참고 영상: 유튜브 스타트코딩
연습 사이트: Electro
크롬으로 진행, 개발자도구 단축키: F12
1. 파일 설치
파이썬은 이미 설치되어있다는 가정 하에
pip install requestspip install bs42. 기초 이해
Requests란?
Python용 HTTP 라이브러리로, 특정 웹사이트에 HTTP 요청을 보내 HTML 문서를 받아올 수 있다.
단순한 String 형태로 받아오기 때문에 가독성이 떨어진다.
BeautifulSoup란?
HTML 코드를 비슷한 데이터끼리 나눠준다(Parsing).
개발자는 파싱된 데이터 중 원하는 데이터만을 가져와 유용하게 사용할 수 있다.
➡️ requests로 읽어들인 문서를 예쁘게 가공
CSS 선택자 활용
클래스와 ID, 하위 태그 선택
-
클래스 선택자:
.
💡 클래스명에 띄어쓰기가 있는 경우 (class="col-md-4 col-xs-6"): 여러 클래스가 띄어쓰기로 합쳐져 있는 것 ➡️.col-md-4.col-xs-6으로 선택 -
ID 선택자:
# -
자식 태그 선택자:
>
➡️ 클래스명이 "product"인 태그의 하위 태그인 div 선택:.product > div -
형제 태그 선택자:
HTML 문서 상 클래스 명이 brand-name인 부분을 선택할 경우
import requests
from bs4 import BeautifulSoup
# 스크래핑 설정
response = requests.get("https://startcoding.pythonanywhere.com/basic")
html = response.text
soup = BeautifulSoup(html, 'html.parser')
# 1. select_one: 매칭되는 태그 중 첫번째 반환
soup.select_one(".brand-name")
# 2. text: 텍스트만 선택
soup.select_one(".brand-name").text
# 3. attrs: 속성값을 딕셔너리 형태로 받기
soup.select_one(".brand-name").attrs
# 4. attrs['href']: 속성 중 'href'에 해당하는 속성값만 받기
soup.select_one(".brand-name").attrs['href']⬇️
# 1. select_one 결과
<a class="brand-name" href="https://www.youtube.com/channel/UCHwhZ7HPBhUh2IscPSL0pHA" target="_blank"><i class="fa fa-youtube"></i>스타트코딩</a>
# 2. text 결과
'스타트코딩'
# 3. attrs 결과
{'class': ['brand-name'],
'href': 'https://www.youtube.com/channel/UCHwhZ7HPBhUh2IscPSL0pHA',
'target': '_blank'}
# 4.attrs['href'] 결과
'https://www.youtube.com/channel/UCHwhZ7HPBhUh2IscPSL0pHA'3. 실전
1단계 - 한 개의 상품 크롤링
문자열 가공
strip(): 앞뒤 공백 문자 제거
soup.select_one(".product-price").text
# 결과: '1,419,000원\n\t\t\t\t\t\t\t\t\t\t\n\t\t\t\t\t\t\t\t\t'
soup.select_one(".product-price").text.strip()
# 결과: '1,419,000원'replace('변경 전 문자', '변경 후 문자'): 문자열 교체
soup.select_one(".product-price").text.strip().replace(',', '').replace('원', '')
# ',', '원' 삭제
# 결과: '1419000'크롤링 완료 코드
import requests
from bs4 import BeautifulSoup
response = requests.get("https://startcoding.pythonanywhere.com/basic")
html = response.text
soup = BeautifulSoup(html, 'html.parser')
category = soup.select_one(".product-category").text
name = soup.select_one(".product-name").text
link = soup.select_one(".product-name>a").attrs['href']
price = soup.select_one(".product-price").text.strip().replace(',', '').replace('원', '')
print(category, name, link, price)2단계 - 여러 개의 상품 크롤링
문자열 가공
select(): 선택자에 매칭되는 태그 전체 리스트 반환
items = soup.select(".product")
for item in items:
category = item.select_one(".product-category").text
name = item.select_one(".product-name").text
link = item.select_one(".product-name>a").attrs['href']
price = item.select_one(".product-price").text.strip().replace(',', '').replace('원', '')
print(category, name, link, price)
# 결과: 클래스명이 product인 모든 태그의 category, name, link, price 출력split(): 특정 문자열을 기준으로 문자열 나누기
price = item.select_one(".product-price").text.split("원")[0].replace(',', '')
# 결과: 14190003단계 - 여러 페이지 크롤링
페이징 알고리즘
- 페이지를 바꾸면서 URL이 변경되는 부분을 찾는다
- 페이지를 증가시키면서 요청을 보낸다
- 💡value 값이 없는 파라미터는 지워도 된다
https://startcoding.pythonanywhere.com/basic?page=1&keyword=
=
https://startcoding.pythonanywhere.com/basic?page=1
f String: 문자열과 변수를 합쳐 새로운 문자열 생성
name = "피카츄"
age = "3"
greeting = f"안녕하세요 제 이름은 {name}입니다. 나이는 {age}살입니다."
greeting
#결과: '안녕하세요 제 이름은 피카츄입니다. 나이는 3살입니다.'크롤링 완료 코드
import requests
from bs4 import BeautifulSoup
for i in range(1, 5):
response = requests.get(f"https://startcoding.pythonanywhere.com/basic?page={i}")
html = response.text
soup = BeautifulSoup(html, 'html.parser')
items = soup.select(".product")
for item in items:
category = item.select_one(".product-category").text
name = item.select_one(".product-name").text
link = item.select_one(".product-name>a").attrs['href']
price = item.select_one(".product-price").text.split("원")[0].replace(',', '')
print(category, name, link, price)4단계 - 크롤링한 데이터 엑셀에 저장
파일 설치
pip install pandaspip install openpyxlpandas: 데이터 분석 라이브러리
openpyxl: 엑셀 자동화 라이브러리
알고리즘
- 비어있는 리스트를 만들고 데이터를 한 행씩 추가한다
data = []
data.append([category, name, link, price])- 데이터 프레임을 만들고 엑셀로 저장한다
# 데이터 프레임 만들기
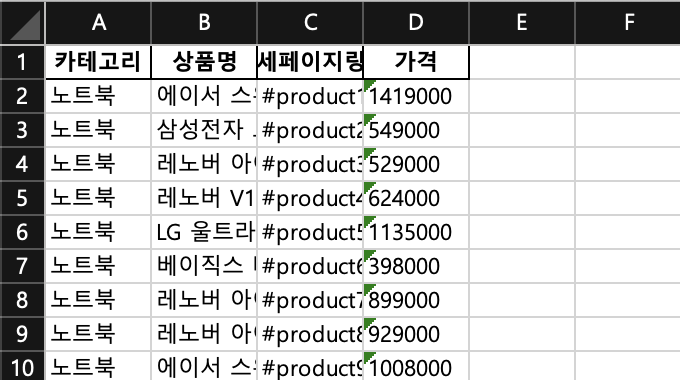
df = pandas.DataFrame(data, columns=['카테고리', '상품명', '상세페이지링크', '가격'])
# data라는 리스트를 데이터로 이용, 테이블 열 설정
# 엑셀 저장
df.to_excel('result.xlsx', index=False)
# result.xlsx 파일명으로 저장, 인덱스 번호는 붙이지 않음크롤링 완료 코드
import requests
from bs4 import BeautifulSoup
# pandas 라이브러리를 pd라는 이름으로 사용
import pandas as pd
data = []
for i in range(1, 5):
response = requests.get(f"https://startcoding.pythonanywhere.com/basic?page={i}")
html = response.text
soup = BeautifulSoup(html, 'html.parser')
items = soup.select(".product")
for item in items:
category = item.select_one(".product-category").text
name = item.select_one(".product-name").text
link = item.select_one(".product-name>a").attrs['href']
price = item.select_one(".product-price").text.split("원")[0].replace(',', '')
print(category, name, link, price)
data.append([category, name, link, price])
df = pd.DataFrame(data, columns=['카테고리', '상품명', '상세페이지링크', '가격'])
df
df.to_excel('result.xlsx', index=False)
개: 개롭지만 발: 발전하는중