[FCN 논문]
“Fully Convolutional Networks for Semantic Segmentation” Jonathan Long, Evan Shelhamer, Trevor Darrell (CVPR 2015)
https://arxiv.org/abs/1411.4038
논문 요약
기존 이미지 분류용 CNN을 픽셀 단위 의미론적 분할(Semantic Segmentation)에 맞게 완전히 컨볼루션 층으로만 재설계한 구조입니다.
핵심 아이디어
1️⃣ 기존 CNN의 Fully Connected 층을 1x1 Convolution으로 대체해 입력 크기에 관계없이 공간적 특성을 유지하며 dense한 픽셀별 예측이 가능하도록 합니다.
2️⃣ 깊은 네트워크를 통해 축소된 저해상도 feature map을 Transposed Convolution으로 원래 해상도로 업샘플링하여 픽셀 단위의 class score map을 생성합니다.
특징
중간 해상도의 feature map을 활용하는 skip connection을 도입해 coarse한 예측의 공간적 세부 정보를 보완함으로써 더 정밀한 분할 결과를 얻습니다.
sliding window 방식의 비효율성을 극복하며 입력의 크기에 구애받지 않고 end-to-end로 학습 가능한 semantic segmentation으로 평가받습니다.
개념 설명
1️⃣ Semantic Segmentation
이미지의 모든 픽셀에 대해 클래스(label)를 예측하는 문제
기존의 CNN의 한계를 넘어 픽셀 단위로 의미를 해석하는 최초의 완전한 컨볼루션 구조를 제공한 모델
2️⃣ Sliding Window vs FCN
Sliding Window
이미지 내의 작은 고정 크기 영역(patch)을 하나씩 잘라내어 각 패치마다 CNN을 따로 적용해 분류하는 전통적 방법
고정 크기의 윈도우를 이미지 위에서 일정한 간격으로 이동시키며 각 위치에서 모델을 적용하여 객체나 패턴을 탐지하는 방식입니다.
중복 계산이 많고 비효율적이며 고정된 입력 크기를 요구하고 객체 경계가 부정확할 수 있습니다.

FCN
입력 이미지의 각 픽셀에 대해 예측을 수행하는 방식
전체 이미지를 한 번에 처리하며 중복 계산을 줄이고 다양한 크기의 입력을 처리할 수 있으며 픽셀 단위의 정밀한 예측이 가능합니다.

3️⃣ FC Layer -> 1x1 Conv
FC Layer의 한계
기존 CNN에서는 마지막에 flatten -> FC layer로 클래스 벡터를 출력하게 됩니다.
이렇게 되면 위치 정보는 다 사라지고 "무엇이 있는가"만 예측할 수 있게 됩니다.
1x1 Convolution으로 대체
FC layer는 사실상 전 채널에 가중치를 곱해 하나의 벡터로 만드는 연산입니다.
이걸 공간을 유지한 채로 적용하기 위해 1x1 convolution으로 대체했습니다.
이렇게 변경한 덕분에 모든 위치에 대해 동시에 예측(dense prediction) 가능하고 각 픽셀에 대해 어떤 클래스인지 판단할 수 있게 됐습니다.
Dense prediction이란?
입력 이미지의 각 픽셀 위치마다 출력(예측)을 생성하는 문제 구조
출력이 이미지와 같은 해상도를 갖고 공간적으로 조밀하게 구성되는 예측 방식
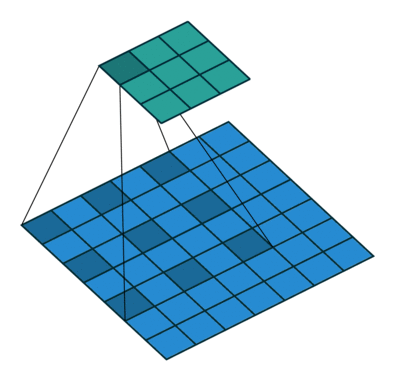
4️⃣ Transposed Convolution
VGG-16은 conv+pool을 반복하여 해상도를 축소합니다.
(예: 224x224 -> 112 -> 56 - 28 -> 14 -> 7) -> 최대 32배 감소 (stride=32)
이때 축소된 해상도를 복원하기 위해 Transposed Convolution을 사용하게 됩니다.
이는 축소된 feature map을 다시 upsampling해서 원래 해상도로 복원하는 역할입니다.
학습 가능한 가중치를 갖는 업샘플링이므로 단순 보간(Bilinear)보다 표현력이 높습니다.
Bilinear Interpolation이란?
비학습 업샘플링 방식입니다. 계산 속도가 빠르다는 장점이 있지만 디테일 복원이 불가하고 경계가 흐릿하게 표현되고 표현력이 제한된다는 치명적인 단점이 존재합니다.

Transposed Convolution 방식
작은 feature map을 입력받아 커널을 "거꾸로 적용"해 더 큰 출력(feature map)을 생성하는 연산입니다.
출력 크기
출력 해상도 = Stride(입력 해상도 - 1) + 커널 - 2 x 패딩
작동 방식
1️⃣ Zero Insertion (Zero Padding between pixels)
입력 feature map의 픽셀 사이에 0을 삽입해 크기를 확장합니다.
(예: stride=2이면 픽셀 사이에 1칸씩 0을 삽입)
2️⃣ Normal Convolution 적용
확장된 입력에 일반 convolution처럼 커널을 sliding합니다.
padding = 1, stride = 2를 준 Transposed Convolution 작동 방식
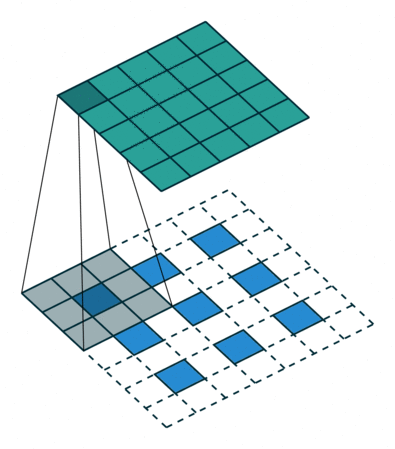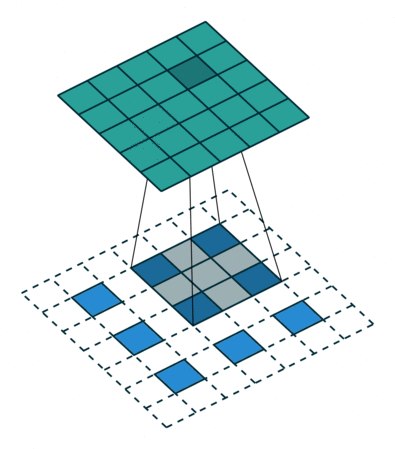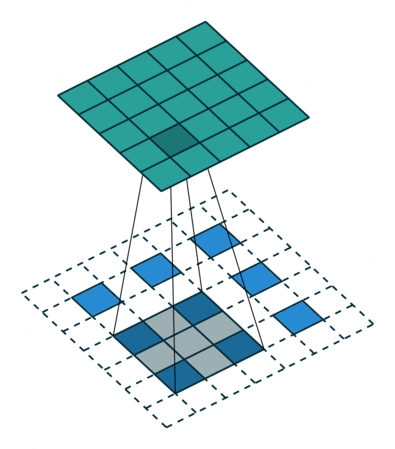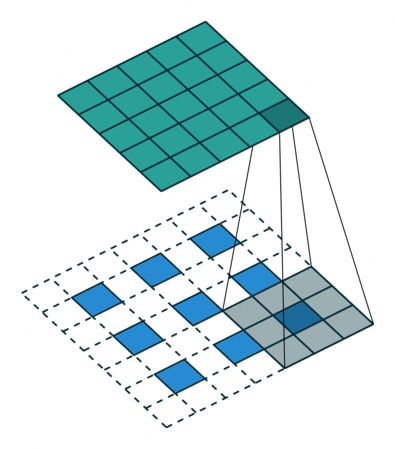
출처: https://github.com/vdumoulin/conv_arithmetic?tab=readme-ov-file
Transposed인 이유
nn.ConvTranspose2d(in_channels, out_channels, kernel_size, stride, padding, output_padding)이때 내부 weight의 shape은
(out_channels, in_channels, kernel_size, kernel_size)-> 일반 conv와 in/out_channels 순서가 바뀌어 있습니다.
커널 내부 값들의 형태나 패턴이 정해져있는가? X
모든 커널 값들은 일반 Convolution처럼 랜덤 초기화되고 학습 과정에서 최적화됩니다.1) 보통 Xavier, He, Kaiming 초기화로 랜덤하게 초기화됨
2) 학습 초기에는 불규칙한 값들로 채워져 있음
3) 학습이 진행되면서 업샘플링에 적합한 방향성 있는 패턴을 자동으로 학습
5️⃣ FCN-32s, FCN-16s, FCN-8s 구조와 Skip Connection
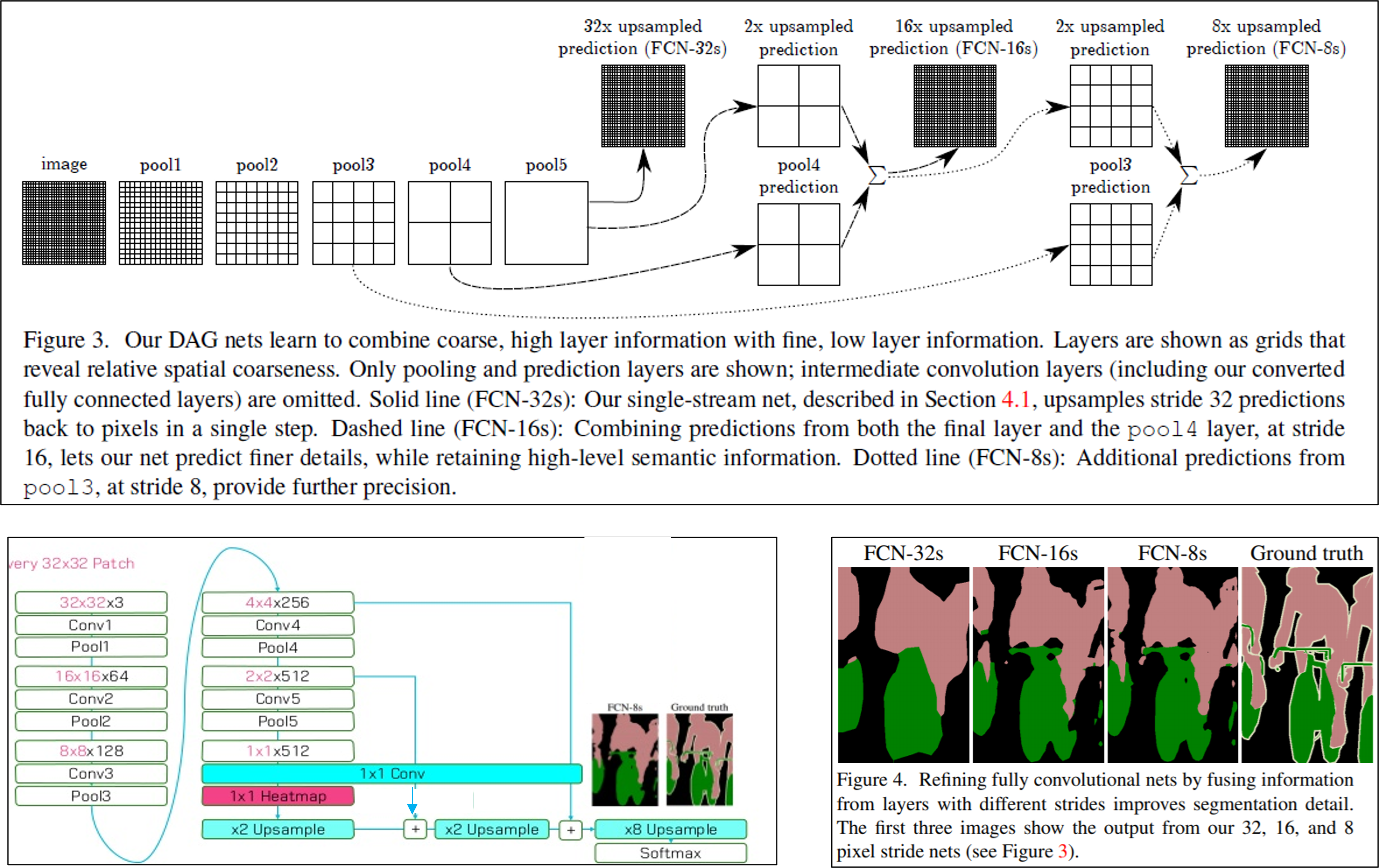
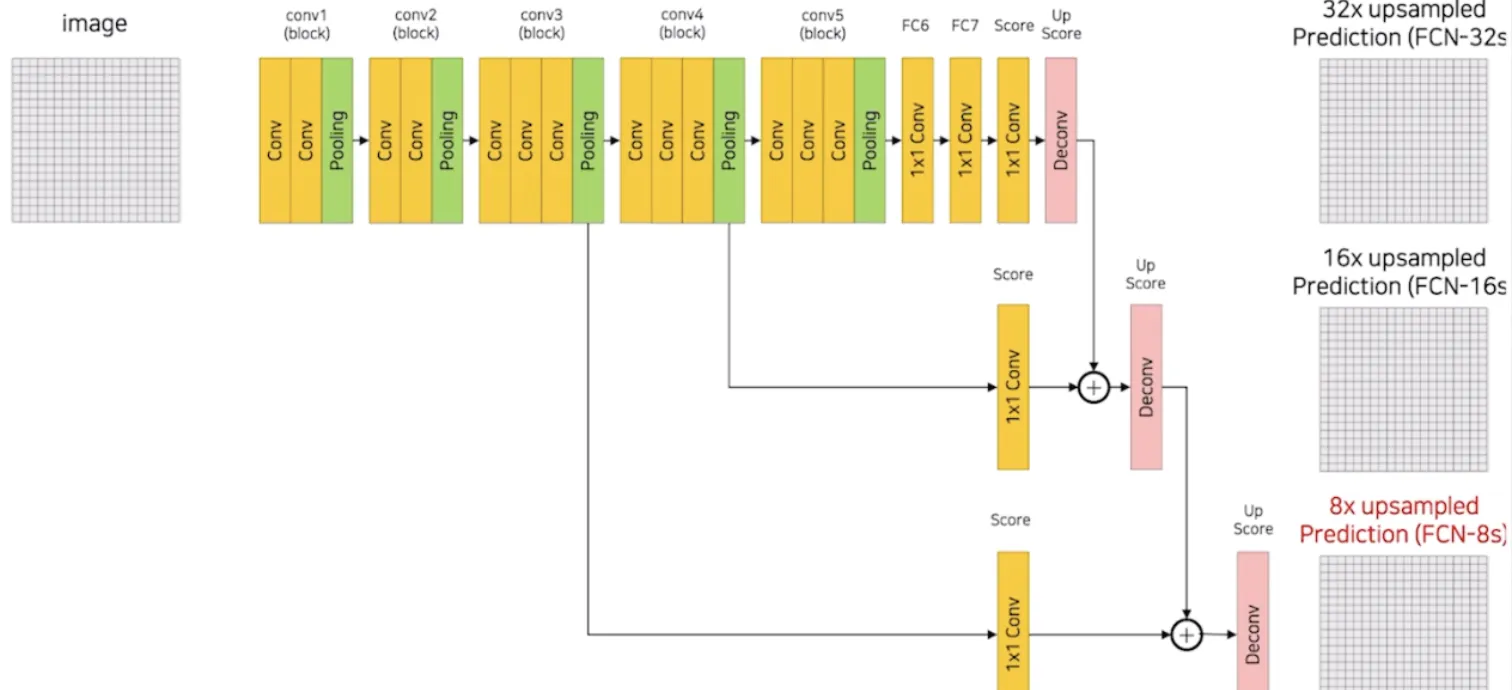
FCN-32s
Input (e.g. 224×224 RGB)
↓
VGG-16 conv layers → 마지막 feature map: 7×7×512
↓
1×1 conv (num_classes) → score map: 7×7×21
↓
Transposed Conv (stride=32, kernel=64) → 224×224 복원
↓
Pixel-wise Softmax특징
- Skip connection 없음
- 한 번에 coarse한 feature를 32배 upsampling
- 가장 간단한 구조지만 출력이 흐릿함
FCN-16s
Input
↓
VGG-16 conv layers
↓
pool5 → 1×1 conv → score map (7×7)
↓
Transposed Conv (stride=2) → 14×14
+ element-wise sum with pool4 (1/16 해상도)
↓
Transposed Conv (stride=16) → 224×224특징
- skip connection 1개: pool4 사용
- pool5의 coarse 정보 + pool4의 finer 정보 결합
- 출력 경계가 더 정밀해짐
FCN-8s
Input
↓
VGG-16 conv layers
↓
pool5 → 1×1 conv → score map (7×7)
↓
Transposed Conv (stride=2) → 14×14
+ element-wise sum with pool4
↓
Transposed Conv (stride=2) → 28×28
+ element-wise sum with pool3
↓
Transposed Conv (stride=8) → 224×224특징
- skip connection 2개: pool4, pool3 사용
- shallow feature 활용해 위치 정보/경계 보정
- 가장 정밀한 FCN 구조
6️⃣ 평가 지표(IoU)
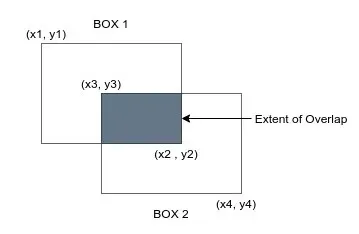
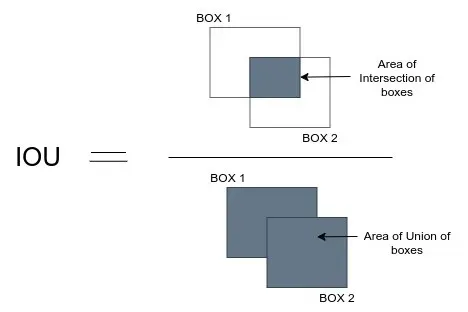
여러 클래스가 있을 경우 클래스별 IoU를 구한 뒤 평균을 냅니다.
- 객체가 많은 클래스와 적은 클래스 모두 동일하게 반영되므로 클래스 불균형에 덜 민감합니다.
7️⃣ FCN의 한계
1️⃣ 출력 해상도가 낮음 (coarse prediction)
FCN의 기본 구조는 VGG와 같은 classification backbone을 기반으로 합니다.
따라서 Conv + Pooling이 반복되어 입력 대비 32배나 축소된 coarse feature map이 생성됩니다.
이 작은 feature map을 Transposed Convolution으로 upsampling하지만 결과적으로 픽셀 단위의 예측이 부정확하거나 경계가 흐릿하게 보입니다.
2️⃣ 객체 경계 불명확 (blurred boundaries)
깊은 레이어일수록 의미는 강하지만 위치 정보는 약해집니다. (semantic-rich, spatial-poor)
FCN은 low-level feature의 위치 정보가 부족하므로 객체 경계(sharp edge) 표현이 부족합니다.
특히 얇은 객체나 경계가 중요한 경우(예: 의료영상, 도로 차선)에 치명적입니다.
3️⃣ skip connection의 단순 결합
단순한 Element-wise sum으로 결합하므로 shallow와 deep feature 간의 의미 불일치 또는 정보 손실이 발생합니다.
이에 대해서는 이후 U-Net처럼 concat 후 conv로 보완하는 방식으로 발전됐습니다.
4️⃣ 모양 다양성(object shape variation)에 취약
FCN은 고정된 필터와 고정 receptive field를 기반으로 하기 때문에 다양한 크기/형태의 객체에 적응력이 부족하다는 단점이 있습니다.
이에 대해서는 이후 DeepLab의 ASPP(Atrous Spatial Pyramid Pooling) 등 멀티스케일 대응 방식으로 발전됐습니다.
5️⃣ 인스턴스 구분 불가(instance-unaware)
픽셀에 class는 부여하지만 동일 클래스 내 다른 객체 구분은 할 수 없습니다.
이에 대해서는 Mask R-CNN, Panoptic Segmentation을 통해 객체까지 구분할 수 있게끔 발전됐습니다.
8️⃣ FCN 코드 구현
FCN 공통 기반 (VGG-16 Feature Extractor)
import torch
import torch.nn as nn
import torchvision.models as models
class VGGBackbone(nn.Module):
def __init__(self, pretrained=True):
super().__init__()
vgg = models.vgg16(pretrained=pretrained)
features = list(vgg.features.children())
self.stage1 = nn.Sequential(*features[:5]) # relu1_2
self.stage2 = nn.Sequential(*features[5:10]) # relu2_2
self.stage3 = nn.Sequential(*features[10:17]) # relu3_3
self.stage4 = nn.Sequential(*features[17:24]) # relu4_3
self.stage5 = nn.Sequential(*features[24:31]) # relu5_3
def forward(self, x):
x1 = self.stage1(x)
x2 = self.stage2(x1)
x3 = self.stage3(x2)
x4 = self.stage4(x3)
x5 = self.stage5(x4)
return x3, x4, x5 # skip용으로 3, 4, 5단계 반환FCN-32s
class FCN32s(nn.Module):
def __init__(self, num_classes):
super().__init__()
self.backbone = VGGBackbone()
self.classifier = nn.Conv2d(512, num_classes, kernel_size=1)
self.upsample = nn.ConvTranspose2d(
num_classes, num_classes, kernel_size=64, stride=32,
padding=16, bias=False
)
def forward(self, x):
_, _, x5 = self.backbone(x)
score = self.classifier(x5)
upsampled = self.upsample(score)
return upsampledFCN-16s (skip from pool4)
class FCN16s(nn.Module):
def __init__(self, num_classes):
super().__init__()
self.backbone = VGGBackbone()
self.score_pool4 = nn.Conv2d(512, num_classes, kernel_size=1)
self.score_final = nn.Conv2d(512, num_classes, kernel_size=1)
self.upsample2x = nn.ConvTranspose2d(num_classes, num_classes, 4, stride=2, padding=1, bias=False)
self.upsample32x = nn.ConvTranspose2d(num_classes, num_classes, 32, stride=16, padding=8, bias=False)
def forward(self, x):
_, x4, x5 = self.backbone(x)
score = self.score_final(x5)
upscore2 = self.upsample2x(score)
score_pool4 = self.score_pool4(x4)
fuse = upscore2 + score_pool4
out = self.upsample32x(fuse)
return outFCN-8s (skip from pool3)
class FCN8s(nn.Module):
def __init__(self, num_classes):
super().__init__()
self.backbone = VGGBackbone()
self.score_pool3 = nn.Conv2d(256, num_classes, kernel_size=1)
self.score_pool4 = nn.Conv2d(512, num_classes, kernel_size=1)
self.score_final = nn.Conv2d(512, num_classes, kernel_size=1)
self.upsample2x = nn.ConvTranspose2d(num_classes, num_classes, 4, stride=2, padding=1, bias=False)
self.upsample4x = nn.ConvTranspose2d(num_classes, num_classes, 4, stride=2, padding=1, bias=False)
self.upsample8x = nn.ConvTranspose2d(num_classes, num_classes, 16, stride=8, padding=4, bias=False)
def forward(self, x):
x3, x4, x5 = self.backbone(x)
score = self.score_final(x5)
score = self.upsample2x(score)
score += self.score_pool4(x4)
score = self.upsample4x(score)
score += self.score_pool3(x3)
out = self.upsample8x(score)
return out