Abstract
- 최근 G2P conversion은 seq2seq task로 간주, RNN 또눈 CNN 기반 인코더 디코더 프레임워크 모델링
(1) 레이블이 없는 추가 데이터에서 knowledge를 distilling하여 정확도 높임
(2) 모델 크기를 줄이지만 높은 정확도 유지할 수 있는 G2P 변환을 위한 token-level ensemble disillation
- 이 두가지 온라인에서 실용적이고 유용
- token-level knowledge distillation 사용해 seq2seq 보다 성능 좋음
- 정확도 향상 위해 RNN 또는 CNN기반 모델 대신 트랜스포머 채택
- CMUDict dataset과 내부적으로 영어 데이터셋에 대해 실험
- CMUDict에서 WER 19.88%달성 이전 작업보다 4.22%이상 능가
1. Introduction
- G2P conversion은 seq2seq task로 볼 수 있으며 인코더-디코더 프레임워크에 의해 모델링
- 학습 데이터는 항상 사람의 레이블링을 하기 떄문에 레이블링되지 않은 데이터를 추가로 활용하는 방법은 G2P conversion 성능을 개선하는데 중요
- 대규모 또는 앙상블 모델은 시스템에 배치할 때 비용이 많이 듬
- 우린 token-level ensemble distillation 제안
- knowledge distillation을 사용해 레이블이 없는 많은 양의 단어 활용
구체적으론 레이블이 지정되지 않은 grapheme sequence가 주어진 확률 분포뿐만 아니라 phoneme sequence를 생성하도록 teacher model을 학습시키고,
레이블이 지정되지 않은 grapheme sequence와 생성된 phoneme sequence를 pesudo labeled data로 간주하여 원래 학습데이터에 추가 - 앙상블을 위한 다양한 모델(CNN, RNN, Transformer)를 학습하여 더 높은 정확도를 얻고, 앙상블 모델의 지식을 다시 distillation를 통해 온라인 배포에 적합한 경량 모델로 이전
Transformer를 기본 인코더-디코더 모델 구조로 채택
- CMUDict 0.7b와 내부 데이터셋에 대한 실험, 웹에서 크롤링된 레이블이 없는 추가 단어도 활용
- 제안된 방법은 이전 연구에 비해 wer 4.22% 향상
- 특히 Transformer 모델은 RNN, CNN 보다 높은 정확도, token-level distillation은 sequence-level distillation보다 성능 좋음
- g2p conversion을 위한 token-level ensembel distillation 제안
- 레이블이 지정되지 않은 단어를 사용해 g2p 정확성 향상시킨 최초의 사례, 트랜스포머를 도입에 더 나은 성능 달성
- CMUDict에서 SOTA 달성해 이전 결과보다 WER 4.22% 향상
2. Background
2.1 Grapheme-to-Phoneme conversion
- G2P 변환은 pheoneme sequence(발음)을 grapheme sequence(단어)에 따라 생성하는 과정
- 철자와 발음이 일부 언어(예: 언어)에서는 정확하게 일치하지 않음
- 게다가, grapheme과 phoneme사이의 정렬은 복잡
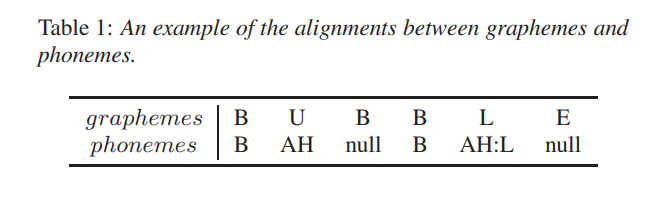
- 표1에서 보듯이, grapheme은 phoneme이 없건, 단일 pheoneme일 수도 있고 많은 phoneme에 해당할 수 있음
- seq2seq모델이 n-gram모델 보다 우수
- 본 연구에선 레이블이 없는 단어로 G2P 변환의 정확도를 높이고, 온라인 배포를 위한 모델 크기를 줄일 수 있느 transformer 모델 기반 token-level distillation 제안
3. Token-level Ensemble Distillation
3.1 Token-Level Knowledge Distillation
- {}는 쌍으로 된 grapheme 과 phoeneme sequence로 구성된 학습 말뭉치
- 말뭉치 D에서 negative log-likelihood loss를 최소화가 목표
3.2 Ensemble Distillation with Diverse Models
- knowledge distillation는 앙상블 모델의 지식을 single model로 distill하는 효과
- Transformer, Bi-LSTM, convolutional seq2seq model 선택
3.3 Knowledge Distillation with Unlabeled Source Words
- 뉴스나 위키피디아의 lexicon 말뭉치에서 레이블이 없는 grapheme을 쉽게 얻을 수 있음
- knowledge distillataion은 레이블이 없는 source data를 사용하는 방법 제공
- teacher model은 레이블이 지정되지 않은 source grapheme sequence가 주어지면 target phoneme sequence를 생성할 수 있으며, 생성된 phoneme sequence는 student model의 레이블로 사용
- 레이블이 없는 데이터가 많을 수록 teacher model의 지식을 student model로 distill하는데 도움
- 이 작업에서 레이블이 지정되지 않은 source words에 대한 token-level knowledge distillation 사용
4. Experiments and Results
4.1 Experimental Setup
4.1.1 Datasets
- CMUDict 0.7b 2. our internal dataset
