논문리뷰
1.PPT: Pre-trained Prompt Tuning for Few-shot Learning 리뷰

pre-trained 언어 모델(PLM)에 대한 Prompt는 pre-training tasks와 다양한 downstream tasks간의 격차를 해소함으로써 놀라운 성능을 보여 주었다.이러한 방법 중 PLM을 freeze하고 soft prompt만 tuning하는 p
2.The Power of Scale for Parameter-Efficient Prompt Tuning 리뷰
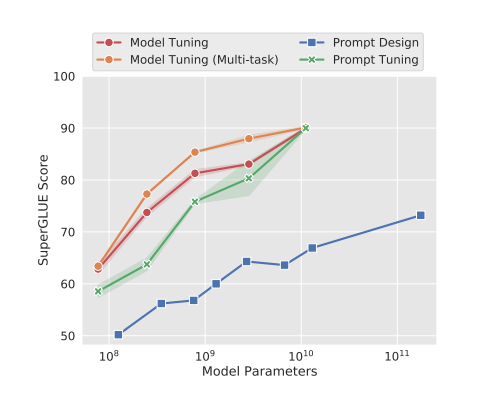
이 연구에서, 특정 downstream tasks을 수행하기 위해 frozen 언어 모델을 condition하는 soft prompt를 학습하기 위한 간단하지만 효과적인 메커니즘인 prompt tuning을 볼 것이다.GPT-3에서 사용되는 개별 텍스트 prompt와
3.Causal Inference in Natural Language Processing: Estimation, Prediction, Interpretation and Beyond (자연어 처리에서의 인과적 추론: 추정, 예측, 해석 및 그 이상)
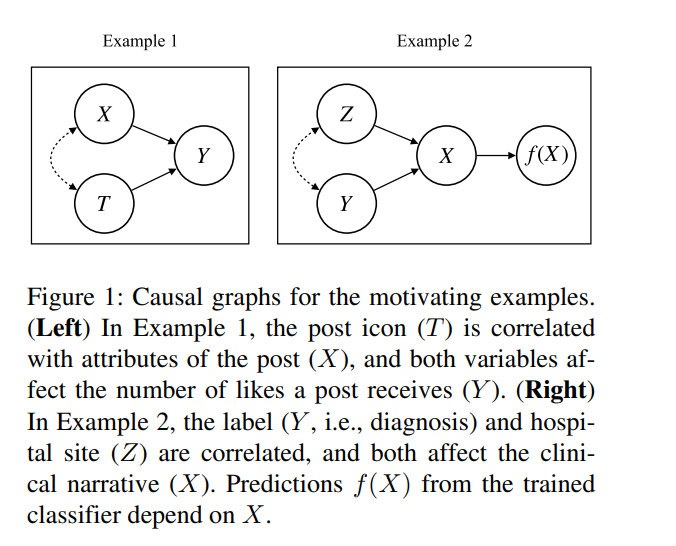
과학 연구의 근본적인 목표는 이노가 관계에 대해 배우는 것이다. 그러나 예측 작업에 더 중점을 둔 자연어 처리(NLP)에서 인과 관계는 중요성을 갖지 못했다. 이러한 구분은 희미해지고 있다. 그럼에도 불구하고, NLP의 인과 관계에 대한 연구는 고유한 속성을 가진 텍스
4.Improving NLP with causality
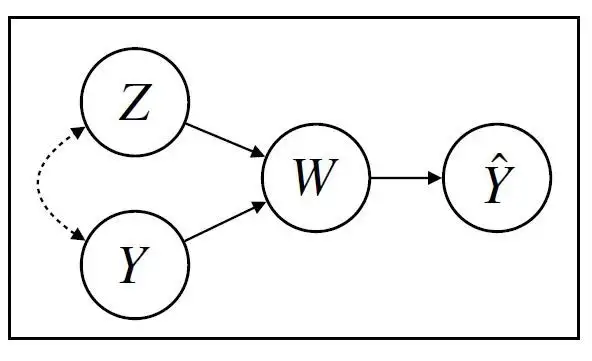
BERT 같은 NLP 모데에 대한 간략한 소개로 시작하고, 본직적인 약점을 강조하며, 인과 관계가 기존 단점을 해결할 수 있는 광범위한 방법을 제안한다.
5.맞춤법 논문 정리
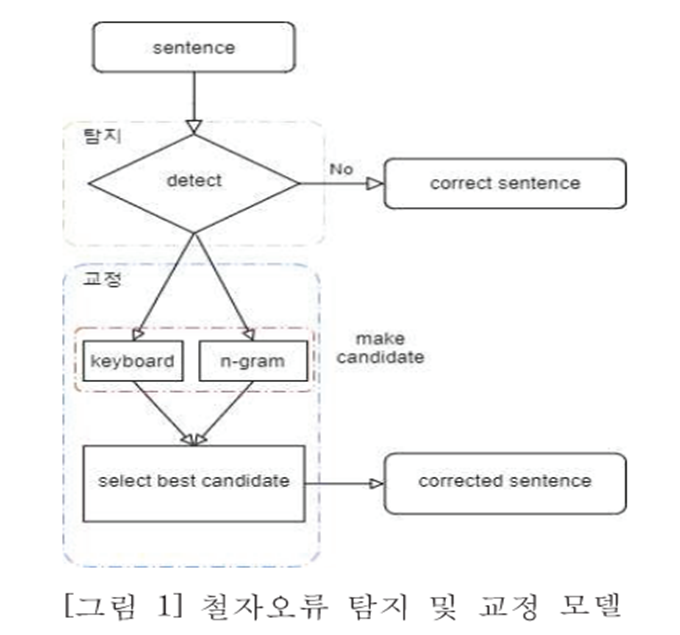
맞춤법 논문 관련 정리
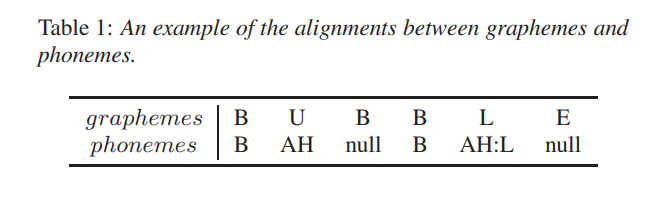
6.[논문리뷰] The SIGMORPHON 2020 Shared Task on Multilingual Grapheme-to-Phoneme Conversion
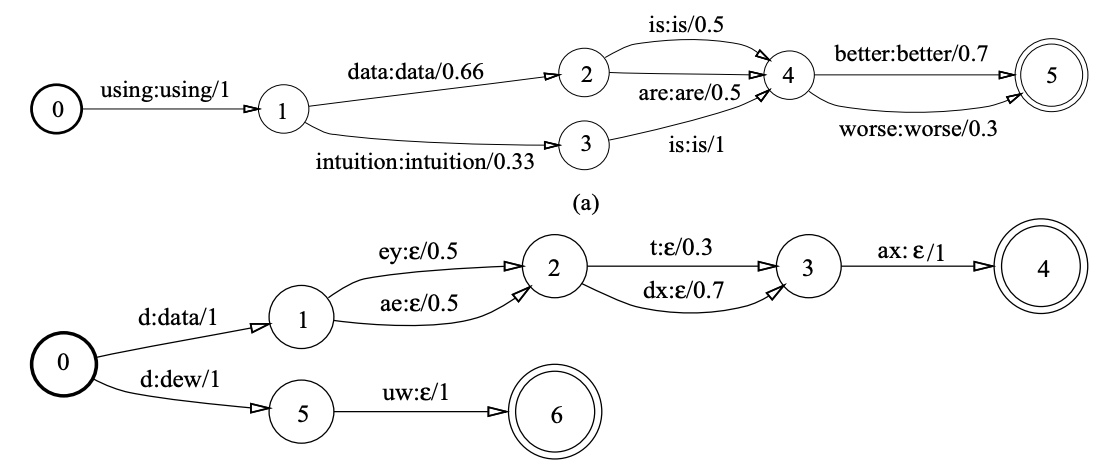
TTS, Pronunciation model
7.[논문리뷰]Massively Multilingual Pronunciation Mining with WikiPron

Wikipron 논문
8.[논문리뷰]DeepSPIN at SIGMORPHON 2020: One-Size-Fits-All Multilingual Models
SIGMORPHON2020의 한국어 성능이 제일 좋은 DeepSPIN 리뷰
9.[논문리뷰]Ensemble Self-Training for Low-Resource Languages: Grapheme-to-Phoneme Conversion and Morphological Inflection
우리는 최적의 앙상블을 학습하고 검색하는 반복적인 데이터 증강 프레임워크를 제시하고, 동시에 self-training 스타일로 새로운 학습 데이터에 주석을 달았음이 프레임워크를 두 개의 SIGMORPON 2020 shared task에 족용: G2P변환과 morphol
10.[논문 리뷰] Neural Grapheme-to-Phoneme Conversion with Pre-trained Grapheme Models

BERT를 이용한 G2P
11.[논문 리뷰]Incorporating BERT into Neural Machine Translation
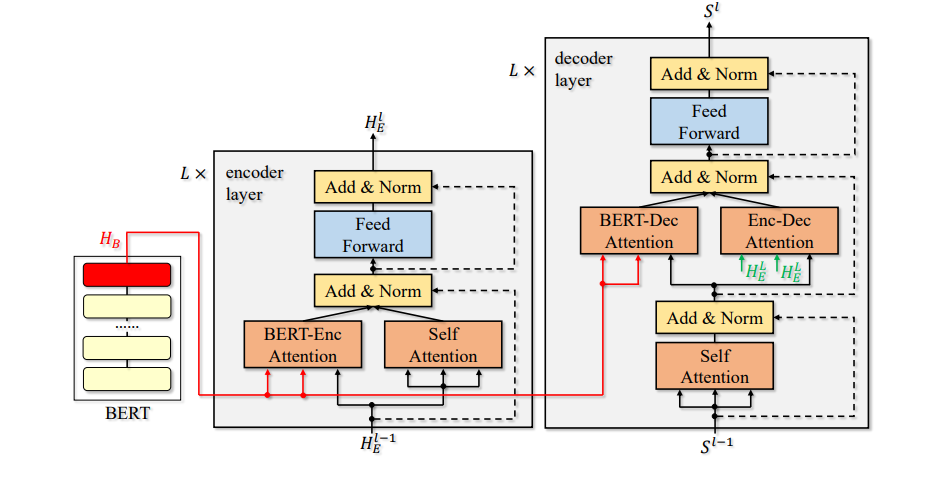
GBERT 관련한 BERT-fusing
12.[논문리뷰] Results of the Second SIGMORPHON Shared Task on Multilingual Grapheme-to-Phoneme Conversion

SIGMORPHON 2021 G2P
13.[논문리뷰]Token-Level Ensemble Distillation for Grapheme-to-Phoneme Conversion
MS token-level ensembel distillation
14.[챗봇] Chatbot 관련 정리
GPT 3.5, instruct GPT, ChatGPT, Blender, LaMDA
15.맞춤법 간단 정리
BERT 맞춤법 논문 정리
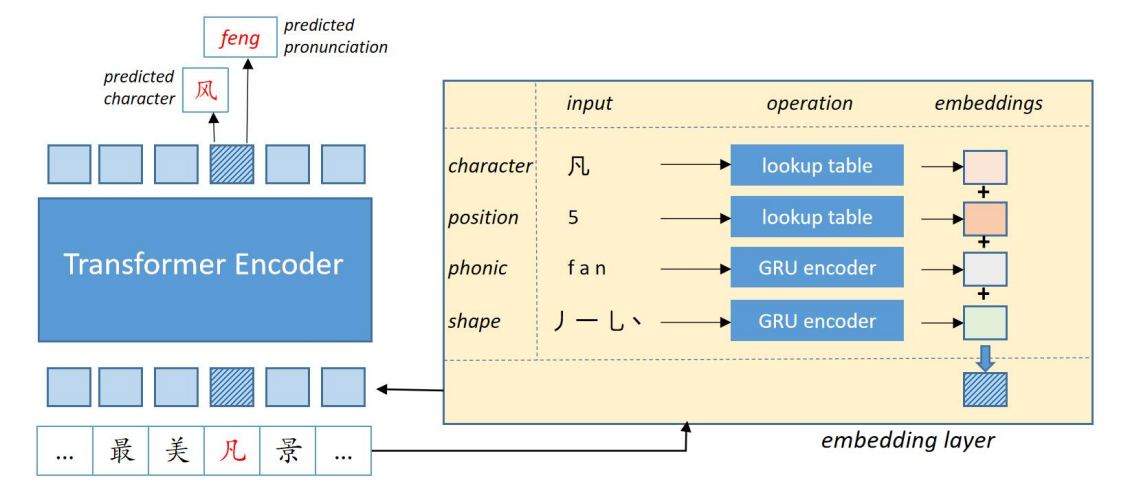
16.[논문리뷰] Correcting Chinese Spelling Errors with Phonetic Pre-training
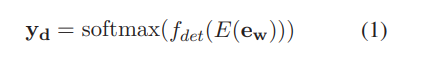
음성 정보 이용한 BERT
17.[논문 리뷰]GECToR - Grammatical Error Correction: Tag, Nor Rewrite
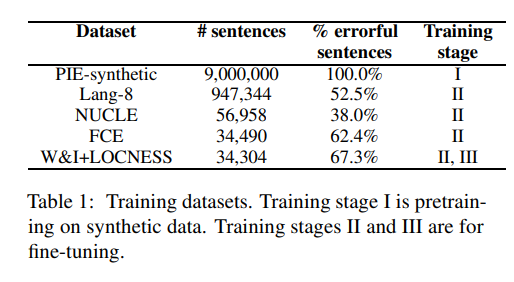
Roberta detection
18.[논문 리뷰]A Simple Recipe for Multilingual Grammatical Error Correction
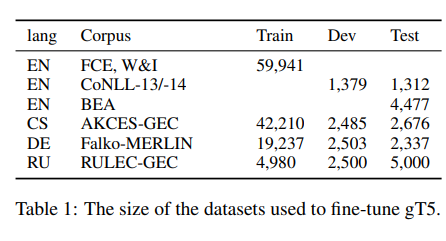
T5 맞춤법
19.[논문 리뷰]Encoder-Decoder Models Can Benefit from Pre-trained Masked Language Models in Grammatical Error Correction

BERT-fuse mask, GED
20.[논문 리뷰] Stronger Baselines for Grammatical Error Correction Using a Pretrained Encoder-Decoder Model
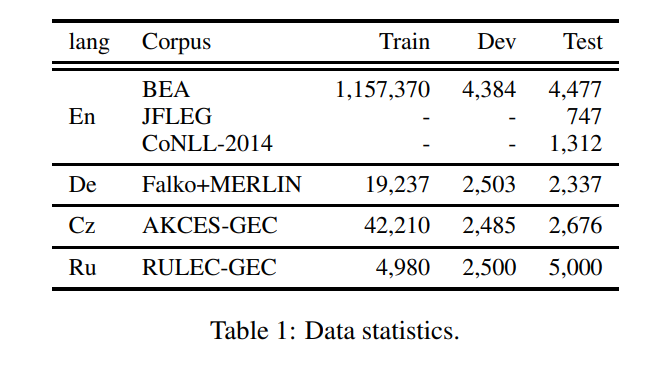
BART 파인 튜닝한 논문
21.[논문 리뷰]K-NCT: Korean Neural Grammatical Error Correction Gold-Standard Test Set Using Novel Error Type Classification Criteria
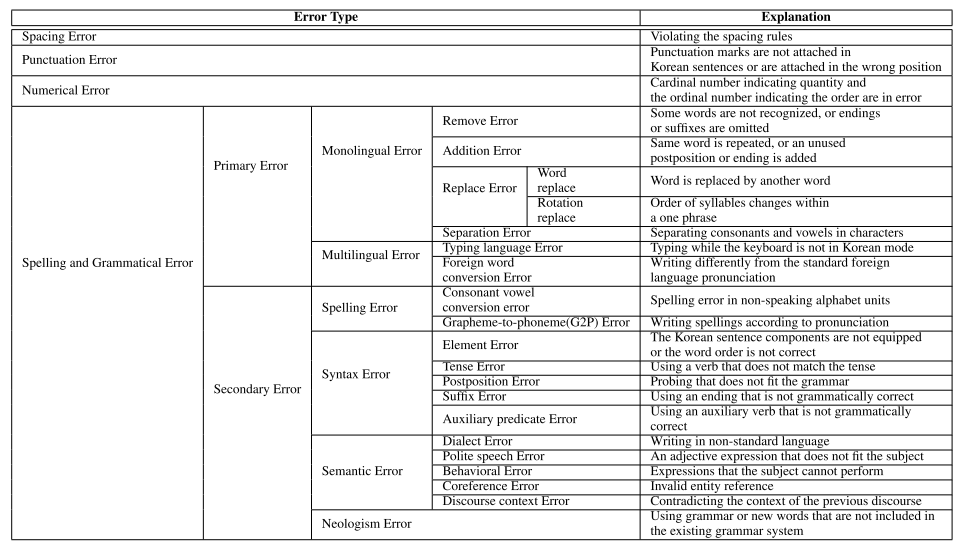
맞춤법 데이터셋
22.[논문리뷰] Active Self-Supervised Learning: A Few Low-Cost Relationships Are All You Need
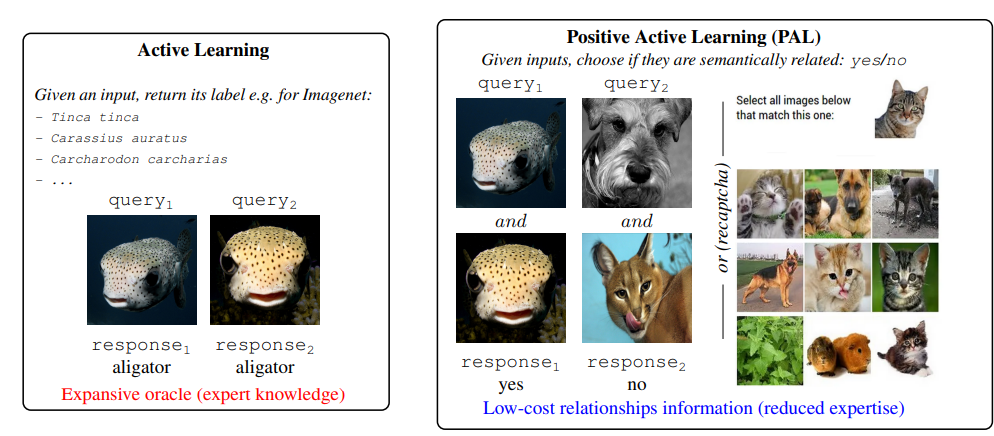
Self-Supervised Learning(SSL)은 레이블이 없는 데이터에서 transfer 가능한 representation을 학습하기 위한 선택 솔루션으로 떠오름하지만 SSL은 의미론적으로 유사한 샘플(positive views)을 구축해야 함이러한 지식이 필
23.[논문 리뷰] A Chinese Spelling Check Framework Based on Reverse Contrastive Learning
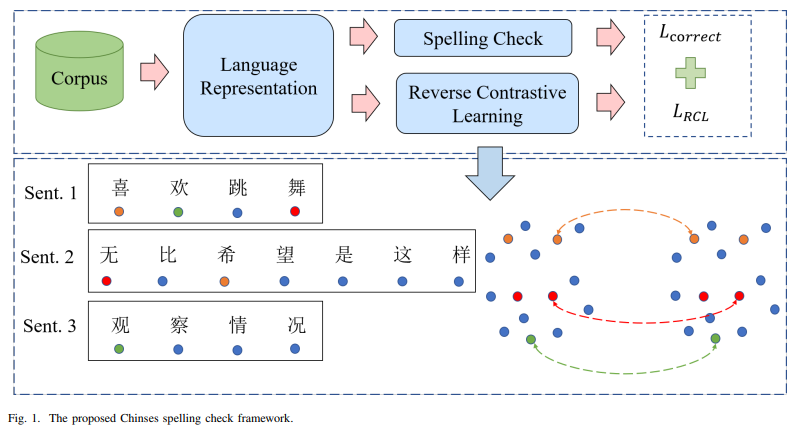
기존 연구는 text representation을 향상시키고 multi-source 정보를 사용하여 모델의 detection과 correction의 성능을 향상시키는 것을 목표로 하지만 혼동하기 쉬운 단어를 구별하는 능력을 향상시키는 데 크게 attention X유사한
24.[논문 제목] Frustratingly Easy System Combination for Grammatical Error Correction
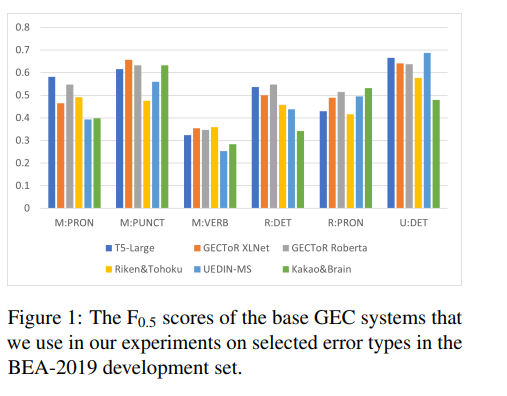
문법 오류 수정(GEC)를 위한 시스템 조합을 간단한 이진 분류로 공식화간단한 로지스틱 회귀 알고리즘이 GEC 모델을 결합하는 데 매우 효과적CoNLL-2014 tast에서 가장 높은 기본 GEC 시스템의 F0.5 점수를 4.2점 BEA-2019 test에서 7.2점
25.[논문리뷰] Mistral 7B

Mistral 7B은 Llama2(13B)보다 모든 평가 벤치마크에서 능가했고 Llama1(34B)보다 reasoning, mathmatics, code generation 부분에서 능가더 빠른 추론을 위해 grouped-guery attention(GQA)릃 활용하고