
과적합 방지를 하는 이유❓
머신러닝 모델에 train 데이터를 100% 학습시킨 후 test 데이터에 모델을 적용했을 때 성능이 생각보다 안나오는 경우가 많고, 이러한 현상을 Overfitting 되었다고 말한다.
모델이 내가 가진 학습데이터에 너무 과적합되어 학습한 상태에서는 이를 조금이라도 벗어난 케이스에 대해서는 예측율이 떨어지기 마련이다. Overfitting 을 방지하는 프로세스는 전체적인 모델 성능을 위해 매우 중요한 단계이다.
- 이 포스터에서는 과적합 방지에 대한 3가지 방법을 기술 할 예정이다.
train_test split: 데이터의 양이 많으나, 과적합이 발생한 경우K-Fold: k개의 data fold set을 만들어 학습도중에 k번 만큼 학습과 평가를 병행StratifiedKFold: 불균형한 분포(편향,왜곡)를 가진 레이블 데이터 집합을 위한 교차 검증
주로 K-Fold 교차 검증방식이 많이 이용되고 있다.
예제들에서 사용될 데이터셋(iris)은 아래 코드를 참고하자.
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
import numpy as np
iris = load_iris()
train_data = iris.data
train_label = iris.target
# 분류 모델
dt_clf = DecisionTreeClassifier().fit(X=train_data,y=train_label)
pred = dt_clf.predict(train_data)
print('예측값 : ',pred)
print('실제값 : ',train_label)
print('분류정확도 : ',accuracy_score(train_label,pred)) #실제값 , 예측값
#분류정확도 : 1.0 | 과적합 의심먼저 과적합 방지없이 결정나무모델 DecisionTreeClassifier 을 이용하여 분류정확도를 확인해봤다.
분류정확도가 1.0이 나오면서 과적합이 충분히 의심되는 수치가 나왔다.
1️⃣ train / test split
지난 포스트에서 많이 사용했던 방식.
데이터의 양이 많을때, 과적합이 발생한 경우 사용한다.
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(iris.data,iris.target,test_size=0.3, random_state=121)
dt_clf.fit(x_train,y_train)
pred2 = dt_clf.predict(x_test)
print('예측값 : ',pred2)
print('실제값 : ',y_test)
print('분류정확도 : ',accuracy_score(y_test,pred2)) #실제값 , 예측값
#분류정확도 : 0.95 | 과적합 의심- train / test 는 7:3 비율로 나누어 분류정확도를 확인했다.
0.95 의 수치가 나오면서 과적합방지를 하지 않았을때와 비교하면 0.5가 떨어진 수치를 보였다.
2️⃣ K-Fold legacy
train_test split 후 과적합 의심이 된다면 K-Fold 교차검증을 권장한다.
교차검증 가장 보편적인 방법으로, k개의 data fold set을 만들어 학습도중에 k번 만큼 학습과 평가를 병행한다.
이 과정은 위에서 train,test로 나뉘어진 데이터 중
train을 train / validation data로 추가 분리 후 학습이 이뤄진다.
from sklearn.model_selection import KFold
features = iris.data
label = iris.target
dt_clf = DecisionTreeClassifier(random_state=121)
kfold = KFold(n_splits=5)
cv_acc=[] #정확도 저장[]
n_iter = 0
print('iris shape',features.shape) #all = iris shape (150, 4)각 선언된 변수의 상세는 아래와 같다.
features: iris 데이터셋의 독립변수label: iris 데이터셋의 종속변수 (꽃종류)dt_clf: DecisionTreeClassifier 결정나무 모델을 생성kfold: 교차검증을 위한 KFold 객체를 생성. (5등분)cv_acc: for루프에서 매 회 분석시 도출되는 분류정확도를 저장할 list형 객체n_iter: 반복횟수 확인용
전체 행수 : 150. 학습데이터: 4/5(120개), 검증데이터: 1/5(30개) 비율로 분할해서 학습할 예정
for train_index, test_index in kfold.split(features):
xtrain, xtest = features[train_index],features[test_index] #kfold 5등분한 test-vali 데이터를 다시 담는다
ytrain, ytest = label[train_index],label[test_index]
#학습 및 예측
dt_clf.fit(xtrain,ytrain)
ypred = dt_clf.predict(xtest)
n_iter+=1
#반복할때마다 정확도 측정
acc = np.round(accuracy_score(ytest,ypred),2)
train_size = xtrain.shape[0]
test_size = xtest.shape[0] #여기서 test는 validation이다.
print('반복수 : {0}, \n교차 검증 정확도: {1}, \n학습데이터 크기 : {2}, \n검정데이터 크기 : {3}'.\
format(n_iter,acc,train_size,test_size))
print('반복수 : {0}, test set index : {1}...'.format(n_iter,test_index[:10]))
cv_acc.append(acc)
print('cv_acc : ',cv_acc) #[1.0, 1.0, 0.9, 0.93, 0.73]
print('평균 검증 정확도 : ',np.mean(cv_acc)) #평균 검증 정확도 : 0.912for 루프의 kfold.split(features) 로부터 발생되는 train_index, test_index 두 변수는 아래 그림의 형태를 따라 순차적으로 index를 출력한다.
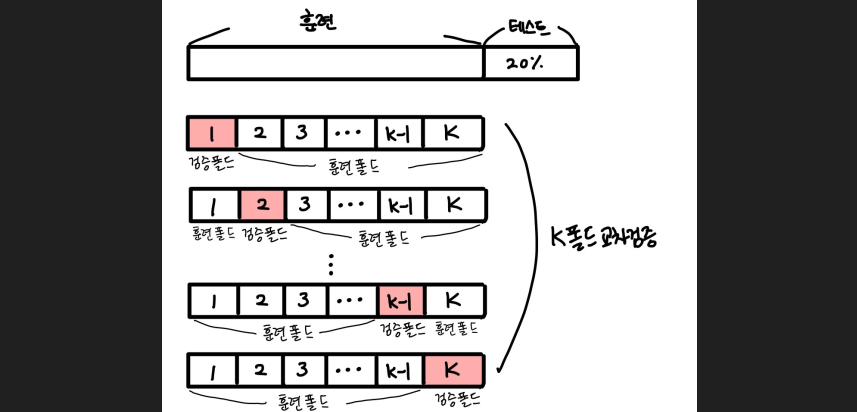
여기서 훈련폴드는 학습데이터 4/5 (120개) 에 해당하는 인덱스가 반환,
검증폴드는 검증데이터 1/5(30개) 에 해당하는 인덱스가 반환된다.
이를 이용해 실제 iris데이터셋에 인덱싱,슬라이싱으로 접목시켜 학습->저장을 반복한다.
- 원리
- 훈련세트를 K개의 폴드로 나눈다.
- 첫 번째 폴드를 검증 세트로 사용하고 나머지 폴드(K-1)를 훈련세트로 사용한다.
- 모델을 훈련한 후 검증세트로 평가한다.
- 차례대로 다음 폴드를 검증세트로 사용하여 반복한다.
- K개의 검증세트로 K번 성능을 평가한 후, 계산된 성능의 평균을 내어 최종 성능을 계산한다.
sklearn은 이 과정을 메소드로 지원한다.
2️⃣-2️⃣ K-Fold method
말 그대로 2번과정을 메소드 하나로 도출해낼 수 있다
from sklearn.model_selection import cross_val_score
data = iris.data
label = iris.target
score = cross_val_score(dt_clf,X=data,y=label, scoring='accuracy', cv=5) #accuracy 기준, k_fold=5 지정
print('교차 검증별 정확도 : ',np.round(score,2)) # [0.97 0.97 0.9 0.97 1. ]
print('교차 검증별 정확도 평균: ',np.round(np.mean(score),2)) #0.96cross_val_score 가 핵심 메소드. 파라미터는 아래와 같다.
- cross_val_score parameter
dt_clf: 적용 모델X: data. 독립변수y: label. 종속변수scoring: 도출 해낼 값. 여기서는 accuracy(분류정확도)로 지정했다.cv: k_fold 몇등분을 할지 결정.
3️⃣ StratifiedKFold
불균형한 분포(편향,왜곡) 를 가진 레이블 데이터 집합을 위한 교차 검증이다.
2번과정에서 for~in 객체만 바뀐 상태이다.
from sklearn.model_selection import StratifiedKFold
skfold = StratifiedKFold(n_splits = 5)
cv_acc = []
n_iter = 0
for train_index, test_index in skfold.split(features,label): #<<<<<< 변경
xtrain, xtest = features[train_index],features[test_index]
ytrain, ytest = label[train_index],label[test_index]
#학습 및 예측
dt_clf.fit(xtrain,ytrain)
ypred = dt_clf.predict(xtest)
n_iter+=1
#반복할때마다 정확도 측정
acc = np.round(accuracy_score(ytest,ypred),2)
train_size = xtrain.shape[0]
test_size = xtest.shape[0] #여기서 test는 validation이다.
print('반복수 : {0}, \n교차 검증 정확도: {1}, \n학습데이터 크기 : {2}, \n검정데이터 크기 : {3}'.\
format(n_iter,acc,train_size,test_size))
print('반복수 : {0}, test set index : {1}...'.format(n_iter,test_index[:10]))
cv_acc.append(acc)
print('StratifiedKFold 교차 검증별 정확도 : ',np.round(cv_acc,2)) #[0.97 0.97 0.9 0.97 1. ]
print('StratifiedKFold 교차 검증별 정확도 평균: ',np.round(np.mean(cv_acc),2)) #0.96kfold.split(features) -> skfold.split(features,label)
kfold 객체와 그의 파라미터에 label을 추가했다.
reference : https://hyjykelly.tistory.com/53
