🖇 데이터와 데이터베이스
🖇 테이블
🖇 스키마와 데이터 타입
데이터는 단순한 숫자나 문자들의 나열일 수 있지만
우리가 그것을 해석하고 의미를 부여하는 순간 데이터는 의미있는 정보로 발전한다.
데이터를 통해 고객의 행동을 분석하고,
도시의 흐름을 예측하며,
심지어는 질병의 가능성까지 예측하는 시대에 살고 있다.
그렇기에 데이터는 더 이상 보조적인 자원이 아닌 핵심 자산이 되었고
이 데이터를 어떻게 저장하고 관리하며 활용할 것인가가 무엇보다 중요해졌다.
데이터를 의미 있는 정보로 발전시켜 현명한 의사결정을 통해 가치 창출을 해내고 싶다는 목표를 가지고
이 글에서는 데이터의 저장소인 데이터베이스와, 이를 다루는 언어인 SQL의 기초 개념을 정리해 보았다.
🖇 데이터와 데이터베이스
데이터
데이터(Data)는 모든 기록들이다.
과거에 비해 데이터의 양과 복잡성이 증대됨에 따라
또 데이터가 단순한 기록이 아닌 비즈니스 자산이 되면서
데이터를 전문적으로 봐야하는 직군들 또한 증가되었다.
그렇다면 데이터베이스는 이런 데이터를 어떻게 다루는 것일까?
데이터베이스
데이터베이스(DB; DataBase)는 데이터가 모여져 있는 공간이며, 구조적인 방식으로 관리되는 데이터들의 집합을 말한다.
데이터를 저장하는 단순한 공간을 넘어서,
정형화된 구조로 데이터를 효율적이고 체계적으로 관리할 수 있도록 만들어진 시스템이다.
- 데이터를 목적에 맞게 저장하고, 권한에 따라 다르게 접근
- 불필요한 중복을 줄이고, 구조화된 자료를 통해 효율적인 처리 가능
데이터베이스의 특징
✓ 실시간 접근성
사용자의 질의에 대하여 즉시 처리하고 응답할 수 있다.✓ 지속적인 변화
새로운 데이터의 삽입, 삭제, 갱신으로 항상 최신의 데이터를 유지한다.
한 시점에서 데이터베이스가 저장하고 있는 내용은 그 당시의 상태를 뜻한다.✓ 동시 공유
다수의 사용자가 동시에 같은 내용의 데이터를 사용할 수 있다.✓ 내용에 대한 참조
데이터베이스에 있는 데이터를 참조할 때 데이터 행의 주소나 위치가 아니라, 사용자가 요구하는 데이터 내용으로 데이터를 찾을 수 있다.
데이터베이스는 이렇게 중복된 데이터를 없애고, 자료를 구조화하여, 효율적인 처리를 할 수 있도록 관리해야 한다.
이렇게 데이터베이스에서 정보를 저장하고, 조회하고, 수정하고, 삭제할 수 있도록 설계된 언어가 있는데
이것이 SQL 이다.
SQL(Structured Query Language)은 데이터베이스와 대화할 수 있는 언어로,
데이터를 조회(SELECT), 추가(INSERT), 수정(UPDATE), 삭제(DELETE)할 수 있도록 도와준다.
관계형 데이터베이스
관계형 데이터베이스 RDB(Relational Database)
: 데이터를 2차원 테이블(행과 열) 구조로 저장하고,
: 이 테이블들을 서로 연결(관계) 지어 구성하는 데이터베이스 모델
가장 널리 사용되는 데이터베이스로
MySQL, Oracle, DB2, SQL Server 등이 RDB에 속한다.
- 테이블(table)을 기본 단위로 사용하며, 모든 데이터는 테이블에 저장된다.
- 구조화된 데이터는 SQL을 통해 조회 가능하다.
- 일관성이 있고, 안정적이며 신뢰성이 있다.
| 장점 | 단점 |
|---|---|
| 업무 변화에 신속히 대응 가능하며, 유지보수가 용이하다 (유연한 구조) | 비정형 데이터 처리에 불리하고, 시스템 자원을 많이 소모한다 |
| 대용량 데이터를 체계적이고 구조적으로 관리 가능 | 테이블 간 JOIN이 많을 경우 성능 저하가 발생할 수 있다 |
| 데이터 무결성 보장 | 복잡한 초기 설계 및 정규화 과정이 필요하다 |
| SQL 기반으로 강력하고 표준화된 질의(Query) 처리 가능 | 데이터 구조가 엄격하여 유연한 데이터 모델링에 제약 발생할 수 있다 |
| 트랜잭션 관리가 강력함 (ACID 원칙) |
💡 여기서 ACID 원칙이란?
관계형 DB는 아래의 트랜잭션 성질을 따른다.
Atomicity(원자성)
: 트랜잭션의 연산은 데이터베이스에 모두 반영되도록 완료(Commit)되든지 아니면 전혀 반영되지 않도록 복구(Rollback)되어야 한다.
Consistency(일관성)
: 트랜잭션이 그 실행을 성공적으로 완료하면 언제나 일관성 있는 데이터베이스 상태로 변환한다.
Isolation(고립성)
: 둘 이상의 트랜잭션이 동시에 병행 실행되는 경우 어느 하나의 트랜잭션 실행 중에 다른 트랜잭션의 연산이 끼어들 수 없다.
Durability(지속성)
: 성공적으로 완료된 트랜잭션의 결과는 시스템이 고장나더라도 영구적으로 반영되어야 한다.따라서 신뢰성 높은 트랜잭션 관리가 가능하다.
🖇 테이블
테이블이란?
데이터를 저장하는 가장 기본적인 단위로,
관계형 데이터베이스(RDB)에서는 모든 데이터가 2차원 표(행과 열)의 형태로 테이블에 저장된다.
- 행/열의 형태로 구성 및 관리할 수 있다.
- 스키마가 정의되어 있고,
- Key를 지정함으로써 원하는 데이터를 빠르고 쉽게 찾아낼 수 있다.
엑셀 시트를 떠올리면 이해가 쉬울 것이다.
하나의 테이블은 엑셀 파일의 한 시트처럼 동작하며
각 행이 한 개의 데이터(레코드), 각 열이 속성(필드)을 나타낸다.
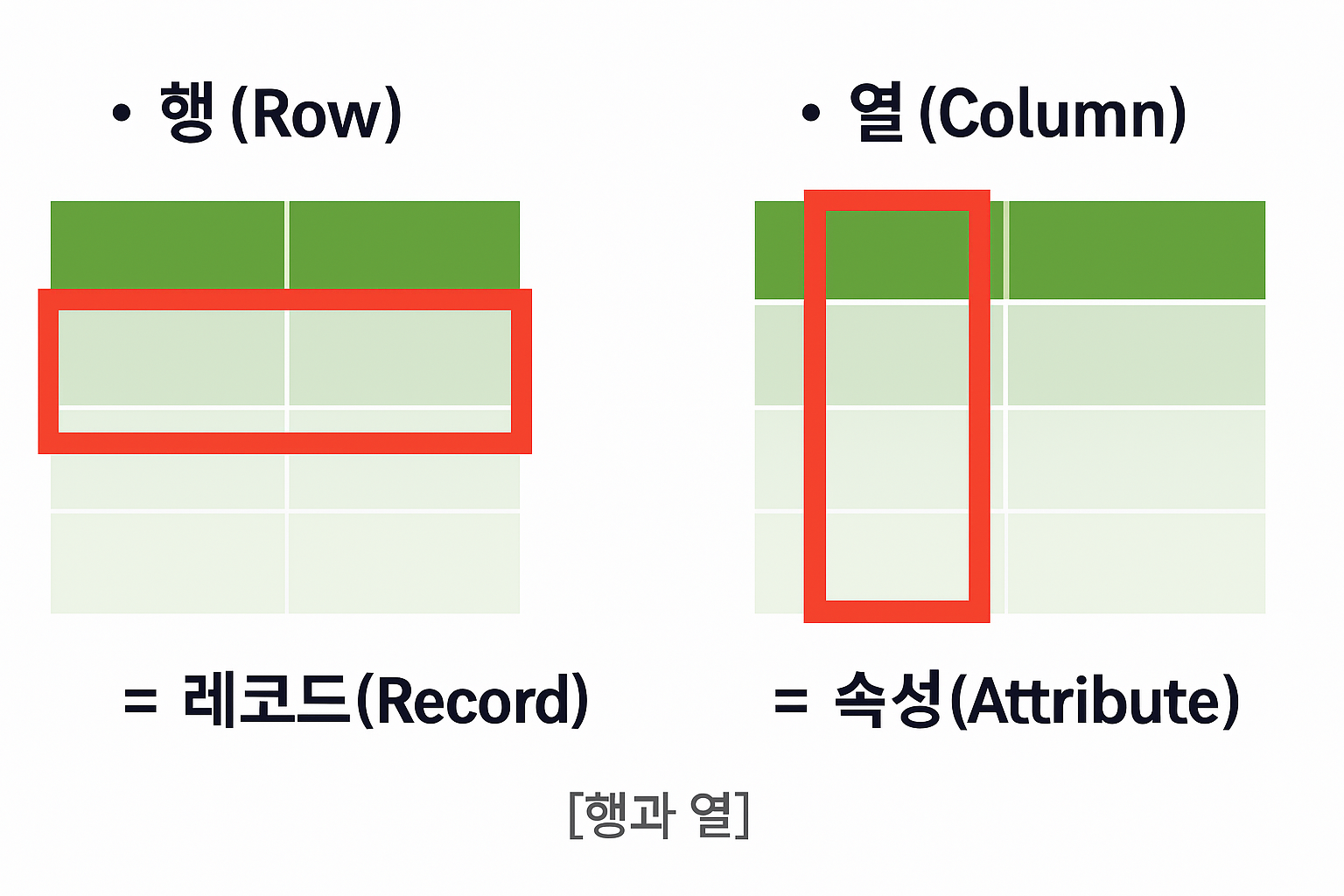
테이블의 구성 요소
-
행(Row): 하나의 레코드
-
열(Column): 해당 레코드가 가진 속성
아래의 테이블에서 살펴보자.
id name email signup_date 1 김철수 cs.kim@email.com 2023-02-01 2 박영희 yh.park@email.com 2023-03-12 → 행(Row)은 각각의 사용자 정보 하나하나
→ 열(Column)은 id, name, email, signup_date 등의 속성
(아래는 생성형 AI에게 만들어 달라고 부탁한 이미지인데, 빨간 박스가 행과 열을 완전히 잡아주지 못했다. 참고하기 바란다.)
(그래도 한글을 반듯하게 뽑아내줘서 만족한다 ㅎㅎ)
🖇 스키미와 데이터 타입
스키마
테이블의 뼈대를 구성하는 것으로, 테이블에 대한 정보가 들어있다.
데이터베이스에서 스키마는
관계형 데이터베이스 내에서 데이터가 구성되는 방식을 정의한다.
즉, 실제 데이터가 들어있는 건 아니고
데이터가 어떤 구조로 들어올지를 미리 약속해두는 틀이라고 이해하면 된다.
- 테이블에 어떤 컬럼이 존재하고, 어떤 데이터 타입을 가지고, 어떤 제약이 있는지를 명세한 것
- 테이블을 정의할 때 컬럼별로 저장할 수 있는 타입까지 명시해 주어야 한다.
💡 관계형 데이터베이스에서 스키마는 왜 중요할까?
데이터 무결성 유지
→ 잘못된 데이터 입력을 사전에 막을 수 있다.SQL 쿼리 작성이 쉬워진다
→ 어떤 컬럼이 있는지 명확하니 정확한 쿼리 작성 가능테이블 간 관계 정의 가능
→ 스키마를 통해 외래 키(FK) 등으로 테이블을 연결할 수 있다.협업에 유리하다
→ 여러 개발자가 같은 구조를 공유하니 일관성 유지 가능
데이터 타입
데이터 타입은
각 컬럼이 어떤 종류의 데이터를 저장할 수 있는지 정의하는 것이다.
데이터베이스 테이블에는 특정 데이터 유형이 있는 여러 열이 포함되어 있는데, 이 데이터들을 프로그래밍 관점에서 식별하기 위한 분류이다.
-
문자열, 숫자, 날짜 등의 속성이 있다.
-
데이터 타입에 따라 사용하는 SQL 구문이 다르다.
주요 데이터 타입 분류
분류 타입 예시 설명 숫자형 INT,FLOAT,DECIMAL정수, 실수 등 숫자 관련 값 문자형 CHAR,VARCHAR,TEXT고정/가변 길이의 문자열 날짜/시간 DATE,TIME,DATETIME,TIMESTAMP날짜 및 시간 정보 논리형 BOOLEAN참/거짓 (True/False) 컬럼마다 알맞은 데이터 타입을 지정하면
데이터 무결성을 지키고, 성능도 최적화할 수 있다.
