모두의연구소 데싸 4기 과정의 첫 번째 메인 프로젝트인 DATAthon이 시작되었다 😊
프로젝트 진행 중에는 실험 과정을 기록하고 성과를 내기에도 시간이 부족했던 터라 데이터톤이 마무리된 지금, 시작부터 되돌아보면서 회고를 담아 진행 과정을 기록해 보기로 했다.
1. AIFFEL 데이터톤 개요
💡 DATAthon
지금까지 교육 과정 중 학습한 내용을 토대로,
주어진 데이터셋을 활용하여 End-to-End 팀 프로젝트를 수행한다.
-
프로젝트 기간: 2025.05.31 - 2025.06.04 (총 4일)
-
팀명: Smokalyzer
-
팀 구성: 총 4인
-
분석 주제: 생체 신호 기반 흡연 여부 이진 분류 모델 구축
-
GitHub: datathon-smokalyzer
데이터톤 세부 일정
1. Day 01 | 05.30(금) ➡️ 팀 빌딩 및 DATAthon 진행
2. Day 02 | 06.02(월) ➡️ DATAthon 진행
3. Day 03 | 06.03(화) ➡️ DATAthon 진행
4. Day 04 | 06.04(수) ➡️ 제출/발표 및 회고이번 데이터톤에서는 이커머스와 플랫폼 비즈니스, 의료 및 헬스케어, 금융 및 보안 등 다양한 도메인과 문제별로 총 13개의 데이터셋 후보가 제공되었다.
우리 팀은 의료 도메인의 데이터를 분석해 보고자 하는 팀원들로 구성되었기 때문에 의료 및 헬스케어 도메인 데이터셋 네 가지를 후보로 하여 뜯어 보았다. 이와 관련해서는 아래의 데이터 선정 배경에서 자세히 정리해 보았다.
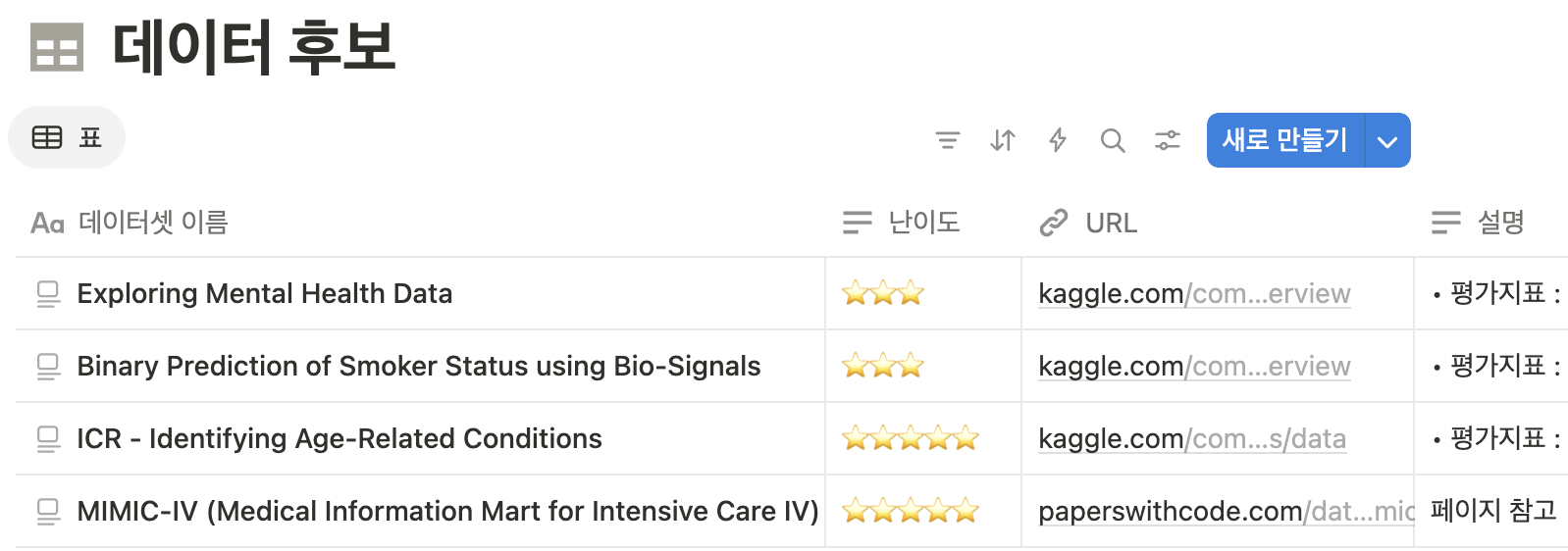
데이터를 확인하고 우리 팀이 처음 세운 목표는 도메인 지식에 기반한 해석 가능한 모델을 만들어, 흡연 여부 이진 분류 문제의 분류 정확도를 높이는 것이었다.
데이터톤이 마무리된 시점에서 되돌아보면 논리적인 근거에 기반한 확실한 프로젝트의 방향과 목표를 세우는 것이 가장 중요한 작업이구나 하는 생각이 든다. 모델 성능 수치 향상을 목표로 하는 것이 아니라, 실제로 발생할 수 있는 문제를 정의하고 이를 해결하기 위한 도구로서 분석을 수행해야 한다는 가장 중요한 부분을 잡고 가지 못했다. 실제로 프로젝트 마무리 단계에서 우리 팀만의 유의미한 방향을 설정할 수 있었는데, 이 부분에서 아쉬움이 남는다.
사담으로, 참신한 팀명 후보들이 여럿 나왔었다.
그중 Smokalyzer (흡연 + Analyzer의 합성어) 는 우리 팀이 "분석할 데이터"와 "분석가로서의 정체성"을 모두 담아내고 있다는 점에서 인상적이었다. 하지만 발음이 어려웠는지 퍼실님께 스모커어쩌구 놀림(?을 받았다는 ..
2. 팀 빌딩과 협업
데이터셋에 대한 이야기를 나눠본 후, 프로젝트에서 필요한 역할 체크리스트를 작성해 보았다. 시간은 한정적이고, 프로젝트의 시작부터 마무리까지 팀원들끼리 함께 완성해 내야 하기 때문에 체계적인 역할 분담이 필요했다.
우리 팀은 총 4명의 팀원으로 구성되었다.
팀원들 모두 각자 뚜렷한 강점을 드러내는 역량을 지니고 있었고, 이에 따라 다음과 같이 역할을 분배해 보았다.
A.
GitHub 관리+피처 엔지니어링+모델링+모델 튜닝(본인)
B.발표+피처 엔지니어링+모델링
C.EDA+데이터 전처리+발표 자료 정리
D.EDA+시각화+피처 엔지니어링+발표 자료 제작
물론 모두가 자신이 맡은 역할 이외에도 필요한 상황이 생기면 나서서 적극적으로 협력하여, 부족한 부분을 함께 보완해 나가면서 프로젝트를 진행하였다.
수치적인 성과를 내는 것도 중요하겠지만, 결국 팀 프로젝트는 소통과 협업 과정에서 얻어갈 부분이 있다는 것이 큰 메리트일 것이다. 실제로 팀원분들의 커뮤니케이션 스킬에서 많은 점을 배울 수 있었다.
협업 방식
우리 팀은 프로젝트 진행 과정 동안 아래의 협업 툴을 사용하였다.
사실 나는 개인 프로젝트도 마찬가지지만 특히 팀 프로젝트에서는 상세한 진행 과정을 기록하고 공유하는 것이 정말 중요하다고 생각한다. 다행히 팀원분들도 모두 같은 의견이셔서(그랬던 거 맞겠죠..?ㅎㅎ) 협업이 원만하게 진행될 수 있었다.
분석 >>
Google Colab,Google Drive
버전 관리 >>GitHub Organization
진행 과정 기록 >>Notion
발표 자료 제작 >>Canva
코드 공동 작성 및 커밋 관리, 회의록 작성, task 종류별 작업 이력을 꼼꼼하게 기록하며 진행하였다. 실제로 발표 후 피드백으로, 협업 과정에 대해서도 칭찬을 받을 수 있었다.
개인적으로 아쉬운 점이 있다면, 구현 과정에서 트러블 슈팅까지 정리해 두고 싶었는데 시간 관계 상 간단하게 기록만 하고 넘어가게 되었다.
3. 데이터 선정 배경
최종적으로 선정한 데이터는 Kaggle에 공개된 Body Signal of Smoking 데이터셋이다. 이 데이터는 실제 생체 신호 데이터를 기반으로 딥러닝 모델이 학습하여 생성한 합성 데이터 (Synthetic Data)다.
네 개의 데이터셋 후보에서 각각 해결해야 하는 문제와 피처 정보, 요구하는 도메인 지식 등을 따져보았는데, 아래와 같은 이유로 최종 선정하게 되었다.
데이터 선정 이유
-
현실적인 주제
- 흡연 여부는 건강검진, 보험심사, 질병 예측 등 다양한 실생활 분야에 적용 가능하다.
- 생체 신호만으로 추론할 수 있다면 실제 응용 가치가 높다고 판단되었다.
-
적절한 난이도와 구조
- 샘플 수: 약 15만 건 이상 (Train: 159,256 / Test: 106,171)
- 변수 수: 23개 생체 신호 관련 지표 + 타겟(smoking)
-
모델링 및 해석 가능성의 균형
- 다양한 지표가 포함되어 있어 머신러닝 실습뿐만 아니라 도메인 해석과의 연결을 시도할 수 있다고 판단하였다.
-
이진 분류 구조로 명확한 목표와 평가지표 제공
- 타겟 변수: smoking (0 = 비흡연자, 1 = 흡연자)
- 예측 값: 확률 (0 ~ 1)
- 평가 지표: ROC-AUC
단, 합성 데이터이므로 변수 간 관계가 실제 생리학과 다를 수 있다는 한계 또한 인지하고 시작하였다. 이 문제는 [Datathon] 시리즈 마지막에서 다룰 예정이다.
4. 데이터 구성 및 변수 설명
팀원 중 한 분이 우리가 선정한 데이터셋과 관련 도메인 지식을 충분히 가지고 계셨다. 덕분에 나를 비롯한 나머지 팀원분들도 조금 더 빠르고 정확하게 데이터와 그 피처가 지니는 의미를 이해할 수 있었다.
추가적으로 필요한 지표의 정상 범위는 서울아산병원 건강증진센터의 공식 문서 및 서울아산병원 건강검진 센터 페이지 내용을 참고하여 정리하였다.
원본 피처 해석
원본 피처들을 해석하고 이해하여 아래와 같이 정리할 수 있었다.
이 값들은 이후 이상치 처리와 피처 엔지니어링의 기준으로 사용되었다.
| 영문 항목 (English) | 한글 이름 (Korean) | 정상 수치 (Normal Range) |
|---|---|---|
| height(cm) | 키 | 참고용 (개인차 있음) |
| weight(kg) | 몸무게 | BMI 18.5-24.9 |
| waist(cm) | 허리둘레 | 남: <90cm, 여: <85cm |
| eyesight(left) | 시력(좌) | 1.0 이상 |
| eyesight(right) | 시력(우) | 1.0 이상 |
| hearing(left) | 청력(좌) | 25dB 이하 |
| hearing(right) | 청력(우) | 25dB 이하 |
| systolic | 수축기 혈압 | 90-120 mmHg |
| relaxation | 이완기 혈압 | 60-80 mmHg |
| fasting blood sugar | 공복 혈당 | 70-99 mg/dL |
| cholesterol | 총 콜레스테롤 | < 200 mg/dL |
| triglyceride | 중성지방 | < 150 mg/dL |
| HDL | 고밀도 지질(좋은 콜레스테롤) | 남: >40, 여: >50 mg/dL |
| LDL | 저밀도 지질(나쁜 콜레스테롤) | < 100 mg/dL |
| hemoglobin | 헤모글로빈 | 남: 13-17, 여: 12-16 g/dL |
| urine protein | 소변 단백질 | 음성 (Negative) |
| serum creatinine | 혈청 크레아티닌 | 남: 0.7-1.3, 여: 0.6-1.1 mg/dL |
| AST | AST(간 효소) | 0-40 U/L |
| ALT | ALT(간 효소) | 0-40 U/L |
| GTP | 감마-GTP | 남: <70, 여: <40 U/L |
| dental caries | 충치 | 없음 (정상) |
외부 데이터셋 활용 배경과 전략
데이터셋을 선택하고 분석하면서 중요하게 고려했던 부분이다.
원본 데이터에는 성별(gender) 정보가 존재하지 않았는데, 흡연 여부는 성별에 따라 통계적으로 유의미한 차이가 존재하기 때문이다.
따라서 우리는 성별 정보를 모델에 반영하기 위해 외부 데이터셋을 도입하기로 결정하였다.
외부 데이터셋 개요
🔗 사용한 외부 데이터셋: Body signal of smoking
| 구분 | 주 데이터셋 | 외부 데이터셋 |
|---|---|---|
| 출처 | Kaggle (Smoker Status Prediction) | Kaggle 생체 신호 분류 데이터 |
| 샘플 수 | 159,256건 | 55,692건 |
| 공통 피처 | 23개 생체 지표 (나이, 키, 혈압 등) | 이하 동일 |
| 차이점 | gender 없음 | gender, oral, tartar 등 포함 |
성별 피처 생성 과정
외부 데이터셋에서 가져온 성별 정보를 기존 데이터셋에서 어떻게 사용할 수 있을지 고민해 보았고, 다음의 방법으로 gender 피처를 생성하였다.
-
외부 데이터셋을 기반으로 성별을 예측하는 분류 모델 학습
-
주 데이터셋(train/test)에 적용하여, '남성일 확률'을 새로운 피처로 생성
-
단순히 남/녀로 분류하지 않고 0~1 사이의 확률값으로 표현하여
→ 불확실성, 경계값, 모델의 민감도를 보다 정교하게 반영
기대 효과
성별은 흡연과의 연관성이 높은 변수이므로 모델 성능 향상에 직접 기여할 수 있을 거라 예상하였다.
또한, 외부 데이터를 활용하여 기존 데이터의 도메인 정보 한계를 보완해 보는 유익한 경험이 될 것이라 판단하였다.
성별 정보를 추가한 결과, 모델 해석력과 성능 지표 향상에 실질적으로 기여하였는지 그 여부는 이어지는 글에서 정리해 볼 예정이다.
>> Next
생체 신호 데이터의 특징은 숫자를 해석하는 것으로 끝낼 수 없다는 것을 이해하였다. 이 지표들이 사람의 몸에서 어떻게 상호작용하고, 흡연이라는 행위와 어떤 관계를 갖는지 도메인 관점에서 깊이 있게 해석할 필요가 있었다.
이어서 데이터에 대한 깊이 있는 이해를 기반으로 프로젝트의 방향과 분석 목표를 정립하는 시간을 가졌다.
🔗 다음 글
[DATAthon] 분석 목적 및 전략 #2 (작성 중)
