데이터 성장기
1.[리눅스] 데이터와 리눅스?
데이터 분석과 데이터 사이언스를 목표로 공부하는 입장에서, 리눅스와 운영체제에 대한 이해도가 충분해야 한다는 것은 안다. 그렇다면 어떨 때 왜 필요한 것일까?
2.[GitHub] 깃 생태계에 입문하신 걸 환영합니다

이 글을 보고 있는 우리들에게 Git과 GitHub은 가까이할 수밖에 없는 사이일 것이다. 버전 관리를 깔끔하게 하기 위해, 여러 명이 함께 작업할 때는 협업 도구로서 필수적으로 사용된다. 따라서 이곳 Git 생태계에서 헤매지 않기 위해
3.[3월 넷째 주] 주간 회고

✓온보딩과 개강 ✓학습 정리 툴을 옵시디언으로 갈아탔다 ✓작고 소중한 이력을 정리했다 ✓나의 의지로 등산을 다녀왔다 ✓감사 일기를 쓰기 시작했다
4.[Python] 파이썬의 예약어에는 어떤 것들이 있을까?
예약어(키워드)란? 파이썬에서 특정 기능을 수행하도록 미리 예약되어 있는, 특별한 의미를 가지는 단어를 말한다. 쉽게 예를 들면, 파이썬을 시작하자마자 만날 수 있는 print, 등을 예약어라고 한다. 예약어를 제대로 알고 있어야하는 이유는
5.[Python] iterable vs. iterator
파이썬을 공부하다 보면 iterable(이터러블)과 iterator(이터레이터) 라는 단어를 자주 접하게 될 것이다. 둘의 차이를 이해하고 넘어가는 것이 중요한데
6.[Python] 람다 표현식
처음 람다 표현식을 마주했을 때, lambda라는 낯선 키워드와 익숙하지 않은 문법에 당황했던 기억이 있다. 함수처럼 동작하는데 함수 이름이나 def도 없고, 한 줄로 끝나는 코드가 과연 무슨 일을 하는지 파악하기 어려웠다. 하지만 람다 표현식은 자주 등장한다.
7.[Python] 객체, 그리고 일급 객체
프로그래밍을 배우다 보면 일급 객체라는 개념을 접하게 된다. 이 글에서는 일급 객체를 제대로 이해하기 위해 먼저 객체와 객체 지향 프로그래밍(OOP)을 살펴보고, 파이썬 함수가 왜 일급 객체인지까지 예제를 통해 정리해 보았다.
8.[Python] 예외 처리는 중요하다
예외 처리는 중요하다. 현실의 데이터는 언제나 깨끗하고 완벽하지 않다. 꼭 파이썬에서만이 아니더라도 시스템이 의도치 않게 동작하는 상황에 대처하기 위해서 예외 처리는 핵심적으로 사용된다. 실제로 경험했던 상황을 이야기 해보자면,
9.[SQL] 데이터베이스와 테이블
데이터는 단순한 숫자나 문자들의 나열일 수 있지만 우리가 그것을 해석하고 의미를 부여하는 순간 데이터는 의미있는 정보로 발전한다. 데이터를 통해 현명한 의사결정과 가치 창출을 해내고 싶다는 목표를 가지고
10.[SQL] 데이터 분석의 시작: SQL로 데이터 다루기
데이터는 저장만으로는 의미가 없다. 진짜 중요한 것은 어떤 데이터를 어떻게 불러오고, 어떻게 추려낼 것인가 이다. SQL은 데이터를 분석하는 가장 기본적이고 강력한 도구이다.
11.[SQL] 다양한 데이터 활용법
SQL은 단순히 데이터를 조회하는 언어가 아니다. 어떤 데이터를 보여줄 것인가, 어떤 방식으로 분류하고 필터링할 것인가, 어떻게 더 읽기 쉽게 가공할 것인가에 따라 쿼리의 힘은 훨씬 더 커질 수 있다.
12.[SQL] 집계 함수: COUNT, SUM, AVG, MAX, MIN
SQL로 데이터를 요약하고 분석할 때 가장 먼저 접하게 되는 것이 바로 집계 함수(Aggregate Function)이다. "총 몇 건인가요?", "평균은 얼마죠?", "최댓값은?" 과 같은 질문에 직접적으로 답할 수 있게 해준다.
13.[SQL] 데이터 그룹화하기: GROUP BY
데이터 분석에서 전체 값을 요약해서 보는 일은 매우 중요하다. "어떤 계절에 이용량이 많았는지", "어떤 시간대에 고객이 몰리는지", "날씨가 어떨 때 더 많이 이용하는지"와 같은 질문에 답하려면, 데이터를 그룹화하고 요약하는 능력이 필요하다. 흥미롭지 않은가? 😊
14.[SQL] 그룹화한 데이터에 조건주기: HAVING
" 그룹화된 데이터에도 조건을 걸 수 있다! "
15.[SQL] 기본키(PK)와 외래키(FK)
데이터셋을 다루다 보면 단일 테이블로 사용하는 경우도 있지만, 대부분의 케이스가 여러 개의 테이블을 붙여서 활용하는 경우일 것이다. 따라서 테이블 간 연결의 핵심인 기본키(Primary Key, PK) 와 외래키(Foreign Key, FK) 를 짚고 넘어가야 한다.
16.[SQL] 다중 테이블 사용하기: JOIN
실제 데이터베이스 환경에서는 정보가 여러 테이블에 분산되어 저장되기 때문에, 이들 테이블을 연결하여 의미 있는 정보를 추출하는 과정이 필수적이다. 이때 사용되는 것이 바로 JOIN 이다. JOIN 은 SQL의 핵심이자 관계형 데이터베이스의 가장 큰 장점 중 하나이다.
17.[SQL] 데이터 이어붙이기: UNION
SQL에서 테이블을 세로 방향으로 연결하고 싶을 때는 UNION 을 사용해야 한다. 이 글에서는 UNION 과 UNION ALL 의 기본 개념부터 사용 시 주의사항, 그리고 중복 제거 기준을 예제를 통해 정확히 이해할 수 있도록 정리해 보았다.
18.[SQL] 서브쿼리 원리와 방식
SQL 쿼리를 작성하다 보면, 단일 쿼리로는 원하는 결과를 얻기 어려운 상황이 자주 발생한다. 이럴 때 유용하게 쓰이는 것이 바로 서브쿼리(Subquery) 즉, 쿼리 안의 또 다른 쿼리이다.
19.[SQL] GROUP BY에 여러 개의 컬럼을 지정한다면? w.집계 함수
프로그래머스에서 문제를 풀다가 GROUP BY 와 관련해 정리하고 넘어가면 좋을 부분을 발견해서 공유하려고 한다. 해당 문제를 통해서 다음의 궁금증을 해결할 수 있었다.
20.[4월 첫째 주] 주간 회고
✓벨로그 활성화 ✓SQL과 가까워지기 ✓바른 자세 🫠 ✓취침 시간이 점점 늦어진다
21.구글 BigQuery 시작하기 w.기존 계정 결제 수단과 [OR-KCCSEH-11]
이 글에서는 구글 BigQuery를 무료로 사용하기 위한 환경 설정부터 빅쿼리에서 테이블을 정의하는 규칙과 유용한 기능까지 정리해 보았다. 또 기존 계정에서 무료 체험기간이 종료된 경우 새 계정으로 결제 수단을 등록할 때 생길 수 있는 문제와 해결 방법도 남겨두었으니
22.[SQL] PV, UV
하루에도 수천만 명이 방문하는 쿠팡, 네이버, 인스타그램 같은 웹/앱 서비스에서 가장 중요한 지표는 무엇일까? ‘얼마나 많은 사람이 들어왔고’, ‘무엇을 얼마나 많이 봤는가?’ 일 것이라 생각한다.
23.[SQL] ARPU, ARPPU
"우리 앱은 이번 달에 다운로드 수가 10만을 넘었어!" 겉보기에 대단한 숫자일 수 있지만, 실제로 이 중 수익을 올리는 사용자 수는 얼마나 될까? 단순 방문자 수보다 훨씬 중요한 지표가 바로 ARPU와 ARPPU이다.
24.[SQL] 퍼널 분석: 사용자의 이탈 지점 파악하기
퍼널 분석은 사용자 이탈 지점을 꿰뚫고, 제품 또는 서비스의 전환 흐름을 정밀하게 진단할 수 있는 데이터 기반 프레임워크이다.
25.[SQL] 리텐션 분석: 사용자의 재방문율 측정하기
사용자를 모으는 건 어렵지 않다. 광고를 때리고, 프로모션을 걸면 금방 수치가 올라가니까 :) 하지만 진짜 중요한 건 얼마나 많은 사용자가 다시 우리 서비스로 돌아오는가이다. 바로 이 지점을 데이터로 보여주는 것이 리텐션(Retention) 분석이다.
26.[SQL] RFM 분석: 고객 가치를 숫자로 보는 법
우리 서비스의 고객 중 누구에게 집중해야 할까? 신규 유저? 충성 고객? 아니면 이탈 직전의 위험 고객? 그 답을 숫자로 정확히 보여주는 분석 기법이 RFM 분석이다.
27.데이터 전처리는 데이터 분석을 결정한다
모든 데이터 분석의 시작은 전처리이다. 아무리 뛰어난 분석 알고리즘도, 지저분한(raw) 데이터를 제대로 다듬지 않으면 원하는 성과를 내기 어렵다. 이후에 진행할 이커머스 데이터 분석 프로젝트를 시작하기 전에, 다양한 전처리 방법들을 알아보자.
28.[고객 세그먼테이션] 데이터 전처리하기
'고객 세그먼테이션' 프로젝트는 Kaggle에 공개된 E-Commerce Data를 바탕으로 고객의 구매 데이터에 기반해 RFM 분석 및 피처 엔지니어링을 수행한다. 이를 통해 고객을 정량적으로 세분화한 뒤 클러스터링 및 시각화를 거쳐 인사이트 도출을 목표로 한다.
29.[고객 세그먼테이션] RFM 지표로 고객별 구매 패턴 분석하기
이제 전처리한 데이터를 가지고 고객별 구매 패턴을 파악하여 고객을 세그먼테이션해야 한다. 다양한 고객 세그먼테이션 방법 중 왜 RFM 지표일까?
30.[고객 세그먼테이션] 추가 feature 추출하기
앞서 고객을 “얼마나 자주, 얼마나 최근에, 얼마나 많이 구매했는가”라는 기준으로 세그먼테이션했다. 하지만 이것만으로 고객의 쇼핑 성향을 완벽히 이해하긴 어렵다. 고객의 구매 습관과 성향을 더욱 깊이 있게 파악할 수 있는 추가 feature들을 추출해 보려고 한다.
31.[고객 세그먼테이션] Z-Score로 이상치 분석 및 처리
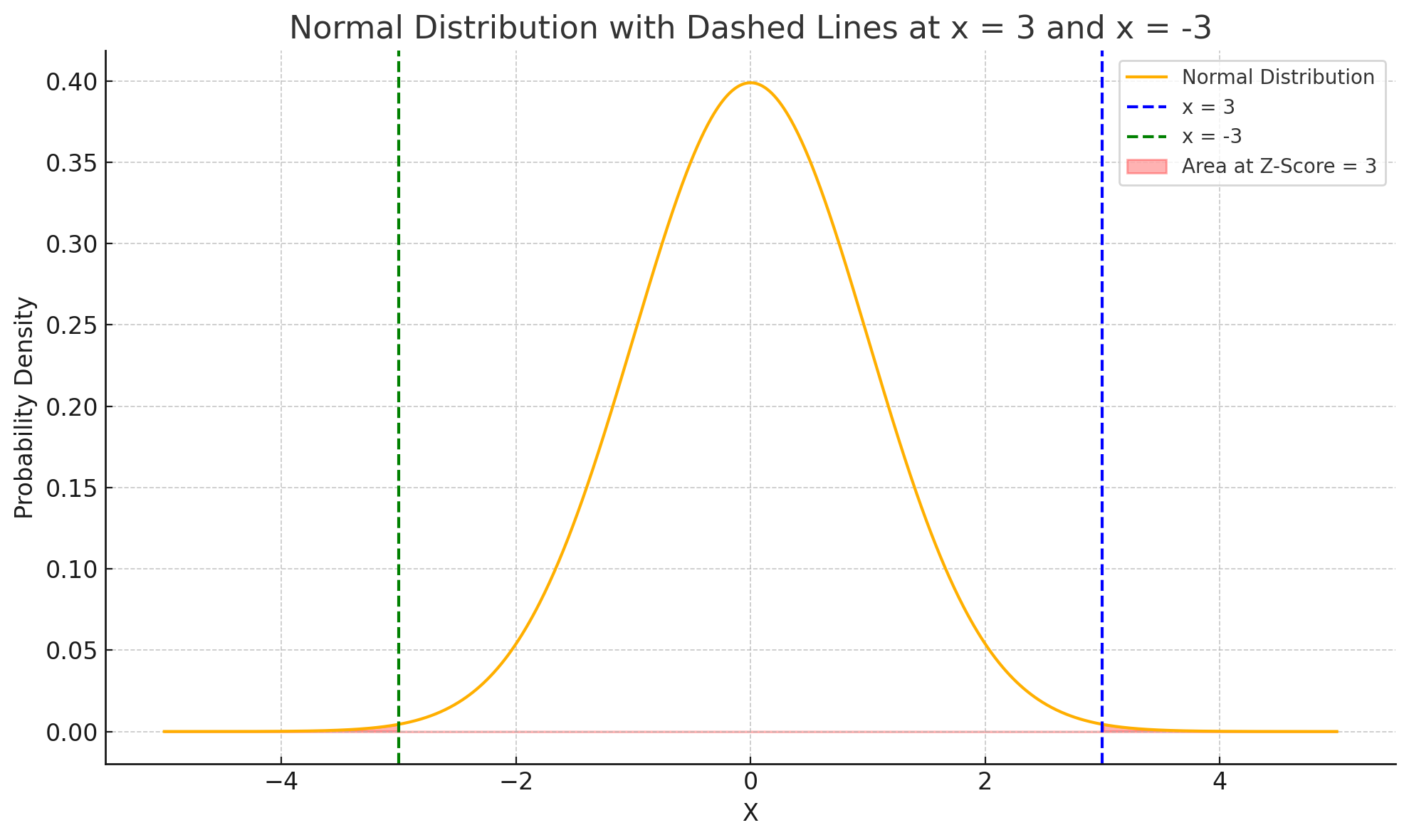
SQL로 전처리해 준 데이터를 바탕으로 클러스터링을 진행하기에 앞서, 이상치(Outlier) 제거는 필수적인 전처리 과정이다.
32.[고객 세그먼테이션] 다중공선성 문제와 상관관계 분석
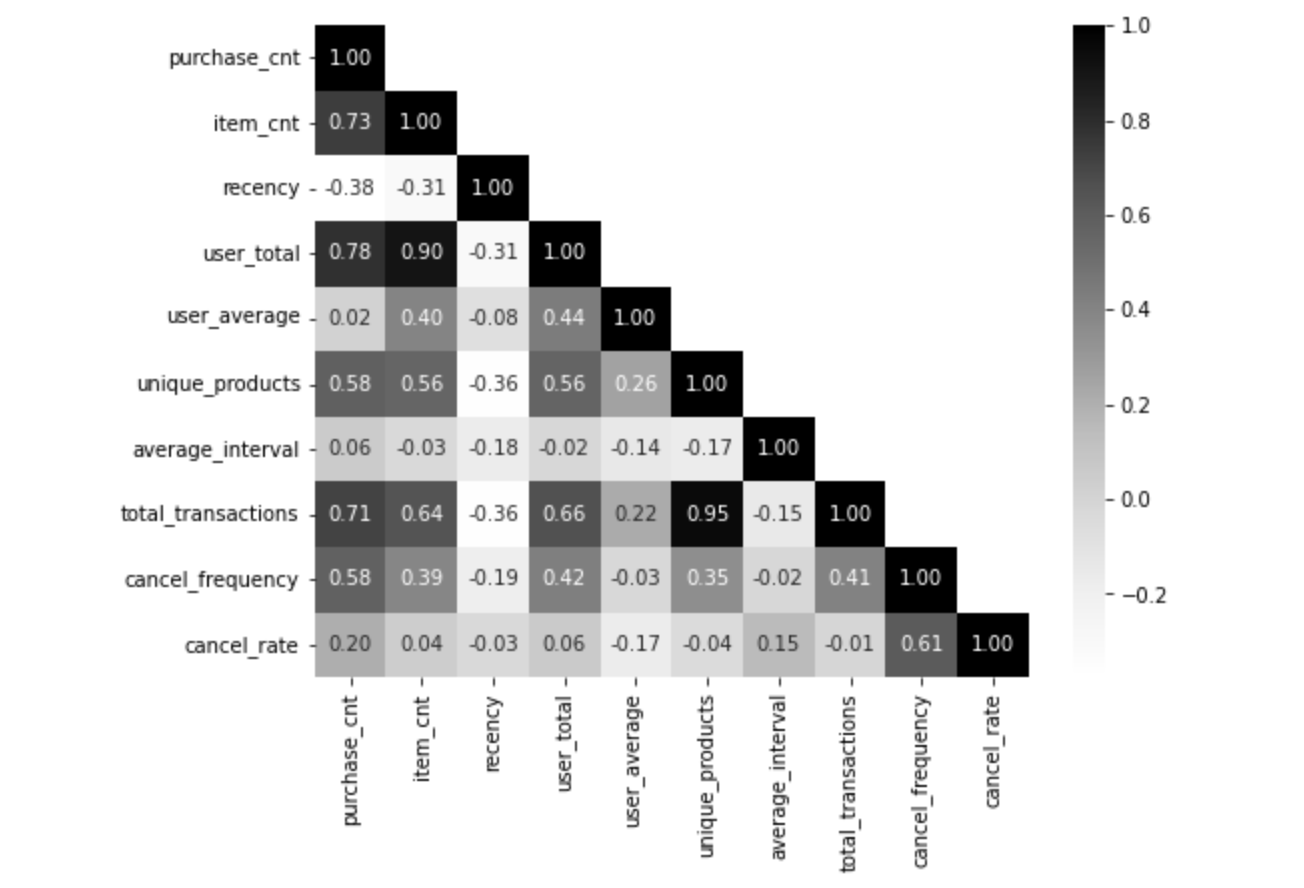
고객 세그먼테이션을 위해 K-Means 클러스터링을 적용하기 전에, 데이터셋 내 특성(feature) 간의 상관관계 분석하는 것이 필요하다. 상관관계가 무엇을 의미하는지, 클러스터링에서 왜 중요한지를 알아보고 다중공선성 문제도 함께 생각해 보았다.
33.[고객 세그먼테이션] Feature Scaling
K-Means 클러스터링이나 PCA와 같은 머신러닝 알고리즘을 적용하기 전에 꼭 거쳐야 할 중요한 과정이 있는데, 바로 Feature Scaling(피처 스케일링)이다.
34.[고객 세그먼테이션] PCA 기반 차원 축소
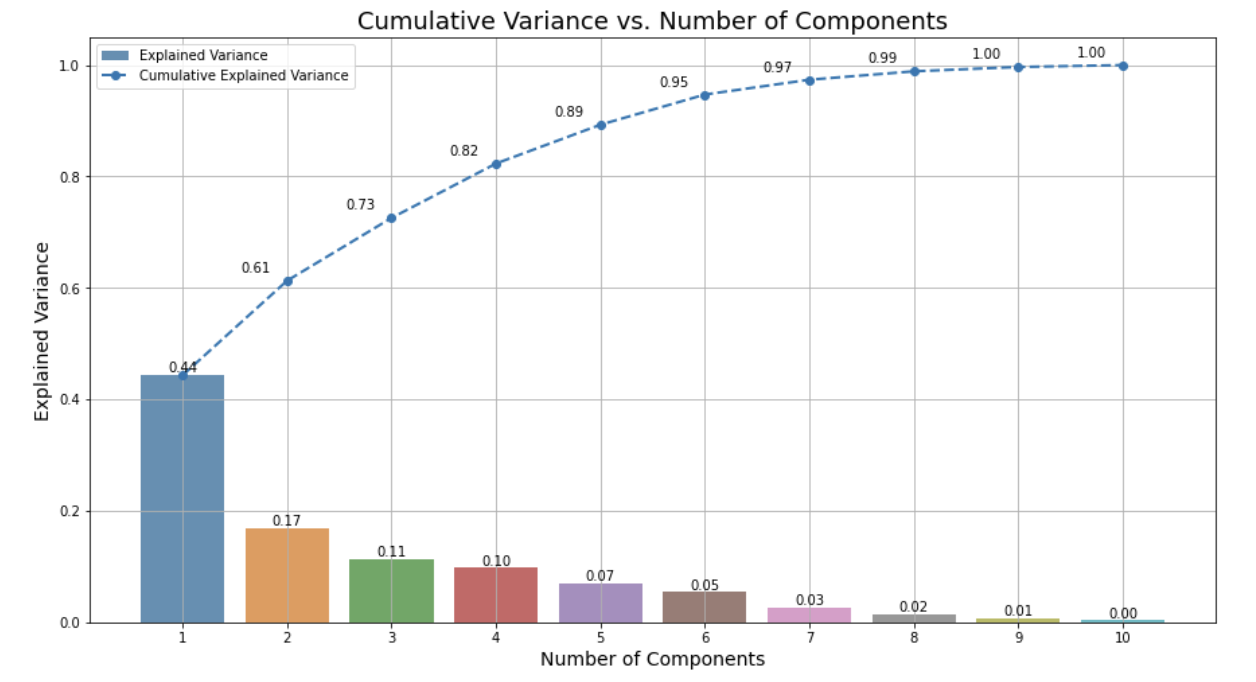
해당 프로젝트에서는 다양한 차원 축소 방법 중 주성분 분석(PCA)를 통해 차원 축소를 진행할 것이다. 먼저 왜 차원 축소가 필요한지, PCA를 선택한 이유는 무엇인지부터 정리해 보았다.
35.[고객 세그먼테이션] K-Means 클러스터링
지금까지 고객 거래 데이터를 보다 정확하게 분석하기 위해 이상치 제거 → 상관관계 분석 → 피처 스케일링 → 차원 축소(PCA)의 과정을 거쳐왔다. 이제 본격적으로 K-Means 클러스터링을 적용해 고객을 그룹으로 나누어 보자.
36.[고객 세그먼테이션] 시각화 및 결과 분석
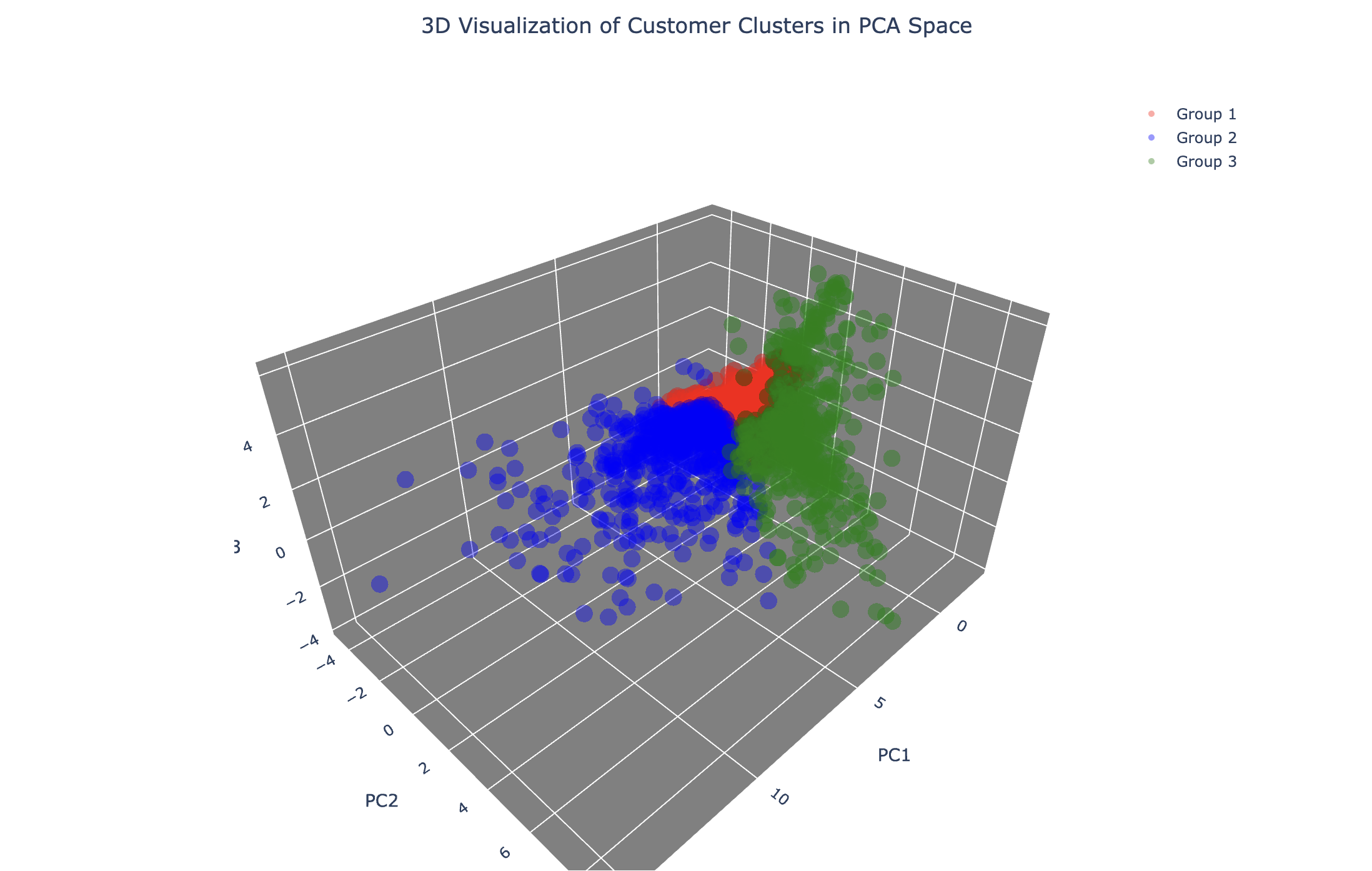
드디어 K-Means 클러스터링까지 완료하였다. 이제 클러스터링 결과가 의미 있는 고객 그룹을 잘 분리하고 있는지를 시각화를 통해 확인해야 한다. 그전에 분석에서 시각화가 왜 중요한지부터 짚어보고 넘어가자.
37.[고객 세그먼테이션] RFM과 K-Means 클러스터링 비교 분석
지금까지 이커머스 데이터를 기반으로 고객의 구매 행동을 다각도로 분석해 보았다. 한 프로젝트 내에서 RFM 지표와 머신러닝 기반의 클러스터링 방식(K-Means)을 모두 적용한 이유는 단일 분석 방법만으로는 고객의 행동을 충분히 설명하기 어렵기 때문이다.
38.[고객 세그먼테이션] 프로젝트 마무리
본 프로젝트는 Kaggle에 공개된 E-Commerce 데이터를 바탕으로 고객의 구매 행동 데이터에 기반해 RFM 분석 및 피처 엔지니어링을 수행하고, 이를 통해 고객을 정량적으로 세분화한 뒤 클러스터링 및 시각화를 거쳐 인사이트를 도출하는 것을 목표로 진행하였다.
39.[Kaggle] 캐글 필사 시작하기 - 구글 코랩 사용 팁과 템플릿 공유📄
구글 코랩(Google Colab) 환경에서 캐글 필사를 진행하기 위한 환경 설정을 정리해 보았다. 세션이 끊기거나, 다음 날 다시 Colab에서 작업할 때 효율적으로 이어서 필사할 수 있도록 세팅을 자동화한 템플릿도 제작하여 남겨두었다.
40.[비정제 데이터] Data Cleaning w.titanic
모두의연구소 교육 과정에서 진행한 Data Cleaning 실습 내용을 바탕으로, 결측치, 이상치, 중복값, 텍스트 데이터 등 다양한 전처리 과정을 정리한 기록이다. 자세한 학습 진행 과정은 GitHub repository에 남겨두었다.
41.[비정제 데이터] mean vs. median, 결측치 처리할 때 무엇을 선택할까?
결측치가 포함된 데이터를 다루다 보면, 다음과 같은 질문이 생길 때가 있다. "이 NaN 값을 mean으로 채울까, median으로 채울까?" 데이터를 정확하게 분석하고 모델링하려면 단순히 결측치를 채우는 것이 아니라, 무엇으로 채울지에 대한 판단이 중요하다.
42.[비정제 데이터] 자주 쓰는 Pandas 메서드 10개: 예제로 알아보기
Pandas는 데이터 분석에 있어 가장 기본이자 필수적인 라이브러리다. 하지만 기능이 워낙 방대하다 보니, 처음 시작할 때는 "도대체 어떤 메서드부터 익혀야 할까?" 라는 고민이 들 수밖에 없다.
43.[비정제 데이터] matplotlib vs. seaborn 시각화 비교
데이터 분석을 하다 보면, 수치보다 더 직관적인 것이 바로 시각화이다. 숫자만으로는 보이지 않던 패턴이, 시각화를 통해 명확하게 드러나는 순간을 경험해 보았을 것이다 :)
44.[비정제 데이터] 헷갈리기 쉬운 함수: replace, map, apply
Pandas를 쓰다 보면 값을 바꾸거나 새로운 열을 만들기 위해 사용하는 함수들이 있는데, 그중에서도 유난히 헷갈리는 세 가지가 있다. "replace, map, apply" 기능도 비슷해 보이고 문법도 닮았지만 이 셋은 적용 대상과 사용 목적이 아주 뚜렷하게 다르다.
45.[비정제 데이터] 접근자 .str과 .dt
데이터 분석을 하다 보면 문자열과 날짜/시간 데이터를 다루는 일이 정말 자주 생긴다. 이름에서 성을 따오거나, 날짜에서 연도만 뽑거나, 특정 요일에 일어난 이벤트를 분석하거나. 이때 Pandas에서는 두 가지 접근자를 사용한다.
46.[비정제 데이터] Data Cleaning w.trip
본 프로젝트는 택시 이용 내역 데이터를 기반으로, 다양한 변수들을 활용하여 “택시 요금”을 예측한다는 가정하에 데이터를 정제하는 것을 목표로 진행하였다.
47..gitignore 오타 하나로 체크포인트 파일이 올라간 사연
".gitignore을 분명히 설정했는데 왜 무시되지 않는 거지?"
48.[비정제 데이터] Data Transformation w.salary
모두의 연구소 교육 과정에서 학습한 Data Transformation 실습 내용을 바탕으로, 다양한 독립 변수를 활용해 연봉을 예측할 수 있는 모델을 만들기 위한 데이터를 정제하는 과정을 정리한 기록이다.
49.[비정제 데이터] 로그 변환으로 데이터 스케일 조절하기
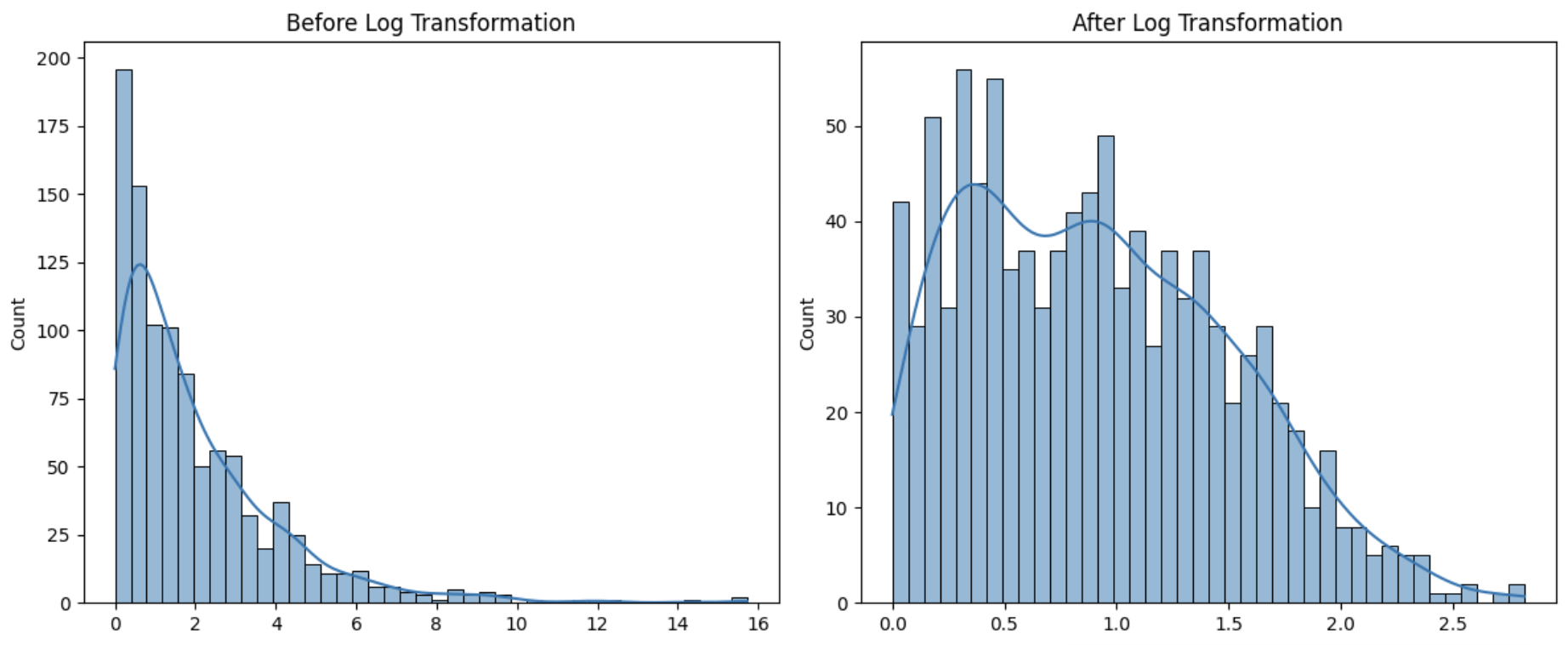
실제 데이터는 대체로 정규분포가 아니고, 한쪽으로 치우쳐 있거나 이상치에 민감한 구조를 가지고 있다. 이때 우리가 취할 수 있는 전처리 기법 중 하나가 로그 변환(Log Transformation)이다.
50.[비정제 데이터] Scaling으로 데이터 범위 조정하기
단위가 서로 다른 여러 변수들이 혼합된 데이터에서, 스케일링은 각 변수의 영향력을 균형 있게 조정해주는 역할을 한다. 특히 거리 기반 알고리즘이나 경사 하강법을 사용하는 선형 모델에서는 스케일링이 성능에 직접적인 영향을 주기도 한다.
51.[비정제 데이터] 다중공선성, 종속변수와의 상관관계가 높다면?
중고차 가격 예측 모델을 위한 데이터 정제 프로젝트에서 정리하면 좋을 인사이트를 발견해 가져와 보았다. 다중공선성은 독립변수들끼리 상관관계가 높을 때 문제가 되는 것이지, 종속변수와 독립변수 간의 상관관계가 높은 건 오히려 모델 입장에선 반가운 일이라는 것이다.
52.[비정제 데이터] Data Transformation w.car
본 프로젝트는 영국 중고차 시장 데이터를 기반으로 데이터 손실은 줄이고 정보량은 최대한 보존한다는 방향을 세우고, "중고차 가격 예측 모델링" 및 "특성 기반 클러스터링"에 사용될 수 있는 데이터로 정제하는 것을 목표로 진행하였다.
53.깃허브 브랜치가 사라졌다: 원인과 해결
일단 어그로까지는 아니지만 약간의 정정을 하자면, 예상했겠지만 브랜치가 진짜 아무 이유없이 갑자기 뿅 사라진 것은 아니었다. 그치만 내가 겪었던 브랜치 자동 삭제 이슈 상황을 그대로 마주한 사람들에게 도움이 될 수 있을 것 같아 이렇게 남겨본다.
54.[비정제 데이터] Feature Engineering w.dating
본 프로젝트는 speed dating 데이터셋을 기반으로 전처리 및 피처 엔지니어링을 통해 단순 수집된 정보를 넘어서 변수 간의 관계와 의미를 확장한 새로운 피처를 설계하고, 이를 함수화하여 재활용 가능한 코드로 패키징하는 것을 목표로 한다.
55.[비정제 데이터] 모듈화와 패키징으로 전처리 자동화하기
Speed Dating 데이터셋을 기반으로 Feature Engineering을 수행하면서, 반복적인 전처리 과정을 모듈화하고 패키징하여 효율적이고 재사용 가능한 전처리 흐름을 구축할 수 있다는 인사이트를 얻을 수 있었다.
56.신용카드 이상거래 탐지 모델을 위한 Feature Engineering 프로젝트
본 프로젝트는 신용카드 거래 이력 데이터를 기반으로 사기 거래 여부를 예측하는 이상탐지 모델을 위한 Feature Engineering을 수행하며, 개인의 행동 패턴을 반영한 파생 피처를 구성해 모델 학습에 적합한 데이터로 정제하는 것을 목표로 진행하였다.
57.[비정제 데이터] 그래서, 사기 거래 건은 어떻게 다른데?
앞선 프로젝트를 진행하면서 "사기 거래 건은 정상 거래의 행동 패턴과 어떻게 다르며, 그 차이를 수치로 설명할 수 있을까? 모델링 시 이 패턴을 신뢰할 수 있을까?" 라는 궁금증이 생겼다.
58.Git 상태는 깨끗한데 왜 GitHub에 반영이 안될까?
프로젝트를 정리한 뒤 GitHub에 올리려고 했을 뿐인데, 아무런 커밋 내역도 없는 텅 빈 저장소를 마주하게 되었다. 처음엔 “버근가?”, “내가 뭔가 빼먹었나?", "아니면 캐시 문제인가?” 싶었다. 하지만 그 원인은 아주 단순하고도 본질적인 것이었다.
59.확률은 지나간 사건의 결과를 보상해 주지 않는다
책 『데이터 분석가의 숫자 유감』 중 '확률과 분포: 그때는 맞고 지금은 틀린가?' 라는 챕터에서 인상적으로 읽은 구절이다.
60.[통계] AARRR: Acquisition
Acquisition(유입) 단계에서는 사용자가 어떤 경로를 통해 처음 서비스를 접하는지를 분석한다. 고객들은 어떤 경로로 우리 서비스에 유입되었는가? 각 유입 채널의 성과는 얼마나 다른가? 효율적인 마케팅 전략 수립을 위해 어디에 집중해야 하는가?
61.[통계] AARRR: Activation
Activation 단계는 단순히 가입 유저 수가 아니라, 제품의 진짜 가치를 경험한 사용자 비율을 측정하는 것이 핵심이다. 서비스 특성에 따라 Activation의 기준은 달라질 수 있지만, 어떤 기준이든 전환 행동과 연결될수록 실질적인 인사이트를 제공하게 된다.
62.[통계] AARRR: Retention
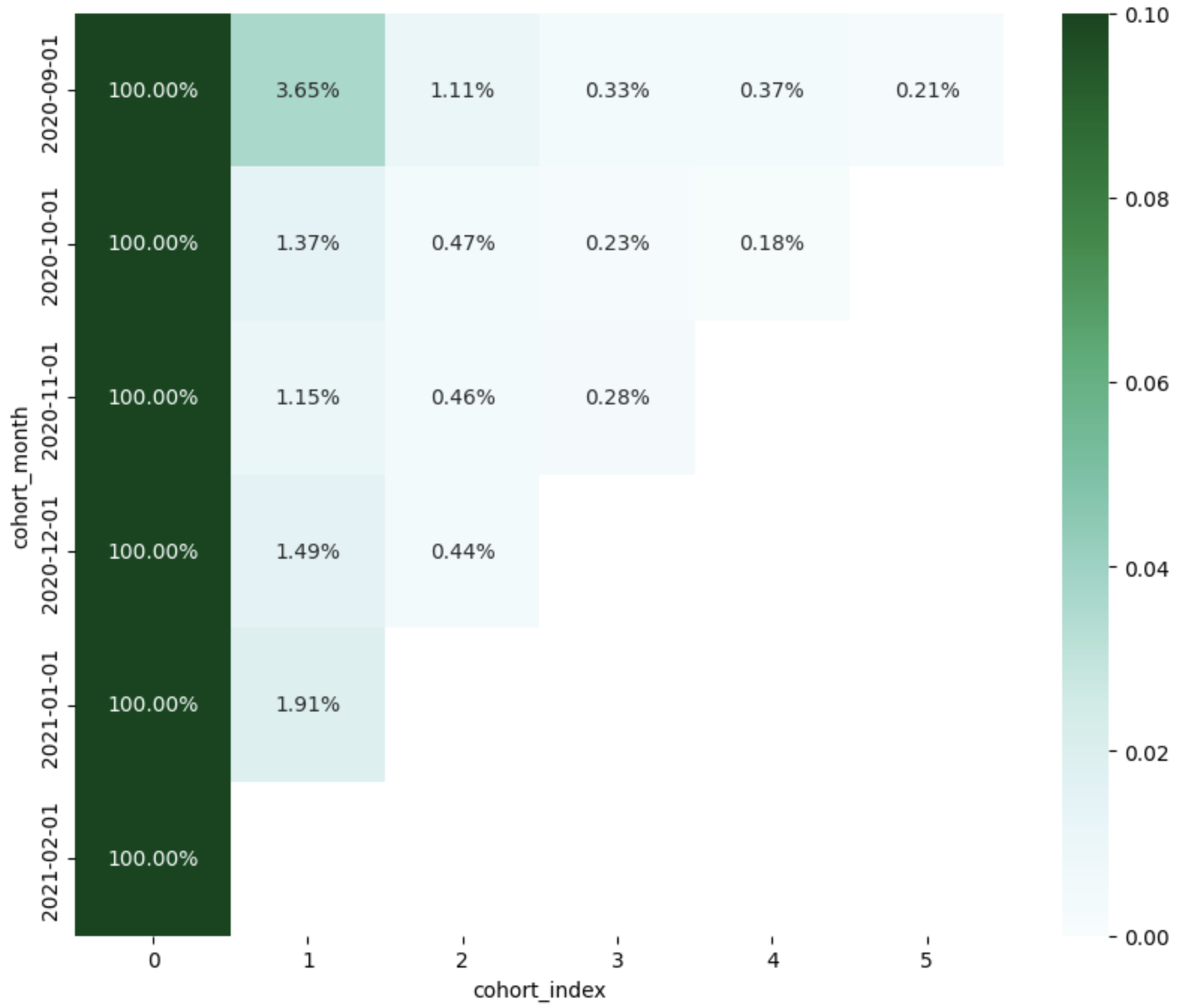
Retention 분석은 성장 지표가 아닌 지속 지표다. 새로운 사용자를 많이 유입시키는 것도 중요하지만, 이들을 얼마나 잘 유지시키느냐가 서비스의 진짜 성장을 의미한다.
63.[통계] AARRR: Referral
사용자가 자발적으로 서비스를 퍼뜨리게 하려면, 만족도와 유도 구조가 모두 정교하게 설계되어야 한다. 지표를 확인한 다음, 실제 유저의 추천 행동을 디자인 관점에서 어떻게 설계할 수 있는지 고민하는 것이 중요하다.
64.[통계] AARRR: Revenue
AARRR 프레임워크의 마지막 단계인 Revenue는 유저가 실제로 프로덕트에 돈을 쓰는 단계이다. 이 단계에서 얼마나 수익을 창출했는지는 당연히 중요한 지표이며, 각 유저가 프로덕트에 지불한 금액이 어느 정도인지도 확인할 필요가 있다.
65.[통계] AARRR 분석 정리 및 회고
AARRR 지표를 이해하기 위해 기본적인 실험을 통해 해석해 보았다. 진짜 중요한 건 이 데이터를 바탕으로 어떤 실험을 설계하고, 어떤 방식으로 개선을 반복할 것인가라는 것이다. 실제 프로덕트에 어떻게 적용할 수 있을지 고민해보는 것이 나의 다음 과제이다 :)
66.[통계] 확률분포 시뮬레이션
확률분포를 직접 구현하면서 이해하면, 이론으로만 접했던 개념들이 실제 문제 상황에서 어떻게 활용되는지 명확히 파악할 수 있다. 이 글에서는 균등분포, 베르누이분포, 이항분포, 정규분포를 시뮬레이션하고 결과를 정리해 보았다.
67.[통계] 중심극한정리(CLT) 구현
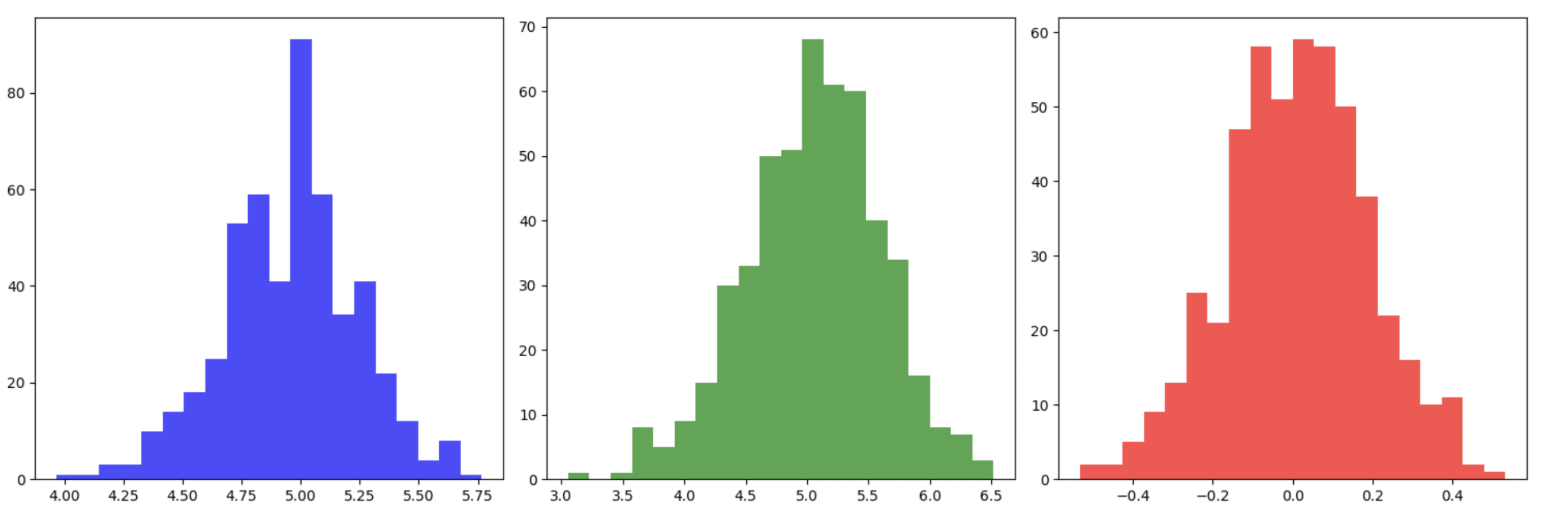
어떤 분포에서 표본을 추출하더라도, 그 평균의 분포는 정규성을 갖게 된다. 따라서 신뢰구간 추정이나 가설검정에서 정규분포를 가정할 수 있는 근거가 생긴다.
68.[통계] 가설 검정
통계적으로 의미 있는 차이가 있는지를 확인하기 위해 가설 검정(hypothesis testing)이 필요하다.
69.[통계] Z-검정과 t-검정 시뮬레이션
이 글에서는 앞서 학습한 통계적 가설검정 개념을 실제 데이터로 구현해보는 실습을 진행한다. 각 검정 방법에 앞서 반드시 검정 전제(정규성, 등분산 등)와 목적에 따라 적절한 방법을 선택해야 한다.
70.[통계] A/B테스트 구현과 해석
Z-test와 P-value를 통해 실험이 ‘진짜로 효과가 있는가’를 데이터 기반으로 판단할 수 있다. 이를 통해 직관이나 추측이 아닌, 통계적 근거에 기반해 결정을 내릴 수 있다. 전환율의 차이가 보이더라도, 그 차이가 의미 있는 것인지는 통계적으로 검증되어야 한다.
71.[통계] 카이제곱 분포와 검정
카이제곱 검정은 수많은 범주형 변수 간 관계를 검증하는 데 활용되며, 특히 모집단의 분포 가정 없이 사용할 수 있다는 점에서 대표적인 비모수 검정이다. 이 글에서는 수식보다는 통계적 해석의 관점에서 정리해 보았다.
72.[통계] 카이제곱 검정: 구현하며 이해하기
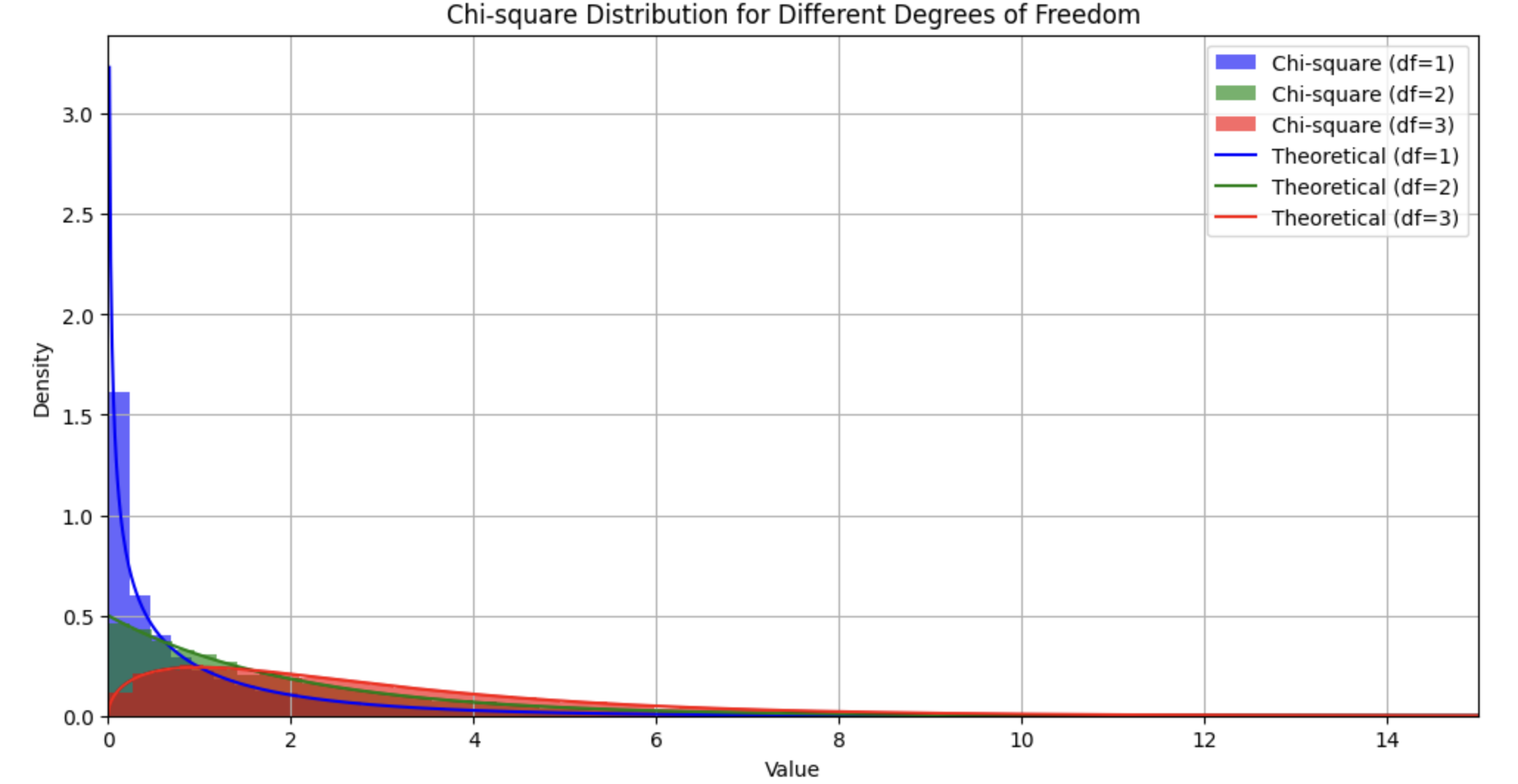
앞선 글에서 카이제곱 검정을 이해한 후, 통계적 사고력과 분석 능력을 키우기 위해 직접 시뮬레이션해 보았다.
73.[통계] F-분포와 ANOVA
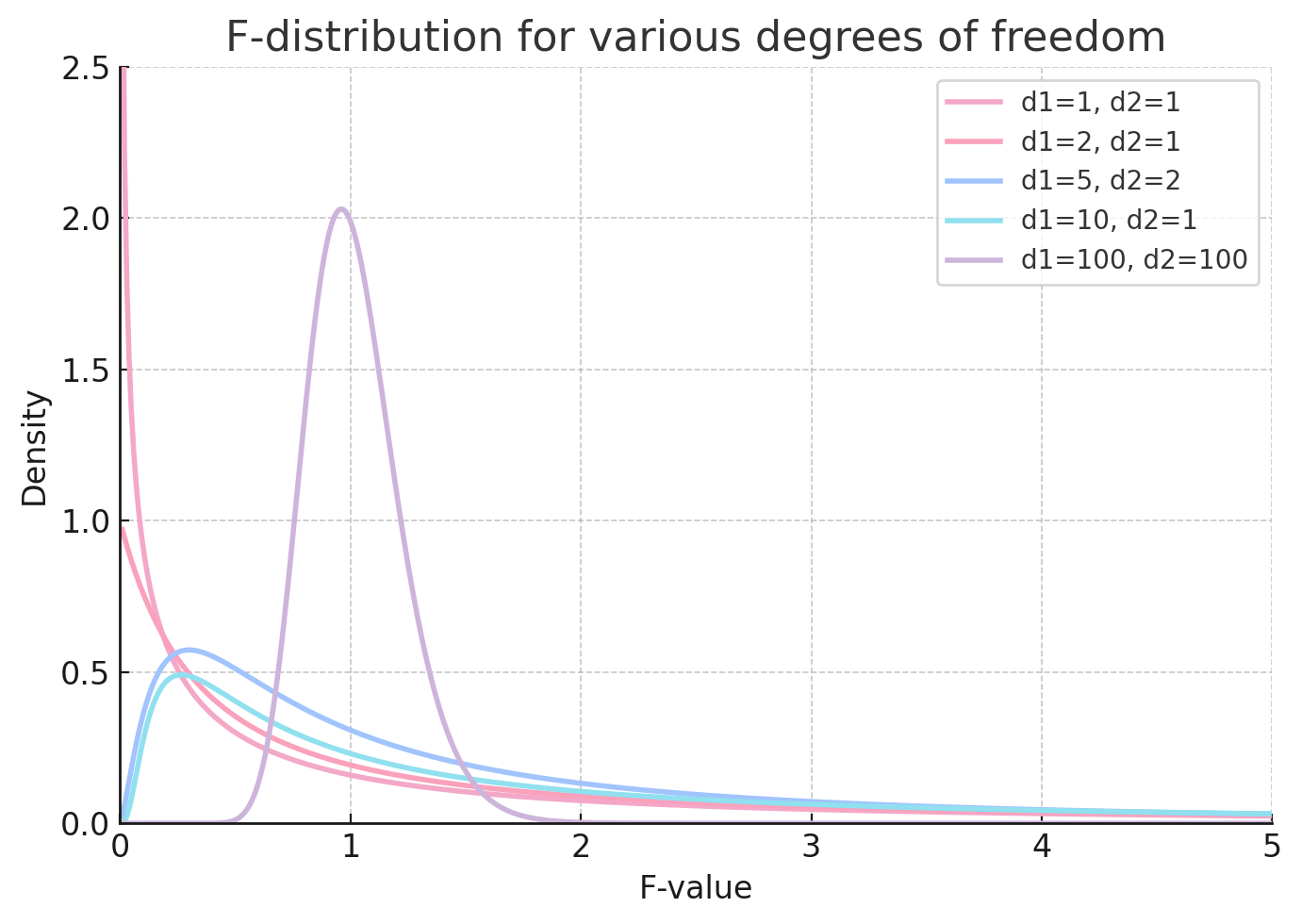
데이터 분석에서는 “그룹 간 평균이 서로 다른가?”라는 질문이 자주 등장한다. 두 집단을 비교할 때는 t-test를 사용하지만, 세 집단 이상이라면 어떨까? 이럴 때 사용하는 것이 ANOVA(Analysis of Variance)이다.
74.[통계] F-분포와 ANOVA 실습
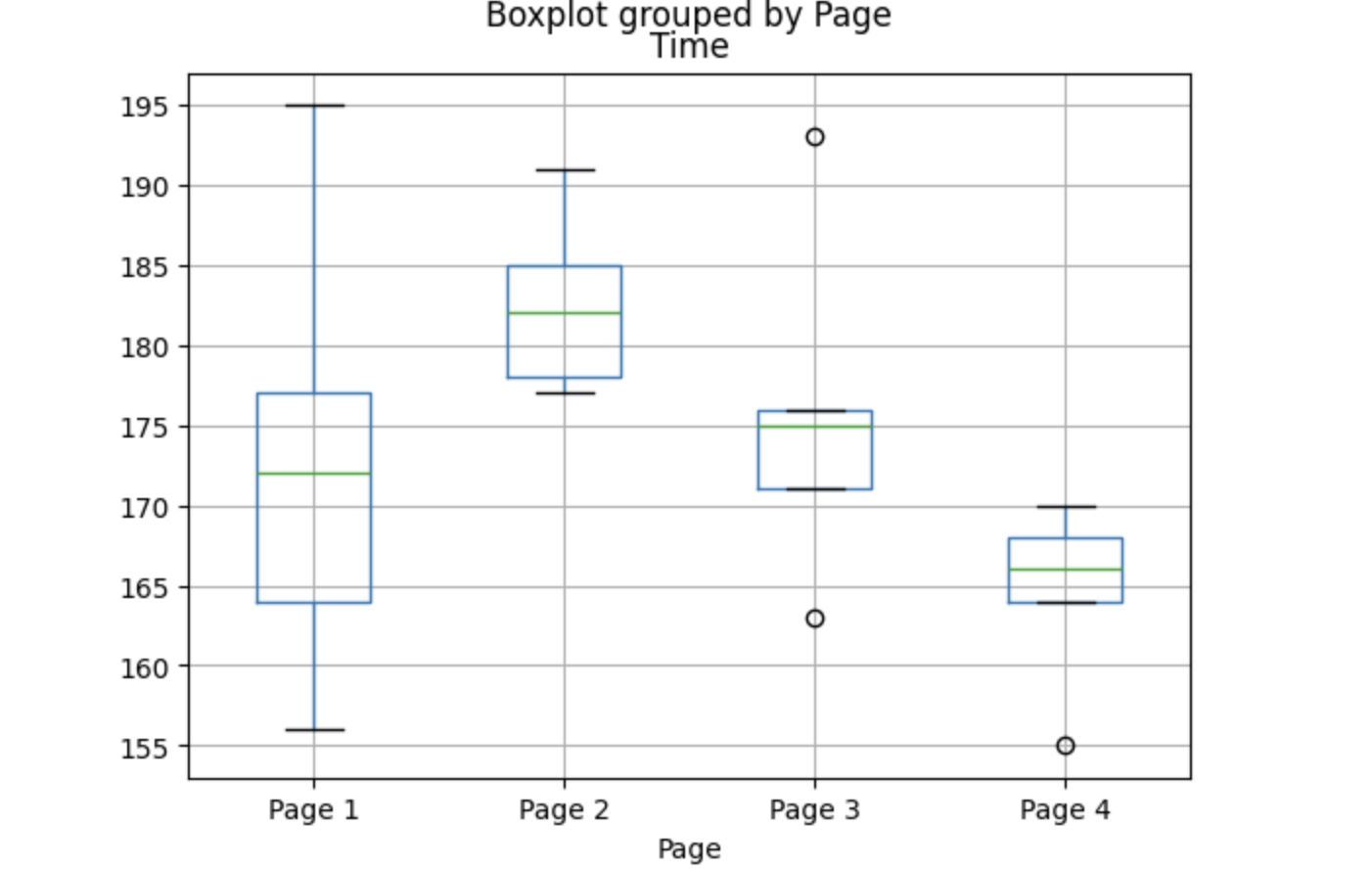
ANOVA는 여러 그룹 평균 비교에 효과적인 검정이다. 하지만 전체 그룹 간 차이만 검정하기 때문에, 어떤 그룹 간 차이가 유의한지는 사후검정으로 확인해야 한다. 특히 오류 누적 가능성 때문에 Tukey’s HSD 같은 사후검정을 사용해야 신뢰성 있는 해석이 가능하다.
75.[통계] 데이터 분석을 위한 통계 회고
지금까지 학습한 데이터 분석에 필요한 전반적인 통계 지식과 Python 기반 실습을 정리하고 회고해 보았다.
76.AARRR Funnel 기반 이커머스 고객 행동 분석 프로젝트
본 프로젝트는 E-commerce 데이터를 기반으로 고객 행동을 AARRR 프레임워크에 따라 분석하고, 각 단계별 지표 정의 후 실제 고객 흐름과 전환을 수치적으로 파악하여 마케팅 및 고객 관리 전략 수립의 기반을 마련하는 것을 목표로 진행하였다.
77.데이터 기반 의사결정을 위한 통계 분석 및 A/B 테스트 결과 해석
본 프로젝트는 다양한 통계 검정 기법과 A/B 테스트 분석을 단계별로 수행하며, 각각의 문제에 대해 가설을 설정하고 통계량을 계산한 후 실제 비즈니스 의사결정에 어떤 영향을 미칠 수 있는지 해석하는 것을 목표로 진행하였다.
78.[Tableau] Tableau Bootcamp Day1
Tableau Korea에서 주최한 자기주도형 부트캠프에 참여했다. Tableau 기초부터 비즈니스 레벨까지 데이터 역량과 경험을 향상시킬 수 있는 과정이었다. 2주 간 수행한 퀘스트를 정리하면서, 이번 기회를 통해 쌓게 된 지식을 완전히 내 것으로 만들고자 한다
79.[Tableau] Tableau Bootcamp Day2
📁"스타벅스 메뉴 데이터"와 📁"매장 정보 데이터"를 이용해 행, 열, 마크의 심화 개념과, 계산식의 기본에 대해 이해에 기반한 시각화 분석을 진행해 보았다.
80.[Tableau] Tableau Bootcamp Day3
📁"스타벅스 메뉴 데이터"와 📁"매장 정보 데이터"를 이용해 매개변수를 생성하여 다른 사용자와 상호작용할 수 있는 시각화 및 대시보드를 구현해 보았다.
81.[Tableau] Tableau Bootcamp Day4
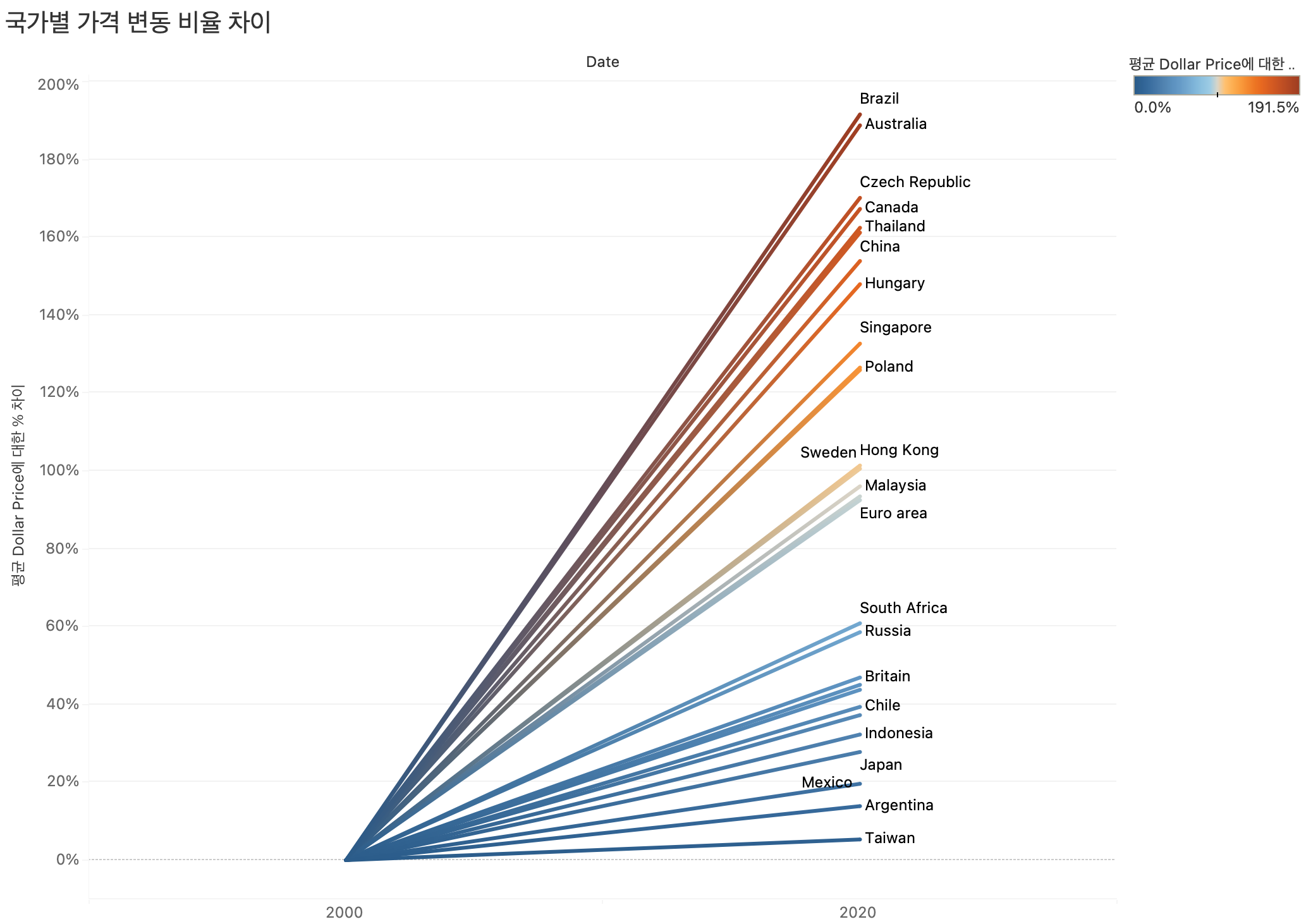
📁"도시대기 미세먼지(PM10) 데이터"와 📁"빅맥 지수 데이터"를 이용해 다양한 시각화를 기반으로 시간 분석을 수행해 보았다.
82.[Tableau] Tableau Bootcamp Day5
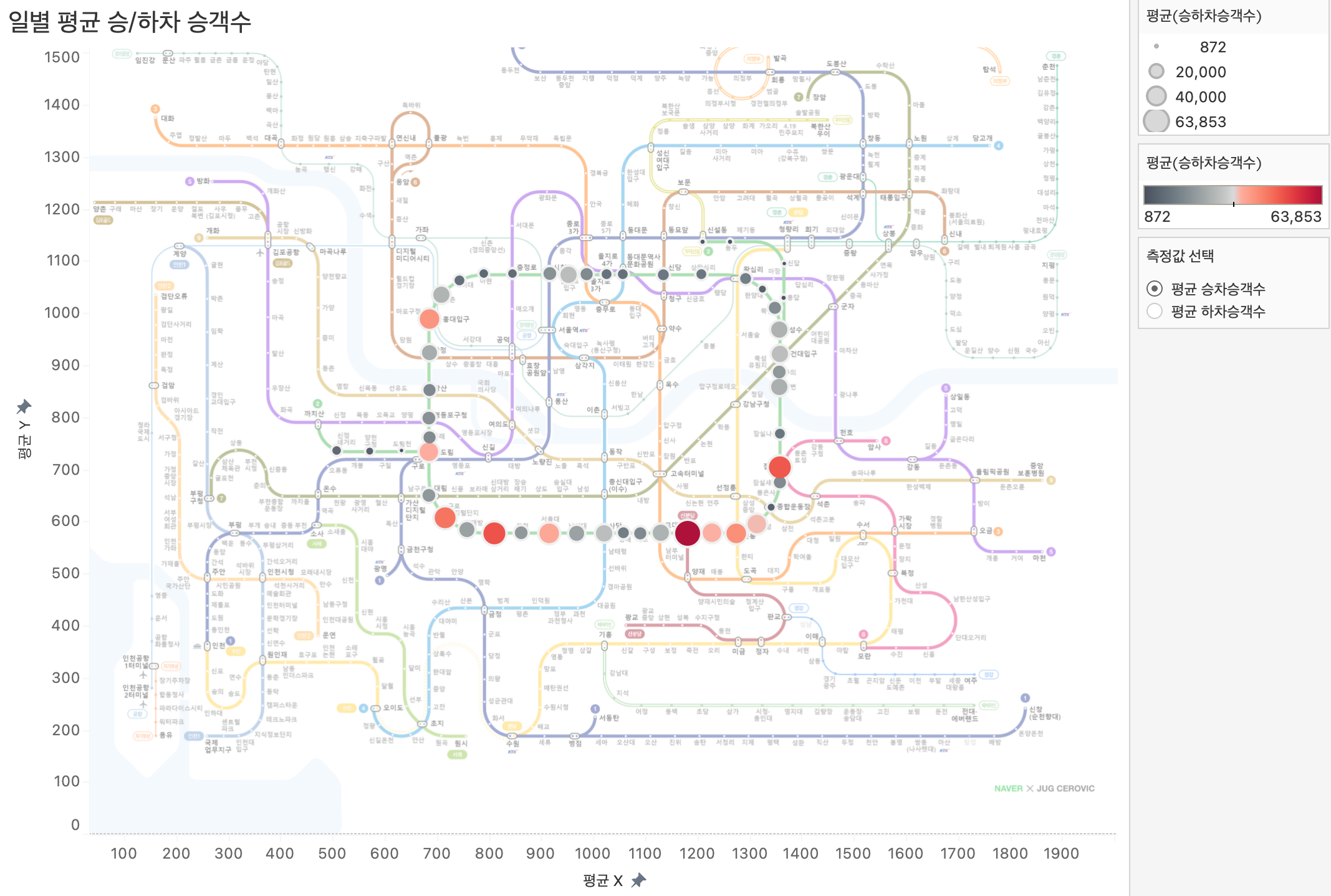
📁"2호선 역별 승하차인원수 데이터", 📁"Airport Extract 데이터", 📁"전국 주유소 추출 데이터"를 이용해 맵을 활용한 다양한 시각화와 공간 분석을 수행해 보았다.
83.[Tableau] Tableau Bootcamp Day6
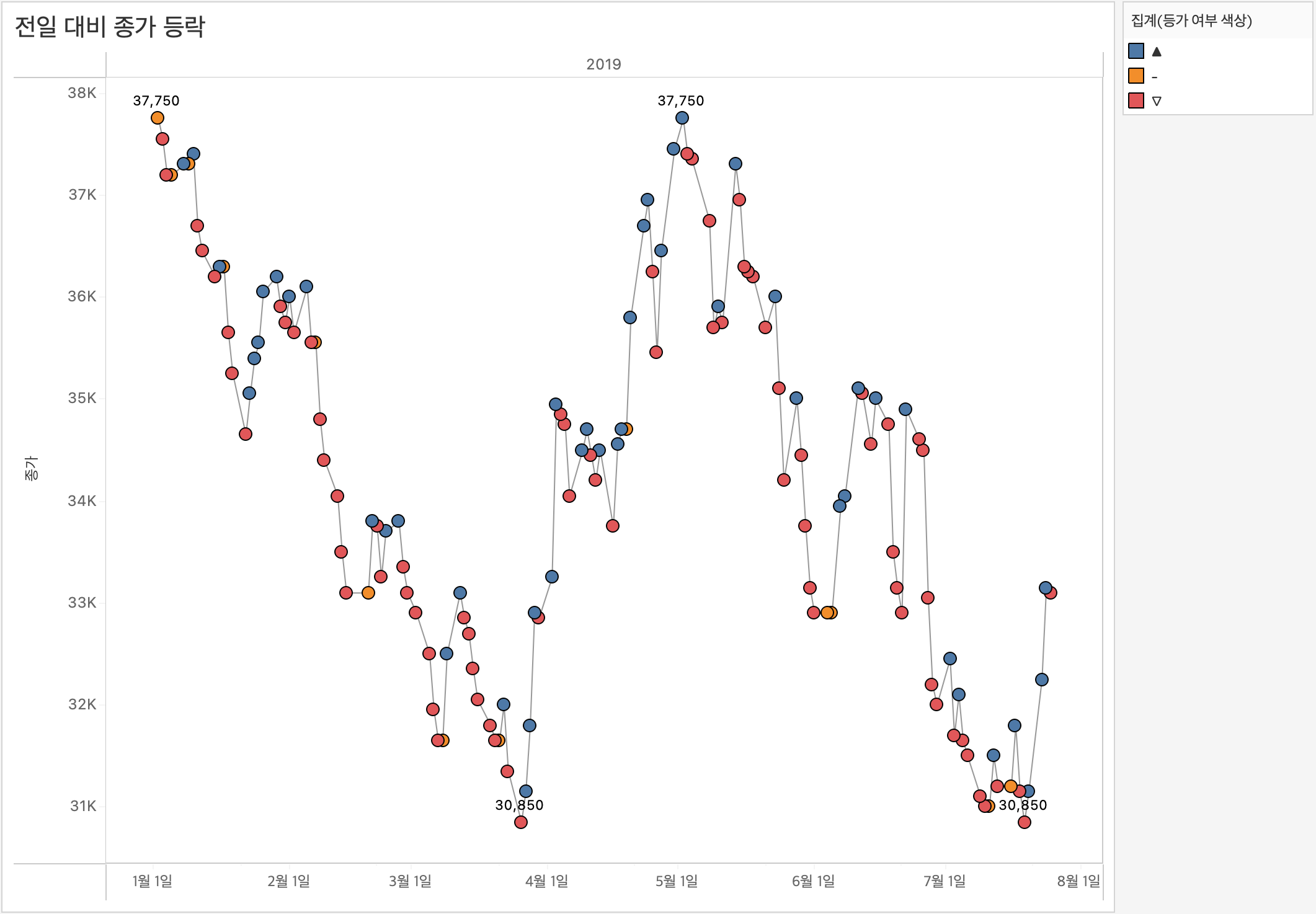
📁"주식 데이터", 📁"주문+반품 추출 데이터"를 이용해 시각화된 데이터에 따라 유연하게 계산 기준을 설정하는 테이블 계산식과, 고정된 기준으로 집계를 수행하는 세부 수준 계산식(LOD)을 실습하며 이해해 보았다.
84.[Tableau] Tableau Bootcamp Day7
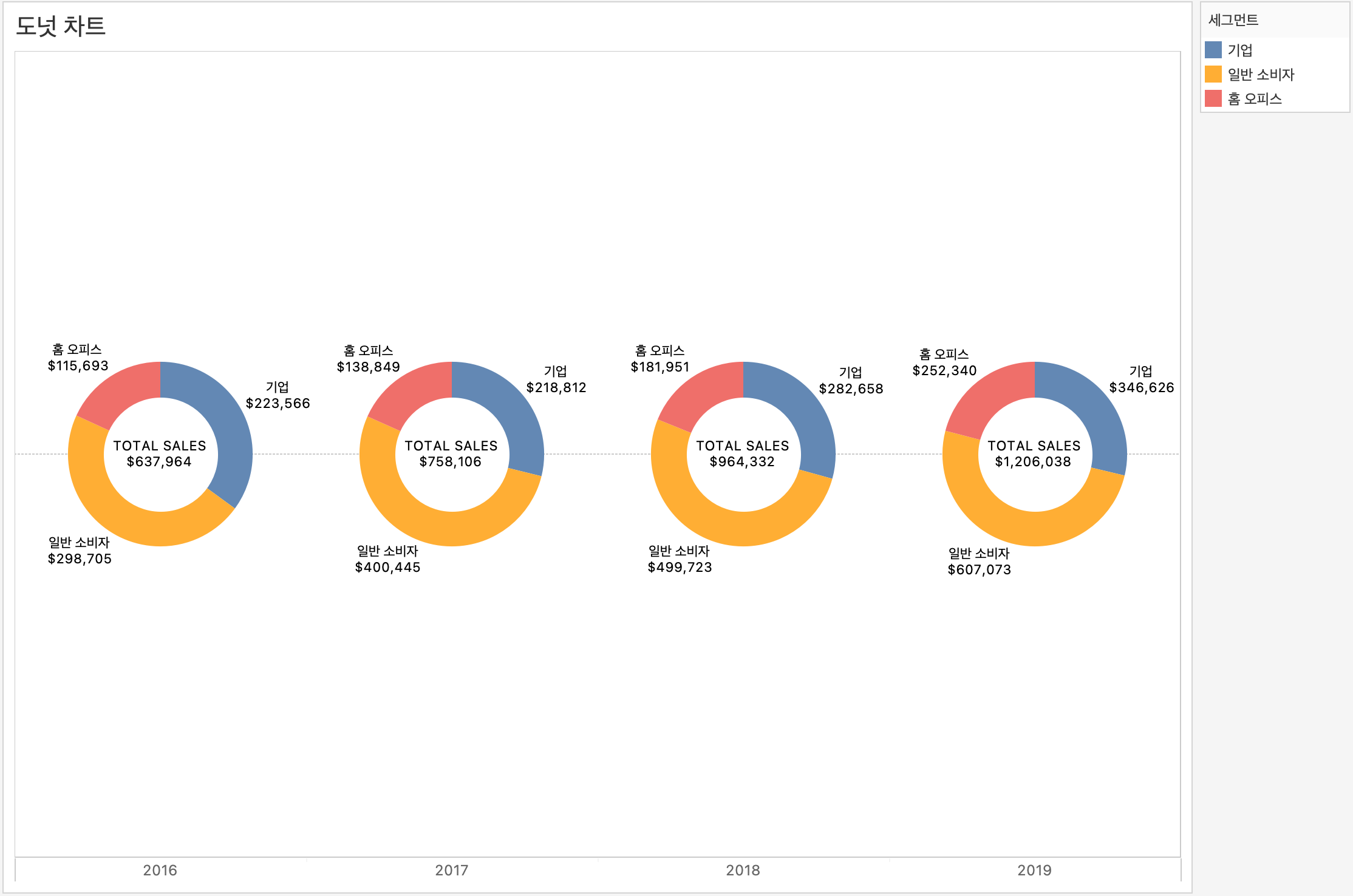
📁"슈퍼스토어 샘플 데이터", 📁"Apple Ads Report 데이터", 📁"스타벅스 매장 정보 데이터"를 이용해 다양한 형태의 시각화 차트(도넛, 워터폴, 범프, 퍼널, 간트)를 구현하며 각각의 분석 목적과 계산 방식에 적합한 차트 유형을 실습해 보았다.
85.[Tableau] Tableau Bootcamp Day8
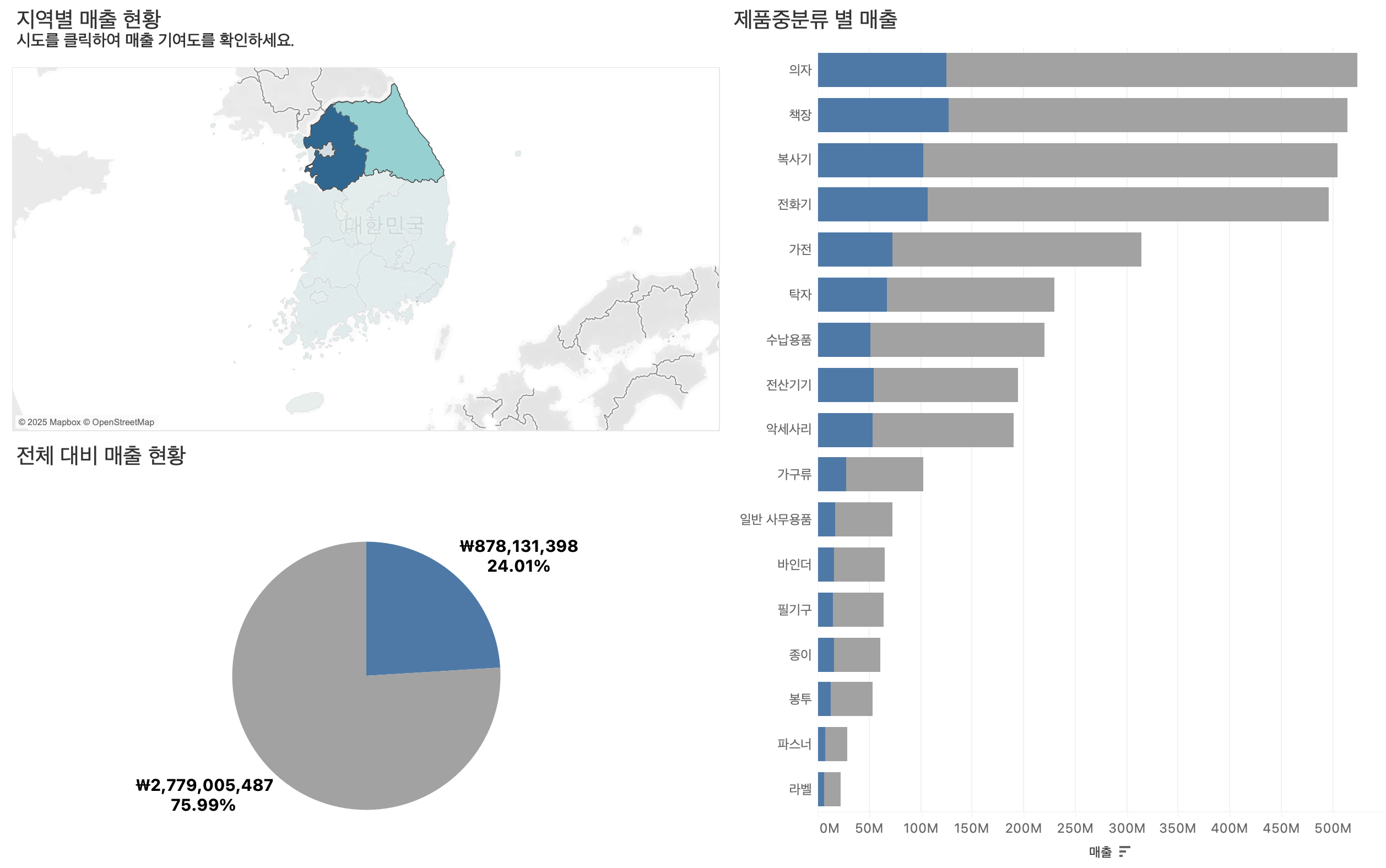
📁"슈퍼스토어 데이터"를 활용해 집합(Set) 동작과 매개변수(Parameter) 변경을 이용한 대시보드 설계 방식을 학습하고, 사용자 선택에 따라 시각화가 동적으로 변화하는 인터랙티브 대시보드를 구현하였다.
86.[Tableau] Tableau Bootcamp Day9,10
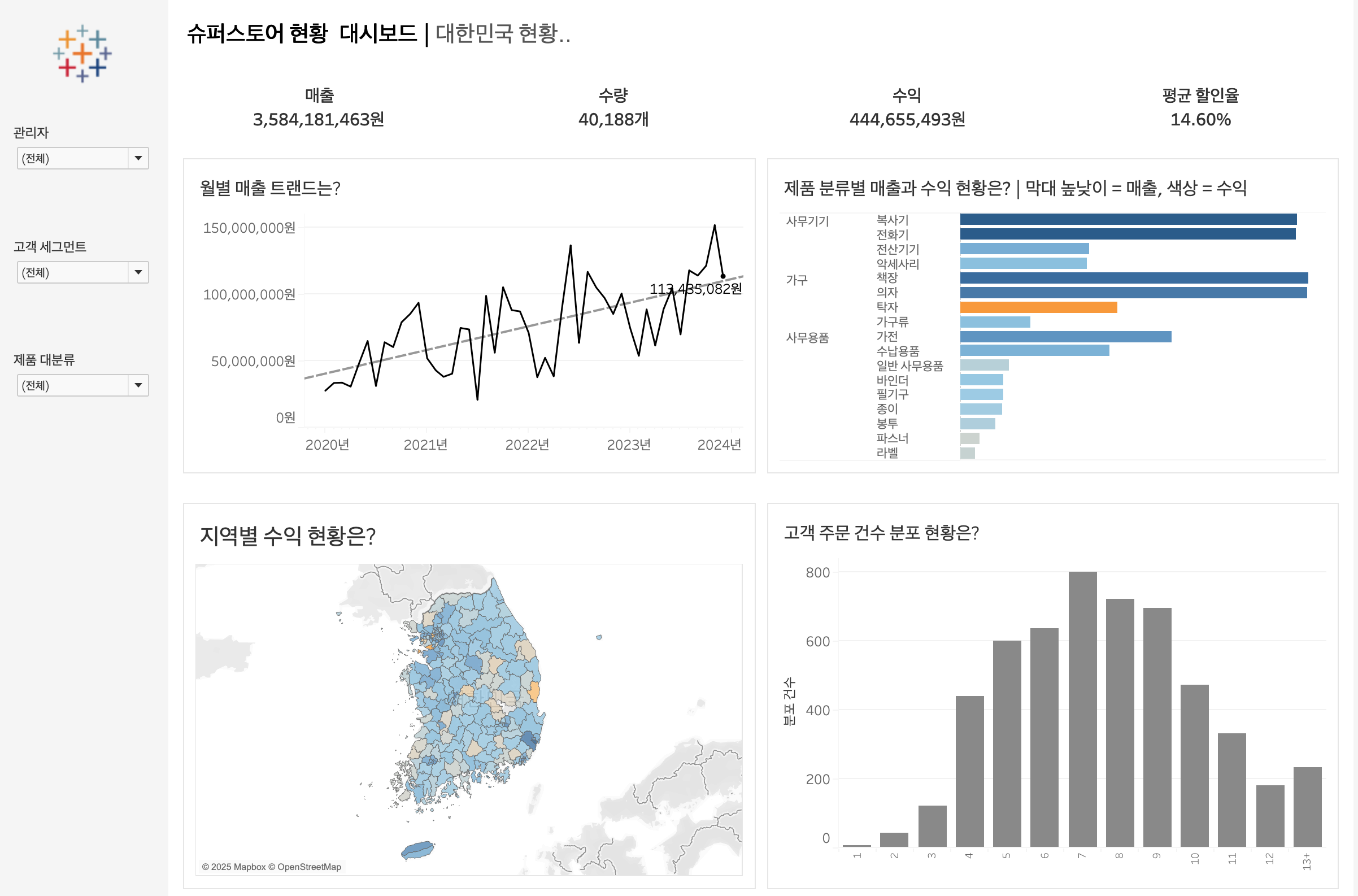
데이터 분석이라는 게 결국 예쁘게 그리는 것이 아니라 올바르게 정리되고 정확하게 연결된 데이터에서 시작해야 한다는 당연한 사실로, 이번 태블로 부트캠프의 마지막 과제를 마무리할 수 있었다.
87.[Tableau] 효과적인 대시보드 디자인을 위한 10가지 인사이트

태블로 부트캠프를 마치면서, 효과적인 대시보드 디자인을 위한 10가지 인사이트를 정리해 보려고 한다. 이 글은 Tableau Korea에서 제공 받은 자료를 바탕으로 이해한 내용을 기록하고 찾아보기 위해 작성하였다.
88.[ML] Scikit-learn
필요할 때마다 효율적으로 참고하여 쓸 수 있도록, 자주 사용하는 전처리와 모델 학습 흐름을 기록해 두려고 한다. 사이킷런을 활용한 머신러닝 실습을 진행하고, 분류와 회귀모델을 중심으로 데이터 처리부터 모델 평가까지의 전체 흐름을 코드로 정리해 보았다.
89.[ML] Classification with Supervised Learning
사이킷런과 XGBoost를 활용하여 대표적인 분류 알고리즘인 의사결정나무, 랜덤포레스트, XGBoost를 실습해보고, 각 모델의 동작 방식과 하이퍼파라미터 설정이 성능에 어떤 영향을 주는지 확인해 보았다.
90.[ML] Classification: Santander Customer Satisfaction
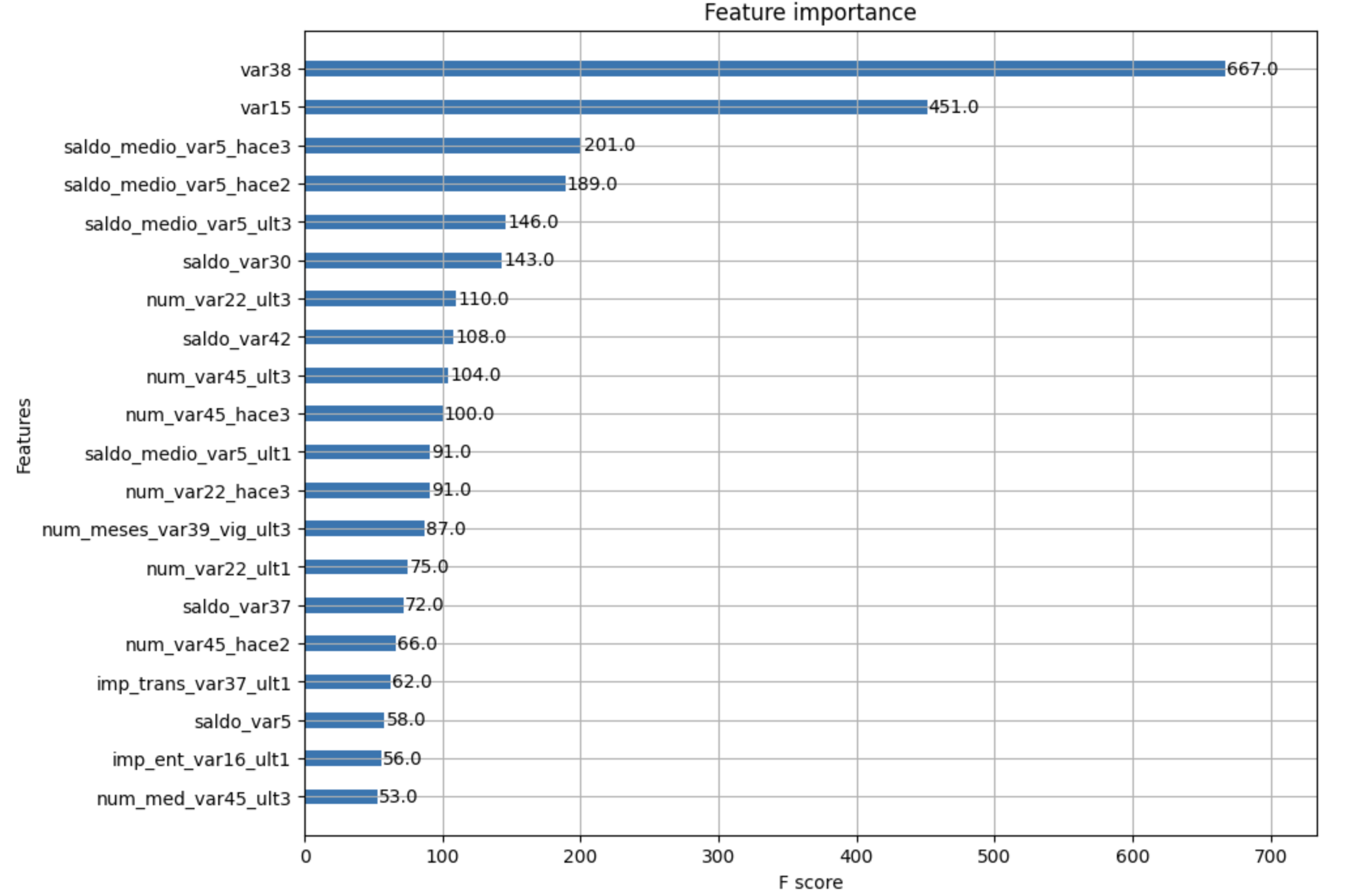
캐글의 산탄데르 고객 만족(Santander Customer Satisfaction) 데이터셋을 기반으로 고객의 만족 여부를 예측하기 위한 분류 모델을 구축하고, XGBoost와 LightGBM을 활용해 하이퍼파라미터 튜닝을 통한 성능 개선 과정을 수행해 보았다.
91.[ML] XGBoost & LightGBM 하이퍼파라미터 튜닝 실험
캐글 Santander Customer Satisfaction 데이터를 기반으로 하이퍼파라미터 튜닝을 통해 XGBoost, LightGBM 모델의 성능을 개선하고, 최종적으로 ROC AUC 성능이 가장 높은 하이퍼파라미터 조합을 도출하는 것을 목표로 진행하였다.
92.[ML] Classification: 불균형 데이터 이진 분류 문제 구조화
Kaggle Credit Card Fraud Detection 대회에 참여하며 불균형 데이터 이진 분류 문제를 해결할 때 기본적으로 세팅하고 가면 좋을 로직을 정리해 보았다.
93.[ML] Regression with Supervised Learning
회귀(Regression)는 수치 예측 문제를 해결하는 대표적인 지도학습 기법이다. 회귀 모델이 학습하는 원리인 비용 함수(Cost Function)와 이를 최적화하는 경사하강법(Gradient Descent)을 알아보고 각 회귀 모델을 비교하는 실습을 진행하였다.
94.[ML] Regression: House Prices
해당 프로젝트는 Kaggle "House Prices: Advanced Regression Techniques" 대회 데이터를 기반으로 Ames 도시의 주택 특성을 분석하고, 주택 가격을 예측하는 회귀 모델을 구현하는 것을 목표로 진행하였다.
95.[ML] Regression: 회귀 문제 구조화
Kaggle의 House Prices 회귀 문제를 해결하면서 기본으로 가져가면 좋을 베이스 로직을 정리해 보았다. 글의 볼륨이 크지만 그래도 회귀 분석이, 혹은 캐글 대회가 아직 낯설다면 아래의 내용 중 얻어 갈 부분이 조금은 있을 거라 생각한다.
96.[ML] 머신러닝에서 모델링이란?
머신러닝에서 사용하는 모델링(Modeling)의 개념을 짚어보고, 학습·예측·검증·평가 등 모델 개발 관련 용어들 사이의 경계를 정리해 보았다. 실제로 머신러닝 프로젝트를 진행할 때 혼동하기 쉬운 표현들과 validation/test 역할 구분도 다뤄 보았다.
97.[ML] 분류 문제, 어떤 모델부터 시도해야 할까?
머신러닝 모델은 그 자체로 정답이 아니고, 모델 선택은 반드시 높은 성능을 내는 알고리즘을 고르는 일도 아니다. 데이터의 특성이나 분석의 목적에 따라 모델 적용 우선순위를 정하고 실험을 확장해 나가는 전략이 필요하다.
98.[ML] XGBoost vs. LightGBM: 하이퍼파라미터 비교
Gradient Boosting 계열의 대표적인 모델인 XGBoost와 LightGBM에는 같은 기능을 다른 이름으로 제공하거나, 문제 유형에 따라 해석이 달라지는 파라미터가 있다. 실험 설계 시 필요한 부분을 선택하여 참고할 수 있도록 용도별로 정리해 보았다.
99.[ML] random_state에 대한 고찰
재현성은 실험의 기본값이다. 머신러닝 실험에서 재현성 확보가 왜 중요한지, 반드시 설정해야 하는 모델에는 무엇이 있는지, 그리고 이를 어떤 전략으로 관리하면 좋을지 실험 설계의 관점에서 정리해 보았다.
100.[ML] 불균형 데이터에서 Precision과 Recall 이해하기
현실의 문제 중에는 양성(Positive) 클래스가 매우 적은 불균형한 데이터가 상당히 많다. 이런 불균형 데이터의 경우에 정확도는 모델의 진짜 성능을 왜곡해서 보여줄 수 있다. 이때 중요한 지표가 정밀도(Precision)와 재현율(Recall)이다.
101.GitHub Push Protection, 보안의 마지막 경고
React Native 앱 개발 중 Google Sheets 연동을 위한 OAuth 토큰 설정 과정에서 발생한 Push Protection 차단 사례를 담아 보았다. 결국 결론은 보안에 경각심을 가지는 것, 커밋 전에 한 번 더 확인하는 습관.
102.[ML] Dimensionality Reduction
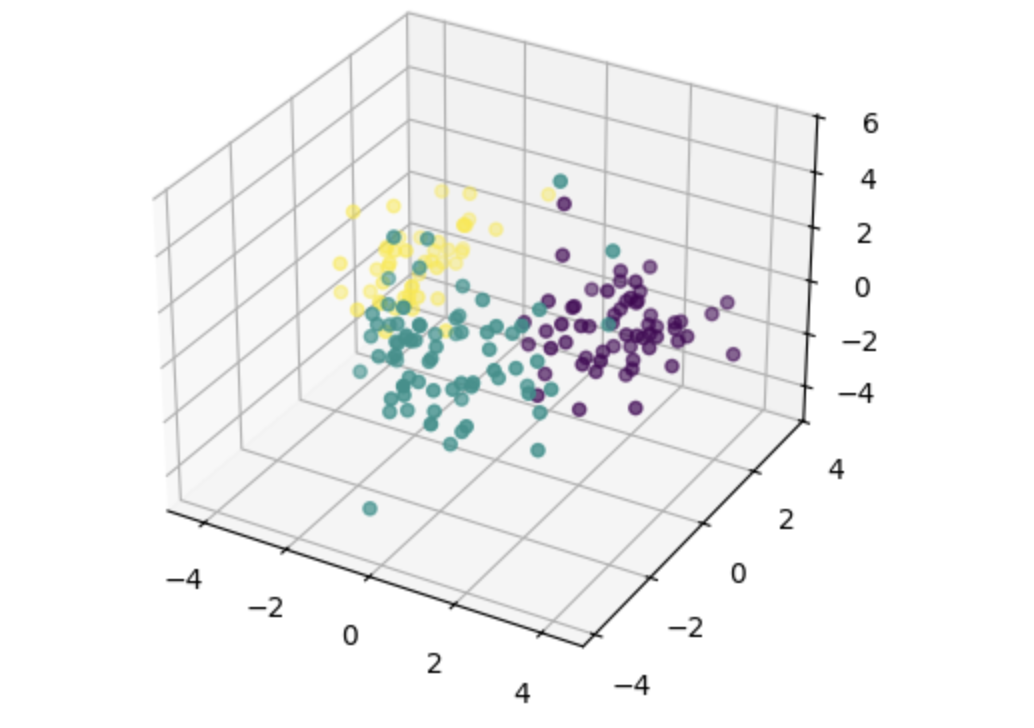
비지도학습은 정답 없이 주어진 데이터를 학습한다. 데이터 안에 숨어 있는 패턴이나 구조를 스스로 찾아내는 것에 초점을 둔다. 그중 차원 축소(Dimensionality Reduction)는 데이터의 특성 수를 줄이면서도 중요한 정보는 최대한 보존하는 방식이다.
103.[ML] Clustering
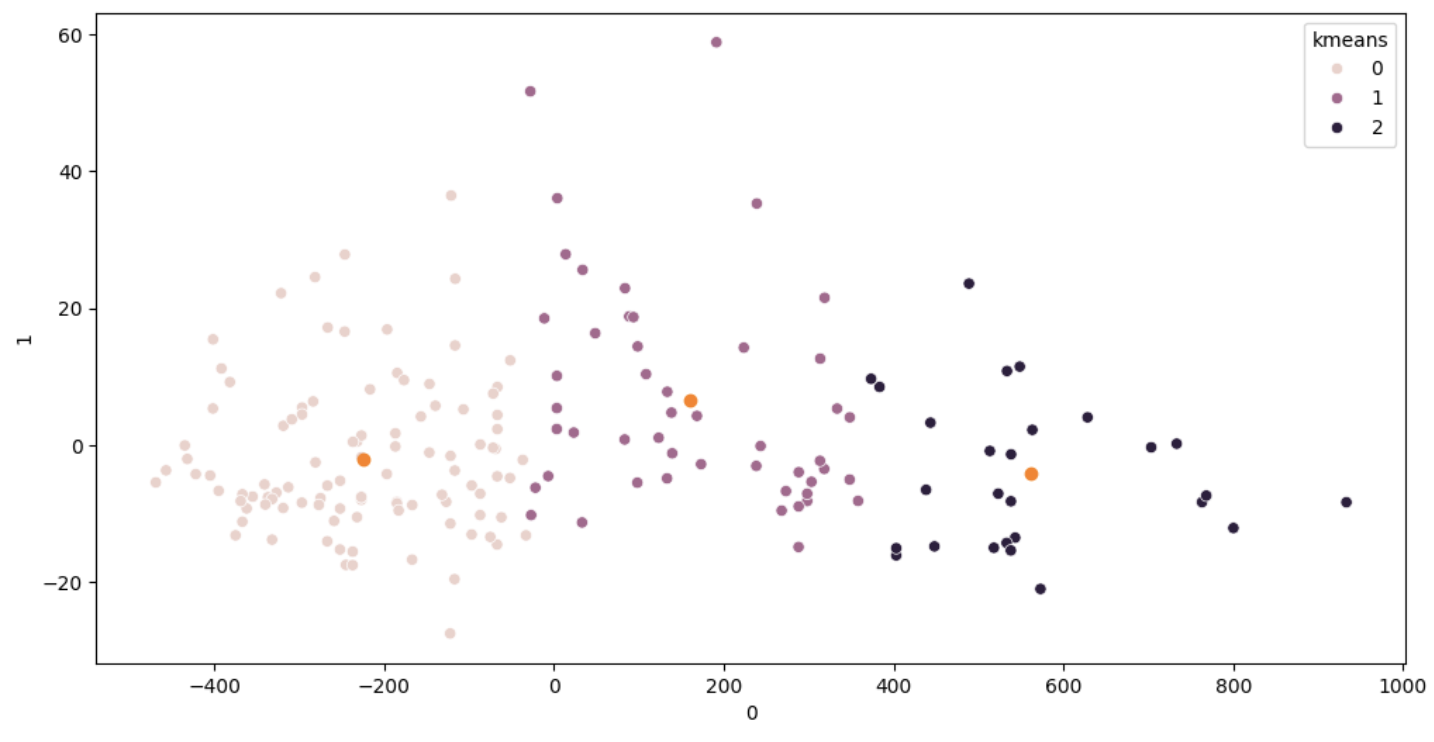
Clustering(군집분석)은 유사한 성질을 가진 데이터들을 하나의 그룹(군집)으로 묶는 비지도학습 기법이다. Clustering의 핵심 목표는 군집 내의 데이터는 최대한 유사하게, 군집 간의 데이터는 최대한 이질적으로 만드는 것이다.
104.[ML] NLP(Natural Language Processing)
자연어 처리(NLP, Natural Language Processing)는 컴퓨터가 인간의 언어를 이해하고 활용할 수 있도록 만드는 기술이다. 챗봇, 음성 인식, 자동 번역, 감정 분석 등 실생활 서비스 전반에 사용되고 있어 기초적인 원리를 이해하는 것이 필요하다.
105.[TimeSeries] 시계열 데이터란
일정한 시간 간격으로 수집되는 데이터는 시계열(Time Series) 데이터에 해당한다. 그렇다면 시간에 따라 나열된 숫자들을 수집하면 모두 시계열 데이터일까? 그렇지 않다. 시계열 데이터에는 시간적 순서와 이전 값과의 관계라는 중요한 특성을 가지고 있어야 한다.
106.[TimeSeries] 시계열에서 도메인 이해하기
시계열 분석은 데이터가 수집된 도메인에 따라 분석의 목적과 해석 방식이 달라진다. 그렇기 때문에 데이터에 시계열 분석을 적용하고자 할 때는 해당 분야에서 자주 사용되는 용어를 미리 파악하는 것이 필요하다.
107.[TimeSeries] 시계열의 성질: Trend, Seasonality, Cycle
시계열 데이터는 시간의 흐름에 따라 관측된 연속적인 데이터다. 대부분의 시계열 데이터는 시간의 흐름에 따라 의미 있는 구조적 패턴을 갖고 있으며, 이를 분석하고 활용하기 위해서는 이 구조를 정확히 이해할 필요가 있다.
108.[TimeSeries] 시계열 분해 해석
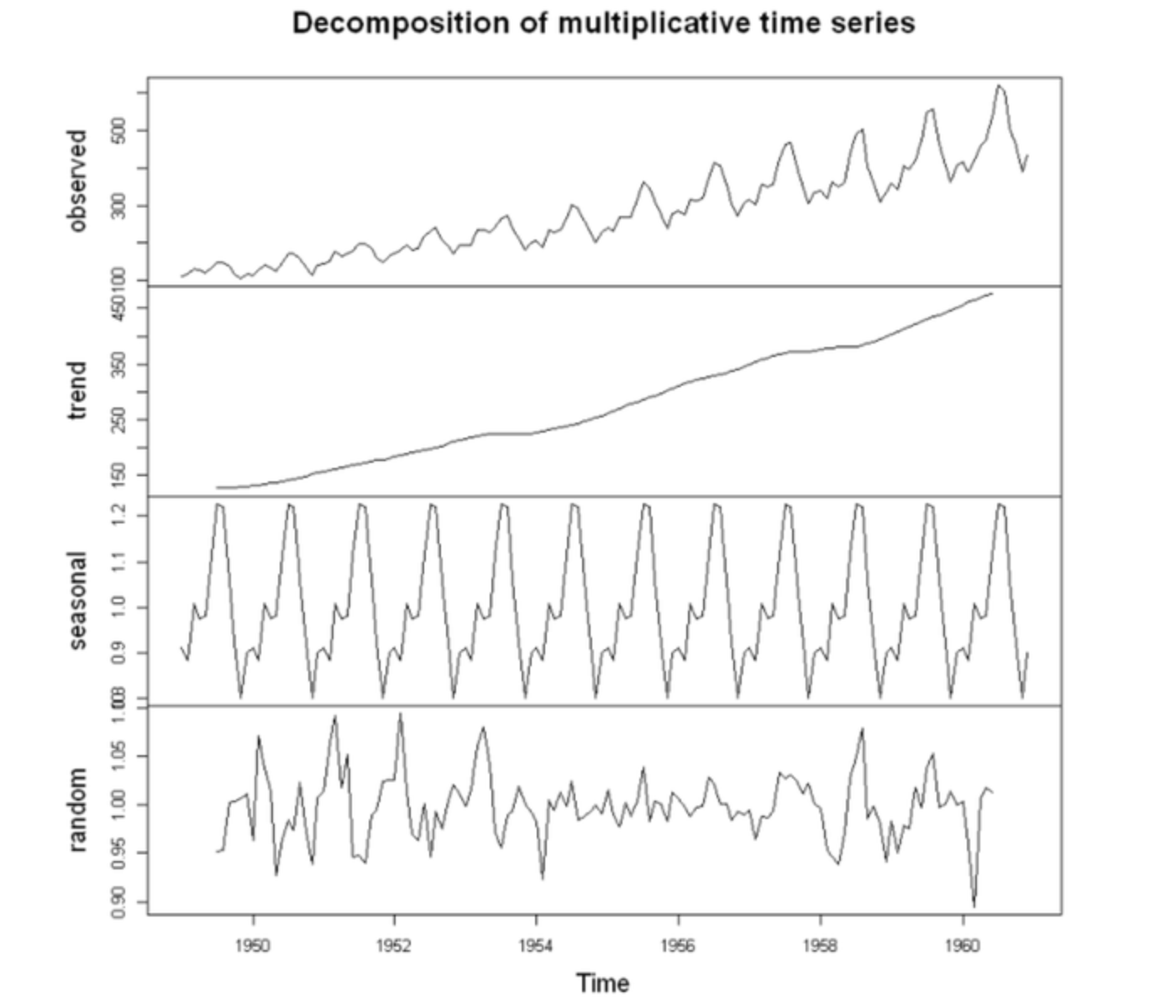
많은 경우 시계열 데이터에는 추세, 계절성, 불규칙성과 같은 구조적 성분이 함께 포함되어 있다. 이러한 구조를 이해하고 분해하는 과정은 예측 모델링, 정상성 확보, 이상 탐지의 기반이 되기 때문에 올바르게 해석하는 것이 중요하다.
109.[TimeSeries] 시계열의 정상성
시계열 분석에서 정상성(Stationarity)은 매우 중요하게 작용하는 개념이다. 시계열 데이터는 시간의 흐름에 따라 관측된 값들의 연속이며, 이 연속적인 데이터의 통계적 특성이 시간에 따라 일정하게 유지되는지 여부가 '정상성'의 여부를 판단하는 기준이 된다.
110.[TimeSeries] 확정적 추세가 있을 때 해석상의 혼란: ADF vs. KPSS
대부분의 시계열 예측 모델은 데이터가 정상성을 만족해야 한다는 전제가 있다. 그러나 많은 데이터는 비정상적인 추세를 갖고 있으며, 이 추세에 따라 접근 방식이 달라진다. 확정적 추세가 있을 때 ADF와 KPSS에서 어떻게 해석상의 혼란이 생기게 되는지 이해해 보았다.
111.[TimeSeries] ACF와 PACF 해석
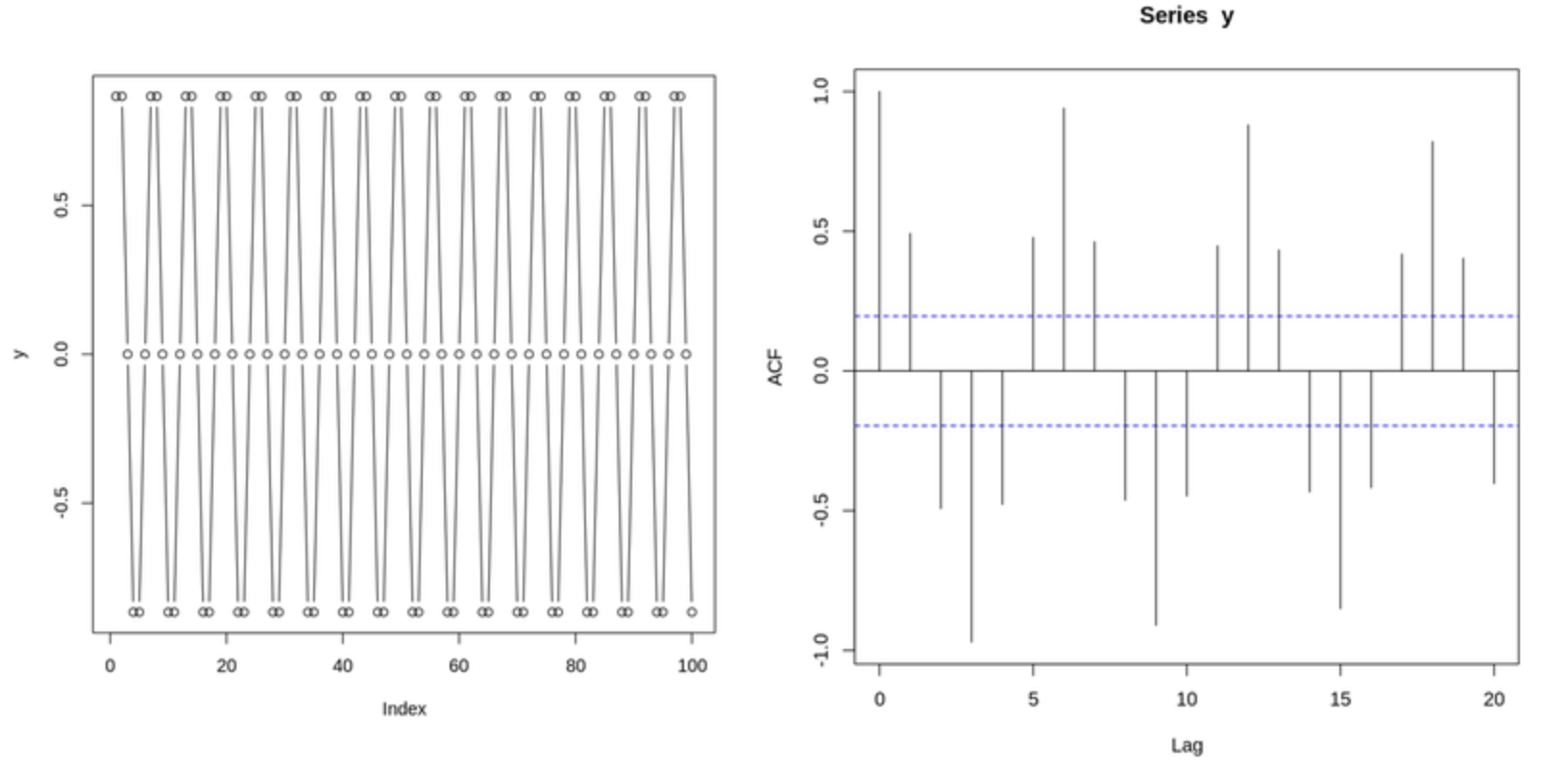
시계열 데이터에서는 패턴의 반복성이나 시차에 따른 자기의존성을 정확히 확인하는 것이 중요하다. 자기상관 함수(ACF)와 부분 자기상관 함수(PACF)를 활용해 이를 확인할 수 있다.
112.시계열 분류 프로젝트: Robot Execution Failures
해당 프로젝트는 로봇 작업 중 발생하는 실패 여부를 시계열 센서 데이터 기반으로 분류하는 것을 목표로 진행하였다. 모델 해석성과 분류 정확도를 동시에 확보하기 위해 시계열에서 추출된 주요 특징을 해석하는 것에 중점을 두었다.
113.[TimeSeries] ARIMA 모델
시계열 데이터를 효과적으로 분석하고 미래를 예측하기 위한 통계 모델 중 하나가 ARIMA다. 2017년 이후 LSTM, Transformer와 같은 딥러닝 기반 시계열 모델이 부상했지만, 복잡성이 낮고 비교적 적은 데이터에서 ARIMA는 여전히 우수한 성능을 보인다.
114.[TimeSeries] 금융시계열과 ARCH 모델의 이해
금융 시계열은 가격 자체보다는 수익률(Return)을 중심으로 분석하는 것이 일반적이다. 수익률은 예측할 수 없는 움직임을 보이는 것처럼 보이지만 일정한 규칙이나 패턴이 반복되는 경우도 있다.
115.[TimeSeries] ARIMA와 GARCH: 시계열 예측과 변동성 모델링
이 글에서 다룰 ARIMA와 GARCH 모델은 모두 단변량 시계열 분석에 기반한 대표적인 통계 모델이다. 두 모델을 각각 실습해 보고, 그 차이점과 적용 목적을 비교하며 실제 데이터를 통해 어떤 경우에 어떤 모델이 적합한지 이해하고자 한다.
116.[TimeSeries] Stationarity &. ARIMA
해당 실습은 시계열 데이터의 정상성 분석부터 ARIMA 모델링, 예측 및 평가까지의 전체 흐름을 구현하며 학습한 기록이다. 시계열의 성질을 진단하고, 비정상 시계열에 대해 ARIMA 모델을 적용하여 예측 성능을 평가하는 것을 목표로 수행하였다.
117.Finance Time Series Classification
해당 프로젝트는 이더리움(ETH)의 분당 시계열 데이터를 기반으로 가격 변화 패턴을 분석하고, 라벨링 및 특징 추출 기법을 적용하여 가격 방향성 분류 모델을 구축하는 것을 목표로 수행하였다.
118.[DATAthon] 팀 빌딩 및 데이터 선정 #1
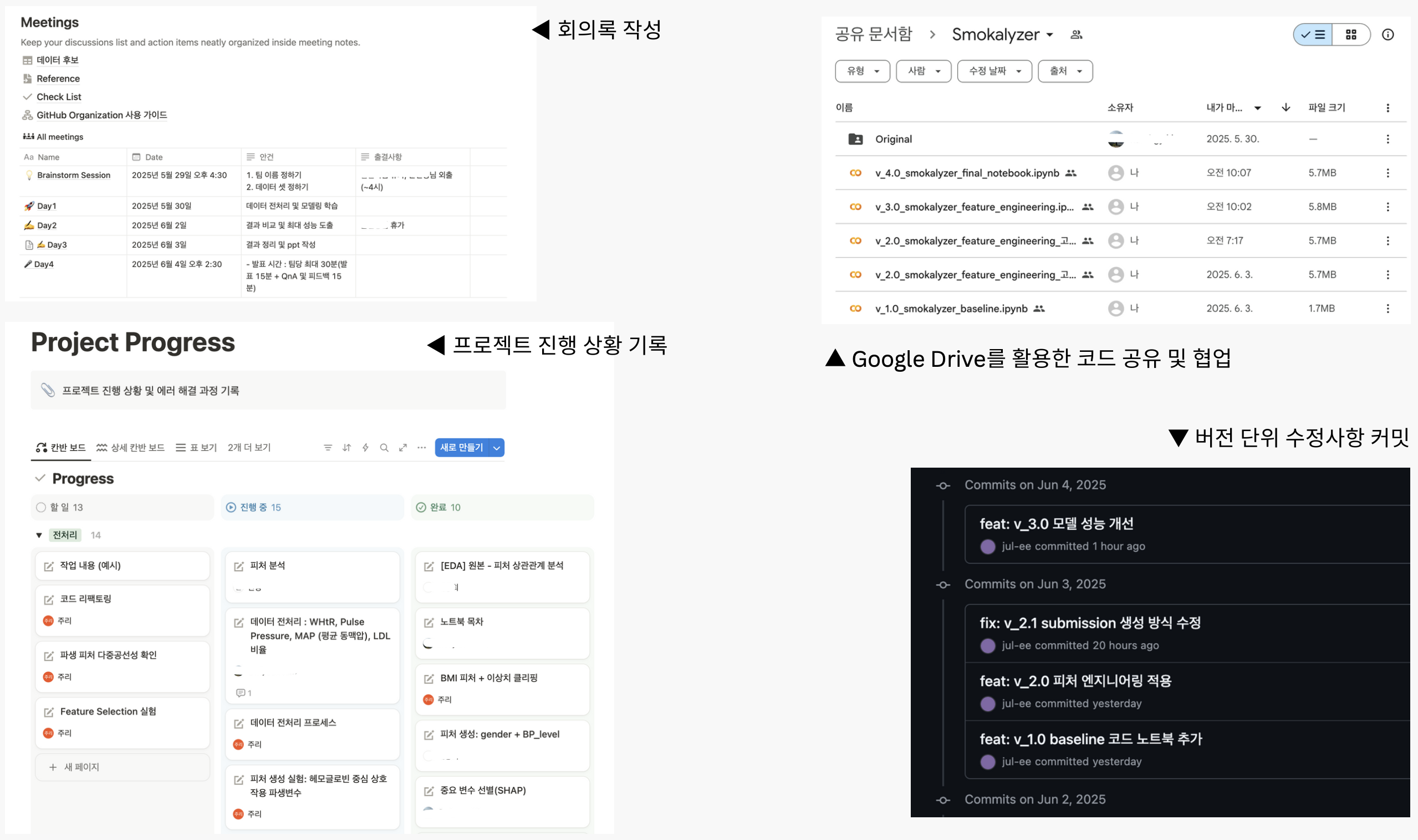
모두의연구소 데싸 4기 과정의 첫 번째 메인 프로젝트인 Datathon이 시작되었다 😊 프로젝트 진행 중에는 실험 과정을 기록하고 성과를 내기에도 시간이 부족했던 터라 데이터톤이 마무리된 지금, 시작부터 되돌아보면서 회고를 담아 진행 과정을 기록해 보기로 했다.
119.[DL] MNIST 숫자 분류로 이해하는 딥러닝
이미지 분류 데이터셋인 MNIST를 활용하여 딥러닝 모델의 핵심 개념과 작동 원리를 실습을 통해 학습하는 것을 목표로 수행하였다. 합성곱 신경망(CNN) 구조를 중심으로 이미지에서 특징을 추출하고 이를 분류하는 전체 흐름을 학습하면서 다음의 내용을 이해할 수 있었다.
120.[DL] 가위바위보 이미지 분류: 웹캠으로 데이터 수집
웹캠을 이용해 가위, 바위, 보 이미지를 직접 촬영하고, 이를 바탕으로 딥러닝 모델을 학습시켜 분류기를 구현한다. MNIST 숫자 분류와 마찬가지로 데이터 수집 → 전처리 → 모델 훈련 → 평가 → 시각화 → 일반화 성능 점검까지의 전체 흐름을 살펴보았다.
121.[DL] Artificial Neural Network
딥러닝에서 가장 먼저 이해해야 하는 개념이 인공신경망(ANN)이다. 핵심 원리는 생각보다 간단할 수 있다. 인간의 뇌 구조에서 영감을 받아 수학적으로 구현된 모델이기 때문이다.
122.[DL] 퍼셉트론의 한계와 MPL
퍼셉트론은 입력과 가중치의 선형 결합을 바탕으로 이진 분류를 수행하는 가장 기본적인 인공 신경망 구조인데, 비선형적인 구조를 가진 문제는 해결하지 못하는 한계가 존재한다. 이러한 한계를 극복하기 위해 은닉층을 추가한 구조인 MLP가 등장하게 된다.
123.[DL] 딥러닝의 구조와 발전
이러한 딥러닝의 중심에는 인공신경망(Artificial Neural Network)이라는 핵심 개념이 존재한다. 이 글에서는 인공신경망의 구조와 원리를 시작으로, 딥러닝 기술이 어떻게 발전해왔고 어떤 방식으로 작동하는지 정리해 보았다.
124.[DL] Tensor의 개념과 구조
딥러닝을 이해하려면 텐서(Tensor)의 개념부터 정확히 짚고 넘어가야 한다. 이 글에서는 텐서의 구조와 연산 방식과 사용 함수들을 코드와 함께 정리하고, 실제 연산 결과를 통해 동작 원리를 직관적으로 이해하는 데 초점을 맞추었다.
125.[DL] 딥러닝 구조와 레이어
딥러닝 모델을 만들기 위해서는 모델의 구성 요소들이 어떤 역할을 하고, 어떻게 연결되는지를 정확히 이해해야 한다. 이 글에서는 Keras에서 딥러닝 모델을 구성할 때 활용하는 주요 API 구조와 레이어의 개념, 종류, 특징, 실제 코드 사용법의 순서로 정리해 보았다.
126.[DL] Keras 딥러닝 모델
딥러닝 모델을 구성하는 방법에는 여러 가지가 있다. 그중 Keras를 사용할 때는 대부분 3가지 방법 중 하나를 선택하게 된다. 각각의 방식이 어떤 구조와 개념적 배경을 갖고 있는지, 왜 그렇게 쓰이는지에 대해 이해하는 과정을 함께 담아보았다.
127.[DL] 손실 함수 (Loss Function)
모델이 학습을 잘하고 있는지를 판단하려면 그 과정에 대한 지표가 필요한데, 손실 함수가 이 역할을 한다. 모델이 예측한 값과 실제 정답 사이의 오차를 수치로 나타내고, 이 값이 작을수록 예측이 정확하다는 뜻이다. 학습은 손실 함수를 최소화하는 방향으로 진행된다.
128.[DL] 옵티마이저와 지표
모델 학습에서 손실 함수가 예측 성능을 수치화해준다면, 옵티마이저는 그 손실 값을 최소화하기 위해 파라미터를 어떻게 업데이트할지를 결정하는 역할을 한다. 학습 도중 혹은 완료 후 모델 성능을 평가할 때는 지표(metrics)를 사용한다.
129.[DL] 딥러닝 모델 학습 기술: 이론
딥러닝 모델의 성능에 있어서 '학습 기술'이 중요하게 작용한다. 어떤 활성화 함수를 사용할지, 가중치는 어떻게 초기화할지, 학습률은 얼마나 줄지, 배치 단위는 어떻게 설정할지 등 세부적인 설정이 전체 결과를 결정짓게 된다.
130.[DL] Adam vs. SGD로 보는 EarlyStopping 작동 원리
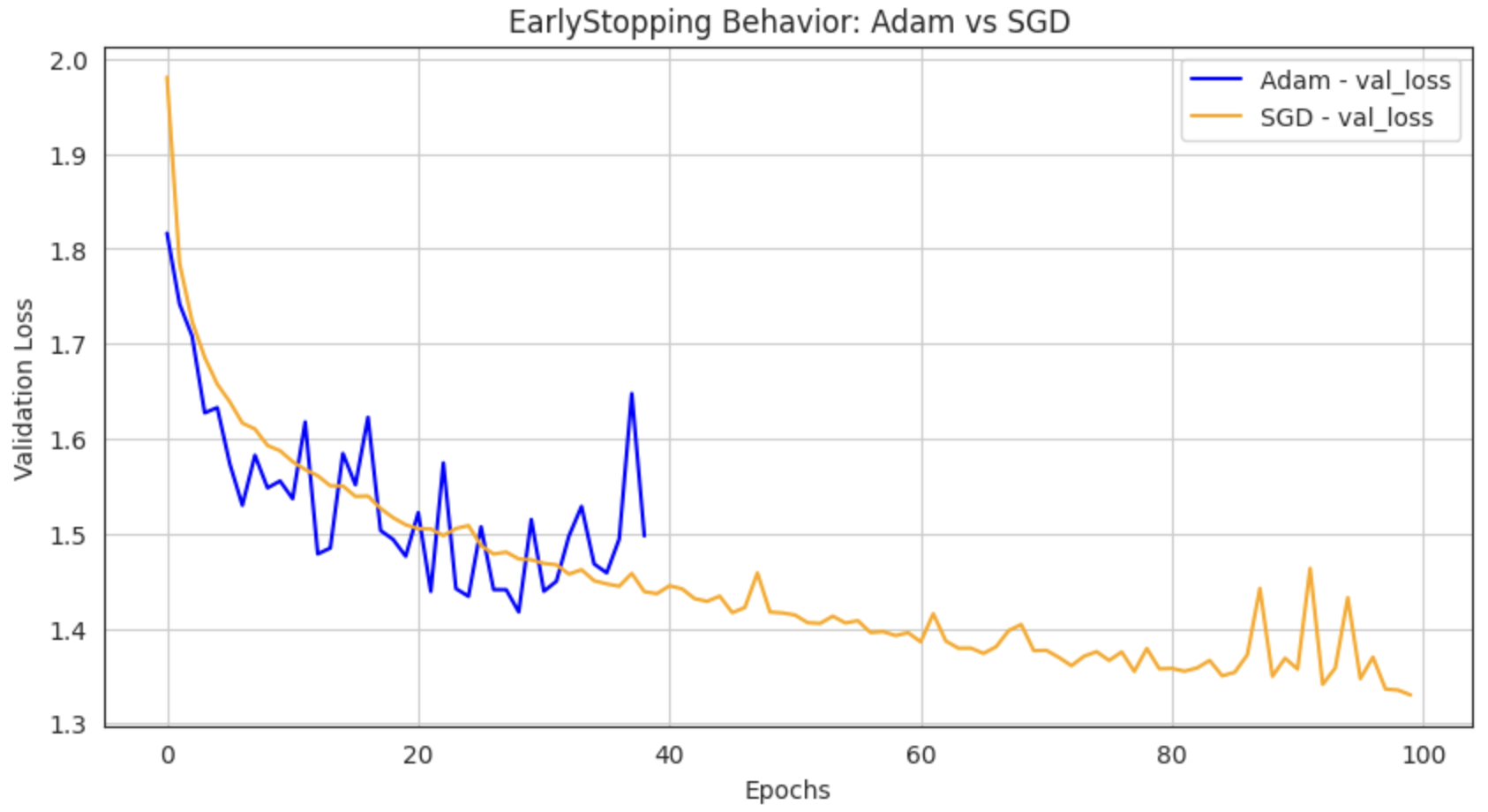
딥러닝 학습 중 EarlyStopping 콜백 동작에서 의문이 하나 생겼다. " 은 모델, 같은 학습 조건인데 .. Adam을 쓰면 중간에 멈추고, SGD를 쓰면 끝까지 100 epoch 다 돌아버리네?"
131.[DL] 자연어 처리를 시작하기 전에
기계는 인간의 언어를 제대로 이해할 수 있을까?
132.[DL] Tokenization: 기계가 텍스트를 다루려면
자연어 처리를 위해서는 토큰화(Tokenization)를 이해해야 한다. 문장을 기계가 이해할 수 있는 형태로 바꾸기 위해서는 먼저 문장을 잘게 쪼개는 작업이 필요하다.
133.[DL] 토큰에 의미 부여하기
기계는 숫자 연산을 통해 데이터를 인지한다. 그렇다면 텍스트로 이루어진 문장을 어떻게 숫자로 바꾸고, 또 의미를 담게 할 수 있을까?
134.로그 데이터 수집 자동화 환경 구축하기
날씨앱을 개발하고 서비스하면서 사용자 경험을 더 정교하게 만들고 싶다는 욕심이 생겼다 🌤️ 복잡한 서버 연동 없이 앱 단에서 수집할 수 있는 구조를 만들고자 했고, 그 결과 Google Sheets 를 활용하여 경량-무서버 로그 수집 시스템을 구성하게 되었다.
135.💊 영양제 Check! 개발기

『모두의 영양소』 RAG 기반 건강 정보 맞춤 영양제 추천 프로젝트
136.💊 영양제 Check! 프로젝트 회고
이번 프로젝트는 "영양제 추천 서비스 만들기" 가 아니라, LLM이 어떻게 더 신뢰성 있게 정보를 전달할 수 있을까에 대한 고민과 실험이었다고 할 수 있다. 그 과정에서 배우고 느낀 점들을 정리해 보려고 한다.
137.[추천시스템] 딥러닝과 추천 시스템
추천 시스템의 중요성과 딥러닝을 접목함으로써 생기는 이점을 시작으로, 딥러닝 기반 추천 시스템의 실제 사례와 평가 지표를 통해 좋은 추천 시스템이란 무엇일지 이해하고 정리해 보았다. 실제로 서비스에 추천 시스템을 적용하기 위해 무엇을 고려해야 할지 생각해 보자.
138.[아이펠톤] 프롬프트 엔지니어링: 도메인 지식 내장형 CoT로 과학 추론 강화하기
Integrating Chemistry Knowledge in Large Language Models via Prompt Engineering (Liu et al., 2024)
139.[아이펠톤] LLM 토론 시스템 도입: DEEVO, DReaMAD 연구 분석
LLM 토론 시스템을 도입해야 하는 이유: DEEVO와 DReaMAD 연구 분석