💡 논문 정보
논문 : Focal Loss for Dense Object Detection
저자 : Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, Piotr Dollár
출처 : ICCV 2017, Facebook AI Research (FAIR)
논문 링크 : https://arxiv.org/pdf/1708.02002
💡 문제 정의 및 연구 동기
1️⃣ 객체 탐지(Object Detection)의 두 가지 접근 방식
객체 탐지기는 입력 이미지에서 객체의 위치(Bounding Box)와 클래스(Label)를 예측하는 모델
Two-stage Detector
대표 모델 : R-CNN, Fast R-CNN, Faster R-CNN
1단계 : 후보 영역(Region Proposal) 생성
2단계 : 각 영역에 대해 분류 및 박스 회귀 수행
장점 : 높은 정확도
단점 : 속도가 느림
One-stage Detector
대표 모델 : YOLO, SSD
전체 이미지를 grid처럼 나누어 **한 번에 객체 탐지**
장점 : 매우 빠름
단점 : 정확도는 two-stage에 비해 낮음
2️⃣ One-stage Detector의 한계 : 클래스 불균형
수많은 앵커(anchor)에 대해 대부분이 배경(background) 이기 때문에 문제 발생
양성 샘플(positive) : 실제 객체를 포함한 anchor (매우 적음)
음성 샘플(negative) : 객체가 없는 anchor (매우 많음)발생하는 문제점
훈련 손실(loss)의 대부분이 easy negative에 의해 지배됨
모델이 모든 영역을 배경으로 분류하는 보수적 학습을 하게 됨
정확한 객체 탐지가 어려워짐
3️⃣ 연구 목표
❓ “왜 one-stage detector는 two-stage보다 정확도가 낮은가?”
결론
원인은 모델 구조가 아니라 훈련 과정에서의 클래스 불균형임
해결책은 손실 함수 자체에 존재
따라서 기존 cross-entropy 손실의 한계를 분석하고 새로운 손실 함수인 Focal Loss를 제안하여 One-stage 모델인 RetinaNet을 통해 정확도와 속도의 균형을 달성하고자 함
💡 Focal Loss 정의 및 직관
1️⃣ 클래스 불균형 문제 : Cross Entropy
객체 탐지에서 수많은 negative anchor는 모델 학습에 방해가 됨
기존 Cross Entropy 손실 수식 :
- : 예측 확률이 정답 클래스일 경우의 확률(정답 클래스가 1이고 모델이 0.95확률로 예측했다면 0.95)
문제점
이미 정확하게 분류된 쉬운 예제도 높은 loss를 유발
negative anchor가 많으므로 전체 loss에서 지배적
2️⃣ Focal 수식
Focal Loss는 Cross Entropy에 modulating factor 를 곱하여 easy sample의 loss를 줄임
- : 정답 클래스일 확률
- : 조절 계수 (focusing parameter), 일반적으로 2 사용
- : 클래스 불균형을 보정하는 weight factor (optional)
3️⃣ 직관 요약
| 예시 | 영향 | ||
|---|---|---|---|
| Easy positive | 0.95 | 매우 작음 → loss 거의 0 | 무시됨 |
| Hard positive | 0.1 | 큼 → loss 유지됨 | 집중됨 |
| Easy negative | 0.99 | 매우 작음 | 억제됨 |
| Hard negative | 0.3 | 중간 | 집중됨 |
쉬운 샘플은 무시하고 어려운 샘플에 집중하도록 유도
4️⃣ γ (gamma)의 영향 실험
γ가 0일 때 -> 일반 cross-entropy
γ가 높을 때 -> easy 예제 무시 비율 증가
일반적으로 γ = 2가 best 결과를 보임
5️⃣ α (alpha) balancin
클래스 불균형을 보정하는 weight
positive class에 α = 0.25, negative class에 1 - α = 0.75 사용
(기존 class-balanced CE 손실과 유사한 개념)
6️⃣ Focal Loss의 핵심 효과
easy negative가 loss에서 차지하는 비중을 줄임
학습 효율을 높이고 모델이 진짜 객체(positive anchor)에 집중하게 만듦
따라서 one-stage detector에서도 높은 정확도 가능하게 만듦
💡 RetinaNet 구조 분석
1️⃣ One-stage Detector의 재정의
Backbone : ResNet-50 또는 ResNet-101
Feature Extractor : FPN (Feature Pyramid Network)
Head Subnet : Classification Subnet(anchor 클래스 예측), Regression Subnet(bbox 예측)
2️⃣ Feature Pyramid Network (FPN)
객체 탐지는 다양한 크기의 객체에 대응해야 하므로 멀티스케일 feature map 필요
FPN 구조
ResNet의 중간 feature (C3, C4, C5 등)를 상향 전파해 고해상도 정보 보존
상향(feature upsampling) + 측면 연결(lateral connection)을 통해 P3 ~ P7 pyramid 생성
| Pyramid Level | 해상도 (input 기준) | 역할 |
|---|---|---|
| P3 | 1/8 | 소형 객체 탐지 |
| P4 | 1/16 | 중형 객체 탐지 |
| P5 | 1/32 | 대형 객체 탐지 |
| P6, P7 | 1/64, 1/128 | 매우 큰 객체 / 앵커 다양화 |
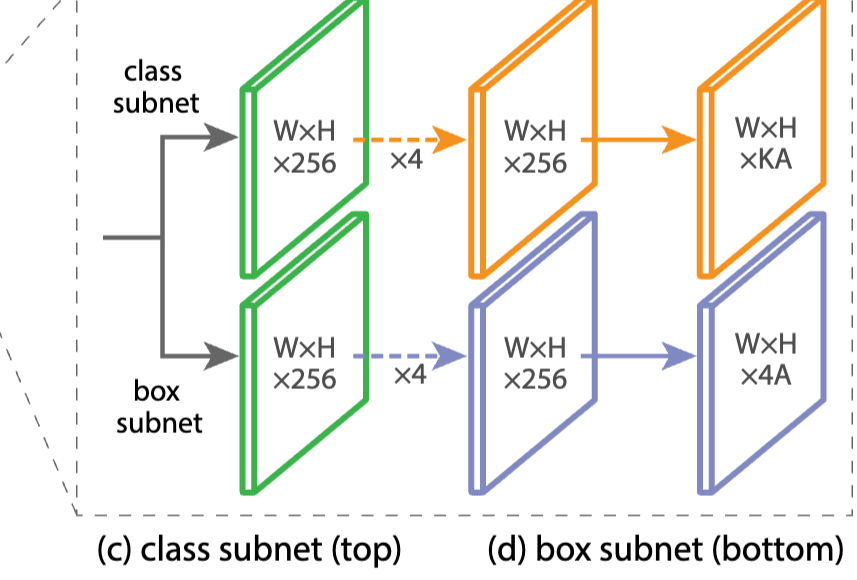
3️⃣ Subnet 구조 (Head)
각 FPN 레벨(P3~P7)에 대해 동일한 구조의 Subnet 2개를 적용
🔧 Classification Subnet
- 4개의 3x3 Conv + ReLU
- 1개의 3x3 Conv -> 출력 (A : anchor 수, C : 클래스 수)
🔧 Regression Subnet
- 4개의 3x3 Conv + ReLU
- 1개의 3x3 Conv -> 출력 (x, y, w, h)
4️⃣ Anchor 설정
각 FPN level마다 anchor box를 미리 정의해 다중 객체 탐지 수행
| 설정 항목 | 값 |
|---|---|
| Anchor scale | |
| Aspect ratio | |
| 각 레벨당 anchor 수 | 9 (3 ratio × 3 scale) |
5️⃣ 장점
FPN으로 멀티 스케일 탐지 강화
Head subnet은 매우 얕고 공유 구조를 사용 -> 속도 향상
Focal Loss로 인해 정확도 문제까지 해결
💡 실험 설정 및 성능 비교 결과
1️⃣ 실험 환경 및 세부 설정
🔧 모델 학습 설정
| 항목 | 값 |
|---|---|
| Optimizer | SGD |
| Batch size | 16 |
| Learning rate | 0.01 |
| Weight decay | 0.0001 |
| Step schedule | [60k, 80k] |
| Total iterations | 90k |
🔧 하이퍼파라미터
- Focal Loss의 γ (gamma): 2
- α (alpha): 0.25 (positive anchor에 적용)
2️⃣ Focal Loss 효과 실험
Focal Loss의 γ 값을 변경하면서 어떻게 정확도(AP) 가 달라지는지 실험
| γ (gamma) 값 | AP (전체) | AP50 | AP75 |
|---|---|---|---|
| 0 (CE Loss) | 낮음 | 낮음 | 낮음 |
| 1.0 | 증가함 | ↑ | ↑ |
| 2.0 | 최고 성능 | 최고 | 최고 |
| 5.0 이상 | 과도하게 easy sample 무시 → 성능 저하 |
3️⃣ RetinaNet vs Faster R-CNN vs SSD
| Model | Backbone | AP | AP50 | FPS |
|---|---|---|---|---|
| RetinaNet | ResNet-101-FPN | 39.1 | 59.1 | 5.0 |
| Faster R-CNN | ResNet-101 | 36.2 | 59.1 | 2.0 |
| SSD513 | ResNet-101 | 31.2 | 51.2 | 6.6 |
RetinaNet은 Faster R-CNN보다 정확도 높고 SSD보다 성능-속도 균형이 우수
특히 AP50, AP75뿐 아니라 **소형 객체(AP_S), 중형 객체(AP_M), 대형 객체(AP_L) 모두에서 강함
4️⃣ RetinaNet의 학습 안정성
Focal Loss를 사용한 RetinaNet은 overfitting 없이 학습이 안정적
CE Loss만 썼을 때는 easy negative에 빠르게 overfit
Focal Loss + FPN + 간결한 서브넷 구조 = 속도·정확도 균형
💡 결론 및 영향력 요약
1️⃣ 실제 영향력
| 분야 | 영향 |
|---|---|
| 논문 인용 수 | 10,000+ 회 이상 (2024년 기준) |
| 후속 연구 | EfficientDet, CenterNet, FCOS 등 다수의 모델이 Focal Loss 또는 RetinaNet 구조를 기반으로 발전 |
| 산업 적용 | Edge 디바이스, 모바일, 실시간 객체 탐지 분야에서 폭넓게 활용됨 |
2️⃣ 한계 및 향후 과제
| 한계 | 설명 |
|---|---|
| 높은 연산량 | FPN + 다수의 anchor 사용으로 여전히 연산 부담 존재 |
| anchor 기반 구조 | anchor-free 방식(FoveaBox, FCOS 등)에 비해 설정 복잡성 있음 |
이 논문은 이후 anchor-free 객체 탐지기의 출현에도 영향을 주었으며 Dense prediction 문제 해결을 위한 출발점 역할을 함
