Abstract
pre-trained 언어 모델(PLM)에 대한 Prompt는 pre-training tasks와 다양한 downstream tasks간의 격차를 해소함으로써 놀라운 성능을 보여 주었다.
이러한 방법 중 PLM을 freeze하고 soft prompt만 tuning하는 prompt tuning은 대규모 PLM을 downstream task에 적응시키는 효율적이고 효과적인 솔루션을 제공.
downstream data가 충분할 때 prompt tuning이 기존의 full-model tuning과 비슷한 성능을 보이지만, prompt tuning의 적용을 방해할 수 있는 few-shot learning 설정에서 훨씬 나빠졌다.
논문에서는 이 낮은 성능을 soft prompt를 초기화하는 방식 때문이라고 본다.
더 나은 초기화를 얻기 위해 pre-training 단계에 soft prompt를 추가하여 prompt를 pre-train할 것을 제안. => 이 이름을 Pre-trained Prompt Tuning frameword ("PPT")
PPT의 일반화를 위해 유사한 classification task를 통일된 task 형식으로 하고, 이 통일된 task에 대한 soft prompt를 pre-train한다.
광범위한 실험에 따르면 downstream task에 대해 pre-trained prompt를 tuning하면 전체 데이터와 few-shot 설정 모두에서 full-model fine-tuning에 도달하거나 능가할 수 있다.
code: https://github.com/thu-coai/PPT.
1. Introduction
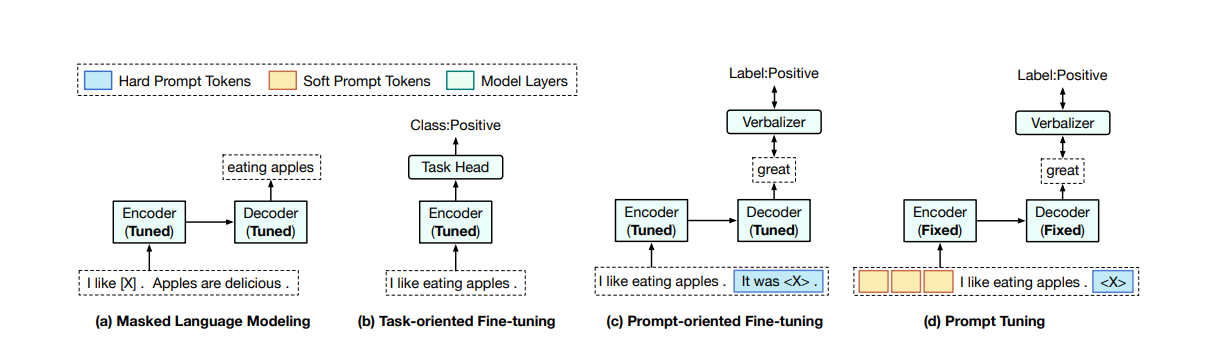 Figure 1: pre-training의 paradigms (masked language modeling), full-model tuning (task-oriented fine-tuning and prompt-oriented fine-tuning), prompt tuning. verbalizer는 task labels을 구체적인 단어에 매핑하는 기능이다. < X >는 일반적인 pre-trained encoder-decoder model의 mask를 의미한다.
Figure 1: pre-training의 paradigms (masked language modeling), full-model tuning (task-oriented fine-tuning and prompt-oriented fine-tuning), prompt tuning. verbalizer는 task labels을 구체적인 단어에 매핑하는 기능이다. < X >는 일반적인 pre-trained encoder-decoder model의 mask를 의미한다.
pre-trained language model들을 Fine-tuning하는 것은 최근 몇 년 동안 큰 발전을 이루었다(BERT).
전체 모델 매개 변수를 조정함으로써 대규모 unlabeled 말뭉치에서 얻은 다양한 지식은 다양한 NLP 작업을 처리할 수 있으며 처음부터 학습 모델에 접근하는 방식보다 더 나은 결과를 얻을 수 있다.
이러한 full-model tuning을 "FT"라고 부르겠다.
FT 방법의 두가지 mainstream

첫 번쨰는 task-oriented fine-tuning으로, PLM위에 task-specific head가 추가된 다음 해당 training data에서 task-specific 목표를 최적화하여 전체 모델을 fine-tuned한다.
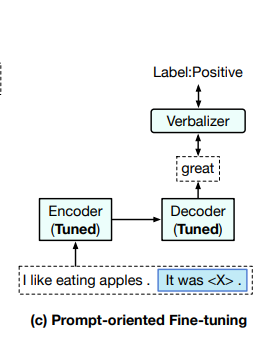
두 번째는 PLM의 지식을 조사하기 위해 언어 prompt를 사용하는 최근 연구(GPT-3)에서 영감을 얻은 prompt-oriented fine-tuning이다(PET).
prompt-oriented fine-tuning에서 데이터 샘플은 prompt token을 포함하는 sequences로 변환되고, downstream tasks은 언어 모델링 문제로 형식을 갖춘다.
"It was < X >" prompt를 문장에 추가하여, mask 위치에 "great" 또는 "terrible"를 예측하여 PLM으로 감정을 결정할 수 있다.
task-oriented fine-tuning과 비교하면 prompt-oriented fine-tuning은 pre-training objectives와 비슷하다(masked language modeling). 따라서 PLM에서 지식을 더 잘 사용하고 종종 더 나은 성능을 얻는 데 도움이 된다.
FT는 유망한 결과를 보였지만 모델 규모의 급속한 성장과 함께 각 downstream task에 대해 전체 대형 모델을 fine-tuning하고 저장하는데 비용이 많이 든다.
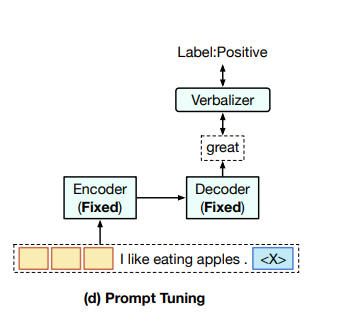
이러한 문제를 해결하기 위해, (논문 : The Power of Scale for Parameter-Efficient Prompt Tuning 참조 : https://velog.io/@jukyung-j/The-Power-of-Scale-for-Parameter-Efficient-Prompt-Tuning-%EB%A6%AC%EB%B7%B0)은 대형 PLM을 downstream tasks에 FT보다 저렴하게 적응시키기 위한 Figure 1 (d)에서 본 것과 같이 prompt tuning을 제안했다.
특히 PT는 hard prompts(개별 언어 구문) 대신 연속 임베딩으로 구성된 soft prompt를 사용합니다.
이러한 연속적인 prompt는 일반적으로 랜덤하게 초기화되며 end-to-end로 학습됩니다.
각 downstream task에 대한 전체 모델이 저장되는 것을 피하기 위해, PT는 모든 PLM 매개 변수를 freeze하고 중간 계층과 task-specific components를 추가하지 않고 soft prompt만 조정합니다.
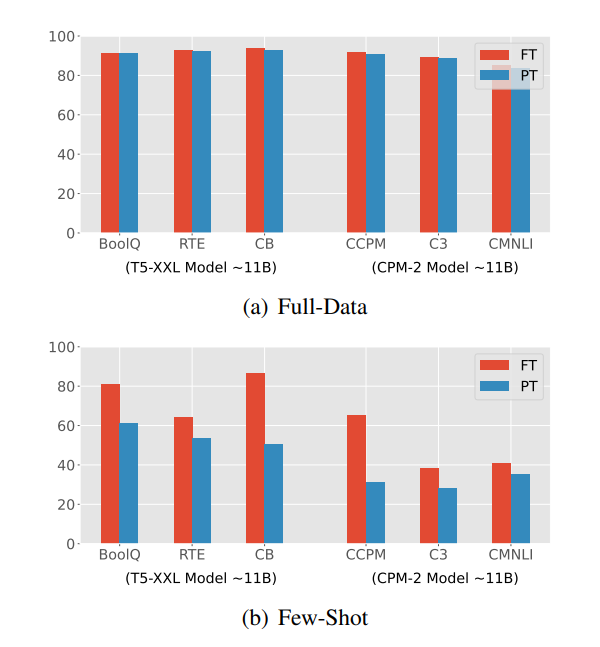 Figure 2: PT와 FT의 비교. 튜닝된 prompt는 PLM의 토큰 임베딩(4096 dimensions)과 동일한 차원의 학습 가능한 임베딩 100개로 구성된다. 이 모든 결과는 11B PLMs T5 및 CPM-2를 기반으로 한다. FT는 모든 11B parameters를 최적화해야 하는 반면 PT는 410K prompt parameters만 학습한다.
Figure 2: PT와 FT의 비교. 튜닝된 prompt는 PLM의 토큰 임베딩(4096 dimensions)과 동일한 차원의 학습 가능한 임베딩 100개로 구성된다. 이 모든 결과는 11B PLMs T5 및 CPM-2를 기반으로 한다. FT는 모든 11B parameters를 최적화해야 하는 반면 PT는 410K prompt parameters만 학습한다.
PT는 두가지 이점이 있다.
첫 번째는 soft prompt는 hard prompt와 비교하여 end-to-end로 학습될 수 있다.
두 번째는 PT는 대규모 PLM의 실용화를 위한 효율적이고 효과적인 paradigm으로, downstream data가 충분할 때 FT에 필적한다(Figure 2(a)).
하지만, Figure 2(b)에서 볼 수 있득이, PT가 few-shot setting에서 FT보다 훨씬 나쁜 성능을 보여, 다양한 low-resource scenarios에서 PT의 적용을 방해할 수 있다는 것을 발견했다.
따라서 본 논문에서는, PT를 통해 few-shot 학습을 위한 PLM을 효율적이고 효과적으로 사용하는 방법을 탐구한다.
구체적으로는 기존의 대부분의 작업에서 무시되고 있는 Section 2의 PLM에 대한 PT의 효과를 경험적을 분석하기 위한 파일럿 실험을 실시한다.
우리의 발견은 다음과 같다:
(1) verbalizer 선택은 성능에 큰 영향을 미친다.
(2) soft prompt를 단순히 구체적인 word embedding으로 초기화하는 것만으로는 성능은 향상되지 않는다.
(3) soft prompt와 hard prompt를 결합하는 것은 도움이 된다.
(4) 이 모든 방법은 few-shot prompt tuning 문제를 잘 처리할 수 없다.
이러한 것들을 통해 PLM의 prompt searching이 사소한 것이 아니라 신중하게 initialized soft prompt token이 중요하다는 것을 보여준다.
model이 적절한 pompt를 찾는 것을 돕기 위해 대규모 unlabeled corpora에서 self-supervised tasks로 이러한 tokens을 pre-train한다.
pre-trained prompt의 일반화를 보장하기 위해, 일반적인 분류 작업을 위한 sentence pair classification, multiple-choice classification, single-text classification 이렇게 세 가지 형식으로 그룹화 하고, 각 형식은 하나의 self-supervised pre-training task에 해당한다.
또한 이러한 형식 중에서 multiple-choice classification이 더 일반적이며 모든 분류 작업을 이 형식으로 통합할 수 있다.
그래서 우리는 Pre-trained Prompt Tuning framework를 "PPT"라고 명명한다.
few-shot scenarios에서 T5-XXL, mT5-XXL 및 CPM-2의 세가지 11B PLM을 기반으로 PPT를 평가한다.
mT5 : (multilingual pre-trained T5)
CPM : large-scale Chinese-centered pre-trained models.
실험에 따르면 PPT는 PT를 대폭 개선해 FT 방법에 도달하거나 심지어 능가할 뿐만 아니라 few-shot 분산을 줄일 수 있다.
PPT는 PT의 parameter 효율성을 유지하며, 이는 대규모 PLM에 대한 향후 적용에 중요하다.
2. Pilot Experiments
 Table 1: SST-2에 대한 few-shot learning(32 samples)에 대한 hard prompt와 verbalizers가 PT에 미치는 영향. 는 soft prompt를 표현한다. 는 입력 문장을 나타낸다. "Man"은 수동으로 설계된 hard pormpt를 의미하며 "Gen"은 자동 생서된 hard prompt를 의미한다. hard prompt의 선택과 verbalizer는 모델의 성능에 상당한 영향을 미친다.
Table 1: SST-2에 대한 few-shot learning(32 samples)에 대한 hard prompt와 verbalizers가 PT에 미치는 영향. 는 soft prompt를 표현한다. 는 입력 문장을 나타낸다. "Man"은 수동으로 설계된 hard pormpt를 의미하며 "Gen"은 자동 생서된 hard prompt를 의미한다. hard prompt의 선택과 verbalizer는 모델의 성능에 상당한 영향을 미친다.
이 섹션에서는 few-shot learning에 대한 PT의 pilot 실험을 볼 것이다.
hybrid prompt tuning, verbalizer 선택 및 실제 단어 초기화를 포함한 세 가지 전략을 분석합니다.
(논문 : The Power of Scale for Parameter-Efficient Prompt tuning)을 따라 T5-XXL(11B parameters)로 PT를 테스트하고 100개의 조정가능한 soft prompt token을 사용한다 (논문에서 100개의 soft prompt token을 사용하여 최고의 성능 달성).
(논문 : It's Not Just Size That Matters: Small Language Models Are Also Few-shot Learners)에 이어, 원래 training data에서 training set 을 구성할 32개의 샘플을 무작위로 선택한다.
hyper-parameter를 조정하기 위해, 원래 training data에서 validation set 를 구성하고
를 보장하여 few-shot learning 설정을 시뮬레이션 한다(True Few-Shot Learning with Language Models).
original validation set를 test set 로 사용한다. 이는 를 의미한다.
2-1. Hybrid Prompt Tuning
hybrid prompt tuning에서는 soft prompt와 hard prompt가 모두 사용됩니다.(PTR: Prompt Tuning with Rules for Text Classification)
하지만 이전 작업은 전체 모델과 함께 soft prompt를 학습시킨다.
prompt token만 조정할 수 있는 PT에서 hybrid prompt의 효과는 충분히 조사되지 않았다.
Table 1에서 감성 분류 문제에 대한 soft prompt P와 수동으로 설계된 3개의 hard prompt 및 자동 생성된 hard prompt 2개를 결합한 결과를 보여준다.
hard prompt가 PT를 향상시키지만 여전히 FT보다 성능이 낮다는 것을 알 수 있다.
또한 다양한 hard prompt는 성능에 큰 영향을 미치므로 prompt 설계 및 선택에 많은 인적 노동이 필요하다.
2-2. Verbalizer Selection
Verbalizer는 task-specific labels을 구체적인 tokens에 매핑한다.
예를 들어 Figure 1 (c), (d)에서 verbalizer는 "Positive"라는 label을 "great"에 매핑한다.
Table 1을 보면 verbalizers의 선택이 성능에 큰 영향을 미친다는 것을 알 수 있다.
일반적으로 해당 label의 의미를 설명하는 일반적인 단어가 잘 동작한다.
Section 3의 PPT용 verbalizer 선택에 대해서도 설명하겠다.
2-3. Real Word Initialization
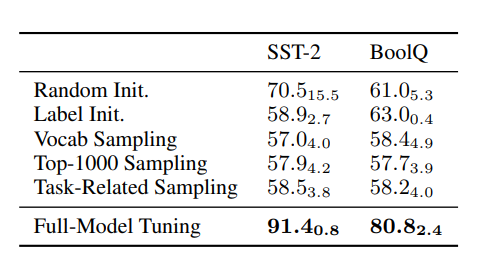 Table 2: PT에서 prompt 초기화를 위해 구체적인 단어를 선택하는 다양한 전략을 가진 Few-shot learning 성능.
Table 2: PT에서 prompt 초기화를 위해 구체적인 단어를 선택하는 다양한 전략을 가진 Few-shot learning 성능.
"Label Init": label 단어의 임베딩을 사용. "Vocab Sampling": vocabulary에서 무작위로 단어를 샘플링한다. "Top-1000 Sampling": pre-training 말뭉치에서 가장 빈번한 1000개의 단어에서 무작위로 단어를 샘플링한다. "Task-Related": downstream data에서 단어를 무작위로 추출한다. 평가를 위해 classification accuracy(%)를 사용한다.
실제 단어 초기화에서는, 구체적인 단어의 임베딩을 사용하여 soft prompt를 초기화하고 네 가지 초기화 전략을 테스트한다.
이 접그법의 효과는 이전 연구에서 small PLM(3B parameters보다 작은)에서 검증되었다.
그러나 SST-2 및 BoolQ(Table 2) 실험에서, 11B 모델의 경우, 실제 단어 초기화가 few-shot scenarios의 성능에 부정적인 영향을 미치는 것을 발견했다.
이는 samll model에 대한 observation이 large model에 직접 적용될 수 없으며 soft prompt에 대한 좋은 초기화를 찾는 것은 아직 탐구되지 않았단느 것을 시사한다.
요약하자면, 위의 개선 사항은 PT가 few-shot setting에서 FT와 유사한 결과를 달성하는 데 도움이 되진 않지만, 여전히 PT 성능에 영향을 미치는 주요 요인이다.
다음섹션에서는, PPT framework를 설명하고 실험에서 PPT가 좋은 prompt 초기화를 제공할 뿐만 아니라, 좋은 verbalizer를 활용하고 hybrid prompt를 보완한다는 것을 보여 준다.
3. Pre-trained Prompt Tuning(PPT)
이 섹션에서는 prompt를 pre-train하고 이러한 pre-trained prompt를 특정 작업에 사용하는 방법을 포함하여 PPT의 framework를 설명합니다.
3.1 Overview
T5와 PT의 접근법에 따라, 모든 downstream tasks을 text-to-text 형식으로 해결한다.
Figure 1 (c)에 나타난 바와 같이, pre-training과 downstream tasks사이의 격차를 줄이기 위해, prompt oriented fine-tuning은 downstream tasks을 cloze-style로 변환합니다.
분류를 예로 들면, 입력 문장 와 label 이 주어지면, 패턴 매핑 는 먼저 를 새로운 sequence 로 변환하기 위해 적용됩니다. 여기서 는 PLM의 vocabulary입니다.
는 일부 prompt token을 힌트로 추가할 뿐만 아니라 mask token 을 유지하여 PLM이 마스크된 위치에서 토큰을 예측할 수 있도록 한다.
그런 다음 verbalizer 를 사용하여 를 일부 label tokens 에 매핑합니다.
와 에서 분류 작업은 pattern-verbalizer pair 으로 나타낼 수 있다.
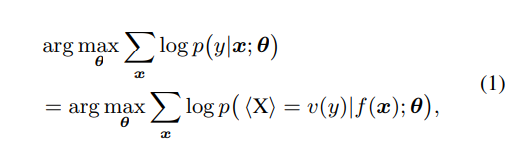
여기서 θ는 모든 조정 가능한 parmeters, 특히 PLM의 parameter를 나타냅니다.
편의상, "PVP"를 사용하여 이 pattern-verbalizer pair를 나타냅니다.
PT에서 soft prompt의 집합 P는 sequence의 시작 부분에 연결되고 모델 입력은 가 됩니다. 여기서 는 연결 연산입니다.
tuning P에 의해, (1)식은 다음과 같이 대체됩니다.

대규모 PLM의 power로 인해, (2)식은 전체 데이터 설정에서 FT 방법과 유사한 것으로 검증되었다.
그러나 효과적인 soft prompt를 학습하기는 어려우며, 이는 다양한 few-shot scenarios에서 성능이 저하될 수 있다.
parameter 초기화는 일반적으로 모델 훈련과 최적화의 난이도에 큰 영향을 미치며, 우리의 파일럿 실험은 기존 초기화 전략이 대규모 PLM의 PT성능에 부정적인 영향을 미치는 것을 보여주었다.
이러한 파일럿 실험에 대한 자세한 내용은 Section 4를 참조하세요.
 Figure 3: sentence pair tasks에서 사용되는 PPT의 예시입니다. P는 soft prompt를 나타냅니다.는 T5와 CPM-2와 같은 전형적인 encoder-decoder 모델의 mask를 의미합니다.
Figure 3: sentence pair tasks에서 사용되는 PPT의 예시입니다. P는 soft prompt를 나타냅니다.는 T5와 CPM-2와 같은 전형적인 encoder-decoder 모델의 mask를 의미합니다.
최근 pre-training은 좋은 모델 초기화를 찾는 효과적인 방법으로 입증되었다.
이에 영감을 받아, soft prompt를 pre-train할 것을 제안한다.
downstream tasks의 일부 그룹이 unlabeled pre-training corpora에 구축된 특정 self-supervised과 관련이 있다는 것을 알아차렸다.
예를 들어, 자연어 추론 및 문장 유사성과 같은 sentence-pair classification형태의 일부 tasks은 pre-training 단계에서 사용되는 다음 문장 예측(NSP)작업과 유사하다.
Figure 3에서 보듯이, 이 tasks은 모두 두 문장을 입력으로 하고 그들의 의미를 비교합니다.
따라서 NSP에 의해 pre-trained된 soft prompt는 이러한 sentence-pair tasks에 대한 좋은 초기화가 될 수 있습니다.
downstream tasks을 m개의 그룹 {}로 나눌 수 있다고 가정합니다(는 downstream tasks 를 포함하는 집합입니다). : {},
각 그룹에 대한 해당 pre-training task 를 설계합니다.
모든 모델 parameter가 고정된 상태에서 이러한 작업에 대한 pre-training soft prompt가 표시되면 pre-trained prompts {}가 표시됩니다.
그런 다음 각 task에 대한 in 에 대해 를 soft prompt 초기화하여 (2)식을 계속 최적화합니다.
