🧐 React-query란?
공식문서에 의하면, React-query(이하 RQ)는 데이터 fetching라이브러리이고, 기술적으로는 fetching, 캐싱, 서버의 상태를 동기화하고 업데이트하는 라이브러리라고 한다.
쉽게 이야기하면, BE서버와의 통신하는 기능을 담당해주는 라이브러리라고 보면 된다.
개인적으로는 반복적인 서버 Api코드를 줄일 수 있고, 캐싱기능 때문에 RQ를 사용하고 있다. 🤭
🔥 React-query의 캐싱 개요
RQ의 핵심 중에 하나가 바로 캐싱이고, staleTime과 cacheTime 모두 RQ의 캐싱 기능 때문에 필요한 값들이다.
그래서 RQ의 캐싱의 동작에 대해서 한번 짚고 넘어가도록 하겠다.
참고로 공식문서가 매우 잘되어 있고, 한번쯤은 읽어보는 것을 RQ팀에서도 권장하므로, 안읽어본 사람들은 한번 읽어보자 🔥
💧 데이터의 라이프 사이클
캐싱을 이해하려면 먼저, RQ에서 데이터를 관리할 때 어떤 라이프 사이클로 관리하는 지 이해할 필요가 있다.
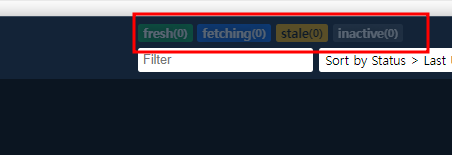
React-query devtools를 쓰면 오른쪽에 이렇게 상태값이 나와 있는 게 있는데, 이것이 바로 데이터들의 생애주기에 대한 값들이다.
1. fresh
- 신선한 상태 : staleTime이 지나지 않은 데이터
- 이러한 상태의 데이터를 다시 요청하면, 이 데이터를 그대로 반환한다.
2. fetching
- 데이터를 불러오는 중인 상태
- 서버에 API를 날리고 기다리는 중이라고 보면 될 것 같다.
3. stale
- 상한 상태 : staleTime이 지난 데이터
- 이러한 상태의 데이터를 다시 요청하면, 서버에 api를 다시 요청한다.
4. inactive
- 쿼리가 실행된 컴포넌트가 unmount됐을 때, 해당 컴포넌트에서 불러와졌던 데이터들은 inactive상태가 된다. 즉, 사용되지는 않지만 캐싱이 되어 있는 상태(메모리에 남아 있는 상태)인 것이다.
5. delete
- 캡쳐한 화면에는 없지만, cacheTime이 지나서 아예 삭제된 상태도 있다.
inactive한 데이터가 cacheTime이 지나면 가비지 컬렉터에 의해 메모리에서 아예 제거된다.
⚡ 캐싱의 동작 원리
이제 본격적으로 캐싱이 어떻게 동작하는 지 알아보자.
크게 2가지 원리를 기억하면 된다.
상한 건 버리고 신선한 거로 가져온다
- fresh한 데이터를 조회하면, 기존의 데이터를 그냥 보여준다.
- stale한 데이터를 요청하면, 서버에 다시 요청해서 데이터를 가져온다.
- fresh한 상태를 유지하는 시간이
staleTime이다.
아 잠깐. 일단 캐시보고 있어
- stale한 데이터를 요청하면 서버에서 다시 데이터를 가져올 것인데, 가져오는 동안 캐싱이된 데이터가 있다면 그 데이터를 보여준다.
⭐ 키 포인트
기본적인 개념들을 알아봤는데, 좀 더 실제적인 이야기들을 해보겠다.
1) 기본 설정으로는 캐싱이 되지 않는다
React query의 staleTime과 cacheTime의 기본 값은 각각 0초와 5분이다.
다시말하자면, 서버에서 가져오는 데이터는 바로 stale한 상태가 되는 것이다. 결국엔 어떠한 데이터든 요청할 때 마다 새로운 데이터를 가져오는 것이여서 캐싱 기능이 동작하지 않는 것과 다름 없다.
2) 캐싱의 사용 유무는 직접 정할 수 있다.
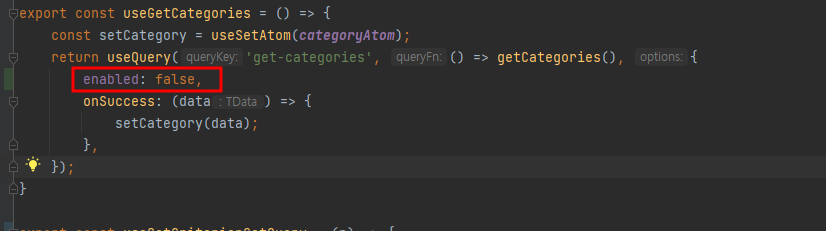
만약 어떤 데이터는 무조건 서버에서 새로 가져와야하는 데이터가 있다면, 이렇게 enabled를 false로 해주고, 필요할 때마다 직접 refetch메서드를 실행해주자.
3) staleTime과 cacheTime의 Best practice
staleTime과 cacheTime을 설정하는 데에 있어서 사실 정답은 없다. 각자가 만드는 서비스나 쿼리의 성격에 맞게 설정해주면 된다.
하지만, 범용적으로 괜찮게 적용할 수 있는 staleTime과 cacheTime이 알고 싶을 수 있다. (내 얘기다 🤭)
찾아보니 잘 모르겠지만 일단 캐싱을 적용하고 싶다면, staleTime은 20초 cacheTime은 5분으로 설정하라고 하는 글들이 많이 있었다. ㅎㅎ
이렇게 설정해놓고 개발하면서 조정해나가면 될 것 같다.
4) cacheTime은 staleTime 보다 항상 커야하는 가?
그렇지 않다.
cacheTime을 staleTime보다 크게 설정하는 게 일반적이긴 하지만, 작게 설정한다고 문제가 되는 것은 없다.
다만, 위에서 이야기했던 서버에서 fresh한 데이터를 가져오는 동안엔 캐시된 데이터를 보여준다라는 기능을 사용하지 않게 되는 것이다.
☕ 마무리
import {QueryClient} from 'react-query';
export const queryClient = new QueryClient({
defaultOptions: {
queries: {
retry: 0,
useErrorBoundary: true,
staleTime: 1000 * 20,
cacheTime: 1000 * 60 * 5,
},
mutations: {
useErrorBoundary: true,
},
},
});
마지막으로 내가 사용하고 있는 RQ설정을 공유하고 마치도록 하겠다.
공유하는 이유는 그냥 참고용으로? 🤭
아! 그리고 RQ에 대한 아주 좋은 내용의 무료 강의를 공유하겠다.
