목표
AI공동경진대회 준비 및 VIS(Video Instance Segmentation) 관련 논문을 읽어보자.
사용 언어
Python
일정
4회차: 8/5 13:00 ~ 16:00
4회차 목표 : IDOL 논문 리뷰

등장 배경
- Online VIS 모델의 단점인 matching association 문제를 해결하여 더 높은 성능을 갖추기 위해 등장.
핵심 기술
- Contrastive learning
- 다른 frame 간의 동일한 instance의 유사성과 다른 Instance와의 차이를 학습 - Optimal transport method
- 모델이 예측한 class, bounding box와 ground truth에서 주어진 class, bounding box를 조합하여 cost 식 이용.
- cost 가 낮은 m1 개와 cost가 높은 m2 개를 각각 positive, negative로 설정하여 계산.
모델 구조
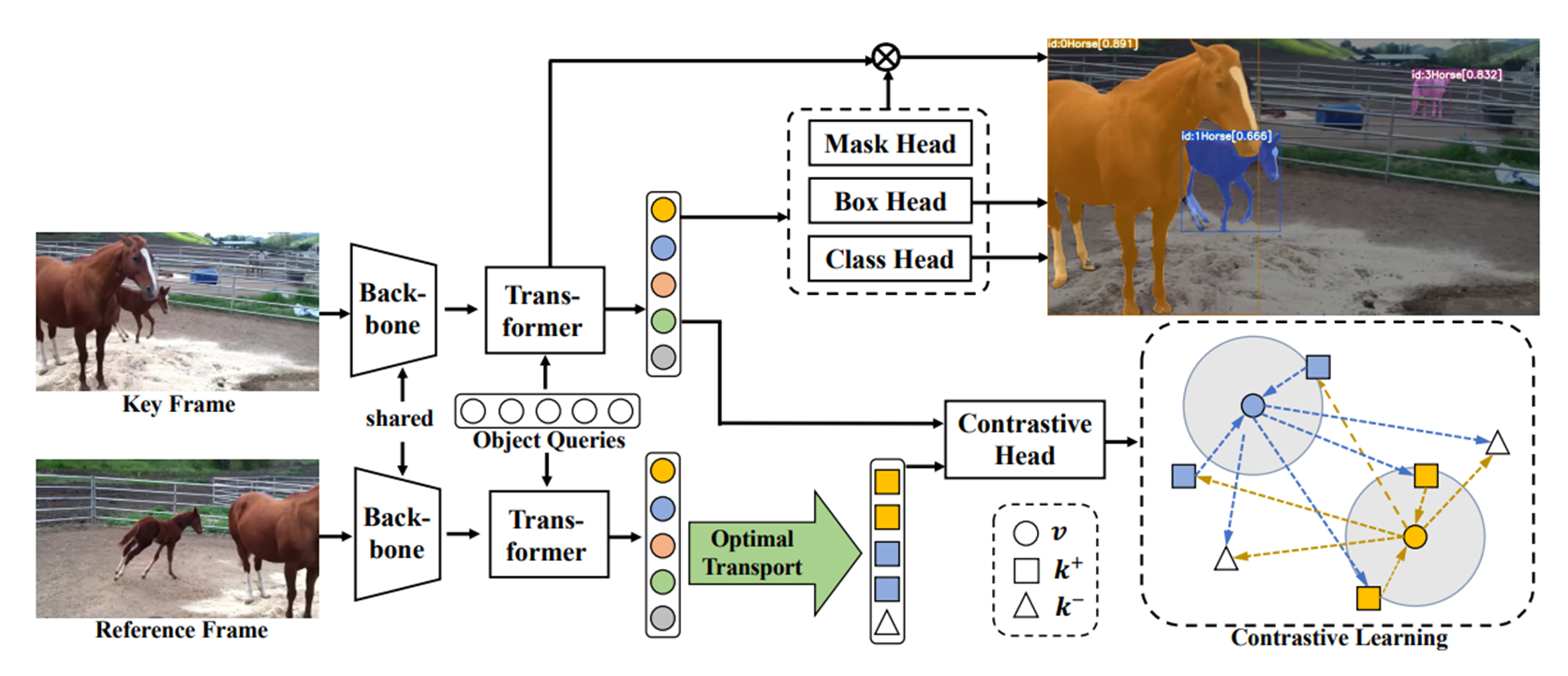
- Key Frame과 Reference Frame은 Backbone을 거친 후에 multi-scale feature maps을 생성하고 이를 Deformable Transformer의 input으로 이용.
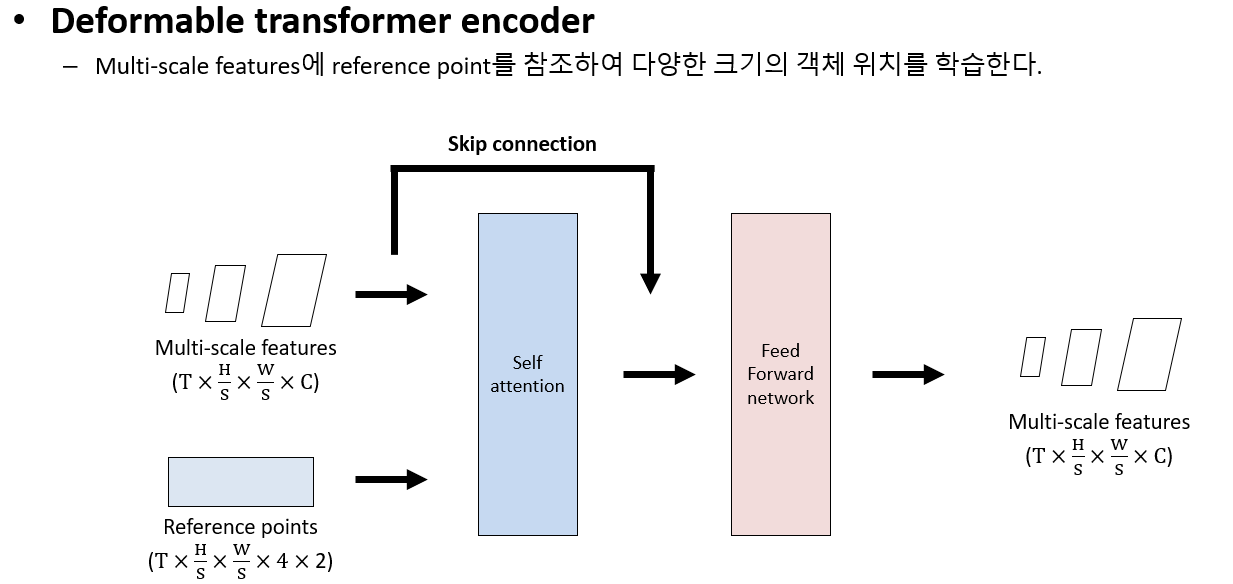
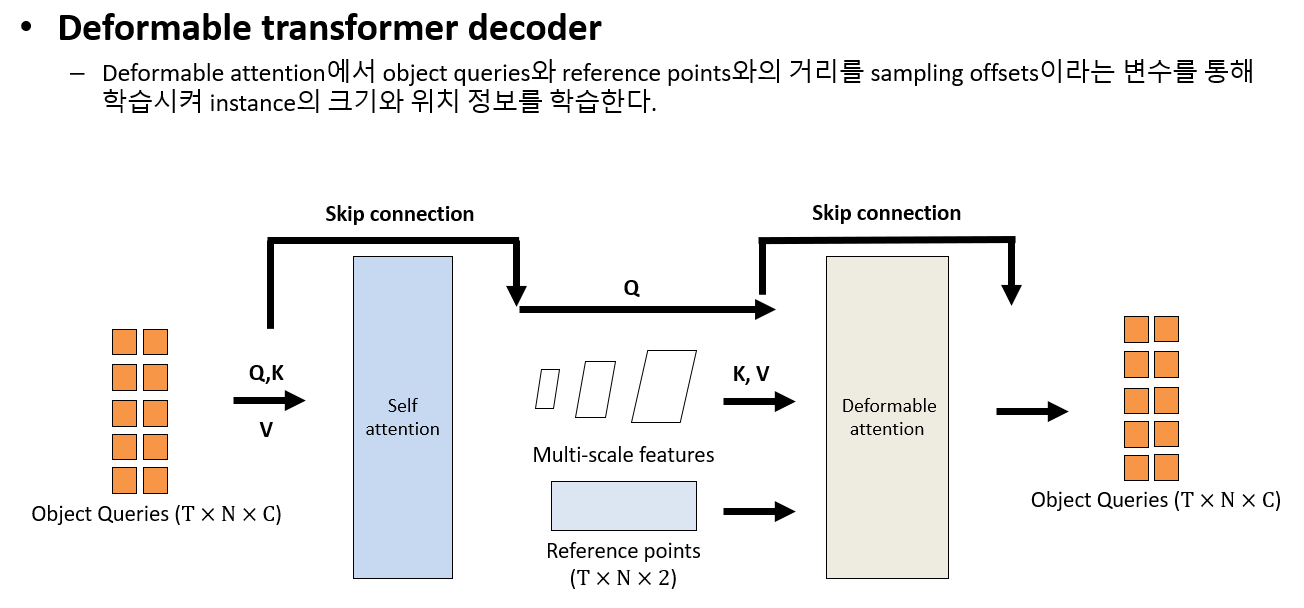


결과


Object Detection, Segmentation, Multi-Object Tracking