paper
- Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
- How Does Batch Normalization Help Optimization?
reference
동빈나 유튜브 https://youtu.be/58fuWVu5DVU
code https://kratzert.github.io/2016/02/12/understanding-the-gradient-flow-through-the-batch-normalization-layer.html
블로그 https://eehoeskrap.tistory.com/430
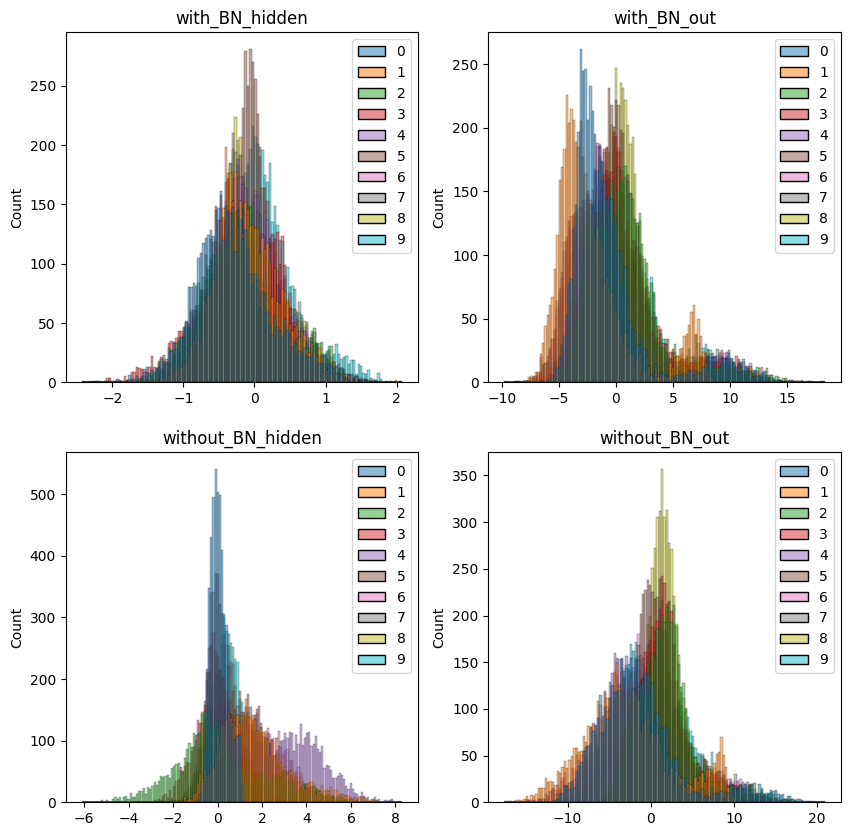
BN vs Without BN
Batch Normalization
Abstract
We refer to this phenomenon as internal covariate shift, and address the problem by normalizing layer inputs.
저자는 internal covariate shift를 해결하기 위해서 BN을 제안했지만 뒤에 나오는 'How Does Batch Normalization Help Optimization?'에 따르면 BN은 internal covariate shift를 해결하지 못했다고 주장한다.
> phenomenon: the distribution of each layer's inputs changes during training, as the parameters of the previous layers change.
Batch Normalization allows us to use much higher learning rates and be less careful about initializaion. It also acts as a regularizer.
As a result, BN achieves the same accuracy with fewer training steps and beats the original model by a significant margin.
Introduction
we could ensure that the distribution of nonlinearity inputs remains more stable as the network trains, then the optimizer would be less likely to get stuck in the saturated regime, and the training would accelerate.
then, we propose a new mechanism, which we call Batch Normalization. It makes it possible to use saturating nonlinearities by preventing the network from getting stuck in the saturated modes.
Towards Reducing Internal Covariate Shift
Whitening transformation
https://dive-into-ds.tistory.com/19
whitening: zero means, unit variances, decorrelated.
We could consider whitening activations at every training step or at some interval, either by modifying the network directly or by changing the parameters of the optimization algorithm.
However, the gradient descent step may attempt to update the parameters in a way that requires the normalization to be updated.
The issue with the above approach is that the gradient descent optimization does not take into account the fact that the normalizatino takes place.
Within this framework, whitening the layer inputs is expensive. This motivates us to seek an alternative that performs input normalizatino in a way that is differentiable and does not require the analysis of the entire training set.
명료한 정리
수식
y = r * x(^) + b
x(^)
- 평균 0, 표준편차 1로 정규화된 입력
- 배치단위로 정규화한다.
학습 패러미터
- scale, shift: r, b
- r, b are a pair of learned parameters
- r, init value = 1
- b, init value = 0
추론할 때,
- 학습에서 사용한 batch 평균값과 분산값을 사용한다.
- 모멘텀을 사용해 배치마다의 평균값과 분산값을 갱신한다.(매 배치마다 극적으로 값이 변하는 것을 방지하기 위함)
한줄요약
각 레이어의 활성화값이 적당히, 골고루 퍼지도록 하는 레이어
효과
- 학습이 빨라진다
- 가중치 초깃값에 의존하지 않도록 한다.
- 오버피팅을 억제
- 높은 learning rate에서도 학습이 가능하다.
회고
시작은 배치 정규화 논문 이해와 구현이었지만,
효과를 확인하기 위해서 fully connected layers를 직접 구현해야 했다.
바닥부터 구현하는 신경망 구조와 제대로된 역전파 이해를 할 수 있었다.
