☕ Partitioning 이란?
어떠한 서비스든 오랜 시간 서비스를 운영하다보면 불가피하게 DB에 많은 양의 데이터들이 쌓이게 된다. 서비스의 형태와 트래픽의 양에 따라 다르겠지만, 몇 백만에서 몇 억개의 데이터는 엄청 성공한 서비스가 아니여도 생각보다 금방 쌓이게 된다.
이렇게 테이블이 비대해지기 시작하면, 여기 저기서 이슈들이 발생하게 된다.
이럴 때, 파티셔닝을 통해서 비대해진 테이블을 효율적으로 더 잘게 쪼개는 방법에 대해서 고민하게 되는데, 이렇게 작은 단위의 테이블로 쪼개는 것을 파티셔닝이라고 한다.
그렇다면, 어떠한 방법들로 비대해진 테이블을 파티셔닝할 수 있는지 알아보자.
📌 Vertical partitioning

Vertical 파티셔닝은 컬럼을 나누는 파티셔닝이다. 한 테이블에 너무 많은 컬럼을 들고 있다보면, 당연하게도 어떤 쿼리를 수행하든 DB입장에서는 더 부담스러워지게 된다. 그래서 자주 호출되는 컬럼을 다른 테이블로 쪼개거나 역할과 관심사를 좀 더 세분화해서 테이블을 쪼개는 방법을 생각해볼 수 있는데, 이를 Vertical partitioning이라고 부른다.
Vertical 파티셔닝의 대표적인 예시는 아래와 같은 상황들을 이야기할 수 있다.
- 테이블 정규화 : 비대한 컬럼을 갖고 있는 테이블을 역할과 관심사에 따라서 작은 단위의 테이블로 나눈다.
- 사용 빈도나 목적에 따른 파티셔닝 :
post라는 게시글을 저장하는 테이블이 있다고 해보자. 이 테이블에는 글의 본문을 저장하는content라는 컬럼이 있고,content는 게시글의 상세 페이지를 조회하는 API에서만 사용된다면,post에서content컬럼을 분리하게 되면,post테이블을 가볍게 만들 수 있게 된다. 이는post가 사용되는 쿼리들에 대해서 성능을 향상 시킬 수 있다.
요약하자면, Vertical 파티셔닝의 핵심은 비대해진 컬럼을 작은 단위의 테이블로 나누는 것이다.
📌 Horizontal partitioning

Vertical 파티셔닝으로 테이블을 아무리 쪼개도 무한대로 테이블을 쪼갤 수는 없기도하고, 시간이 지남에 따라서 데이터는 계속해서 쌓일 것이다. 그래서 언젠가는 하나의 테이블을 Row를 기준으로 여러 덩어리로 쪼개는 방법에 대해서 생각해보게 되는데, 이를 Horizontal 파티셔닝(이하 '파티셔닝')이라고 부른다.
Horizontal 파티셔닝의 원리
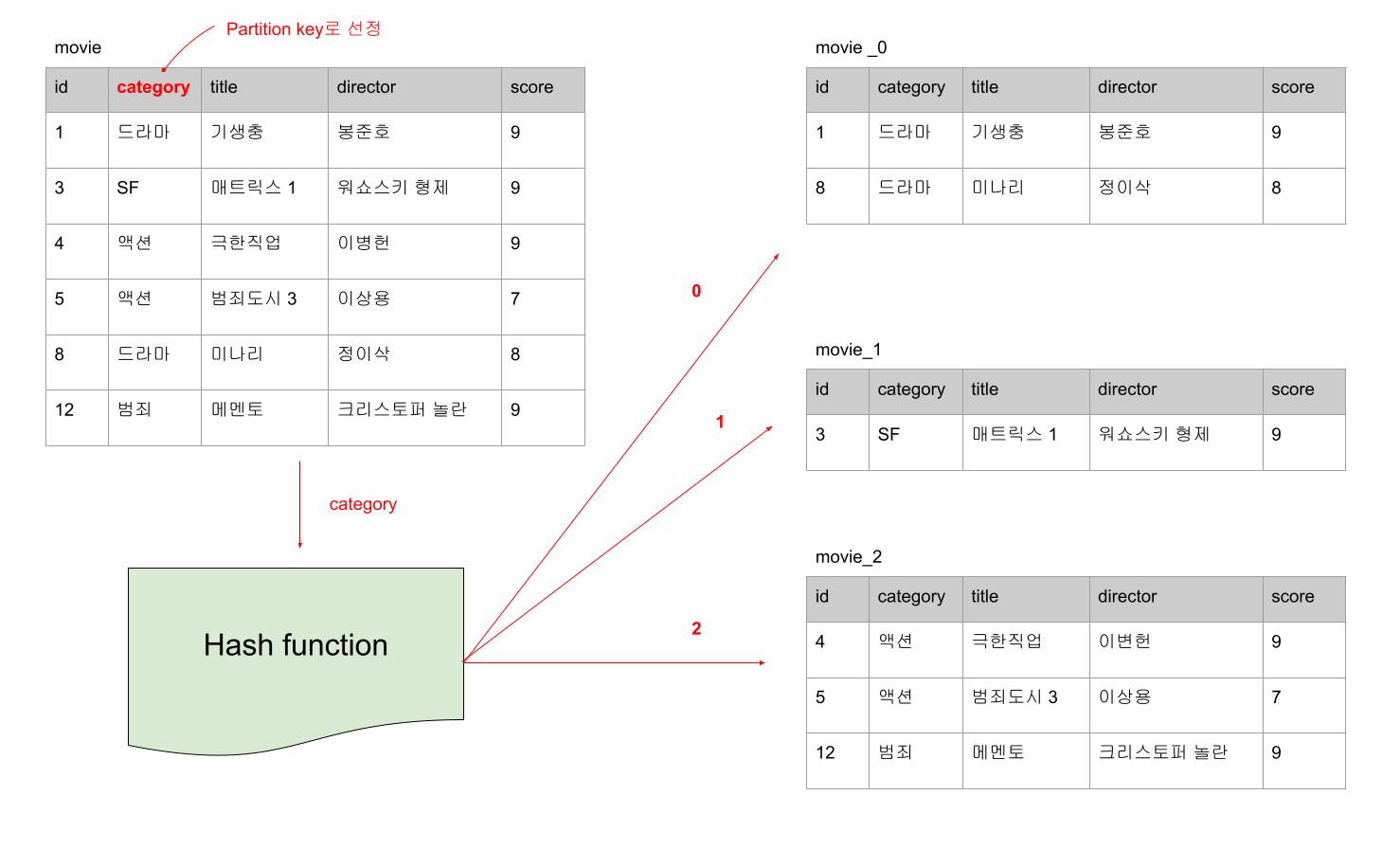
여러 파티셔닝 기법 중에서 Hash를 활용하는 방법을 기준으로 이야기해보겠다.
먼저, 테이블에서 파티셔닝의 기준이 될 컬럼을 정한다. 그리고, 그 값을 해싱하면 임의의 값이 만들어지게 되는데, 이 임의의 값이 해당 데이터가 위치할 파티션 테이블을 의미하게 된다.
쉽게 이야기해서 movie라는 테이블에서 category라는 컬럼을 Partion key로 선정했다면, 하나의 큰 테이블이 category를 해싱한 값을 기준으로 서로 다른 N개의 테이블로 나눠지게 된다는 것이다.
Partition key 정하기
파티셔닝에서 가장 중요한 것은 Partition key를 정하는 것이다. 파티셔닝은 한번 하게 되면 파티션 테이블들을 다시 합치거나 파티셔닝 기준을 수정하는 것은 쉬운 작업이 아니므로, 신중하게 Partition key를 선정해야한다.
Partition key를 정할 때는 해당 테이블이 기능적으로 어떻게 활용되고 있는지를 잘 고민해야하고, 무엇보다 해당 테이블이 검색 기능에서 어떻게 사용되는지가 가장 중요하다.
특정 컬럼으로 구분해서 자주 조회가 된다면, 그 특정 컬럼을 기준으로 파티셔닝을 하는 것이 좋은 방법일 수 있다. 그것보다 데이터의 생성 시간이 데이터를 구분하는 중요한 기준이 되는 종류의 데이터라면, 시간 순으로 파티셔닝을 하는 것도 좋은 방법이 될 수 있다.
파티셔닝의 장점과 단점
파티셔닝을 하게 되면, 논리적으로는 하나의 테이블이지만 물리적으로는 분리된 테이블로 된다. 데이터들 뿐만 아니라 인덱스도 모두 분리해서 각각 관리되게 된다.
이러한 특징이 바로 파티셔닝의 장점이자 단점이 되는데, 장점은 적은 수의 파티션을 참조해서 기능을 수행하게 되면 파티셔닝을 하기 전보다 높은 성능을 보일 것이고, 풀스캔과 같은 기능을 수행할 때는 오히려 파티셔닝을 하기 전보다 안 좋은 성능을 보일 수 있다는 것이다.
그래서 파티셔닝을 할 때, 한 후에 유의할 점은 내가 작성한 쿼리가 '얼만큼의 파티션 테이블을 참조할 것인가'이다.
파티셔닝을 사용할 때, 주의사항
- 파티션 테이블에서는 Foreign key를 사용할 수 없다.
- 파티션 테이블에서는 Full-Text search를 사용할 수 없다.
- 파티션 테이블에서는 '공간'을 나타내는 컬럼 타입(Point, Geometry)을 사용할 수 없다.
- 임시 테이블은 파티션 기능을 사용할 수 없다.
- 파티셔닝된 테이블에서 PK 또는 UNIQUE 인덱스를 생성할 때는 반드시 Partition key를 포함시켜주어야한다.
Ex)caetgory컬럼을 기준으로 파티셔닝된movie라는 테이블에서title이라는 컬럼에 대한 유니크 인덱스를 생성할 때는 아래와 같이 실행해야한다.CREATE UNIQUE INDEX `title_UNIQUe` on `movie` (`title`, `category`) PARTITIONED
👀 샘플 테이블 생성
CREATE TABLE `movie` (
`id` BIGINT(20) UNSIGNED NOT NULL AUTO_INCREMENT,
`category` VARCHAR(50) NOT NULL COLLATE 'utf8mb4_general_ci',
`title` VARCHAR(200) NOT NULL COLLATE 'utf8mb4_general_ci',
`director` VARCHAR(100) NOT NULL COLLATE 'utf8mb4_general_ci',
`score` INT(10) UNSIGNED NOT NULL DEFAULT '0',
PRIMARY KEY (`id`) USING BTREE
)
아래 섹션부터는 위 테이블을 샘플 테이블로 사용하도록 하겠다.
💡 범위(Range) 파티셔닝
범위를 기반으로 데이터를 여러파티션에 나누는 것을 의미하고, Partition key 위주로 자주 검색이 수행되는 경우 자주 사용된다.
시간 또는 날짜를 기반으로 파티셔닝하는 경우에 해당한다.
파티션 생성
ALTER TABLE `movie` PARTITION BY RANGE (id) (
PARTITION movie_p0 VALUES LESS THAN (100),
PARTITION movie_p1 VALUES LESS THAN (200),
PARTITION movie_p_max VALUES LESS THAN (MAXVALUE)
);파티션 병합
ALTER TABLE `movie` REORGANIZE PARTITION movie_p0, movie_p1 INTO (
PARTITION movie_p01 values less than (200)
);
OPTIMIZE TABLE `movie`; -- 테이블, 인덱스, 디스크 공간을 최적화한다.REORGANIZE PARTITION문을 사용해서 파티션 병합을 하게 되면, 데이터의 물리적인 이동이 발생한다. 즉, 대량의 데이터가 존재하는 테이블에서 파티션 병합을 하게 될 때는 충분한 테스트를 하고, 백업 데이터를 마련한 후 병합을 진행하는 것이 좋다.
파티션 삭제
ALTER TABLE `movie` DROP PARTITION `movie_p0`; 파티션 해제
ALTER TABLE `movie` REMOVE PARTITIONING;파티션 해제 시 주의할 점은 파티션을 해제했을 때 데이터들이 재정렬되는 것은 아니고, "파티션"만 제거가 된다. 그래서 데이터를 재정렬하고 싶다면, 동일한 컬럼 및 인덱스 설정을 갖고 있는 테이블을 하나 더 만들어서 테이블을 복사해주어야한다.
CREATE TABLE `movie_temp` AS SELECT * FROM `movie`;DROP TABLE `movie`;ALTER TABLE `movie_temp` RENAME TO `movie`;💡 리스트 파티셔닝
영화의 카테고리, 유저의 성별등등 고정적인 N개의 값으로 구성되는 컬럼을 Partition key로 선정하려고 할 때, 사용하기 적당한 파티셔닝 방법이다.
이렇게 선정한 Partition key를 기준으로 파티셔닝했을 때, 데이터들이 균일하게 파티셔닝이 될 수록 좋다.
리스트 파티셔닝에서 파티션 생성을 제외하고는 범위 파티셔닝과 동일하므로, 파티션 생성 문법만 알아보도록 하겠다.
파티션 생성
ALTER TABLE `movie` PARTITION BY LIST COLUMNS (`category`) (
PARTITION movie_p0 VALUES IN ('드라마'),
PARTITION movie_p1 VALUES IN ('액션'),
PARTITION movie_p2 VALUES IN ('SF', '범죄'),
PARTITION movie_p_default VALUES IN (DEFAULT)
);💡 Hash기반 파티셔닝
위에서 예시로 이야기한 파티셔닝 방법이다. Partition key로 선정된 컬럼의 값들을 해싱하여, 파티셔닝하려고하는 갯수로 모듈러 연산(나머지 연상, %)해서 데이터들을 파티셔닝하는 방법이다.
Range, List로 데이터를 적당히 나누기 힘든 경우 사용하고, 모든 컬럼이 검색에 고르게 사용되는 경우에 Hash기반 파티셔닝을 선택하기도 한다.
단, 한번 파티셔닝하면 파티셔닝을 다시 수정하는 경우엔 그 처리가 매우 까다로워서, 매우 신중하게 파티셔닝을 해야한다.
파티션 생성
ALTER TABLE `movie` PARTITION BY HASH(id) PARTITIONS 4;이렇게 하면, id컬럼을 Partition key로 선정해서 해싱하고, 해싱된 값은 4로 모듈러 연산이 된다. 결과적으로 4개의 파티션 테이블이 만들어지게 된다.
파티션 병합, 삭제, 해제등등은 위에서 언급한 문법들과 동일하므로 생략한다.
