Binary Search Tree (이진 탐색 트리)
B-Tree에 대해서 이야기하기 전에 먼저 모든 트리구조의 근간이 되는 Binary Tree 자료구조에 대해서 알아야할 필요가 있다.
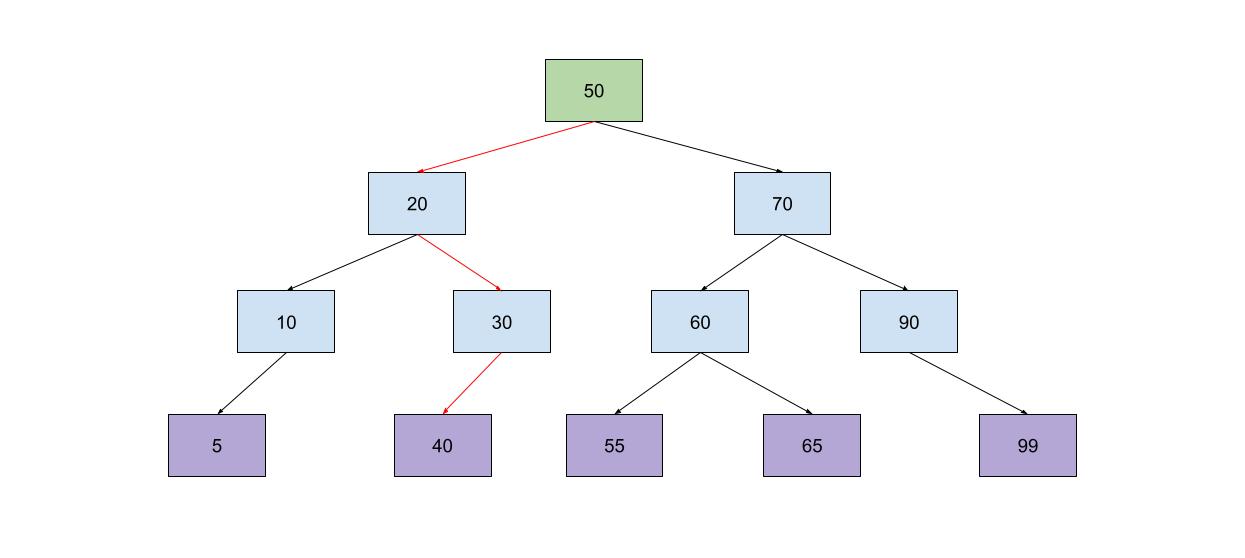
Binary 트리는 자식을 2개를 가질 수 있는 노드들로 구성되는 트리 형태의 자료구조이고, 아래와 같은 중요한 특징을 갖고 있다.
- 각 노드의 왼쪽 서브 트리에는 자신보다 작은 값들이 배치된다.
- 각 노드의 오른쪽 서브 트리에는 자신보다 큰 값들이 배치된다.
위와 같은 특징을 갖고 있다보니, 어떤 데이터를 풀스캐닝하는 것보다 상대적으로 빠른 속도로 찾을 수 있고, 데이터 탐색 속돈느 데이터의 양이 많을 수록 많이 나게 된다.
그래서 DB Index에서는 '이진 탐색 트리'를 업그레이드 한 B-Tree 또는 B+Tree 자료구조를 사용한다.
B-Tree
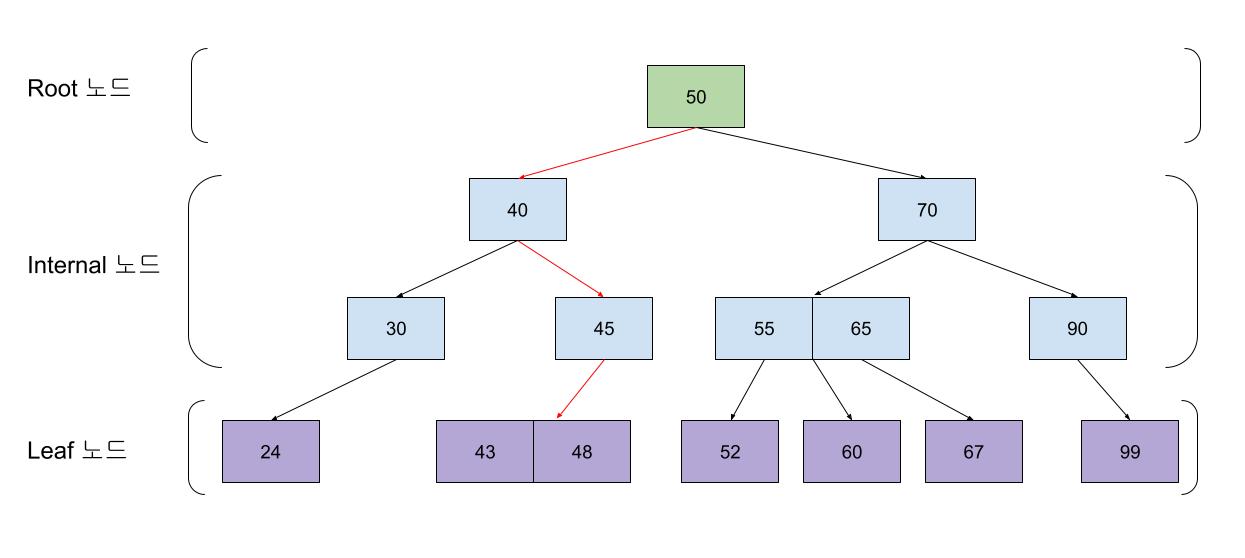
B-Tree는 Binary search tree(이진 탐색 트리)를 업그레이드한 자료구조로, 관계형 DB의 Index에서 자주 사용되는 자료 구조이다. 모든 Leaf노드가 동일한 레벨에 존해하는 특징을 갖고 있으며, 이진 탐색 트리는 2개의 자식 노드만 가질 수 있었던 것과 달리 B-Tree는 2개 이상의 자녀 노드를 가질 수 있다.

예를 들어서, 부모 노드에 55, 65라는 2개의 값이 저장되어 있다면, 자식 노드는 아래 3가지 케이스로 값을 구분해서 저장할 수 있는 것이다.
- 55보다 작은 값
- 55초과, 65 미만의 값
- 65보다 큰 값
즉, 부모 노드에 저장된 값이 N개 라면 그 하위 노드는 최대 N+1개의 노드를 가질 수 있게 된다.
이러한 특징으로 인해서 검색 성능과 뿐만 아니라 Binary search tree 자료구조에 비해서 데이터 관리의 효율도 증가하게 되는 것이다.
추가적으로, 하나의 노드에 여러 값이 저장되어 있는 경우 값들은 오름차순으로 정렬이 된다는 특징도 갖고 있다.
B+Tree
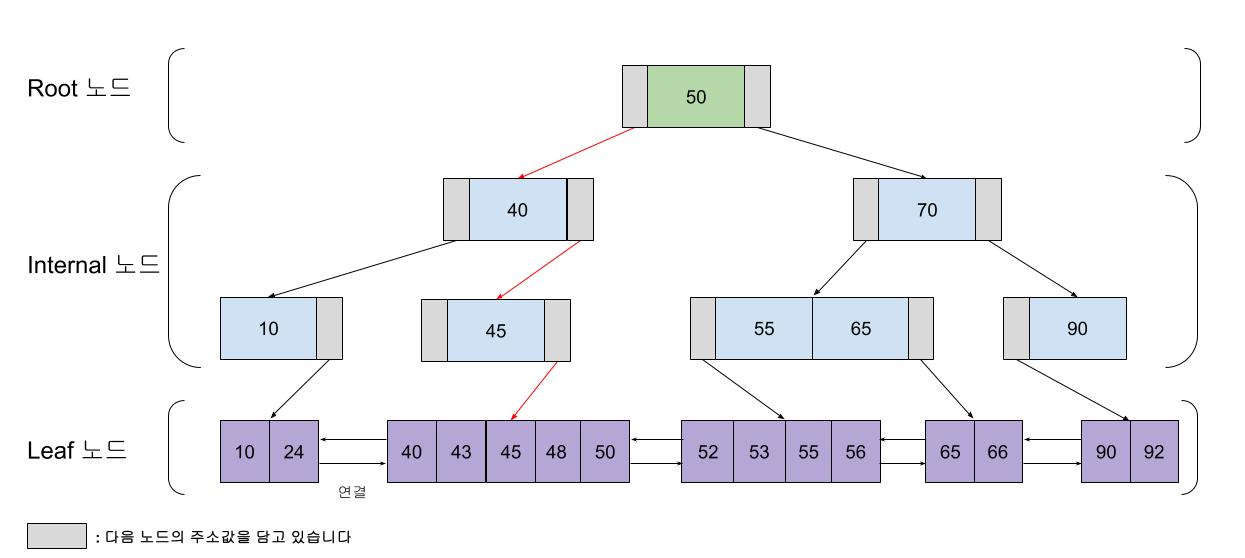
B-Tree에서 검색 성능을 한층 개선한 자료구조가 바로 B+Tree이다. 대표적으로 InnoDB엔진에서 Index를 관리할 때 B+Tree를 사용한다.
B-Tree보다 검색 연산이 빠르고, 범위 검색에 유용하다는 특징이 있다.
B-Tree의 범위 검색
A이상 B이하의 범위를 찾아야하는 상황이라고 가정해보자. 이 범위를 찾기 위해서는 당연하게도 A값의 위치와 B값의 위치를 알아야한다. 그래야 그 사이의 값들이 검색의 결과에 해당하는 범위인 것을 알 수 있기 때문이다.
B-Tree 자료구조에서 이러한 범위 검색을 수행한다고 생각해보면, 먼저 최상위 노드 부터 시작해서 A를 검색하게 될 것이다. 그리고 B를 찾을때도 마찬가지로 최상위 노드부터 올라가서 B를 찾아야한다. 즉, 최상위 노드부터 검색하는 과정(선형 검색)을 2번 반복해야하는 것이다.
B+Tree의 범위 검색
B+Tree는 B-Tree에서 Leaf 노드 간에 '연결성'이 추가된 자료구조이다. 즉, 하나의 A 또는 B중 하나만 선형 검색을 해서 위치를 알게 되면, Leaf 노드간의 연결성을 통해서 나머지 값을 탐색할 수 있는 것이다. 예를 들어서 A의 위치를 알게 되면 그 후부터는 현재 Leaf노드의 오른쪽 방향만 빠르게 탐색해서 B의 위치를 알 수 있는 것이다.
B-Tree VS B+Tree
위 설명만으로는 B+Tree가 더 나은 자료구조로 생각될 수 있지만, 각각의 장단점이 존재한다. 몇가지 관점에서 B-Tree와 B+Tree를 비교해보자.
-
메모리 효율 : B-Tree에서는 각 노드에 데이터의 주소값뿐만 아니라, 실제 데이터로 오름차순으로 정렬이 되어 있고, B+Tree에서는 Leaf노드에만 실제 데이터들이 저장되어 있다. 그래서 B-Tree보다 B+Tree가 메모리 효율 측면에서는 좀 더 좋다고 할 수 있다.
-
생성 및 삭제의 효율 : B+Tree는 Leaf노드 간에 '연결'을 나타내는 데이터도 추가적으로 관리되어야한다. 그래서 데이터의 생성, 수정, 삭제가 일어날 때는 B-Tree가 B+Tree보다 좀 더 좋은 성능을 일반적으로 보인다.
B 트리가 DB 인덱스로 사용되는 이유
데이터의 양과 시간 복잡도
DB의 데이터 양이 아주 적으면 인덱스를 사용해서 데이터를 검색하는 것은 테이블을 풀스캔을 하는 것보다 비효율적일 수 있다. 테이블을 풀스캔하는 것은 무식하지만 직관적이고 명료한 검색 방법인 것에 비해서 인덱스를 활용하는 것 데이터 검색은 관리할 데이터의 양이 늘어나고 비교적 고차원(?)적인 방법이여서 좀 더 복잡하기 때문이다. 하지만, 실무에서는 아주 작은 양의 데이터가 존재하는 테이블은 시스템 설정용 테이블 외에는 거의 없다. 그래서 인덱스는 필수적인 옵션이 되는 것이다.
데이터의 양을 이야기한 이유는 데이터 양에 따른 풀스캔의 치명적 단점을 이야기하고 싶어서인데, 당연하게도 풀스캔의 검색 속도는 데이터의 양이 늘어나는 것에 비례해서 증가하게 된다. 데이터의 양이 몇 몇 백만 건만 되도, 데이터 조회 기능을 사용자에게 제공하기 힘든 정도의 성능을 보여주게 된다.
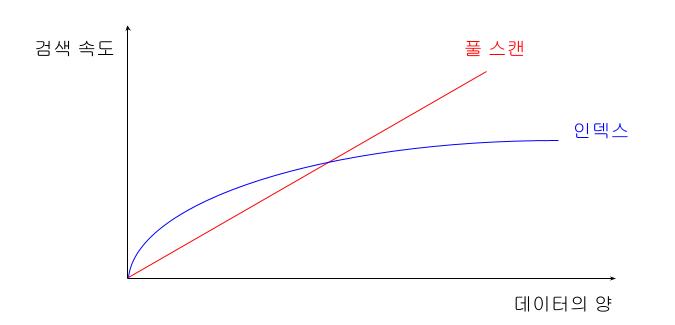
하지만, 인덱스를 사용하는 데이터의 경우 데이터 양이 증가해도 성능이 어느 정도 확보된다. 시간 복잡도를 그래프로 그린다면, 인덱스는 log 함수의 형태를 띄게 된다.
쉽게 이야기한다면, DB에서 인덱스를 사용하는 이유는 데이터 양이 많아지더라도 빠른 속도의 데이터 조회기능을 제공할 수 있기 때문인 것이다.
또, 풀스캔과 비교를 하지 않더라고, AVL과 같은 Binary search tree와 비교해도 훨씬 뛰어난 성능을 보여준다. 왜냐하면, 동일한 양의 데이터를 더 적은 노드의 Depth로 관리할 수 있고 그로 인해서 특정 데이터를 찾기 위해서 하드 디스크에 접근해야하는 횟수를 줄일 수 있기 때문이다.
범위 검색
HashMap 또는 HashTable과 같은 자료구조를 사용하면, 데이터의 양과 무관하게 데이터의 Hash값만 있으면 매우 빠른 속도로 데이터를 조회할 수 있다. 그런데 왜 이러한 자료구조는 DB에 사용되지 않는 것일까?
실제 서비스를 만들때는 당연하게도 단일 데이터 조회 뿐만 아니라 데이터의 범위를 조회해야하는 일이 매우 빈번하다. 사실 빈번하다고 말하는 것도 이상하게 들릴만큼 범위 검색은 당연히 성능이 보장되어야한다.
이러한 측면이 있기 때문에 Hash를 사용하는 자료구조는 적절하지 않게 되는 것이고, B트리 계열의 자료구조가 DB의 인덱스에는 사용되고 있다.

안녕하세요 여쭤보고 싶은것이 있는데요.
대표적으로 InnoDB엔진에서 Index를 관리할 때 B+Tree를 사용한다. 라고 말씀하셨는데, MySQL공식 Document에서 8.0, 8.4, 9.0을 봐도 B-Tree를 채택하고 있지, B+Tree를 사용하고 있다는 말은 제가 못찾고 있는데 혹시 어디서 찾을 수 있는지 여쭤봐도 되겠습니까 ?
MySQL공식문서에서는 "공간 인덱스를 제외하고 InnoDB인덱스는 B-tree 데이터 구조입니다. 공간 인덱스는 다차원 데이터의 인덱싱에 특화된 데이터 구조인 R-trees 를 사용합니다" 라고 명시되어있습니다.
공부하다가 혼란이 와서요 ㅜ