🧐 LIKE 문을 활용한 검색 기능
SELECT * FROM table_A WHERE title LIKE '%something%'; 기본적으로 검색 쿼리를 구현한다고 하면, 가장 먼저 생각할 수 있는 게 LIKE문이다.
많은 양의 데이터가 있는 테이블이 아니고, 검색도 빈번하게 발생하는 게 아니라면 별 문제없이 검색 기능을 구현할 수 있다.
하지만, 데이터가 100만 건, 1000만 건 또는 억 단위가 되면 문제가 있을 수 있다.
왜 문제가 있을 수 있는 지 한번 살펴보도록 하자.
LIKE 문의 동작 방식
📌 table_A라는 테이블의 title이라는 컬럼에는 Index가 걸려있다고 가정한다.
SELECT * FROM table_A WHERE title LIKE 'something%';SELECT * FROM table_A WHERE title LIKE '%something'; SELECT * FROM table_A WHERE title LIKE '%something%'; LIKE 문은 특정 문자열의 포함 여부를 체크하는 기준에 따라서 3가지 형태로 구분할 수 있다. 여기서 중요한 점은 데이터의 앞부분에 문자열이 포함되는지 체크하는 경우에만 Index를 타게 된다는 점이다.
SELECT * FROM table_A WHERE title LIKE 'something%';즉, 이 쿼리는 title에 대한 Index가 데이터 조회에 사용되고,
SELECT * FROM table_A WHERE title LIKE '%something'; SELECT * FROM table_A WHERE title LIKE '%something%'; 이 쿼리들은 title에 대한 Index가 데이터 조회에 사용되지 않아서 테이블 풀스캔을 하게 되는 것이다.
왜 이렇게 동작하는 것일까?
LIKE와 Index
위에서 이야기한 것에 대해서 이해하려면, Index의 자료구조에 대해서 알아야 한다.
Index는 B-Tree 또는 B+Tree 자료구조로 관리가 되는데, B 트리는 기본적으로 데이터를 1,2,3 또는 ㄱ,ㄴ,ㄷ과 같은 오름차순 형태로 들고 있기 때문에 특정 문자열로 시작하는 데이터의 주소값은 알 수 있지만 그렇지 않은 경우엔 모든 테이블을 다 뒤져야만 조건에 만족하는 데이터를 찾을 수가 있다.
SELECT * FROM table_A WHERE title LIKE 'something%';예를 들어서 위와 같은 쿼리를 실행했다고 가정하고, MySQL 서버 안에서는 어떤 일이 벌어질지 생각해보자.
먼저 something으로 시작하는 데이터를 찾을 것이고, 그 이후에 데이터들 중에서 something으로 시작하지 않는 데이터를 찾게 될 것이다.
그러면, 그 사이의 데이터들은 모두 something으로 시작하는 데이터라는 것을 알 수 있는 것이다. 왜냐하면, 오름차순으로 데이터가 정렬되어 있기 때문이다. 우리가 사전에서 원하는 글자를 찾거나 도서관에서 원하는 도서를 찾는 과정과 매우 유사하다.
반면에, 특정 문자열이 something으로 끝나거나, 중간 어딘가에 something이 포함되어 있는 데이터를 찾으려면 모든 데이터를 뒤져야하는 방법 밖에 없다. 마찬가지로 데이터가 오름차순으로 정렬되어 있기 때문인 것이다.
LIKE문의 성능 이슈
보통 우리가 검색 기능을 구현할 때는 특정 문자열이 데이터에 포함되어 있는지의 여부에 따라서 데이터를 필터링한다.
SELECT * FROM table_A WHERE title LIKE '%something%';즉, 위와 같은 형태의 쿼리문을 수행한다는 것이고, 안타깝게도 테이블 풀스캔을 통해서 조건에 맞는 데이터를 찾는 수 밖에 없게 된다.
그렇기 때문에 데이터의 양이 매우 많은 테이블에 대해서 검색 기능을 제공하려면 Full-text search 기능을 활용하는 것이 바람직하다고 할 수 있다.
🔨 테이블과 데이터 준비하기
본격적응로 Full-Text Search에 대해서 알아보기 전에 테스트 목적의 테이블과 데이터를 만들어주자.
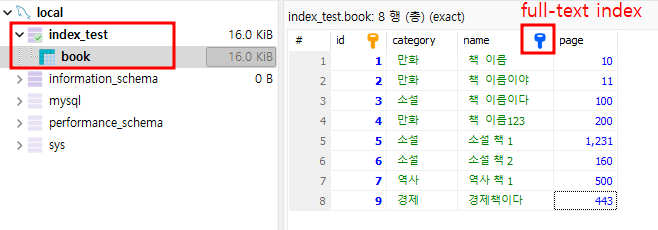
나는 아주 간단한 위와 같은 테이블과 데이터들을 조금 생성해보았다.
📌 Full-Text Index
💡 Full-Text Index는 MySQL진영에서는 InnoDB엔진과 MyISAM 엔진에서만 사용할 수 있고, CHAR나 VARCHAR와 같은 TEXT 타입의 컬럼에만 적용할 수 있다.
Full text search를 활용하기 위해선 해당 기능을 사용하고자 하는 컬럼에 Full-text index를 먼저 설정해줘야한다.
Full-Text Index 설정하기
1) Full text index 생성
CREATE FULLTEXT INDEX {인덱스 이름} ON {테이블} ({컬럼}); -- built in parser 사용또는
CREATE FULLTEXT INDEX {인덱스 이름} ON {테이블} ({컬럼}) WITH PARSER ngram; -- ngram parser 사용💡
Built in parser는 기본적으로 공백을 기준으로 단어를 구분해서 파싱하고,ngram parser는 하나의 문장을 최소 토큰 수만큼 모두 나눠서 기록을 한다.
예를 들어서, "안녕하세요 반갑습니다" 라는 문장이 있다면, Built in parser는안녕하세요,반갑습니다라고 파싱해서 인덱스를 생성하지만, ngram parser는안녕,녕하,하세,세요,요반,반갑,갑습,습니,니다와 같이 파싱을 한다.
그래서 실무에서는 아마도ngram parser를 사용해야하는 경우가 대부분일 것이고, 각자의 상황에 맞게 parser를 선택해서 사용하면 된다.
2) Index 제거
DROP INDEXT {인덱스 이름} on {테이블} ;3) Index 보기
SHOW INDEX FROM {테이블};위 쿼리들을 이용해서 Full text index는 쉽게 생성 및 삭제할 수 있다.
Full-Text Index의 모습(?)
위에서 생성한 샘플 테이블에 Full-Text index를 설정하고, 어떻게 Index 데이터가 이루어지는 지 확인해보도록 하자.
SET GLOBAL innodb_ft_aux_table = 'index_test/book'; # {db명/table명}
SELECT * FROM information_schema.innodb_ft_index_table;위 쿼리를 수행하면, Full-Text Index가 어떤 식으로 걸려있는지 확인해볼 수 있다.

InnoDB에서 Full-text indexing의 대상이 되는 글자 수는 3글자이상이여서 3글자이상으로 구성된 어절들만 인덱싱이 된 것을 확인할 수 있다.
Full-Text Index 최소 글자 수 조정
⭐⭐⭐ InnoDB 엔진에서는
innodb_ft_min_token_size가 최소 인덱싱 글자 수를 의미하고, 그 외의 엔진에서는ft_min_word_len이 그 역할을 한다. 그리고,built-in parser가 아니라ngram parser를 쓸 때는ngram_token_size가 최소 토큰 크기(인덱싱된 글자의 크기)를 의미한다.
SHOW VARIABLES LIKE 'innodb_ft_min_token_size';위 쿼리를 실행하면, 몇 글자부터 Indexing의 대상이 되는지 설정할 수 있다.
이제 아래 방법에 따라서 이 설정값을 2로 조정해보고, Full-Text Index의 데이터를 확인해보자.
1) conf 파일 위치로 이동
cd /etc/mysql/mysql.conf.d2) mysqld.conf에 설정값을 수정 또는 추가
vim mysqld.confinnodb_ft_min_token_size = 23) mysql 서버 재시작
service mysql restart4) 변수 조회
SHOW VARIABLES LIKE 'innodb_ft_min_token_size'; 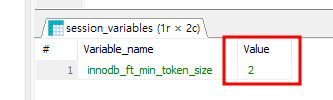
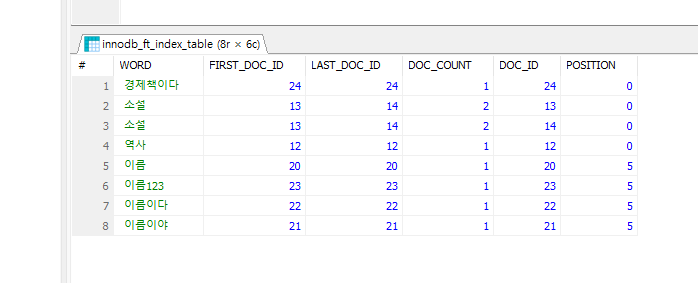
자, 이제 변수 값이 2로 변경되었으니, Full-Text Index를 DROP한 후 다시 설정해보자. 그러면, 아래와 같이 2글자부터 Full-Text Index가 잘 생성된 것을 확인할 수 있다.
⭐ 주의사항
innodb_ft_min_token_size의 값과 Parser의 종류에 따라서 Full-text index 되는 방식이 매우 달라지고, 그에 따라서 아래에서 소개할 Full-Text search의 결과들 또한 많이 달라지게 된다.
내가 필요한 방식이 어떤 것인지 잘 파악하고 설정 값과 Parser를 잘 설정해야한다.
🔨 Full-Text search 사용하기
이제 Index가 설정되었으니, Full-Text Search의 쿼리 문법에 대해서 알아보도록 하자.
3가지의 검색 방식을 사용할 수 있는데, 하나씩 자세히 알아보도록 하자.
- 자연어 검색
- Boolean 모드 검색
- 쿼리 확장 검색
1. 자연어 검색
💡 자연어 검색은 특정 단어가 포함된 것은 조회할 수 없고, 어절이 정확히 일치해야 검색이 된다.
1) '이름'이라는 어절이 포함된 데이터 조회
SELECT * FROM book WHERE MATCH(name) AGAINST('이름');
SELECT * FROM book WHERE MATCH(name) AGAINST('이름' IN NATURAL LANGUAGE MODE);2) '이름' 또는 '역사'라는 어절이 포함된 데이터 조회
SELECT * FROM book WHERE MATCH(name) AGAINST('이름 역사');2. Boolean 모드 검색
1) '이름'이라는 어절이 정확히 포함된 데이터 조회
SELECT * FROM book WHERE MATCH(name) AGAINST('이름' IN BOOLEAN MODE);2) '이름'으로 시작하는 어절이 포함된 데이터 조회
SELECT * FROM book WHERE MATCH(name) AGAINST('이름*' IN BOOLEAN MODE);3) '이름'으로 시작하는 어절 포함되어 있으면서 '이름이다'는 제외하고 데이터 조회
SELECT * FROM book WHERE MATCH(name) AGAINST('이름* -이름이다' IN BOOLEAN MODE);4) '이름'으로 시작하는 어절이 포함되어 있고 '소설'이라는 어절도 반드시 포함
SELECT * FROM book WHERE MATCH(name) AGAINST('이름* +소설' IN BOOLEAN MODE);3. 쿼리 확장 검색
먼저 자연어 검색을 통해서 데이터를 찾고, 그 데이터를 한번 더 Boolean 모드로 검색함
'이름*'으로 갖고 쿼리 확장 검색
SELECT * FROM book WHERE MATCH(name) AGAINST('이름*' WITH QUERY EXPANSION);📒 중지 단어 설정
위 내용들을 통해서 Full-Text Search 의 동작 방식과 사용법에 대해서 알아보았다.
마지막으로, Full-Text Indexing에서 제외하고 싶은 단어들을 지정할 수 있는데, 아래의 방법을 통해서 설정할 수 있다.
1) Full-Text Index 제거
DROP INDEXT {인덱스 이름} on {테이블} ;2) 정지 단어 테이블 생성
CREATE TABLE {정지 단어 관리용 테이블} (value VARCHAR(100));3) 정지 단어 적용
SET GLOBAL innodb_ft_server_stopword_table = '{DB 이름}/{정지 단어 관리용 테이블}';4) Full-Text Index 재설정
CREATE FULLTEXT INDEX {인덱스 이름} ON {테이블} ({컬럼});💡 %LIKE%와 유사하게 구현하기
위에서 설명한 내용들은 built-in-parser를 통해서 full-text index를 생성한 거여서 사실 검색이 원하는 만큼 잘 되지 않는다.
왜냐하면, '어절' 단위로 문장들을 파싱하므로, "녕하"이라는 단어를 통해서 "안녕하세요"라는 문장을 찾을 수 없게 된다. 왜냐하면, 어절의 시작단어 또는 끝 단어로만 검색이 가능하기 때문이다.
그렇다면, %LIKE%를 사용하는 것에 비해서 성능은 향상될지언정 사용성은 많이 떨어지게 된다. 그래서 이번에는 %LIKE%를 대체할 수 있도록 설정하는 방법에 대해서 알아보도록 하겠다.
1. ngram parser 사용하기
InnoDB에서 기본적으로 갖고 내장되어 있는 Parser 중에서 ngram parser라는 것이 있다.
위에서도 잠깐 언급했지만, ngram parser를 통해서 문장을 파싱하면 어절 단위로 파싱하는 것이 아니라 최소 Token 사이즈만큼 조각내어서 파싱을 하게 된다.
예를 들어서 ngram_token_size값이 2인 상태에서 "안녕하세요"라는 문장에서 full-text 인덱스를 만들면, 안녕, 녕하, 하세, 세요와 같이 2자씩 잘려진 인덱스들이 만들어진다. 즉, built-in parser 에서는 할 수 없었던 "녕하"로 "안녕하세요"가 검색이 가능해지게 되는 것이다. 😊
CREATE FULLTEXT INDEX {인덱스 이름} ON {테이블} ({컬럼}) WITH PARSER ngram;결론적으로, %LIKE%문을 활용하는 것과 유사한 검색 기능을 구현하고자한다면, 이렇게 ngram parser로 Index를 만들어야한다.
2. 최소 Token 크기 설정하기
이 값을 설정하기 전에 내가 구현하려고 하는 검색 기능에서 검색 가능한 "최소 글자 수"를 어떻게 설정할 것인지 생각해볼 필요가 있다.
유저들에게 최소 1글자이상을 입력받도록 할 것이라면, ngram_token_size을 1로 설정하는 수 밖에 없고, 1보다 큰 숫자를 최소 검색어로 할 것이라면, 그에 맞게 ngram_token_size를 설정하는 것이 좋다.
이 값을 알맞게 설정해야하는 이유는 ngram_token_size 값이 작을 수록 인덱스를 훨씬 많이 만들어야 하므로, 생성, 수정 또는 삭제 기능에 좀 더 부하를 줄 수 있기 때문이다.
 ngram_token_size를 1로 설정했을 때, Index가 생성된 모습
ngram_token_size를 1로 설정했을 때, Index가 생성된 모습
⚡ 성능 비교
성능 비교는 회사에서 개발중인 게시판 역할을 하는 테이블을 대상으로 진행하였고, 이 테이블은 현재(2024년 1월 31일)를 기준으로 총
5059308개의 레코드가 존재하는 테이블이다. 또, 쿼리문에서 사용한 테이블 이름과 컬럼 이름은 실제 이름을 공개하지 않기 위해서 가명을 사용하였다.
1) '안녕하세요' 검색하기
- LIKE 문
SELECT count(*) FROM `post` WHERE `title` LIKE '%안녕하세요%';- 1차 : 4.2초
- 2차 : 4.5초
- 3차 : 4.4초
- MATCH AGAINST 문
SELECT COUNT(*) FROM `post` WHERE MATCH(`title`) AGAINST('안녕하세요' IN BOOLEAN MODE);- 1차 : 3.4초
- 2차 : 3.6초
- 3차 : 3.4초
2) '안녕' 검색하기
- LIKE 문
SELECT count(*) FROM `post` WHERE `title` LIKE '%안녕%';- 1차 : 4.6초
- 2차 : 4.5초
- 3차 : 4.3초
- MATCH AGAINST 문
SELECT COUNT(*) FROM `post` WHERE MATCH(`title`) AGAINST('안녕' IN BOOLEAN MODE);- 1차 : 2.5초
- 2차 : 2.5초
- 3차 : 2.5초
🧐 결론
위 테스트를 진행해본 결과, Full-text search가 좀 더 빠른 성능을 보여주는 것으로 확인이 되었다.
또, Full-text search의 경우 Full-text index를 타기 때문에 검색어에 따라서 성능이 달라지는 모습을 보여주었는데, LIKE문의 경우엔 무조건 풀스캔을 해야하다보니 검색어에 무관하게 비슷한 성능을 보여주는 것 또한 확인할 수 있었다.

안녕하세요. 좋은 글 잘 봤습니다.
성능 비교할 때, ngram-parser로 하신걸까요 built-in parser로 하신걸까요?