📌 글에서 사용한 코드 : 깃헙
☕ 개요
개발을 하다보면, '동시성 문제'에 자주 마주하게 된다.
이를 해결하기 위한 다양한 기술 및 솔루션들이 존재하는데, 그 중에서도 DB의 Lock를 Application 레벨에서 활용하는 Pessimistic lock과 버전 관리 컬럼을 활용한 Optimistic lock 기법에 대해서 알아보도록 하겠다.
레츠고 🔥
💥 동시성 문제
동시성 문제는 동일한 데이터에 대해서 여러 개의 접근이 동시에 발생할 때, 생길 수 있는 문제이다.
실제적인 예시로는 '수량이 한정된 티켓의 선착순 판매'와 같은 상황을 이야기할 수 있을 것 같다. 이 경우에는 티켓의 수량을 전역적으로 체크해야하는 상황이여서, 동시에 많은 티켓 구매 요청이 쏟아지게 될 경우 실제 수량과 각 요청에서 조회한 수량이 일치하지 않게 될 가능성이 생기게 된다.
즉, 동일한 데이터에 대한 동시 접근으로 인한 동시성 문제가 발생하게 되는 것이다.
그렇다면, 이러한 동시성 문제는 어떻게 해결할 수 있을까?
One by One

동시성 문제 해결을 위한 개념 자체는 간단하다.
동시에 들어오는 요청들을 동시에 처리하지 않으면 되는 것이다.
실생활에 비유하자면, 사람들이 무분별하게 매표소로 들이닥쳐 표를 끊도록 하는 것이 아니라, 사람들을 줄 세워서 순서대로 표를 발급해주면 되는 것이다.
이런 방식을 프로그래밍적으로는 어떻게 구현할 수 있을까?
Synchronized
Java는 기본적으로 멀티 쓰레드 언어이기 때문에 동시성 문제가 발생하기 딱 좋은 환경이다.
그래서 Java는 언어 레벨에서 동시성을 제어할 수 있는 기능을 제공하는데, 그것이 바로 synchronized이다.
public class TicketService {
public synchronized void ticketing(Long ticketId, Long quantity) {
// ... Logic ...
}
}사용법은 매우 간단하다. 위와 같이 순서를 보장하고 싶은 메서드에 synchronized키워드를 붙여주기만 하면 된다.
이렇게 되면 ticketing이라는 메서드는 한번에 하나의 쓰레드에서만 돌아가게 되서, 동시성 문제를 해결할 수 있게 된다.
Synchronized의 한계
하나의 JVM, 즉 하나의 서버에서는 synchronized만으로도 충분히 동시성 제어가 가능해진다. 하지만, 서비스 규모가 약간만 커져도 하나의 서버로 서비스를 운영하는 것은 불가능하고, N대의 서버가 구동되게 된다. 이런 상황에서는 synchronized를 사용해도 여러 서버들에서 동시에 요청이 쏟아지므로 동시성 문제를 해결할 수 없게 된다.
그렇다면, 여러 대의 서버가 구동중인 환경에서도 동시성 문제를 막으려면 어떻게 해야할까?
🤔 Pessimistic Lock (비관적 락)
먼저 이야기할 방식은 Pessimistic lock(이하, P-Lock)을 활용하는 방법이다.
Entity
import jakarta.persistence.Entity;
import jakarta.persistence.GeneratedValue;
import jakarta.persistence.GenerationType;
import jakarta.persistence.Id;
import lombok.Getter;
import lombok.NoArgsConstructor;
import lombok.Setter;
@Getter
@Entity
@NoArgsConstructor
public class Ticket {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Setter
private Long quantity;
public static Ticket create(Long quantity) {
Ticket entity = new Ticket();
entity.setQuantity(quantity);
return entity;
}
public void decrease(Long quantity) {
long q = this.quantity - quantity;
this.quantity = q < 0 ? 0L : q;
}
}매~우 단순한 Ticket이라는 엔티티를 만들어주었다.
Repository
import jakarta.persistence.LockModeType;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.jpa.repository.Lock;
import org.springframework.data.jpa.repository.Query;
public interface TicketRepository extends JpaRepository<Ticket, Long> {
@Lock(LockModeType.PESSIMISTIC_WRITE)
@Query("select t from Ticket t where t.id = :id")
Ticket findByIdWithPLock(Long id);
}@Lock어노테이션을 통해서 P-Lock을 걸어주었고, Lock모드는 PESSIMISTIC_WRITE로 하였다. 이 옵션은 특정 데이터에 Lock이 걸리면 해당 데이터에 대해서 조회, 수정, 삭제가 모두 불가능한 강한 격리성을 보장하는 모드이다. MySQL의 REPEATABLE-READ 수준의 격리성을 갖게 된다.
다른 모드들에 대해서는 이 문서를 참고해보면 좋을 것 같다.
Service
import lombok.RequiredArgsConstructor;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
@Transactional
@Service
@RequiredArgsConstructor
public class TicketService {
private final TicketRepository ticketRepository;
public void ticketing(Long ticketId, Long quantity, Boolean lock) {
Ticket ticket = lock
? ticketRepository.findByIdWithPLock(ticketId)
: ticketRepository.findById(ticketId).orElseThrow();
ticket.decrease(quantity);
ticketRepository.saveAndFlush(ticket);
}
}Ticket을 찾아서 티켓의 수량을 감소시키는 매우 간단한 기능을 갖고 있는 Service이다.
다만, lock이라는 매개변수를 받아서 P-Lock이 적용된 조회기능에 대한 사용여부를 결정할 수 있도록 해두었다.
테스트 코드
import lombok.extern.slf4j.Slf4j;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.DisplayName;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import static org.junit.jupiter.api.Assertions.*;
@Slf4j
@SpringBootTest
class TicketServiceTest {
@Autowired
TicketService ticketService;
@Autowired
TicketRepository ticketRepository;
private Long TICKET_ID = null;
private final Integer CONCURRENT_COUNT = 100;
@BeforeEach
public void before() {
log.info("1000개의 티켓 생성");
Ticket ticket = Ticket.create(1000L);
Ticket saved = ticketRepository.saveAndFlush(ticket);
TICKET_ID = saved.getId();
}
@AfterEach
public void after() {
ticketRepository.deleteAll();
}
private void ticketing100(boolean good) throws InterruptedException {
Long originQuantity = ticketRepository.findById(TICKET_ID).orElseThrow().getQuantity();
ExecutorService executorService = Executors.newFixedThreadPool(32);
CountDownLatch latch = new CountDownLatch(CONCURRENT_COUNT);
for (int i = 0; i < CONCURRENT_COUNT; i++) {
executorService.submit(() -> {
try {
ticketService.ticketing(TICKET_ID, 1L, good);
} finally {
latch.countDown();
}
});
}
latch.await();
Ticket ticket = ticketRepository.findById(TICKET_ID).orElseThrow();
assertEquals(originQuantity - CONCURRENT_COUNT, ticket.getQuantity());
}
@Test
@DisplayName("동시에 100명의 티켓팅 : 정상")
public void good() throws Exception {
ticketing100(true);
}
@Test
@DisplayName("동시에 100명의 티켓팅 : 동시성 이슈")
public void bad() throws Exception {
ticketing100(false);
}
}테스트 코드가 멀티 쓰레딩하는 코드 때문에 좀 길지만, 핵심은 동시에 100개의 요청을 수행하는 것이고, 2개의 테스트는 각각 P-Lock을 사용했을 때와 그렇지 않았을 때 어떻게 동작하는지를 테스트하는 것이다.
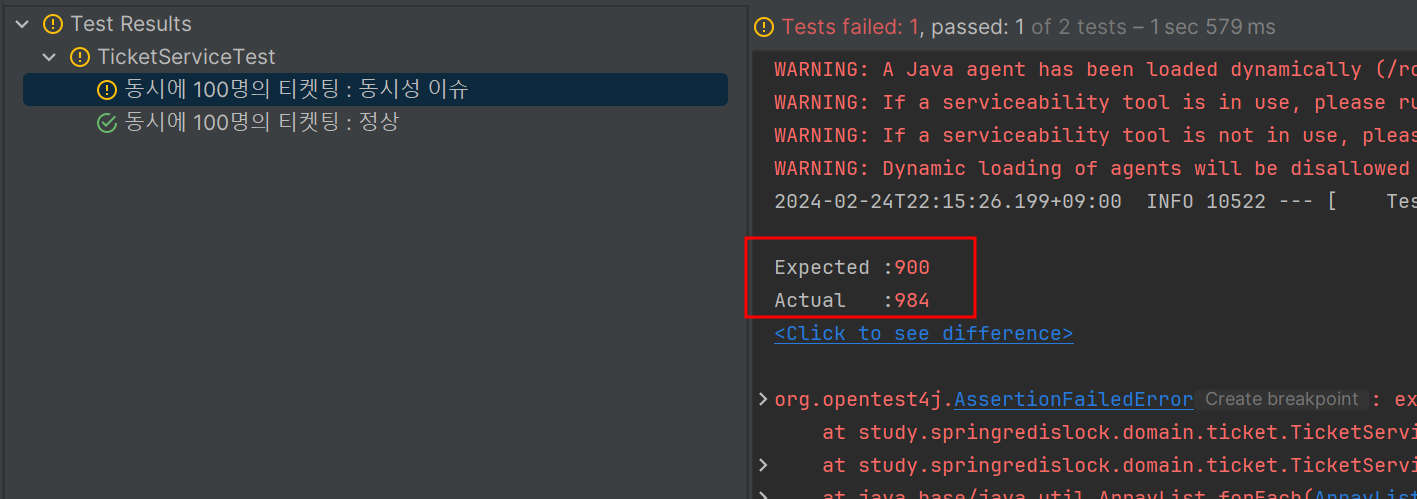
그 결과는 이렇다. P-Lock을 사용하지 않았을 때는 정상적으로(?) 예상한 결과 값과 실제로 줄어든 티켓의 수량이 일치하지 않는 것을 확인할 수 있다.
정리
@Lock 어노테이션을 활용해서 특정 데이터에 Exclusive lock을 걸고, 하나의 처리가 완료될 때 까지는 해당 데이터의 읽기, 수정, 삭제를 방지함으로써 동시성 문제를 해결하였다.
이 처리는 동시성 문제 측면에서는 안정성이 매우 높지만, 하나 하나씩 순차적으로 처리해서 처리 속도가 비교적 매우 늦어지고, 특정 데이터의 조회까지도 막아버려서 또 다른 부작용이 발생할 가능성도 높아진다는 단점이 있다.
🤓 Optimistic Lock (낙관적 락)
Optimistic lock은 DB의 Lock을 활용하지 않고, 데이터의 버전을 기록할 수 있는 컬럼을 추가해서 이 버전을 기준으로 동시 접근 제어를 하게 된다.
Entity
import jakarta.persistence.*;
import lombok.Getter;
import lombok.NoArgsConstructor;
import lombok.Setter;
@Getter
@Entity
@NoArgsConstructor
public class Ticket {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Setter
private Long quantity;
@Version
private Long version;
public static Ticket create(Long quantity) {
Ticket entity = new Ticket();
entity.setQuantity(quantity);
return entity;
}
public void decrease(Long quantity) {
long q = this.quantity - quantity;
this.quantity = q < 0 ? 0L : q;
}
}기존의 Entity에 버전을 관리할 수 있는 version이라는 컬럼을 추가해준다ㅏ.
Repository
import jakarta.persistence.LockModeType;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.jpa.repository.Lock;
import org.springframework.data.jpa.repository.Query;
public interface TicketRepository extends JpaRepository<Ticket, Long> {
@Lock(LockModeType.PESSIMISTIC_WRITE)
@Query("select t from Ticket t where t.id = :id")
Ticket findByIdWithPLock(Long id);
@Lock(LockModeType.OPTIMISTIC)
@Query("select t from Ticket t where t.id = :id")
Ticket findByIdWithOLock(Long id);
}기존의 Repository코드에 Optimistic lock을 사용하는 메서드를 하나 추가한다.
Service
import jakarta.persistence.OptimisticLockException;
@Slf4j
@Transactional
@Service
@RequiredArgsConstructor
public class TicketService {
private final TicketRepository ticketRepository;
// ...생략...
public void optimisticTicketing(Long ticketId, Long quantity) {
try {
Ticket ticket = ticketRepository.findByIdWithOLock(ticketId);
ticket.decrease(quantity);
ticketRepository.saveAndFlush(ticket);
} catch (ObjectOptimisticLockingFailureException | OptimisticLockException e) {
log.info("Version 충돌. 롤백 또는 재시도");
}
}
}기존의 Service에도 Optimistic lock을 활용하는 코드를 추가해준다.
Optimistic lock은 version 컬럼을 기준으로 최신 데이터인지를 판별하고, 데이터의 수정 및 삭제를 하려고 할 때 최신 데이터가 아니면 에러를 뱉게 된다. 이렇게 Optimistic lock에 의해서 로직 수행에 실패한 경우, 재시도 또는 롤백 기능을 직접 구현해줘야한다. (나는 생략 ㅋ)
테스트 코드
Pessimistic Lock에서 사용한 것과 같은 테스트 코드로 이 코드를 테스트하면 당연히 실패하긴 할 것이다. 왜냐하면 Version이 충돌했을 때 동작할 재시도 또는 롤백 기능이 구현되어 있지 않기 때문이다.
로직의 재시도 또는 롤백 기능은 생략하도록 하겠다.
정리
Optimistic lock의 경우 강한 수준의 DB Lock을 걸지 않아서 Pessimistic Lock에 비해서 자유롭게 데이터 조회가 가능하다는 장점이 있지만, 롤백 및 재시도 로직을 직접 구현해줘야한다는 단점 또한 존재한다.
🧐 한계점과 분산락
한계점
Pessimistic Lock과 Optimistic lock 모두 동시성 문제를 해결할 수는 있지만, 한계점들이 너무 명확하다.
Pessimistic lock은 매우 안전한 동시 접근 제어를 보여주지만, 너무 과하게 Lock이 적용된다는 단점이 있고, Optimistic lock은 DB Lock을 적용하지는 않지만 재시도 로직을 작성해야한다는 단점이 있다. 재시도 로직을 작성을 단점이라고 하는 것은 단순히 코드를 작성하기 귀찮다는 것은 아니고, 재시도와 같은 처리는 굉장히 까다롭기도하고 재시도가 너무 많이 실행될 경우 DB에 부하를 줄 수 있다는 것을 의미한다.
분산락
위와 같은 한계점을 극복하기 위해서 Redis와 같은 것을 활용해서 '분산락'을 구현하곤 한다.
그렇게 되면, DB Lock을 걸지 않으면서도 안전하고 효율적인 재시도 기능까지 쉽게 구현할 수 있기 때문이다.
다음 글에서는 Redis를 활용한 분산락 처리를 알아보도록 하자. ㅎㅎ
(사실은 이 글은 Reids를 활용한 분산락을 이야기 위한 빌드업이다.)
그럼 이만 ☕
🙏 참고
- 인프런 강의 - 재고시스템으로 알아보는 동시성이슈 해결방법 👍
- 트랜잭션 동시성 문제 해결- Optimistic Lock과 AOP활용
- JPA 비관적 잠금(Pessimistic Lock)
- Pessimistic Locking in JPA
- Optimistic Locking in JPA
