앙상블이란?
머신 러닝에서 앙상블은 단어 그대로 여러 단순한 모델을 결합하여 정확한 모델을 만드는 방법이다.
강력한 성능에 비해 의외로 앙상블 방법의 개념은 매우 단순하다
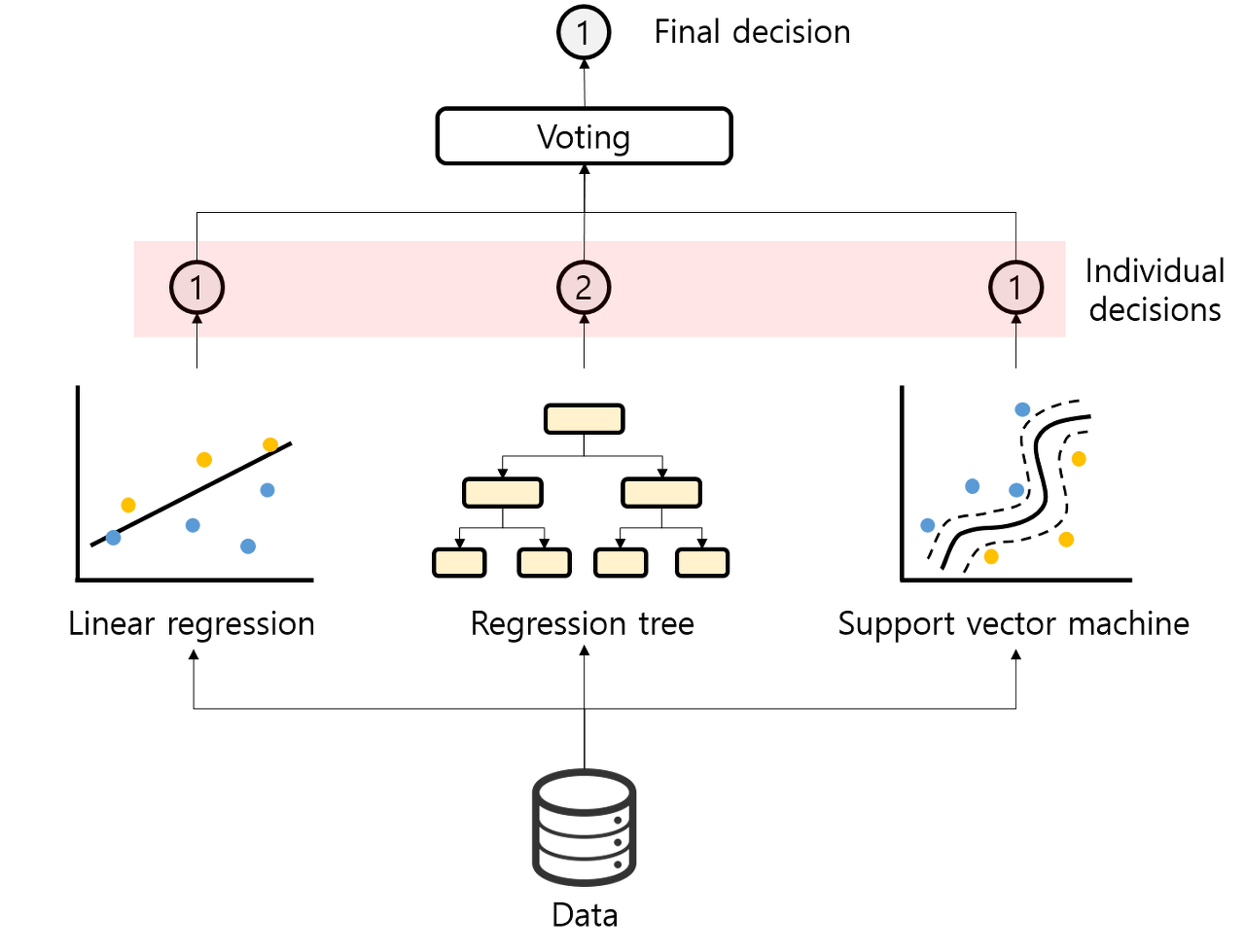
[사진: 투표 기반 base estimator (Voting) 앙상블]
다수의 예측이 곧 최종 예측이 되기 때문에 그림의 예시에서는 2가 아니라 1이라는 값이 최종 예측으로 선택되었다.
앙상블 개념의 핵심 개념은 다양한 종류의 여러 estimator를 결합하여 더 좋은 estimator를 만드는 것이다. 앙상블 방법의 종류는 estimator들을 어떻게 결합할 것인지에 의해 결정된다.
- 앙상블 기법의 종류.
- 보팅 (Voting): 투표를 통해 결과 도출
- 배깅 (Bagging): 샘플 중복 생성을 통해 결과 도출
- 부스팅 (Boosting): 이전 오차를 보완하면서 가중치 부여
- 스태킹 (Stacking): 여러 모델을 기반으로 예측된 결과를 통해 meta 모델이 다시 한번 예측
-
사용된 데이터
- Wisconsin Diagnostic Breast Cancer (WDBC) : 위스콘신 유방암 진단 데이터
-
모델
- LogisticRegression, DecisionTree, KNN 사용
import pandas as pd
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.ensemble import VotingClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
cancerdata = load_breast_cancer()
data_df = pd.DataFrame(cancerdata.data,columns = cancerdata.feature_names)
print(data_df.head(),data_df.shape) #(569, 30)
x_train, x_test, y_train, y_test = train_test_split(\
cancerdata.data,cancerdata.target,test_size=0.2,random_state=12)
#(455, 30) (114, 30) (455,) (114,)train_test split으로 7:3 데이터 분리. VotingClassifier를 위해 모델 3개 객체를 만들었다.
logi_regression = LogisticRegression()
knn = KNeighborsClassifier(n_neighbors=3)
dec_model = DecisionTreeClassifier()
classifiers = [logi_regression,knn,dec_model]for루프에서 리스트에 담은 모델을 순차적으로 학습->평가를 해봤다.
for classifier in classifiers:
classifier.fit(x_train,y_train)
pred = classifier.predict(x_test) #각 모델3개의 예측
class_name = classifier.__class__.__name__ #클래스 이름얻기
print('{0} 모델의 정확도 : {1:.3f}'.format(class_name,accuracy_score(y_test,pred)))
# LogisticRegression 모델의 정확도 : 0.930
# KNeighborsClassifier 모델의 정확도 : 0.895
# DecisionTreeClassifier 모델의 정확도 : 0.939앞에서 사용할 VotingClassifier 모델은 위의 과정을 함수로써 동작하도록한다.
#VotingClassifier로 확인
voting_model = VotingClassifier(\
estimators=[('LR',logi_regression),('knn',knn),('Decision',dec_model)],\
voting='hard')
voting_model.fit(x_train,y_train)
vpred = voting_model.predict(x_test)
print('voting 분류기의 정확도 : {0:.3f}'.format(accuracy_score(y_test, vpred)))
#voting 분류기의 정확도 : 0.930