 를 이용하여 문장 쌍을 필터링하는 가장 간단한 방법으로
1. MT - Target 문장 간 BLEU score 를 계산하고,
2. BLEU score 범위가 0~100, 숫자가 클수록 번역 모델의 성능이 좋은 점,
다시 말해 두 문장의 유사도가 높음을 이용하여 특정 score 이상인 문장 쌍만 남기는 방법이 있습니다.
다만 이 경우는 데이터셋이 클수록 각각의 문장 쌍 당 BLEU score 를 계산하는 데에 시간이 오래 걸리므로
대규모 데이터셋 (문장 쌍 천만개 이상) 을 반복적으로 필터링할 때에는 그다지 추천하고 싶지 않고
문법 구조, 유의어 등을 고려할 수 없는 BLEU 의 단점 때문에 BLEU score 를 온전히 신뢰할 수 없으므로
다른 필터링 방법을 함께 이용하는 것을 추천하고 싶습니다.
또한 이 방법은 이미 학습된 번역 모델이 없으면 MT 데이터를 얻을 수 없어 적용이 불가능합니다.
개인적인 견해로 데이터셋 구축 과정에서 Back-Translation 을 이용하면 source - MT - target 모두 얻을 수 있는데,
이렇게 얻은 Triplet 에 바로 BLEU score 를 계산하여 필터링하면 효율적일 것이라 생각합니다.
Practice
Target 과 MT 문장의 BLEU score 를 측정해 보겠습니다.
NLTK 및 MOSES 라이브러리에서 BLEU score 를 측정하는 모듈을 제공하지만
예제에서는 WMT 에서 평가 지표로 쓰이는 SacreBLEU 를 이용하겠습니다.
import sacrebleu
# Target
refs = ["I want to go home"]
# MT (Generated by a MT model)
candis = ["I want to go"]
bleu = sacrebleu.corpus_bleu(candis, [refs]).score
측정 결과는 다음과 같으며, 각각의 문장 쌍에 BLEU score 를 계산한 후
score 가 70점 이상인 문장 쌍만 남기는 형태로 필터링이 가능합니다.

Reference
(BLEU)
https://wikidocs.net/31695
(BLEU & N-gram)
https://tech.kakaoenterprise.com/50
(SacreBleu)
https://github.com/mjpost/sacrebleu
(SacreBleu in Python)
https://github.com/isi-nlp/sacrebleu
3. Multilingual Sentence Embedding
앞서 BLEU score 를 이용하는 방법으로는 문법 구조, 유의어를 고려할 수 없다고 설명하였고,
이미 학습된 번역 모델이 없으면 적용 불가능하다는 점도 함께 언급하였습니다.
그렇다면, 각 언어의 문법 구조나 유의어에 크게 구애받지 않으면서
학습된 번역 모델 없이도 두 문장의 유사도를 얻을 수 있는 방법은 없을까요?
해답은 '다국어 문장 임베딩' 입니다.
딥러닝을 이용해 사전 학습된 다국어 임베딩 모델을 이용하면 코드 몇 줄만으로
다양한 언어 문장 쌍 간의 유사도를 구할 수 있습니다.
LASER (Language-Agnostic SEntence Representations)
딥러닝을 이용한 다국어 문장 임베딩 계산
2020년 Fasebook AI 에서 다국어 문장 임베딩을 계산하는 라이브러리 'LASER' 를 발표했습니다.
LASER는 각 언어에 대해 별도의 모델을 사용하지 않고, 하나의 모델을 이용해 모든 언어를 하나의 shared space 에 join 시킵니다.
(= 다국어 문장을 고차원 공간의 한 지점에 매핑합니다.)
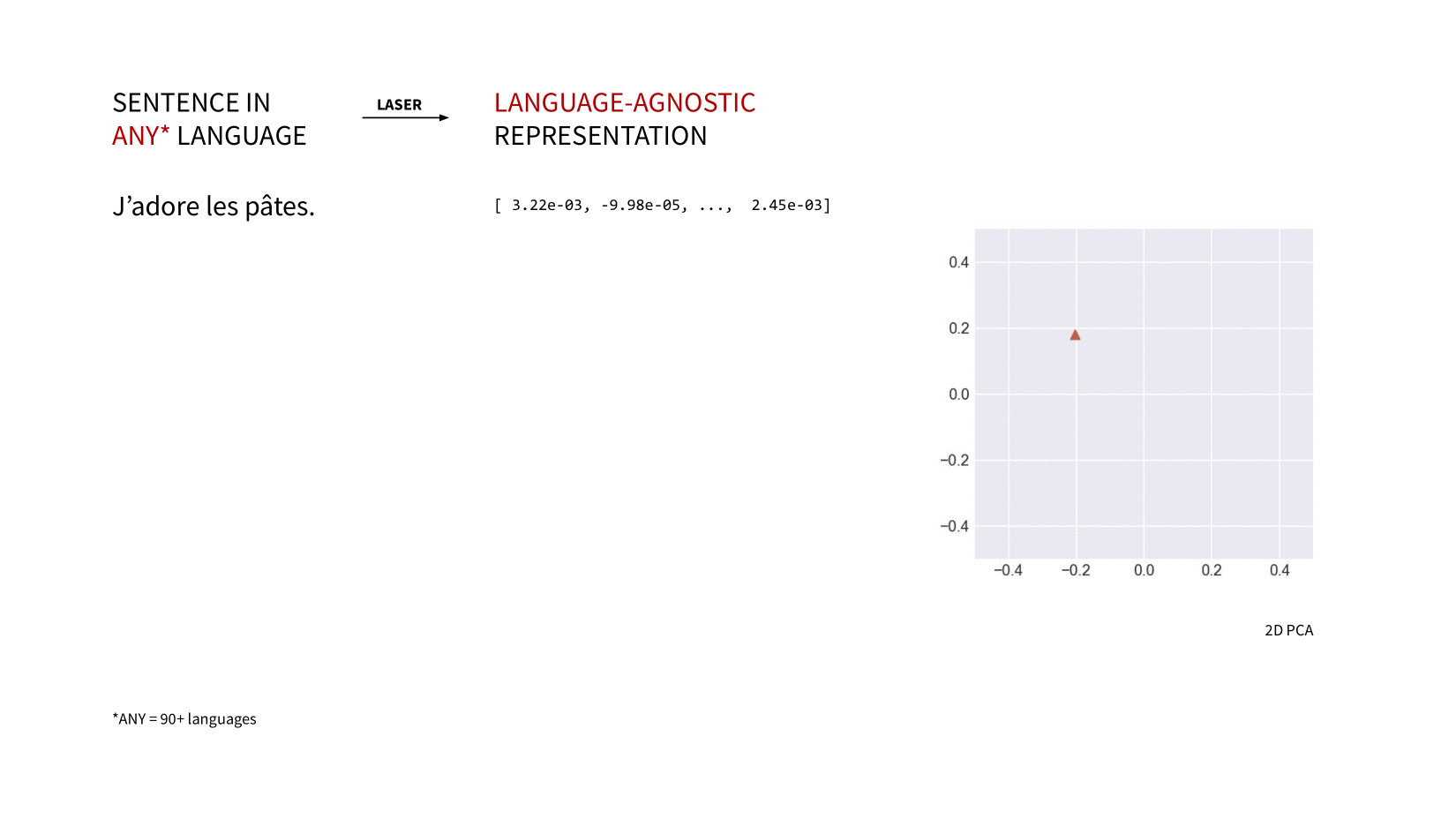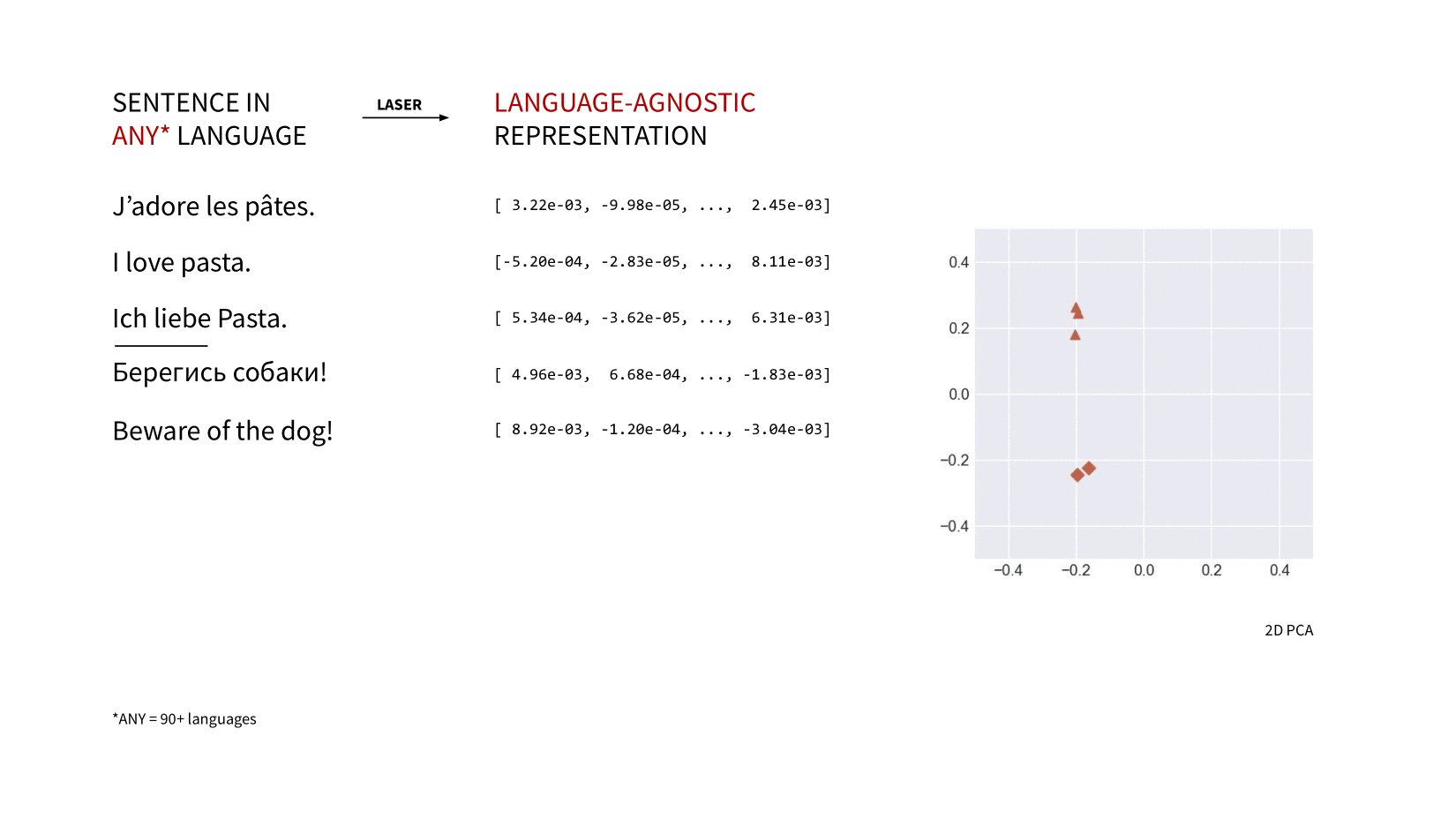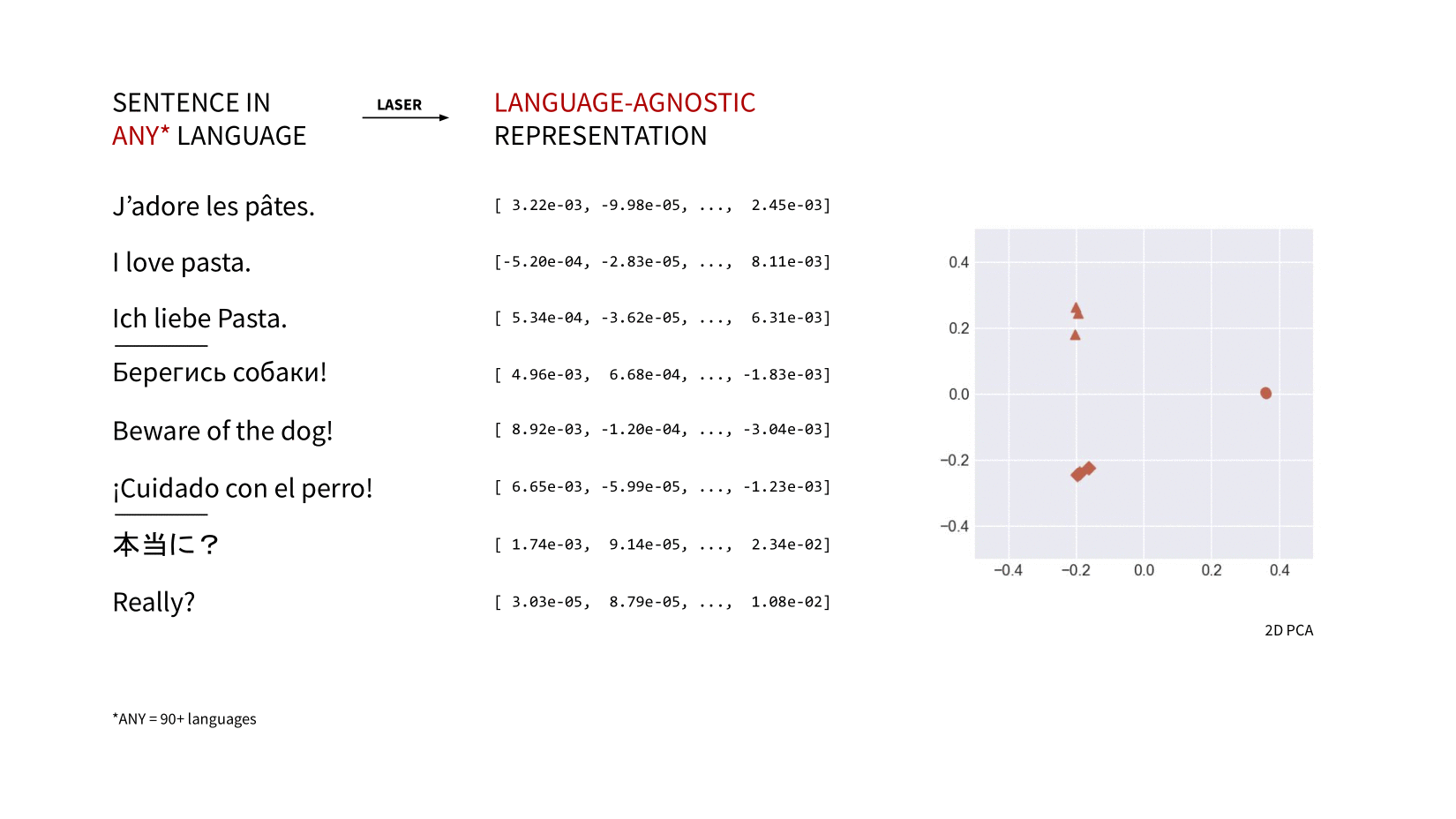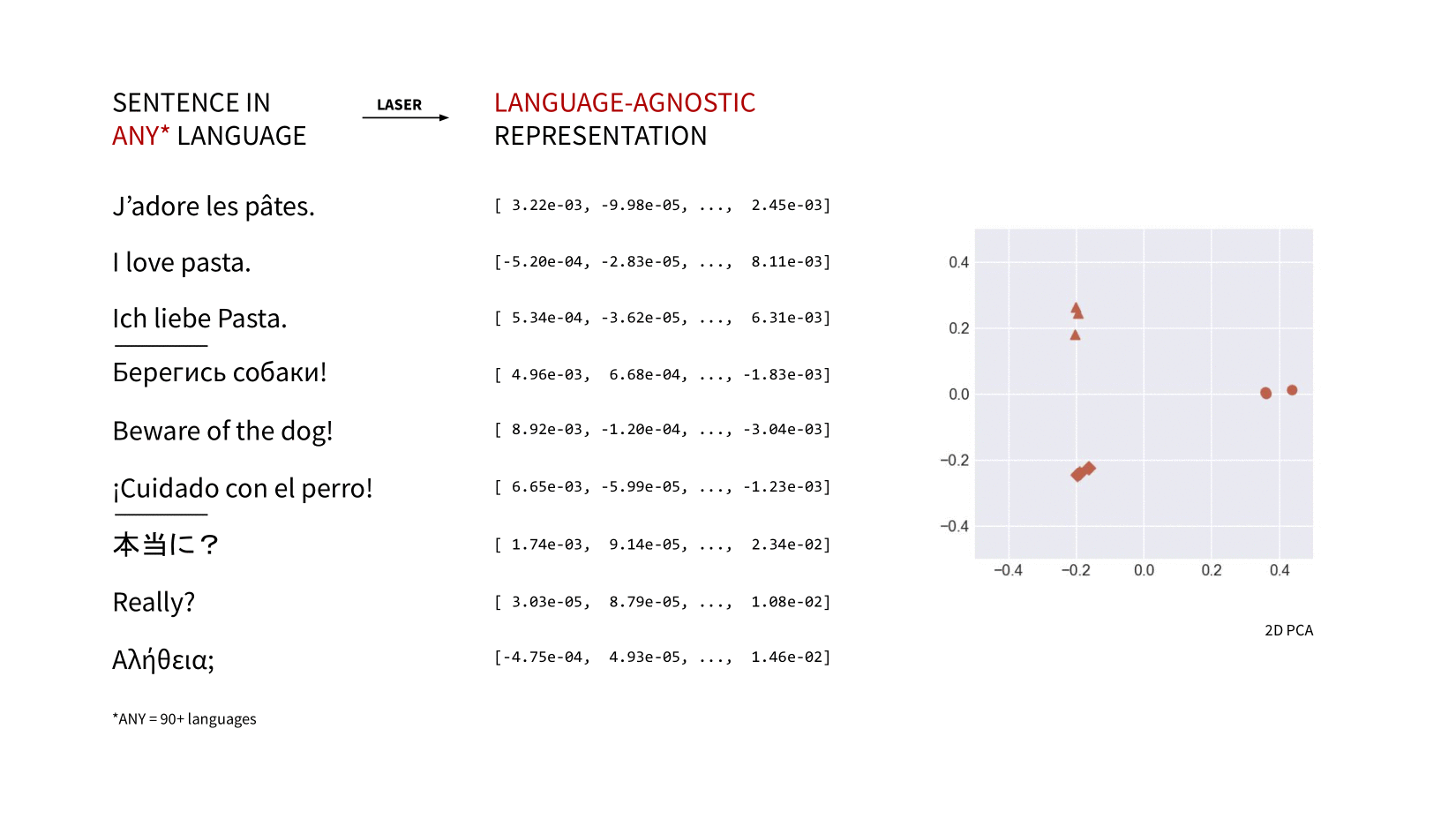
현재 LASER2 를 거쳐 LASER3 까지 발표되었으며, 사용 가능한 언어가 지속적으로 추가되었습니다.
Practice
LASER 를 이용해 원문, 번역문 각각 임베딩 벡터를 구한 후, 두 벡터의 유사도를 구하는 예제입니다.
유사도를 계산하는 방법으로 가장 기본적인 코사인 유사도를 사용하였습니다.
- LASER 를 이용해 문장 임베딩 벡터를 구합니다.
from laserembeddings import Laser
laser = Laser()
src = "집에 가고 싶다"
tgt = "I want to go home"
# Get embedding vector of sentences
src_embed = laser.embed_sentences(src, lang='ko')
tgt_embed = laser.embed_sentences(tgt, lang='en')- 문장 임베딩 벡터 간 유사도 계산 (코사인 유사도 사용)
import numpy as np
# Get cosine similarity between 2 vectors
def cosine_similarity(v1, v2):
n1 = np.linalg.norm(v1)
n2 = np.linalg.norm(v2)
return np.dot(v1, v2.T).squeeze() / n1 / n2
# Get cosine similarity score between src, tgt embeddings
cs_score = cosine_similarity(src_embed, tgt_embed)
동일한 방법으로 여러 번역 쌍의 유사도를 구한 뒤
유사도가 (예를 들어) 0.7 이상인 번역 쌍만 남기는 방법으로 필터링할 수 있습니다.
Reference
(LASER 임베딩 벡터 구하기)
https://github.com/yannvgn/laserembeddings
Future Work
이번 글에서 1:1 문장 쌍으로 구성된 Parallel Corpus 를 필터링하는 방법에 대해 몇 가지 방법을 소개하였는데요,
그렇다면 관점을 바꿔서 이미 구축된 1:1 데이터셋을 필터링하여 클린한 데이터셋을 만드는 것에 그치지 않고
처음 데이터셋을 구축할 때부터 최대한 클린한 초기 데이터셋을 만드는 방법은 없을까요?
보통 데이터셋을 구축할 때 2개 이상의 언어로 쓰여진 웹사이트(특히 뉴스 사이트)를 크롤링하거나 문서 파일을 파싱하여 구축하곤 하는데요,
보통은 문장 단위로 1:1 매칭이 되어있지 않고 단락(Paragraph) 내지 글 (Article) 단위로 매칭이 되어 있습니다.
따라서 단락/글 단위로 언어 쌍이 매칭되어 있는 raw dataset 으로부터 문장을 추출한 뒤
뜻이 맞는 문장끼리 짝을 지어 주어야 하는데, 다시 말해 문장 단위로 정렬(Align)을 해 줘야 합니다.
(Align 작업에는 이 글에서 언급한 BLEU 와 LASER 도 사용됩니다.
BLEU Align, LASER + FAISS 또는 VecAlign...)
추후에 Align 라이브러리들의 종류와 사용법도 정리해 보겠습니다. 👩🏻💻
