
백엔드에서 이미지 파일을 받아 처리하는 로직을 구현하고 있었다.
기존엔 이미지를 받고 나서 buffer에 담긴 정보를 toString('base64')로 인코딩하여 db에 저장했었다.
@Post()
@UseInterceptors(FileInterceptor('book-image'))
async createBookReview(
@UploadedFile() bookImage: Express.Multer.File,
@Body() bookDto: BookReviewDto,
) {
bookDto.bookImage = bookImage.buffer.toString('base64')
await this.bookReviewService.createBookReview(bookDto);
}이렇게 구현하니 프론트에서 이미지를 불러오고 렌더링 하기까지 5초가 걸렸다.
왜 이렇게 오래 걸린걸까?
gemini한테 물어보니, base64 인코딩은 이미지 저장 용량을 30%까지 늘리기 때문에 데이터베이스 저장이나 이미지 불러오는 시간 측면에서 단점이 많다고 한다.
gemini가 내놓은 해답은 이렇다.
이미지는 S3에 저장하고 저장된 이미지 url만 db에 저장하세요.
S3는 한 번도 세팅해보지 않아서 gemini의 도움을 많이 받았다
먼저 AWS S3 버킷을 만들어야 한다.
AWS S3 버킷 만들기
버킷 생성
AWS에 접속한 후 S3에 들어간다.
주황색 버킷 만들기를 누르고 초기 세팅을 진행한다.
- 일반 구성: Global namespace 그대로 둔다.
- 버킷 이름: 마음대로 지정한다.(그렇다고 막 짓진 말고 서비스와 관련해서 짓자)
- ACL 비활성화됨을 유지한다.
- 모든 퍼블릭 액세스 차단 선택을 풀어주고 하단 경고창에 체크표시를 한다.(이 설정을 해야 외부에서도 파일 접근이 가능하다)
- 버킷 버전 관리, 기본 암호화도 기본 설정을 유지한다.
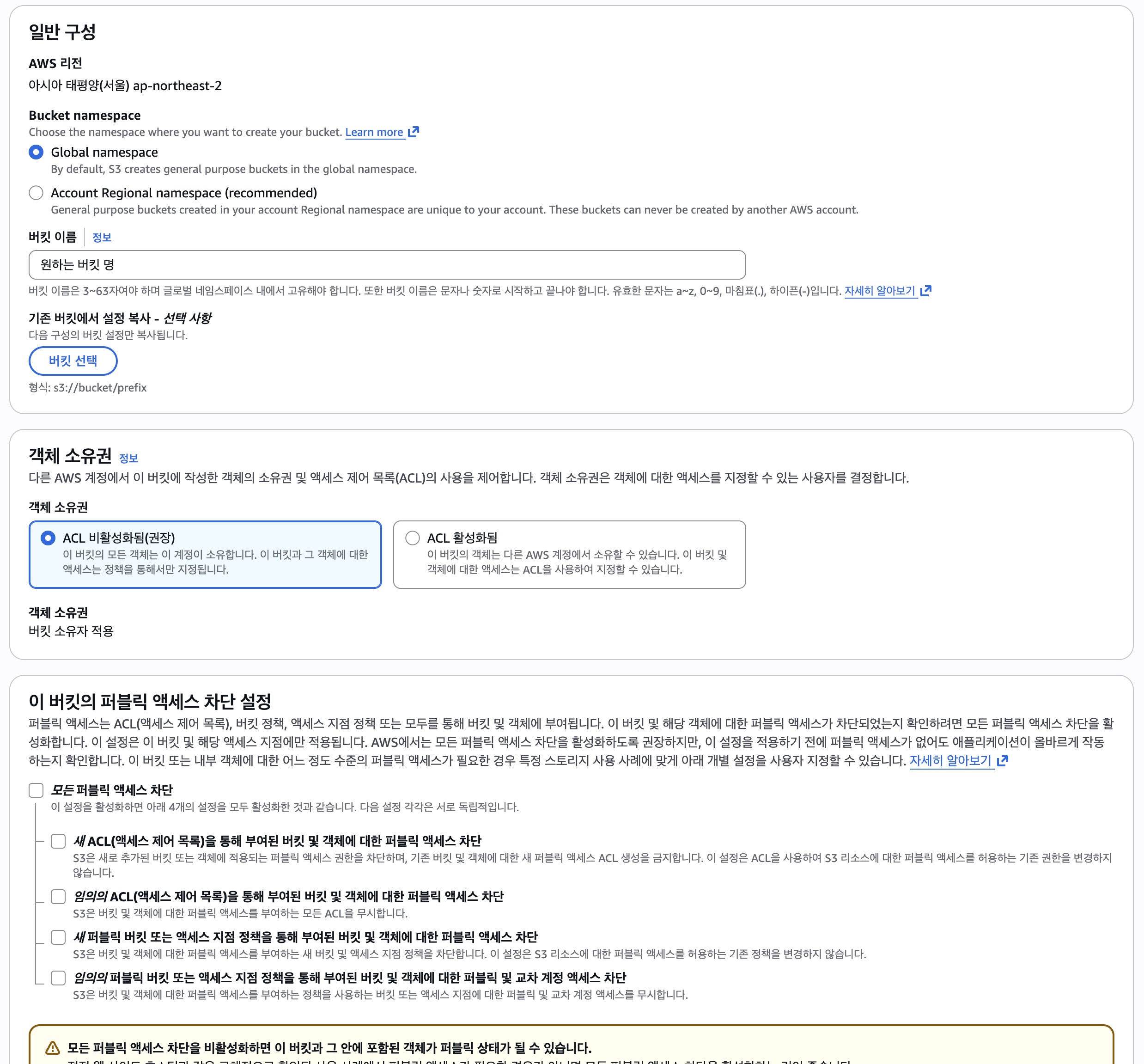
이렇게 세팅을 마치고 버킷 만들기를 누르면 버킷이 생성된다.
버킷 정책 설정
버킷 생성이 완료됐으면 정책을 설정해야 한다.
- 생성된 버킷을 클릭하고 상단 권한 탭에 들어와 버킷 정책을 편집하면 된다.
- 정책에 빈 json 내용이 있으면 거기에 작성하면 되고 없다면 우측에 새 문 추가를 누른다.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "PublicReadGetObject",
"Effect": "Allow",
"Principal": "*",
"Action": "s3:GetObject",
"Resource": "arn:aws:s3:::{본인 버킷 명}/*"
}
]
}{ } 자리에 본인 버킷 명을 그대로 작성해주면 된다.(물론 {,}는 뺀다)
이후 변경 사항 저장을 누른다.
이렇게 버킷 설정은 완료됐다.
IAM 생성하기
사용자 생성
만들어놓은 버킷에 접근 권한이 있는 사용자를 생성한다.
여기서 가졌던 의문
루트 계정으로 다 접근할 수 있게 해야하는 거 아닌가? 왜 굳이 사용자를 또 나눠서 관리하지?
gemini의 대답
- 최소 권한 원칙: 루트 계정이 털리면 모든 서비스에 피해가 간다. 필요에 맞게 최소한의 권한으로 사용자를 설정해서 사용하는 게 안전하다.
- 책임 소재 파악: 루트 계정만 사용할 경우 로그 관리가 어렵다. 여러 부서가 한 계정을 사용할 경우 실수로 DB를 날려도 어떤 부서가 잘못한 건지 알 수 없다.
개인적으로 aws를 사용하는 분들에겐 첫 번째 이유가 가장 중요할 것 같다.
어쨋든, IAM 사용자 탭에 들어와서 사용자 생성을 누른다.
- 사용자 이름을 설정한다.
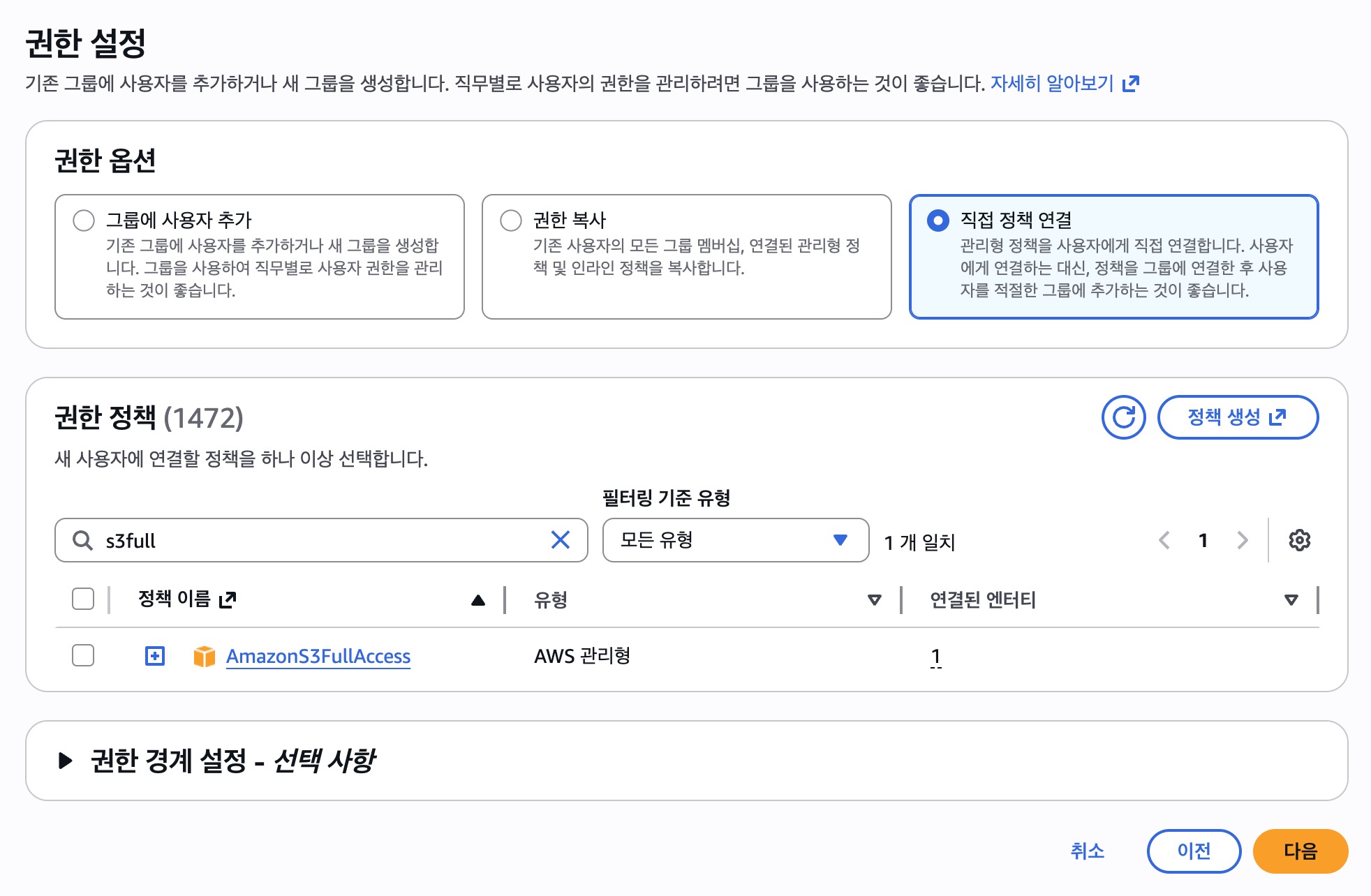
- 권한 옵션에서 직접 정책 연결을 선택한다.
- 하단 권한 정책 검색창에 s3full을 입력하면 아래에
AmazonS3FullAccess옵션이 나오는데 왼쪽 체크박스를 클릭하고 다음 버튼을 누른다. - 바로 다음 페이지에서 사용자 생성 버튼을 누른다.
액세스 키 발급
사용자를 만들었으니 이 권한을 사용할 수 있는 액세스 키를 발급받아야 한다.
여기에 나오는 키는 생성된 직후만 조회할 수 있기 때문에 안전한 개인 파일에 보관하는 게 중요하다.
- 생성된 사용자를 클릭하고 하단 액세스 키 탭의 액세스 키 만들기 버튼을 누른다.
AWS 외부에서 실행되는 애플리케이션 옵션을 클릭하고 다음을 누른다.- 태그는 생략하고 액세스 키 만들기를 누른다.
- 이후에 하단에 나온 액세스 키와 비밀 액세스 키를 꼭 저장해둔다.

이렇게 S3 버킷과 IAM 사용자 생성이 완료됐다.
이제 버킷명, IAM 사용자 액세스 키와 비밀 액세스 키를 본인 서비스 .env파일에 저장하고 S3를 사용하면 된다.
끝. 생각보다 쉬웠다.
gemini 말대로 설정했을 때 잘 된 경우가 많이 없었는데, 최근에 좀 똑똑해졌나보다
