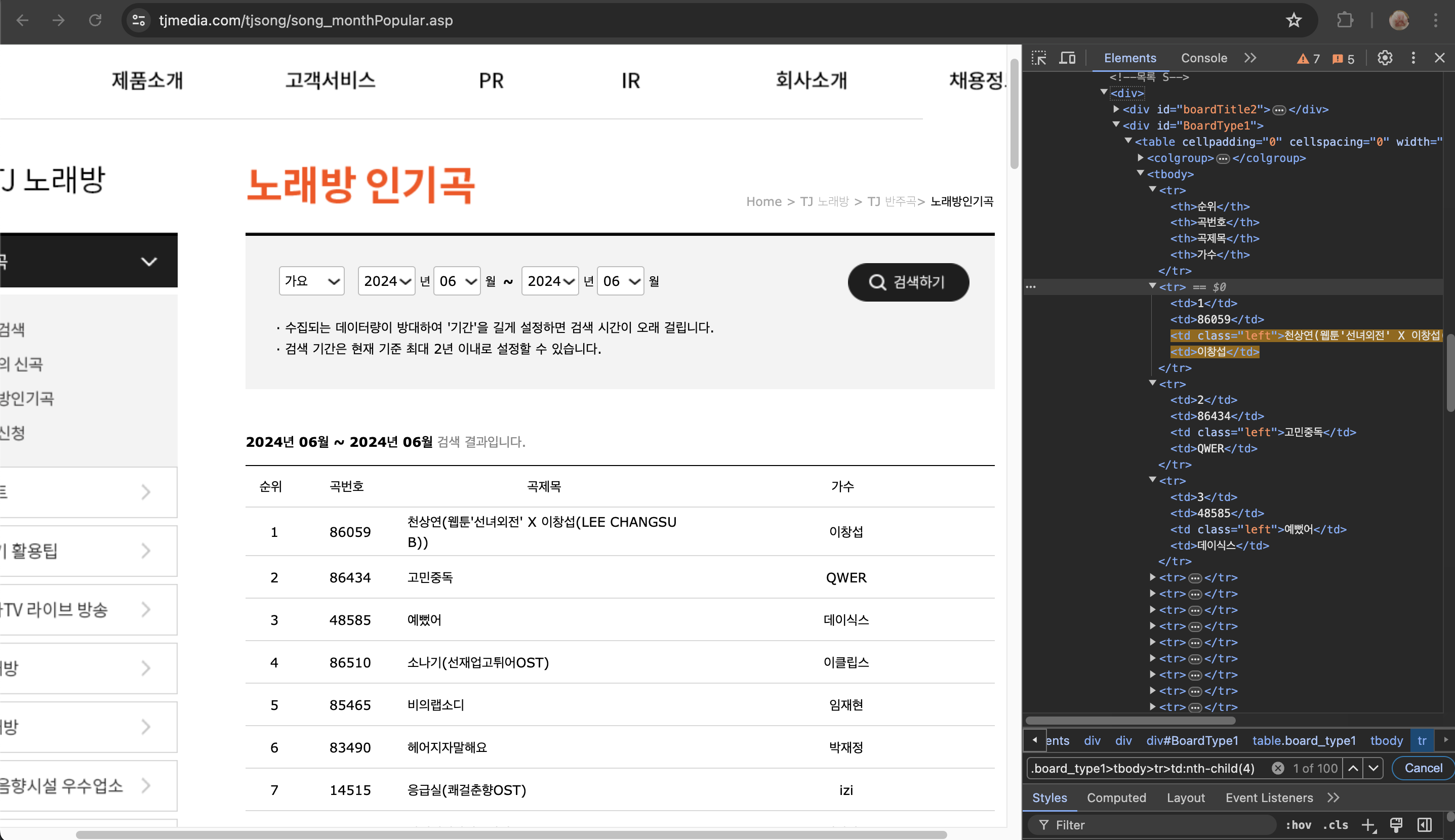
목표: TJ 노래방 인기차트 데이터를 크롤링하여 csv 파일에 저장하기
초기 코드
import requests
from bs4 import BeautifulSoup as bs
import pandas as pd
data = []
for i in range(100):
response = requests.get("https://www.tjmedia.com/tjsong/song_monthPopular.asp")
# 한글 데이터 안깨지게 가져오려면 인코딩 필요
response.encoding = "utf-8"
html = response.text
soup = bs(html, 'html.parser')
# .board_type1>tbody>tr:nth-child(n+2) 선택자를 사용하여 첫 번째 tr을 제외
items = soup.select(".board_type1>tbody>tr:nth-child(n+2)")
for item in items:
rank = item.select_one("td:nth-child(1)").text
number = item.select_one("td:nth-child(2)").text
title = item.select_one("td:nth-child(3)").text
artist = item.select_one("td:nth-child(4)").text
print(rank, number, title, artist)
data.append([rank, number, title, artist])
#df = pd.DataFrame(data, columns=['순위', '곡번호', '곡제목', '가수'])
#df
#df.to_excel('tj_result.xlsx', index=False)💥 문제 상황:
탑100 랭킹 데이터 처리에 25초라는 매우 긴 시간이 소요된다.
→ 스레드를 이용해 동시에 데이터를 수집하도록 고친다.
최종 코드
import requests
from bs4 import BeautifulSoup as bs
import pandas as pd
from concurrent.futures import ThreadPoolExecutor
import csv
def fetch_data(url):
response = requests.get(url)
# 한글 데이터 안깨지게 가져오려면 인코딩 필요
response.encoding = 'utf-8'
html = response.text
soup = bs(html, 'html.parser')
# .board_type1>tbody>tr:nth-child(n+2) 선택자를 사용하여 첫 번째 tr을 제외
items = soup.select(".board_type1>tbody>tr:nth-child(n+2)")
data = []
for item in items:
rank = item.select_one("td:nth-child(1)").text
number = item.select_one("td:nth-child(2)").text
title = item.select_one("td:nth-child(3)").text
artist = item.select_one("td:nth-child(4)").text
data.append((rank, number, title, artist))
return data
# 수집할 URL 리스트 생성
urls = ["https://www.tjmedia.com/tjsong/song_monthPopular.asp" for _ in range(10)] # URL을 10번만 호출하도록 수정
# 동시 요청 수행
data = []
with ThreadPoolExecutor(max_workers=10) as executor:
results = executor.map(fetch_data, urls)
for result in results:
data.extend(result)
# 동시 요청으로 인한 데이터 중복 제거
data = list(set(data))
# 데이터를 DataFrame으로 변환
df = pd.DataFrame(data, columns=["Rank", "Number", "Title", "Artist"])
# DataFrame을 CSV 파일로 저장
df.to_csv("songs.csv", header=False, index=False, quoting=csv.QUOTE_ALL)
print("Data saved successfully to songs.csv")- 스레드 동시 요청을 수행하기 위해 데이터 처리 부분을
fetch_data함수로 작성했다. - 10개의 스레드로 동시 요청 수행 시 중복 데이터가 X10만큼 생겨 제거하는 과정이 필요하다.
🩵 결과:
수행 평균 시간이 0.7s로 향상되었다.
수집된 데이터 미리보기
"70","48462","나에게로의초대(이상한나라의앨리스,하트다하트여왕)","조유진,박기영"
"100","83434","I AM","IVE(아이브)"
"21","14832","사랑했나봐","윤도현"
"7","14515","응급실(쾌걸춘향OST)","izi"
"45","37545","스물다섯,스물하나","자우림"
...곡 순위, 노래방 번호, 제목, 가수가 잘 들어갔다.
느낀점
-
쌍따옴표를 제거하고 싶었지만 데이터 특성 상 콤마가 자주 들어간다.
콤마로 데이터가 구분되기에 pandas 라이브러리로는 해결할 수 없었다.
(콤마 포함된 문자열을 콤마 대신 다른 문자열로 감싸는 것은 가능)
데이터 사용시 쌍따옴표를 어떻게 처리해야할지에 대한 고민이 필요할 것 같다. -
정적 페이지 크롤링이라 비교적 쉬웠다. 휴우~ 별거 아니네 ㅋㅋ 😵 💫
-
앨범아트 url도 데이터로 저장하고 싶은데 TJ는 관련 데이터가 없다. 어떤 방법이 좋을까...

개: 개롭지만 발: 발전하는중