🔴 논문 개요
제목: Rich feature hierarchies for accurate object detection and semantic segmentation (R-CNN, 2014)
저자: Ross Girshick, Jeff Donahue, Trevor Darrell, Jitendra Malik
링크: 논문, 코드
한 줄 요약: Region Proposal + CNN + SVM 구조로 기존 탐지 성능을 크게 향상시킨 최초의 딥러닝 기반 객체 탐지 시스템
🔴 Motivation
기존 기법의 한계는?
저수준 feature + hand-crafted 방식 -> 성능 한계
이 논문이 해결하려는 문제는?
CNN을 활용하여 데이터 기반의 고수준 특징을 추출하고자 함
제안된 아이디어의 핵심은?
선택적 탐색 + CNN 특징 추출 + SVM 분류기 + 박스 회귀기 조합으로 성능 30% 향상 (VOC 2012 기준)
🔴 Architecture / 방법론
전체 파이프라인 도식
입력 이미지
↓
Selective Search (Region Proposals)
↓
Warp & Resize (227x227)
↓
CNN (Pretrained on ImageNet)
↓
4096-d Feature Vector (fc7)
↓
├─> Category-specific SVM → 클래스 분류
└─> Bounding Box Regressor → 위치 보정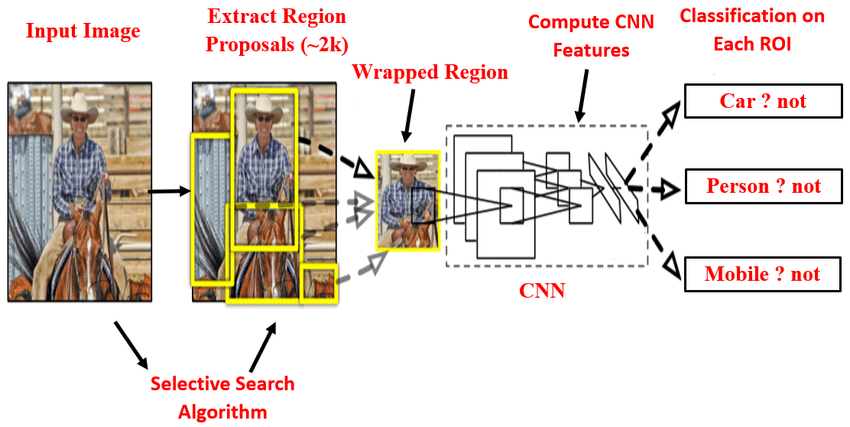
각 구성 요소 설명
- Selective Search: 약 2000개 제안 박스 생성
- CNN (AlexNet): 각 proposal에서 특징 추출
- SVM: 각 클래스를 위한 이진 분류기
- BBox Regressor: 박스 위치 정교화 (L2 손실)
🔴 Implementation Detail
데이터셋
- VOC 2007/2012
- ILSVRC2012
특징 추출 방식
CNN: AlexNet (ImageNet pretrained)
Input 개발법: 각 region proposal을 227x227으로 재조정(warping)
Feature Vector: fc7 계층과에서 나온 4096차원 특징 벡터
모델 구조
Region Proposal (Selective Search)
↓
Warp to 227x227
↓
CNN (AlexNet)
↓
fc7 Feature Vector (4096-d)
↓
├─ SVM Classifier (Class-wise)
└─ Bounding Box Regressor (Class-wise)학습 세부 설정 (Optimizer, Epoch 등)
Fine-tuning
Optimizer: SGD
Learning Rate: 0.001
Batch Size: 128
Epochs: 충분한 학습 필요(10 ~ 50 epoch)
Weight Decay: 0.0005
Momentum: 0.9SVM 학습
Class-wise Linear SVM
Positive: IoU ≥ 0.5
Negative: IoU ∈ [0.1, 0.5)
Hard Negative Mining 적용BBox Regression
Loss: L2(Least Squares)
IoU < 0.6은 학습에서 제외
Class-wise 바운딩 박스 회귀기🔴 실험 결과
mAP 또는 주요 지표 표로 정리
| 방법 | VOC2010 mAP (%) |
|---|---|
| DPM v5 | 33.4 |
| Regionlets | 39.7 |
| R-CNN | 50.2 |
| R-CNN + BBox Reg | 53.7 |

비교 모델과의 성능 비교
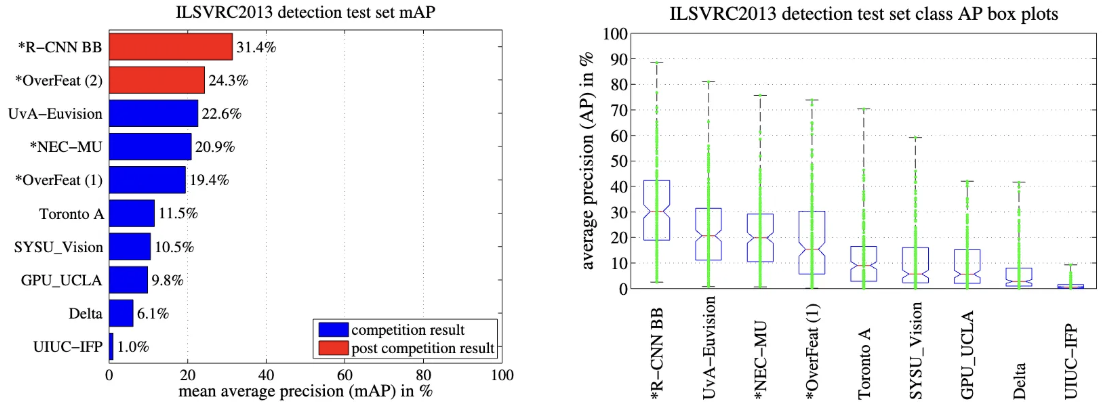
| 방법 | ILSVRC2013 mAP (%) |
|---|---|
| R-CNN + BBox Reg | 31.4 |
| OverFeat | 24.3 |
Ablation Study 요약
- BBox Regression 사용 시
- mAP 약 3% 향상
- Softmax vs SVM
- Softmax only: 50.9%
- Softmax + SVM: 54.2%🔴 Insight & Discussion
강점 / 한계
강점
간단하고 확장 가능한 구조로 기존 탐지 성능 대비 mAP 30% 향상
한계
매 proposal마다 CNN 추론 수행 (Warping) -> 속도 느림, 계산량 큼
왜 이 방법이 효과적이었는가?
CNN으로 데이터 기반의 강력한 특징 학습
Region Proposal을 통해 배경/객체 구분 -> 클래스 불균형 완화
Fine-tuning + SVM + BBox Regression 결합으로 정밀도와 위치 정확도 모두 개선
후속 연구에 미친 영향은?
Fast R-CNN, Faster R-CNN, Mask R-CNN의 기초 구조 제공
Feature reuse, end-to-end 학습 개념 발전 계기
RPN(Region Proposal Network) 등장의 기반 마련
🔴 참고 코드
GitHub
- GitHub: rbgirshick/rcnn
🔴 요약 정리
이 논문을 한 문단으로 요약하면?
Selective Search + CNN 특징 추출 + SVM + BBox Regression이라는 단순한 구조로 딥러닝 기반 객체 탐지의 새 지평을 연 R-CNN
기존 탐지 시스템 대비 30% 이상 성능 향상, 이후 발전 계열(Fast/Faster R-CNN 등)의 기반이 됨
🔴 코드 간단 구현
import cv2
import torch
import torchvision.models as models
import torchvision.transforms as T
from sklearn.svm import LinearSVC
from sklearn.preprocessing import LabelEncoder
import numpy as np
from tqdm import tqdm
from PIL import Image
# 1. Pretrained CNN 모델 (특징 추출기 역할)
cnn = models.alexnet(pretrained=True)
feature_extractor = torch.nn.Sequential(*list(cnn.children())[:-1]) # fc7 이전까지
feature_extractor.eval()
# 2. 전처리 transform
transform = T.Compose([
T.Resize((227, 227)),
T.ToTensor(),
T.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
# 3. Selective Search 함수
def get_proposals(image):
ss = cv2.ximgproc.segmentation.createSelectiveSearchSegmentation()
ss.setBaseImage(image)
ss.switchToSelectiveSearchFast()
return ss.process() # [x, y, w, h] 리스트 반환
# 4. 이미지 → 특징 벡터 추출 함수
def extract_feature(img):
with torch.no_grad():
x = transform(img).unsqueeze(0) # [1, 3, 227, 227]
features = feature_extractor(x)
return features.view(-1).numpy()
# 5. 데이터 구축 및 SVM 학습
X, y = [], []
for img_path, gt_boxes, label in tqdm(train_data): # train_data는 [(경로, GT박스, 라벨)]
image = cv2.imread(img_path)
image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
rects = get_proposals(image)
for (x, y_, w, h) in rects[:100]: # top 100개만 사용
roi = image_rgb[y_:y_+h, x:x+w]
if roi.shape[0] < 20 or roi.shape[1] < 20:
continue
pil_roi = Image.fromarray(cv2.resize(roi, (227, 227)))
feature = extract_feature(pil_roi)
X.append(feature)
# GT box와 IoU ≥ 0.5 → 양성 / 아니면 음성
iou = compute_iou([x, y_, x+w, y_+h], gt_boxes) # GT 여러 개일 수 있음
label_value = label if iou >= 0.5 else "background"
y.append(label_value)
# 6. 라벨 인코딩 및 SVM 학습
le = LabelEncoder()
y_encoded = le.fit_transform(y)
svm = LinearSVC()
svm.fit(X, y_encoded)🔴 주요 키워드
CNN: 합성곱 신경망, 특징 추출기로 사용됨
Image classification: 이미지 분류
Object detection: 객체 탐지
Region proposals: 객체가 있을 가능성이 높은 영역 후보를 이미지에서 미리 찾아내는 과정
Sub-images / sub-windows: 서브이미지, 후보 영역
Sliding window classifiers: 슬라이딩 윈도우 기반 탐지기
Feature extractor: 특징 추출기, CNN이 대체하는 부분
Feature hierarchy: 특징 계층 구조, CNN의 추출 방식
Bounding box: 객체의 위치를 나타내는 사각형
Bounding box regression: 바운딩 박스를 더 정확히 조정하는 기법
Category-specific SVMs: 각 클래스마다 따로 학습된 이진 분류기. 특정 객체 vs 배경
Transfer learning: 전이 학습, 사전 학습된 모델 활용
Fine-tuning: 미세 조정, 대상 테스크에 맞게 학습
PASCAL VOC / ILSVRC: 실험에 사용된 대표적인 데이터셋
Mean Average Precision(mAP): 탐지 성능 측정 지표
Computational cost: 계산 비용
Selective Search: 비학습 기반 region proposal 알고리즘. Superpixel을 계층적으로 병합해 약 2000개 후보 영역 생성
Superpixels: 비슷한 색, 질감 등의 픽셀을 하나의 작은 영역으로 묶은 단위.
Warping(227x227): 제안된 각 영역을 CNN의 입력 크기에 맞게 변형 (AlexNet에 맞도록 resize)
Hard Negative Mining: SVM 학습에서 헷갈리는 음성 예시만을 사용해 날카로운 결정 경계 학습
Bounding Box Regresison: CNN 특징을 바탕으로 예측된 박스를 실제 객체 위치에 가깝게 수정
Localization: 객체 위치를 정확하게 맞추는 능력. BBox Regression이 핵심 역할
IoU(Intersection over Union): 예측 박스와 정답 박스의 겹치는 정도. 0.5 이상이면 탐지 성공
AP(Average Precision): 특정 클래스에서 Precision-Recall 곡선 아래 면적
mAP(mean Average Precision): 모든 클래스의 AP 평균. 객체 탐지 성능을 평가하는 대표 지표
Non-Maximum Suppression (NMS): 중복된 예측 박스 제거. confidence가 높은 박스를 남기고 나머지 제거.
Test-time Detection: 테스트 시 region proposal 생성 -> CNN 추출 -> SVM 분류 -> NMS 순서로 탐지 수행
Fast R-CNN: R-CNN 구조를 end-to-end로 통합하여 속도 개선
Faster R-CNN: Region Proposal 자체를 신경망(RPN)으로 학습
Mask R-CNN: Faster R-CNN에 segmentation 기능 추가
Feature Reuse: 한 번 추출한 CNN feature map을 여러 proposal에 재활용하는 방식
Region Proposal Network(RPN): 기존 Selective Search 대신 학습 기반 영역 제안🔎 Sliding Window vs Selective Search
| 항목 | Sliding Window | Selective Search |
|---|---|---|
| 방식 | 전수 탐색 | bottom-up 병합 기반 |
| 속도 | 매우 느림 | 빠름 (2000개로 제한) |
| 특징 | 학습 불필요 | 비학습 기반 |
🔎 Fine-tuning 할 때랑 SVM 훈련할 때 P/N 기준이 다른가?
fine-tuning은 양성 샘플을 넉넉하게 쓰고 SVM은 확실한 샘플만 써서 더 날카롭게 훈련시키기 때문
CNN fine-tuning
CNN은 proposal을 받아 "여기 고양이가 있나?"를 스스로 판단하도록 미세 조정(fine-tuning) 함
학습 시 positive sample이 많이 필요한데 GT 박스만 양성으로 쓰면 부족함
그래서 IoU ≥ 0.5인 박스는 전부 양성으로 사용
-> 예: 정답 박스랑 0.6 정도 겹치는 proposal도 "고양이 있음"으로 학습
negative는 그보다 낮은 모든 박스 사용
장점: 양성 샘플이 늘어나서 CNN이 더 일반화된 특징을 잘 학습할 수 있음
SVM 학습
CNN으로부터 특징 벡터를 뽑은 후, 그걸 입력으로 SVM 분류기를 따로 학습
여기서는 "이건 진짜 고양이야 vs 절대 고양이 아님"처럼 선명하게 판단할 수 있는 샘플 필요
- Positive: GT 박스만 사용
- Negative: IoU < 0.3인 박스만 사용
- IoU 0.3~0.5는 애매해서 무시
장점: 헷갈리지 않고 명확한 샘플로 학습해서 SVM의 결정 경계가 더 날카로워짐
🔎 R-CNN이 느린 이유는?
이미지당 proposal 2000개 x CNN 인퍼런스 1번씩 수행
-> 연산량 매우 큼 (GPU에서도 13초/image)
따라서 Fast R-CNN, Faster R-CNN이 등장해 이 구조를 최적화
🔎 End-to-End 학습이 불가능한 이유는?
R-CNN은 세 파트(CNN, SVM, BBox Reg)가 따로 훈련됨
미분이 전체로 연결되지 않아 end-to-end backpropagation이 안됨
