☕ 시작
MySQL은 특정 쿼리를 수행할 때, 어떻게 하면 효율적으로 쿼리를 수행할지 계획을 세우는데, 이를 Optimizing(최적화)라고 부른다.
이러한 작업은 MySQL서버의 MySQL엔진에서 이루어지고, 최적화 작업을 하는데에 여러가지 기준이 있을 수 있지만 '비용 기반 최적화'방식으로 최적화를 하는 것이 일반적이다.
이번 글에서는 최적화 작업의 산물인 '실행 계획'에 대해서 살펴보도록하자 🔥
🧐 실행계획이란?
MySQL서버에 내가 실행하고자 하는 쿼리를 전달하면, Query Parser가 쿼리를 파싱하고 전처리기를 거쳐서 Optimizer가 실행계획을 수립한다.
하나의 쿼리를 어떻게 하면 효율적으로 잘 실행할지를 판단하는 것이다.
🧐 실행계획 뜯어보기

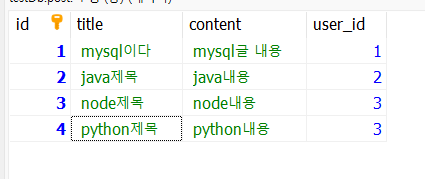
이렇게 user테이블과 post테이블이 있다고 가정해보자.
SELECT * FROM post LEFT JOIN user ON post.user_id = user.id;그리고 이렇게 쿼리를 실행한다면, 아래와 같은 결과가 나올것이다.
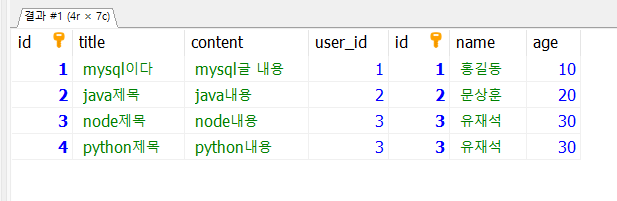
각자 사용하는 mysql 툴에 따라 다르겠지만 내가 사용하고 있는 HeidiSQL의 경우 쿼리를 선택하고 우클릭을 하면,

이렇게 실행계획을 확인할 수 있다.
하나의 쿼리 문에 대해서 2단계의 실행 계획이 생성이 된 것이다.
이 실행계획이 정확히 어떤 의미인지 자세히 살펴보자.
💻 실행계획 컬럼 분석
1) id 컬럼
SELECT문을 구분하는 id값이다. 위의 예시에서는 하나의 SELECT문을 실행하고 있으므로 id는 1로 통일되었다.
2) select_type 컬럼
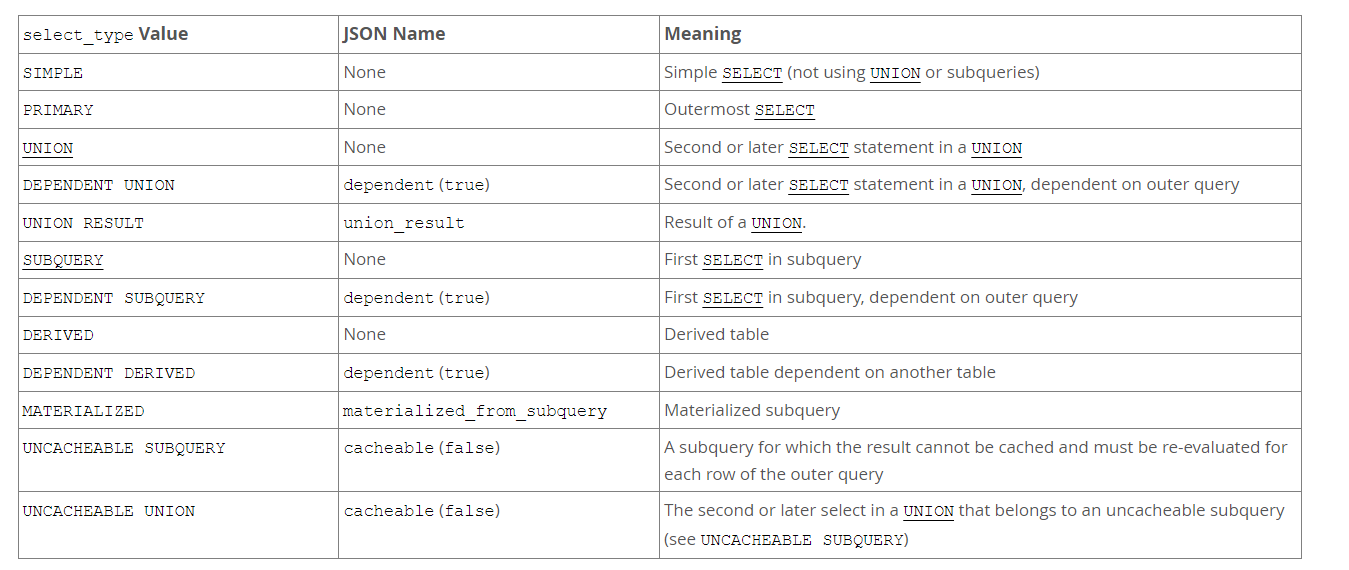
말 그대로 SELECT 문의 종류인데, 일반 쿼리인지 서브 쿼리인지 UNION문인지등등으로 select_type이 결정되게 된다.
- PRIMARY : 서브쿼리 또는 UNION 쿼리에서 가장 바깥의 SELECT문을 나타낸다.
- UNION : UNION을 사용한 쿼리 중 두번째 이상의 SELECT문을 나타낸다.
- DEPENDENT UNION : UNION을 사용한 쿼리 중 두번째 이상의 SELECT문이면서 외부 값을 참조한 경우이다.
- UNION RESULT : UNION을 사용한 쿼리의 최종 결과를 나타낸다.

- SUBQUERY : 서브 쿼리에서 처음 실행되는 SELECT문을 나타낸다.
- DEPENDENT SUBQUERY : 서브 쿼리에서 처음 실행되는 SELECT문 이면서 외부 값을 참조하고 있는 것을 나타낸다.
- DERIVED : FROM 절에 위치한 서브 쿼리의 SELECT문은 임시 테이블을 생성하는데, 이 때 만들어지는 임시 테이블을
Derived Table이라고 한다. 이를 나타내는select_type값이DERIVED이다. - DEPENDENT DERIVED : 다른 테이블을 참조하는 Derived table을 나타낸다.
- MATERIALIZED : FROM절 또는 IN절 안에서 사용된 SELECT문을 나타낸다. 이 때도 Derived table처럼 임시 테이블이 생성되는데, Materialized table은 실체가 있는 물리적인 임시 테이블이고, Derived table은 가상의 임시 테이블이라는 차이가 있다.
- UNCACHEABLE SUBQUERY : 캐싱할 수 없는 서브 쿼리를 나타낸다.
- UNCACHEABLE UNION : 캐싱할 수 없는 UNION절을 나타낸다.
💡 UNCACHEABLE SUBQUERY, UNCACHEABLE UNION 는 사용자 변수나 특정 MySQL 내부 함수를 사용한 경우를 나타내고, 그래서 캐싱을 할 수 없다는 것을 의미한다. 캐싱을 할 수 없다는 것은 성능이 떨어질 가능성이 있다는 것이므로, 유의할 필요가 있다.
3) table 컬럼
기본적으로 테이블 명이 명시되는 컬럼이다. 단, 임시 테이블도 값이 될 수 있는데, 예시로는 아래와 같다.

- <unionid1, id2> : id1, id2에 대한 결과를 UNION한다는 의미이다.
- <derivedid1> : id1에 대한 임시 테이블을 의미한다.
- <subqueryid1> : id1에 대한 Materialized 서브 쿼리를 의미한다.
4) partitions 컬럼
하나의 테이블의 용량이 너무 클 경우 파티셔닝을 할 수 있는데, 그런 경우에 어떤 파티션에서 실행된 SELECT문인지를 나타낸다.
5) type 컬럼
JOIN의 종류를 나타낸다.
system, const, eq_ref, ref, fulltext, ref_or_null, unique_subquery, index_subquery, range, index_merge, index, ALL 과 같은 종류들이 있는데, ALL은 풀스캔을 하는 것을 나타내는 것이여서 성능이 가장 안좋다.
(system에서 ALL로 갈수록 성능이 안좋다.)
6) possible_keys 컬럼
Optimizer가 최적화할 때, 후보로 선정됐던 접근 방법에서 사용되는 인덱스들이다.
7) key 컬럼
Optimizer가 최적화할 때 사용한 인덱스일 경우 그 인덱스가 표시된다.
풀스캔을 했을 때는 NULL이 찍히게 된다.
쿼리 최적화를 할 때, 내가 의도한 인덱스가 잘 찍혔는지 확인해볼 수 있다.
8) key_len 컬럼
최적화에 선택된 인덱스의 길이이다.
9) ref 컬럼
위의 type컬럼에 ref라고 되어 있을 때, 어떤 컬럼이 조건문에 사용되었는지를 나타낸다.
10) rows 컬럼
Optimizer가 스캔해야하는 레코드 수를 예측한 값이다. 실제 레코드 수와 일치하지 않을 수 있다.
11) filtered 컬럼
필터링되고 남은 레코드 수의 비율이다. 실제 비율과 다를 수도 있다.
12) Extra 컬럼
Optimizer가 어떻게 동작하는 지를 알려주는 중요한 컬럼이다.
이 또한 종류가 매우 많다..
문장 형태로 되어 있어서 대충 의미를 파악할 수 있긴하다. 😂
- Backward index scan
- Child of 'table' pushed join@1
- const row not found
- Deleting all rows
- Distinct
- FirstMatch(테이블 명)
- Full scan on NULL key
- Impossible HAVING
- Impossible WHERE
- Impossible WHERE noticed after reading const tables
- LooseScan
- No matching min/max row
- no matching row in const table
- No matching rows after partition pruning
- No tables used
- Not exists
- Plan isn't ready yet
- Range checked for each record
- Recursive
- Rematerialize
- Scanned N databases
- Select tables optimized away
- Skip_open_table
- Open_frm_only
- Open_full_table
- Start temporary
- End temporary
- unique row not found
- Using filesort
- Using index
- Using index condition
- Using index for group-by
- Using index for skip scan
- Using join buffer
- Using MRR
- sing sort_union(...), Using union(...), Using intersect(...)
- Using temporary
- Using where
- Using where with pushed condition
- Zero limit
에.... 쿼리가 어떻게 실행됐다는 것들이 쭉 열거 되는데, 디버깅이 필요하다면 EXTRA 컬럼을 까보면 좋을 것 같다 ㅎㅎ
☕ 마무리
이번 글에서는 MySQL 실행 계획에 대해서 알아보았다.
MySQL의 동작 방식이 좀 더 와닿았던 것 같다.
내 하찮은 쿼리를 실행해주느라 MySQL이 고생이 참 많다.. ㅎㅎ;;
그럼 20000...
