🖇 리텐션 분석이란?
🖇 리텐션의 유형
🖇 월별 리텐션 분석하기
사용자를 모으는 건 어렵지 않다. 광고를 때리고, 프로모션을 걸면 금방 수치가 올라가니까 :)
하지만 진짜 중요한 건 얼마나 많은 사용자가 다시 우리 서비스로 돌아오는가이다.
바로 이 지점을 데이터로 보여주는 것이 리텐션(Retention) 분석이다.
리텐션은 단순히 반복 방문률을 뜻하는 것이 아닌, 사용자가 우리 서비스에 얼마나 만족했고 얼마나 신뢰했는지를 가늠하게 해주는 지표이기도 하다.
이번 글에서는 리텐션의 개념부터 자주 쓰이는 Cohort 기반 리텐션 분석 방법, 그리고 BigQuery와 Google Sheets를 활용한 월별 리텐션 분석 실습까지 함께 정리해 보았다.
🖇 리텐션 분석이란?
리텐션(Retention)은 시간을 두고 사용자들이 얼마나 지속적으로 우리 서비스를 이용하고 있는지를 보여주는 지표이다.
한 번 방문했던 유저가 다시 돌아오는지, 얼마나 자주 돌아오는지를 알 수 있기 때문에
서비스의 "충성도", "유의미한 유입", "지속 가능성"
등을 평가할 때 반드시 살펴봐야 한다.
예를 들어,
✨ 대규모 프로모션으로 10만 명의 사용자를 유치했지만, 7일 후 리텐션이 1%라면
실제로 남아 있는 사용자는 1,000명밖에 되지 않는다.
그만큼 리텐션 분석은 단순한 수치 이상의 의미를 담고 있으며,
많은 기업들이 이탈의 원인을 파악하고 개선점을 도출하기 위해 반드시 진행하는 분석 프레임워크이다.
🖇 리텐션의 유형
리텐션은 분석 목적에 따라 보통 다음 세 가지로 나뉘며,
각 유형마다 분석하는 방식과 해석의 포인트가 조금씩 다르다.
| 유형 | 설명 | 특징 |
|---|---|---|
| Class Retention | 기준일을 기준으로 특정일에 사용자들이 정확히 방문했는지를 측정 | 1일 차, 7일 차, 30일 차 리텐션 추적 등→ Cohort 분석에 자주 사용 |
| Rolling Retention | 기준일을 포함하여 그 이후에 한 번이라도 재방문한 사용의 비율 | "가입 이후 7일 이내에 재접속한 적이 있는가?" |
| Range Retention | 일 단위인 클래식 리텐션을 구간 범위로 확장한 방식 | 고객의 재방문 주기에 맞게 분석 구간을 유연하게 설정 가능 |
리텐션을 이해하는 데에 아래 블로그의 도움을 받았다.
리텐션 (1) Classic Retention
리텐션 (2) Rolling Retention
리텐션 (3) Range Retention
Class Retention
가장 보편적으로 사용되는 리텐션 측정 방식으로, 기준일을 기준으로 정해진 날짜에 해당 사용자들이 얼마나 남아 있는지 측정한다.
카카오톡 같은 메신저 앱이나, 트위터 같은 SNS 서비스 등 사용자가 매일 접속해서 사용할 것으로 기대되는 서비스에 활용하기 적절한 지표이다.
이렇게 매일매일 사용하는 게 아니라 사용 주기가 길 경우 Class Retention을 사용하면,
특정일에 대한 유지율만 보여주기 때문에, 실제 사용자들의 재방문율을 과소 측정하게 되다는 단점이 있다.
6일 내내 우리 서비스에에 방문했던 사용자라도 7일차에 딱 방문하지 않는다면 D+7 리텐션에는 집계되지 않기 때문이다.
이처럼 Class Retention은 고객이 정확히 N일 후 제품을 재사용하는 비율을 측정한다. 그렇기 때문에 제품의 사용 주기가 길다면 아래의 두 가지 측정 방식을 채택하는 것을 권한한다.
Rolling Retention
N일 이후 단 한 번이라도 재방문한 활성 사용자의 비율을 계산한다.
Class Retention과 비교했을 때, 사용자가 제품을 매일 재사용하는지 보다는 실제로 우리 제품을 재사용하는지 여부를 확인한다는 점에서 더 적합하다.
하지만 특정 기간 이후로 한 번이라도 방문한 고객을 모두 리텐션 고객으로 인정한다는 측면에서 리텐션이 다소 높게 측정된다는 단점이 있다.
또한, 측정일을 언제로 잡냐에 따라서 계속해서 리텐션이 바뀐다는 점도 유의할 사항이다. 예를 들어 누군가는 매일 방문하는 충성 고객인데 한 달만에 오랜만에 방문한 고객이라고 했을 때, 30일 리텐션을 기준으로 같게 취급된다는 단점이 있다.
Range Retention
일 단위인 Class Retention을 구간 범위로 확장한 방식이다. 고객의 재방문 주기에 맞게 분석 구간을 유연하게 설정할 수 있는 것이 장점이다. 지정된 기간 내에서만 한 번 이상 방문하면 리텐션을 계산되므로 재방문 주기가 긴 제품에서 유용하게 사용할 수 있다.
Rolling Retention과 마찬가지로 구간 설정이 길어질수록 리텐션이 과대 추정될 수 있다는 단점이 있다.
비즈니스에서 리텐션이 높다는 것은 우리 서비스가 지속적으로 방문할 만한 매력적인 가치를 주고 있다는 의미이다. 그렇기 때문에 리텐션이 높은 서비스는 최대한 많은 고객을 유입시켜서 성장하는 전략을 사용한다. 하지만 반대로 리텐션이 높지 않은 경우 아무리 많은 고객을 유입시켜도 서비스 자체의 가치가 부족하기 때문에 장기적인 관점에서 사업이 유지되기 힘들 수 있다.
💡 이런 점 때문에 굉장히 많은 조직에서는 리텐션을 핵심 지표로 관리한다.
이제 BigQuery에서 Class Retention 지표를 기반으로 월별 리텐션을 분석해 보자.
🖇 월별 리텐션 분석하기
영양제처럼 사용 주기가 긴 제품을 주력으로 판매하는 회사가 있다고 하자.
이 경우에는 일일 리텐션보다 월 단위로 고객이 돌아오는지를 분석하는 것이 더 의미가 있다.
리텐션 분석에서 자주 등장하는 개념 중 하나가 바로 Cohort(코호트)인데, 아래에서 자세히 알아보자.
Cohort
코호트란 '동일한 특성을 공유하는 집단'을 의미한다.
데이터 분석에서는 보통 특정 시점에 동일한 조건으로 유입된 사용자 집단을 코호트라고 부른다.
예를 들어, 다음과 같은 기준으로 코호트를 나눌 수 있다.
- 가입일 기준 코호트: 2023년 1월에 가입한 사용자
- 첫 구매일 기준 코호트: 2023년 2월에 처음 구매한 사용자
- 광고 채널 기준 코호트: 인스타그램 광고를 보고 유입된 사용자
그렇다면 왜 코호트를 나누는 것일까?
모든 유저를 한꺼번에 묶어 평균을 내버리면, 실제로 "어떤 시점의 유저가 얼마나 오래 남아 있었는지" 를 파악하기 어렵다.
하지만 코호트 단위로 묶어서 분석하면 특정 시기에 유입된 유저들이 시간이 지나도 여전히 활동 중인지, 어느 시점에 이탈했는지를 훨씬 정교하게 분석할 수 있다.
예를 들어
- 2023년 1월에 유입된 유저들의 3개월 후 리텐션이 50%
vs - 2023년 2월 유입 유저들의 3개월 후 리텐션이 15%
이렇게 되면, 2월에 유입된 유저들에 무슨 문제가 있었는지 집중적으로 분석할 수 있는 것이다.
Cohort 분석하기
먼저, 각 사용자의 최초 구매일(cohort_day) 을 구한다.
WITH cohort_base AS (
SELECT user_id,
MIN(invoice_date) AS cohort_day
FROM project_name.dataset.retention
GROUP BY user_id
)
그 다음, 실제 구매 데이터와 조인하여
cohort_group: 최초 구매가 일어난 월cohort_index: 최초 구매 기준 몇 개월 후인지
를 계산한다.
, retention_with_cohort AS (
SELECT
user_id,
DATE_TRUNC(c.cohort_day, MONTH) AS cohort_group,
DATE_DIFF(r.invoice_date, c.cohort_day, MONTH) AS cohort_index
FROM project_name.dataset.retention AS r
JOIN cohort_base AS c
USING(user_id)
)
이제 최종적으로 cohort_group과 cohort_index를 기준으로 user_count를 구한다.
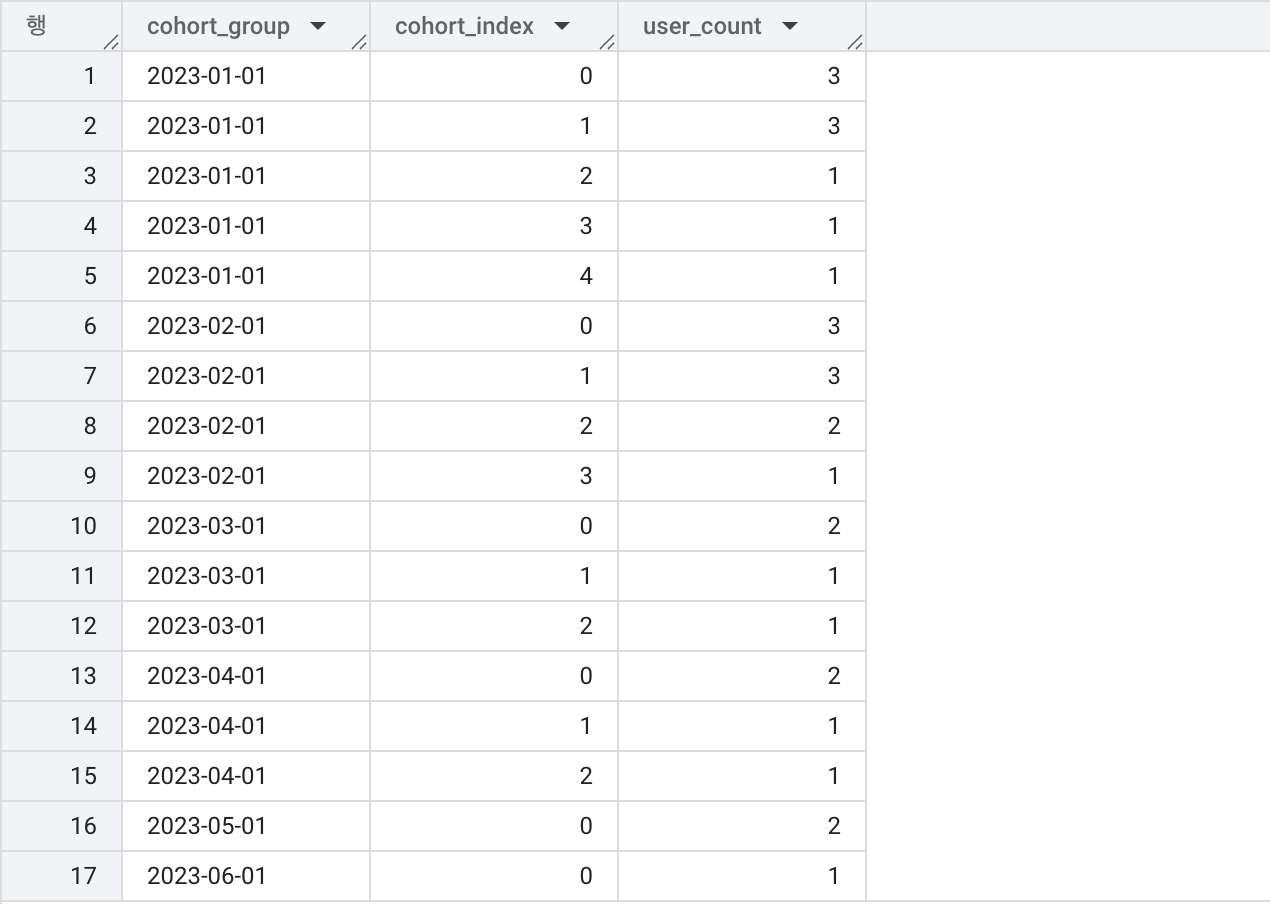
SELECT
cohort_group,
cohort_index,
COUNT(DISTINCT user_id) AS user_count
FROM retention_with_cohort
GROUP BY cohort_group, cohort_index
ORDER BY cohort_group, cohort_index;
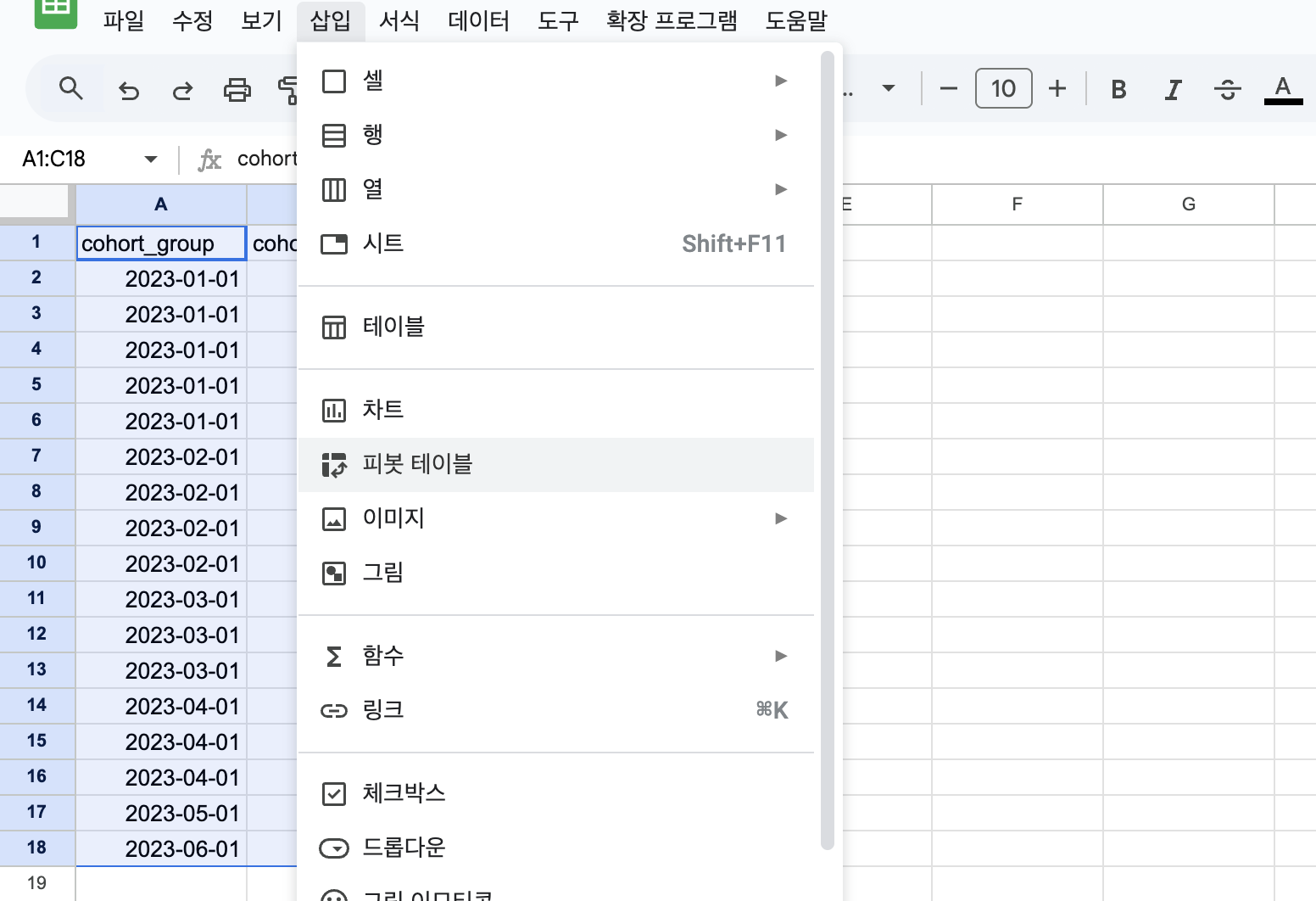
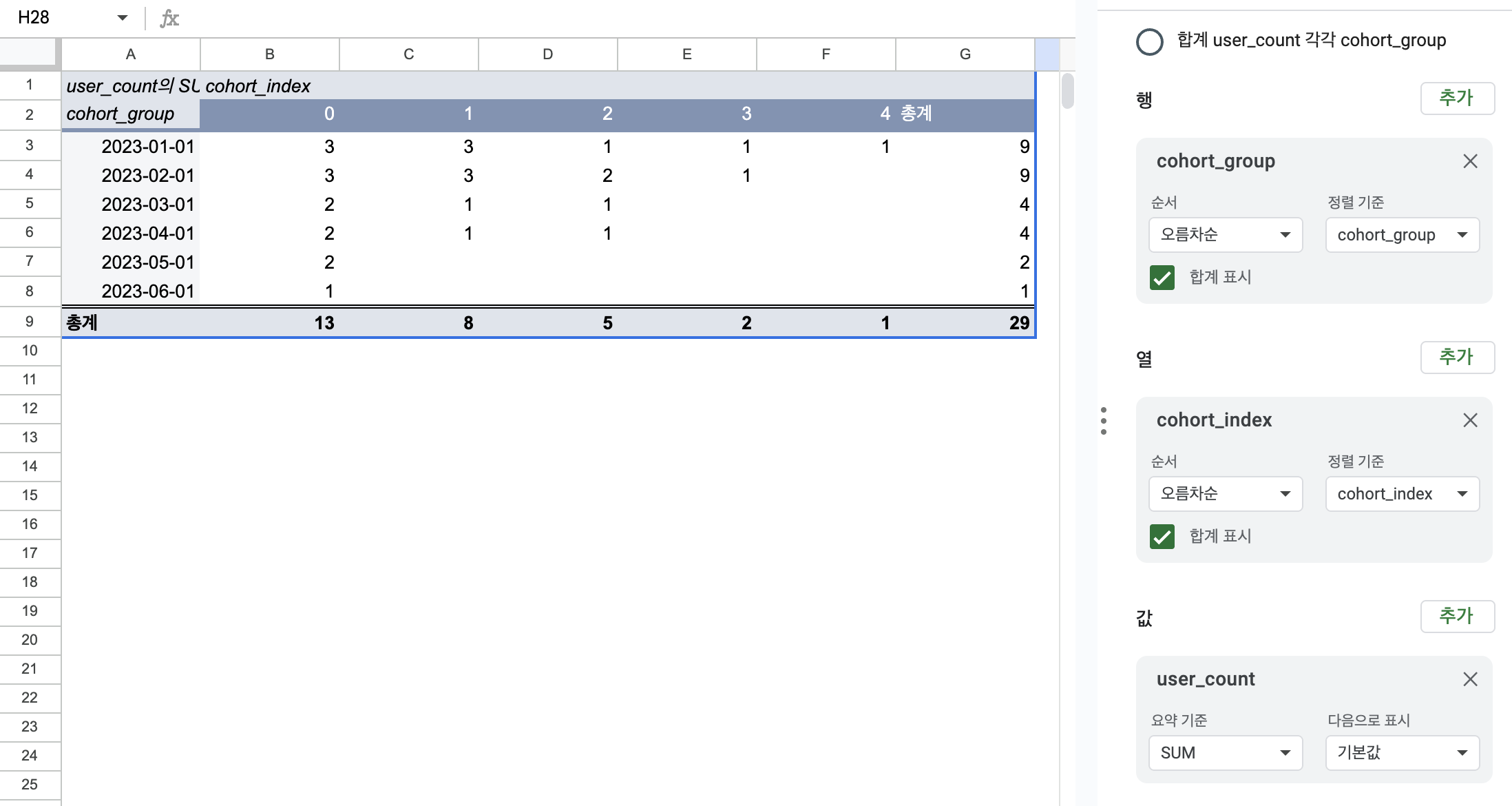
Google Sheets에서 리텐션 시각화
위 결과를 BigQuery에서 CSV(Google Drive)로 저장한 뒤 Google 스프레드시트에 업로드하면,
아래와 같이 피봇 테이블을 구성하여 리텐션 분석을 시각화할 수 있다.
- 행 →
cohort_group - 열 →
cohort_index - 값 →
user_count
Tip) 첫 번째 월을 기준으로 나머지 값을 퍼센트로 변환하면 리텐션 비율을 쉽게 확인할 수 있다.
지금까지 같은 시점에 유입된 사용자 집단의 유지율 추적하기 위해, Cohort 기반으로 월별 리텐션을 분석해 보았다.
리텐션 분석으로 아래와 같은 인사이트를 도출해 볼 수 있었다.
💡 사용자 이탈이 많은 시점을 찾아 무엇이 원인인지 파악해야 한다.
💡 특정 마케팅 캠페인 이후 리텐션이 낮다면, 품질 대신 유입에만 집중한 것일 수 있다.
💡 반대로 리텐션이 높다면, 고객이 만족하고 반복해서 구매하고 있다는 긍정적인 신호이다.
