Optimizer
SGD
Stochastic Gradient Descent
class SGD:
def __init__(self, lr=0.01) -> None:
self.lr = lr
def update(self, params, grads):
for param in params.keys():
params[param] -= self.lr * grads[param]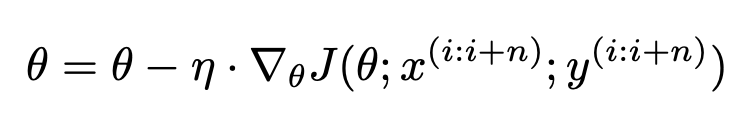
backpropagation을 통해 얻은 gradient를 이용해서 parameter를 update한다.
이 떄, hyper parameter로 learning rate가 사용되었다.
SGD에는 다음과 같은 단점이 존재한다.
- 학습 중에 learning rate를 조절하기 어렵다. scheduler에 의한 조절은 인위적이며 데이터 친화적이지 않다.
- parameter가 모두 같은 learning rate로 update된다.
- plateau로 둘러싸인 saddle point를 탈출하기 힘들다.
Momentum
class Momentum:
def __init__(self, lr=0.01, momentum=0.9):
self.lr = lr
self.momentum = momentum
self.v = None
def update(self, params, grads):
if self.v is None:
self.v = {}
for key, val in params.items():
self.v[key] = np.zeros_like(val)
for param in params.keys():
self.v[param] *= self.momentum
self.v[param] -= self.lr * grads[param]
params[param] += self.v[param]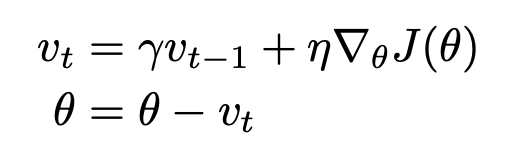
Momentum은 ravine(협곡, in paper; areas where the surface curves much more steeply in one dimension than in another)에서 학습을 가속화하기 위해 고안되었다.
v는 0으로 초기화된 후, gradient와 learning rate의 곱의 누적합으로 parameter를 update한다. 모멘텀 상수 값은 보통 .9로 지정한다.
Nesterov accelerated gradient
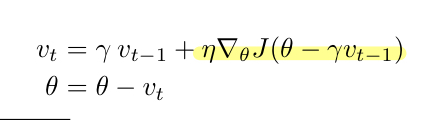
weight(parameter) - loss관계에서 gradient를 구할 때, 현재 parameter에 대한 gradient를 구하는 것이 아니고, 모멘텀에 의해 갱신된 parameter를 넣어 gradient를 구하면 loss가 slope up 하기 전에 속도를 늦출 수 있도록, 즉 예측하여 움직일 수 있도록 고안되었다.
AdaGrad
Adaptive Gradient
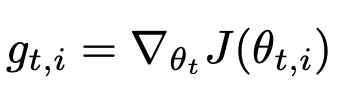

ϵ: smoothing term
AdaGrad는 학습하면서 learning rate를 조절하기 위해 고안되었다. 하지만 학습이 진행되면서 크기가 단조 증가하므로 learning rate가 0에 수렴하여 학습이 진행되지 않는 문제점을 가지고 있다.
밑바닥부터 시작하는 딥러닝 1 에서 배웠던 내용에 의하면 numpy를 이용해 grad**2와 같이 원소 제곱으로 G_t를 표현하지만 논문의 주석 11에 달린 내용은 vector(gradient)의 outer product를 통해 G_t,ii 행렬을 구한다. 이 때, 연산은 대각선만 사용하여 원소 제곱과 같은 형태로 만든다.
outer product
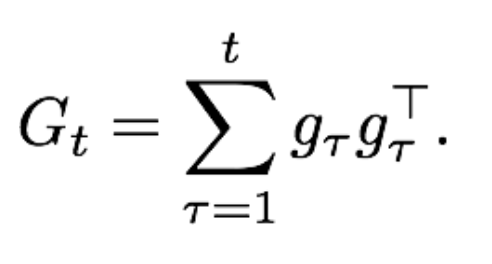
참고:
- AdaGrad
https://medium.com/konvergen/an-introduction-to-adagrad-f130ae871827 - outer product
https://numpy.org/doc/stable/reference/generated/numpy.outer.html
Adadelta
AdaGrad의 단점을 보안하기 위해서 decaying average을 사용한다. learning rate를 조절하기 위한 계수가 끊임없이 누적되지 않아 0에 수렴하지 않는다.
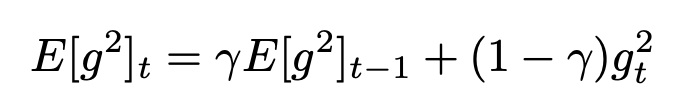
또 다른 차이점은, 논문에서
The authors note that the units in this update (as well as in SGD, Momentum, or Adagrad) do not
match, i.e. the update should have the same hypothetical units as the parameter. To realize this, they
first define another exponentially decaying average, this time not of squared gradients but of squared
parameter updates:

번역은 역시 chatGPT !
단위가 다른 것을 맞추기 위해 gradient의 제곱을 사용하지 않고 parameter의 변화량의 제곱을 사용한다.
RMSprop
Adadelta에서 gradient의 제곱을 사용한 식이다. 그럼에도 효과적이다.
Adam
간단하게 Adam을 소개하자면, Momentum과 Adaptive learning rate method를 합친 것이다. 따라서 두 개의 매개변수를 통해 갱신한다.
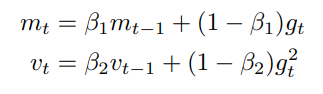
m_t, v_t는 각각 mean, variance에서 따왔고 gradient의 first moment와 second moment로 불린다.
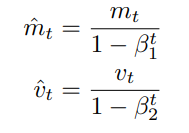
Adam을 제안한 사람에 따르면 m_t, v_t는 0으로 초기화되므로 0에 편향된다고 한다. 이것을 조정하기 위해 m hat, v hat을 위처럼 제안했다.
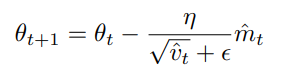
Adam 최종식
Learning rate scheduler with adaptive gradient descent
위 글을 요약하면 adaptive gradient descent 계열 optimizer의 경우가 월등히 효과가 좋았다.
