🖇 시계열 데이터 EDA
🖇 ACF와 PACF
🖇 ACF와 PACF 적용
🖇 비정상적 데이터에서 ACF와 PACF
🖇 허위 상관 주의하기
시계열 분석에서 첫 단계는 데이터가 어떤 구조를 갖고 있는지를 파악하는 것이다.
시계열 데이터에서는 패턴의 반복성이나 시차에 따른 자기의존성을 정확히 확인하는 것이 중요하다. 자기상관 함수(ACF, Autocorrelation Function)와 부분 자기상관 함수(PACF, Partial Autocorrelation Function)를 활용해 이를 확인할 수 있다.
이 글에서는 시계열 데이터 EDA 과정에서 ACF와 PACF가 어떤 의미를 가지며, 실제로 어떻게 해석해야 하는지를 사인 함수 예제를 통해 정리해 보았다.
🖇 시계열 데이터 EDA
시계열 데이터를 분석하기 전에는 반드시 데이터를 충분히 탐색(EDA: Exploratory Data Analysis)해야 한다. 시계열 데이터는 관측값 간에 시간 의존성이 존재하며, 일반적인 정형 데이터와는 다른 구조적 특성을 갖기 때문이다.
값이 증가하는 원인은 단순한 시간의 흐름 때문인지, 실제로 과거 값이 미래에 영향을 주는지, 혹은 계절성과 같은 반복 패턴이 있는지를 먼저 파악해야 이후 분석이 가능하다.
시계열 EDA에서는 아래의 질문을 고려해야 한다.
- 데이터에 추세(trend)나 계절성(seasonality)이 존재하는가?
- 특정 주기나 자기상관 구조(autocorrelation)는 얼마나 강한가?
- 시계열이 정상성(stationarity)을 만족하는가?
이러한 구조적 특성을 빠르게 파악하는 데 ACF와 PACF는 매우 유용하게 작용하며 이후 ARIMA 모델링이나 이상 탐지 등의 기반이 된다.
사인함수와 선형 시계열을 예로 들어 ACF, PACF가 어떤 정보를 제공하는지 시각화하여 확인해 보자.
🖇 ACF와 PACF
ACF (Autocorrelation Function)
▼ (왼쪽)사인함수와 (오른쪽)사인함수의 ACF Plot
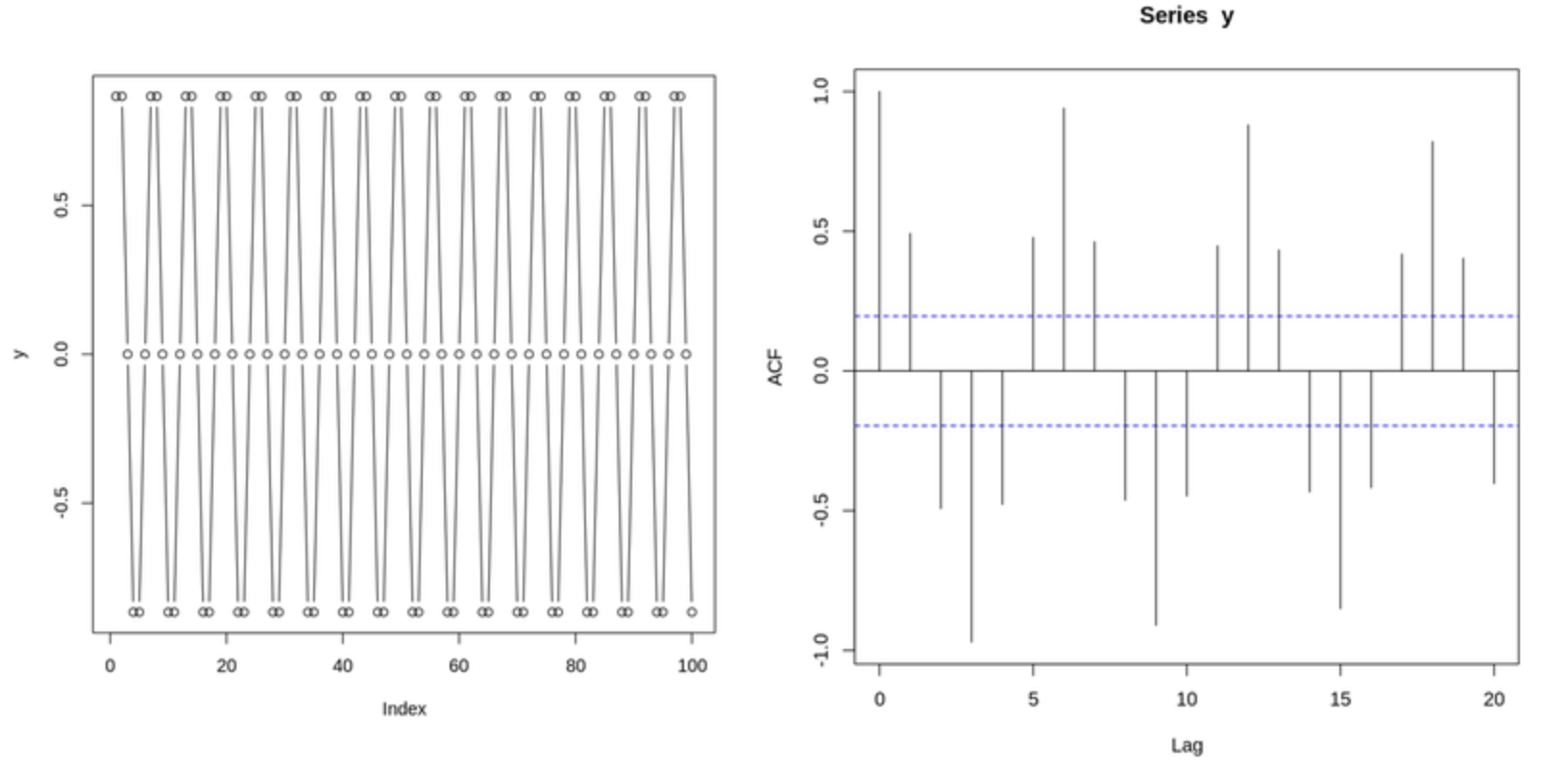
ACF는 시계열 내에서의 시간 간격(lag)별 자기상관 정도를 나타낸다.
(자기 상관: 시계열 데이터에서 일정 간격이 있는 값들 사이의 상관관계)
시계열 데이터가 과거의 자기 자신과 얼마나 닮아 있는지를 수치로 계산해주는 함수라고 생각하면 이해하기 쉽다.
- x축: 시차 (lag)
- y축: 해당 시차에서의 상관계수
- 파란 점선: 임계값 (95% 신뢰구간)
💡 시차가 0일 때 자기상관은 항상 1이며 이후 시차가 커질수록 상관관계가 어떻게 변화하는지를 보여준다.
💡 시계열이 자기상관이 없을 경우, 대부분의 lag 값이 암계값 범위 안에 존재해야 하며 이 범위 안의 값은 통계적으로 유의하지 않다.
PACF (Partial Autocorrelation Function)
▼ (왼쪽)사인함수와 (오른쪽)사인함수의 PACF Plot
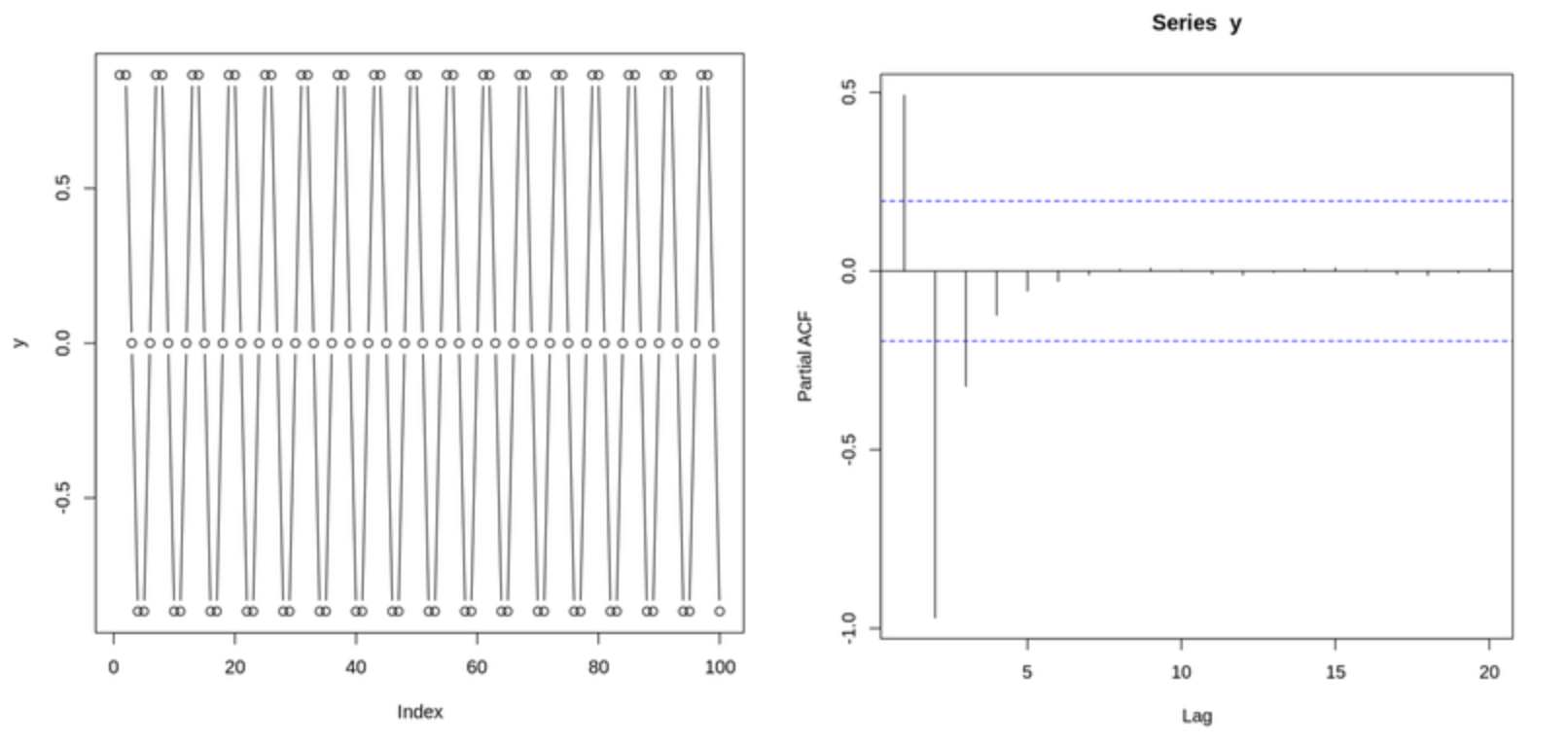
PACF는 시차가 있는 두 시점 간의 직접적인 상관관계만을 보여준다.
(부분 자기상관 = 편자기상관: 자신에 대한 그 시차의 편상관)
두 시점 사이의 전체 상관관계에서 그 사이 다른 시점의 조건부 상관관계를 제거하고 나서 남는 순수한 상관관계를 나타낸다.
💡 ACF는 전체적인 상관관계를 포함하기 때문에 중복 정보가 많다.
💡 PACF는 각 lag 간의 독립적인 관계만 남기 때문에 모델 차수 파악(AR 차수 결정 등)에 자주 사용된다.
🖇 ACF와 PACF 적용
사인 함수 시계열에 ACF와 PACF를 적용해서 ~를 시각적으로 확인해 보자.
라이브러리 불러오기
# statsmodels
# : 통계 모델 추정, 통계 결과, 통계 데이터 탐색을 지원하는 python 모듈
import numpy as np
import matplotlib.pyplot as plt
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
데이터 생성 및 시각화
x = np.array(range(100)) # 0~99까지 생성
y = np.sin(x + np.pi/3) # 사인 함수 값 도출
plt.plot(y)
plt.title("Sine Wave Time Series")
plt.show()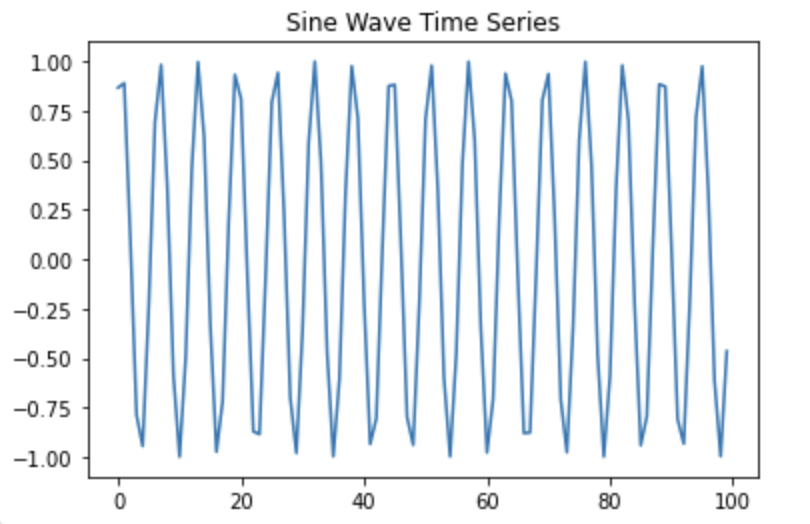
- 위 그래프는 완벽하게 주기적인 시계열 데이터인 사인 함수다.
- 평균이 0 근처이고, 진폭도 일정하다.
이와 같은 데이터는 정상성(stationarity)을 만족하는 전형적인 예시로, ACF와 PACF를 적용하기에 적합하다.
ACF 시각화
plot_acf(y)
plt.show()
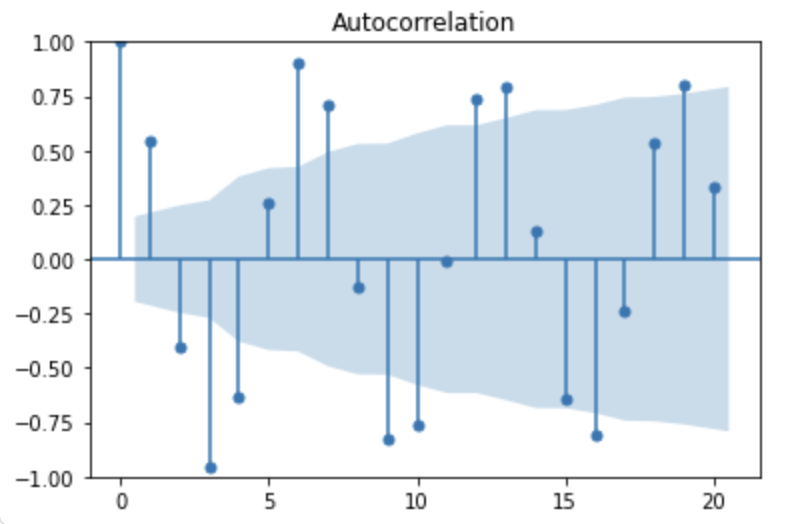
- 뚜렷한 주기성이 보인다.
- 특정 간격(lag)마다 높게 튀는 막대들이 반복적으로 나타난다.
이는 사인 함수의 주기적 구조가 lag 간 반복되며 자기상관이 강하게 유지되고 있음을 보여준다.
PACF 시각화
plot_pacf(y)
plt.show()
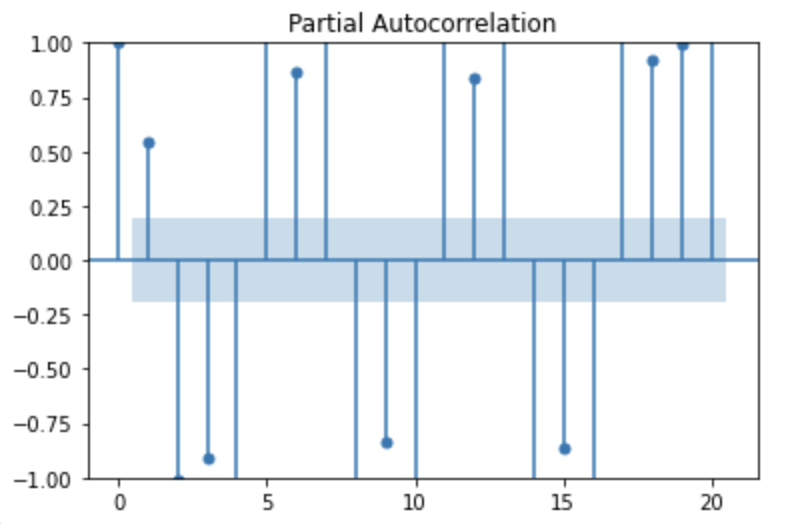
ACF와 비교하면 보다 정제된 상관구조를 확인할 수 있다.
이는 PACF가 각 lag에 대해 중복 정보를 제거하고 직접적인 관계만 보여주기 때문이다.
🖇 비정상적 데이터에서 ACF와 PACF
▼ 1부터 100까지 선형적으로 증가하는 데이터의 ACF plot과 PACF plot
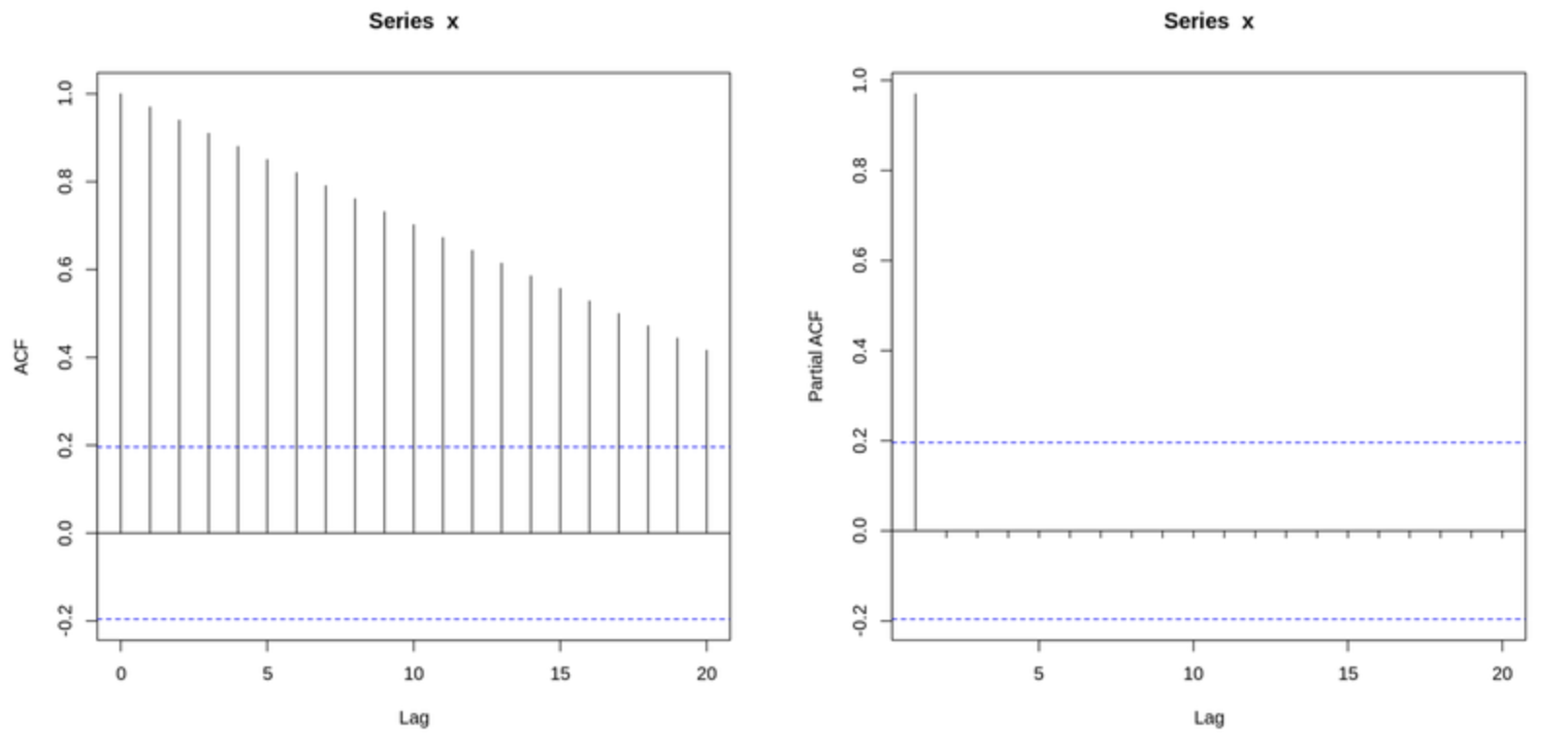
값들은 단순히 균등하게 증가하는 것이기 때문에, ACF와 PACF로부터도 크게 유의미한 정보를 얻을 수 없다.
선형 증가 시계열에 ACF와 PACF를 적용해서 ~를 시각적으로 확인해 보자.
선형 증가 시계열
x_linear = np.arange(1, 101)
plt.plot(x_linear)
plt.title("Linear Increasing Series")
plt.show()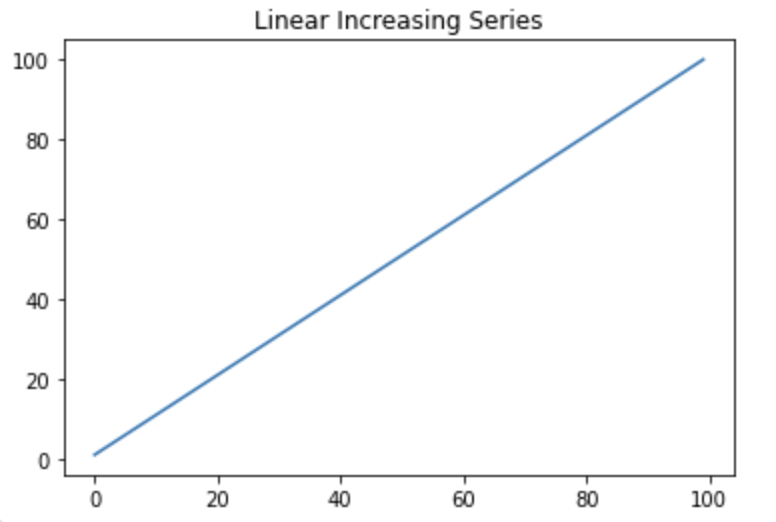
ACF와 PACF
plot_acf(x_linear)
plt.show()
plot_pacf(x_linear)
plt.show()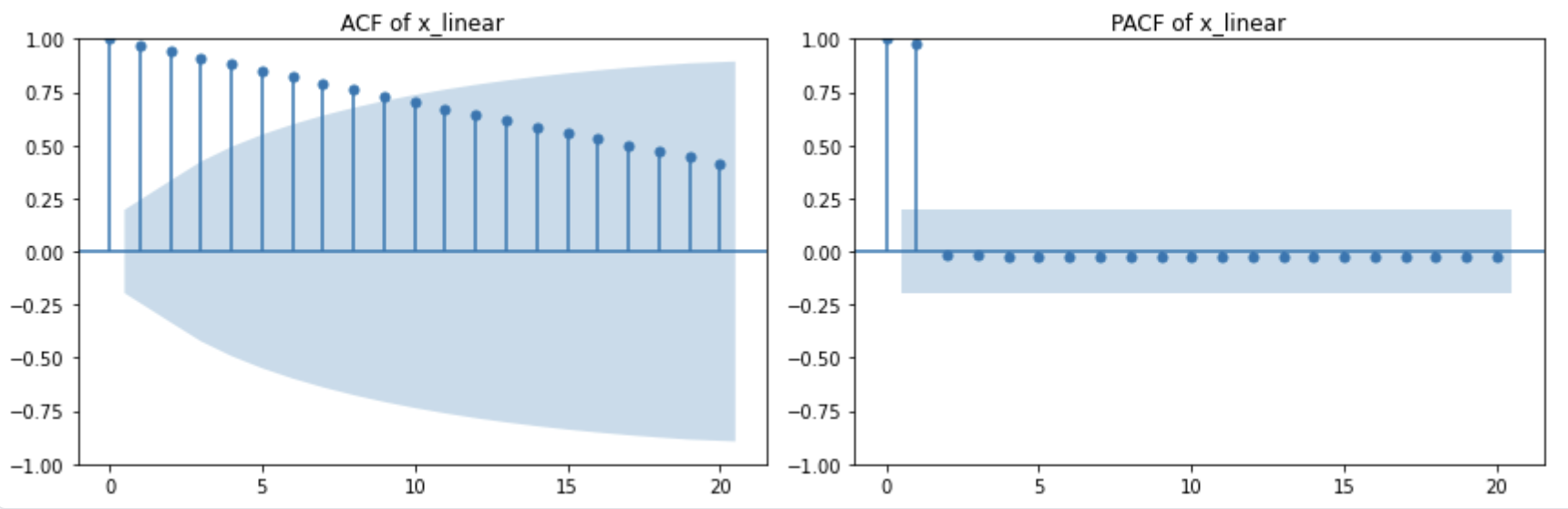
- ACF와 PACF 모두에서 패턴이 없는, 쓸모 없는 상관 구조만 남는다.
- 이는 선형적으로 증가하는 데이터가 비정상 시계열이며, 자기상관이 구조적으로 왜곡되어 있다는 것을 뜻한다.
이처럼 비정상성(non-stationarity)을 가진 데이터에서는 ACF, PACF가 신뢰할 수 있는 통계 정보를 제공하지 못한다.
🖇 허위 상관 주의하기
시계열 EDA에서 체크해야할 가장 중요한 위험은 허위 상관(spurious correlation)이다.
허위 상관은 두 개 이상의 변수가 통계적 상관은 있지만 인과관계가 없는 관계를 말한다. 두 시계열 간에 통계적으로 높은 상관이 있는 것처럼 보이지만, 실제로는 공통된 시간 추세만 존재하고 인과관계는 없는 경우다.
- 예를 들어, 선형 증가하는 두 지표의 ACF가 매우 높게 나오더라도 이는 실제 연관성이 아니라 동일한 추세(Trend)에 기인한 것일 수 있다.
- 이를 해결하기 위해서는 시계열을 정상화(differencing, detrending)한 뒤 ACF/PACF를 확인해야 한다.
흔히 말하는 상관관계는 인과관계가 아니다 라는 것이 적용되는 사례라고 볼 수 있다.
인사이트 및 회고
지금까지 시계열 데이터를 해석하고 모델링 구조를 설계하는 데 있어 ACF와 PACF가 가지는 의미를 살펴보고, 간단한 시계열 데이터 예제에 적용 후 해석해 보았다.
중요한 건, 그 해석이 유의미하려면 데이터가 정상성(stationarity)을 만족하는지 먼저 확인해야 한다는 것이다. 또한 주기성 또는 추세성에 따라 달리 해석되어야 한다는 점도 유의해야 한다.
예제로 살펴본 사인 함수와 선형 증가 시계열은 각각 정상적인 주기 시계열과 비정상적인 추세 시계열을 대표하는 예시로, 두 경우에서 ACF와 PACF가 얼마나 다르게 나타나는지를 비교해볼 수 있었다.
시계열 데이터가 일반적인 정형 데이터와 구조적으로 다른 특징을 갖는 다는 것에 유의하며 분석해야겠다.
