🖇 시계열 분해란?
🖇 시계열 분해 해석
🖇 시계열 분해가 필요한 이유
많은 경우 시계열 데이터에는 추세(Trend), 계절성(Seasonality), 불규칙성(Random/Noise)과 같은 구조적 성분이 함께 포함되어 있다. 이러한 구조를 이해하고 분해하는 과정은 예측 모델링, 정상성 확보, 이상 탐지의 기반이 되기 때문에 올바르게 해석하는 것이 중요하다.
이번 글에서는 시계열 데이터를 곱셈적 구조(Multiplicative Model)로 분해한 예시를 통해 각 구성 요소가 의미하는 바와 해석 방법에 대해 다뤄보았다.
특히 변동성이 커지는 시계열에서 어떻게 추세, 계절성, 불규칙 성분을 나눠서 이해할 수 있는지를 중심으로 정리해 보았다.
🖇 시계열 분해란?
시계열 분해는 하나의 시계열 데이터를 세 가지 성분(Trend, Seasonality, Random)으로 나누는 과정이다.
이때 사용하는 분해 모델은 크게 두 가지 유형으로 나뉜다:
-
Additive Model (가법 모델)
Y = T + S + R→ 모든 성분이 선형적으로 더해져 구성됨
→ 일반적으로 변동폭이 일정할 때 적합
-
Multiplicative Model (곱셈 모형)
Y = T × S × R→ 추세가 커질수록 계절성이나 노이즈의 절대 폭도 함께 커짐
→ 즉, 변동성의 비율이 일정할 때 적합
아래의 예시는 곱셈적 분해(Multiplicative Decomposition)에 해당하며, 비선형적 성장 시계열을 다룰 때 자주 사용된다.
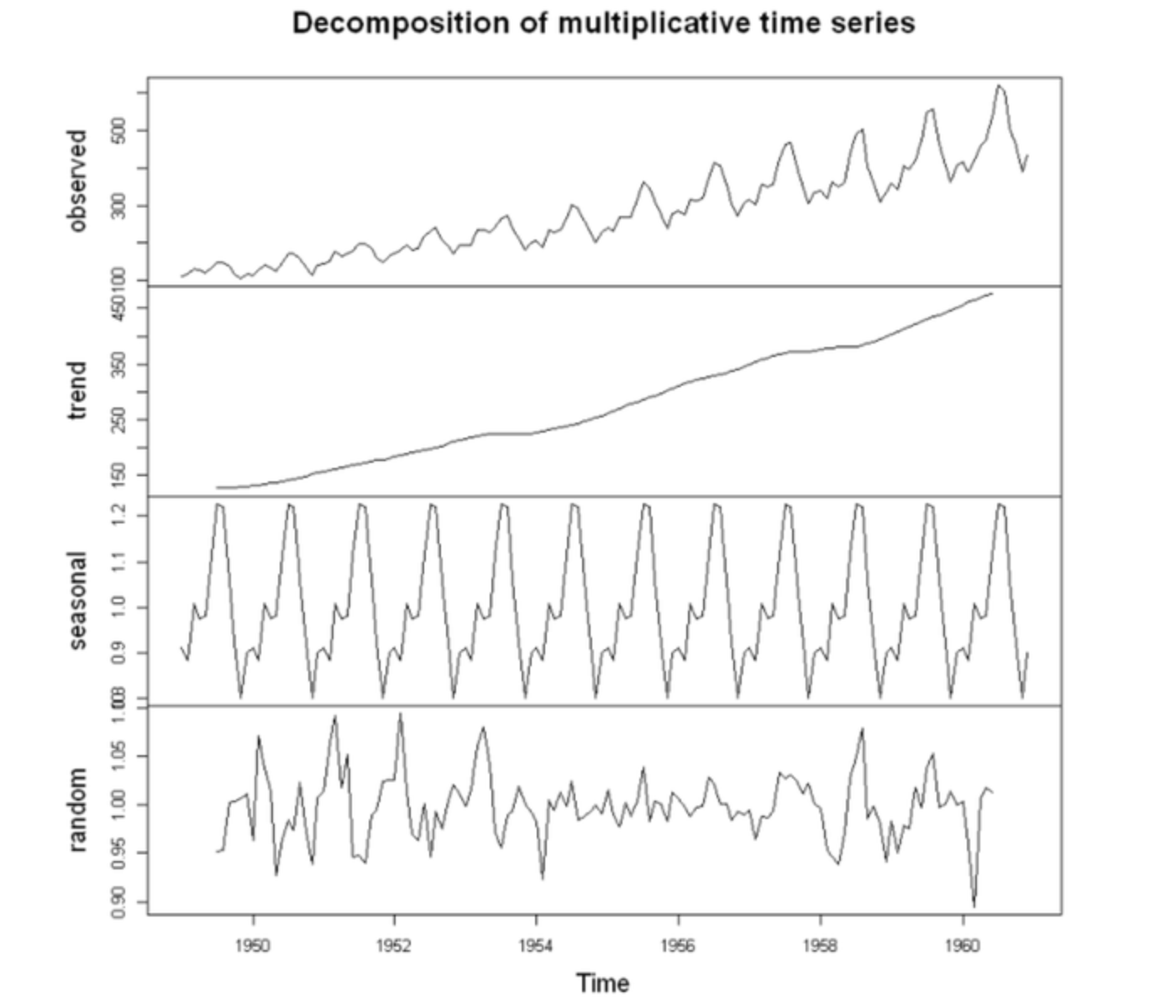
Observed = Trend × Seasonal × Random
(곱셈적 모형, Multiplicative Decomposition)
🖇 시계열 분해 해석
아래와 같은 특징을 통해 Multiplicative Decomposition이 적합한 시계열임을 판단할 수 있다.
- 시간이 지남에 따라 전반적인 값의 크기가 증가하거나 감소
- 값이 커질수록 변동성도 함께 커지는 구조
- 특정 주기마다 반복되는 패턴이 존재
이러한 경우에는 단순 평균이나 선형 회귀로는 구조를 제대로 설명할 수 없기 때문에 분해 후 구성 요소별 해석이 중요하다.
✓ Observed – 원시 시계열 데이터

시계열 분해의 시작은 관측된 원래 데이터(Observed, raw data)다.
아직 아무런 처리를 거치지 않은 시계열이다. 전체적인 추세, 반복 패턴, 그리고 무작위 변동이 모두 함께 포함되어 있다.
✓ Trend – 추세 성분
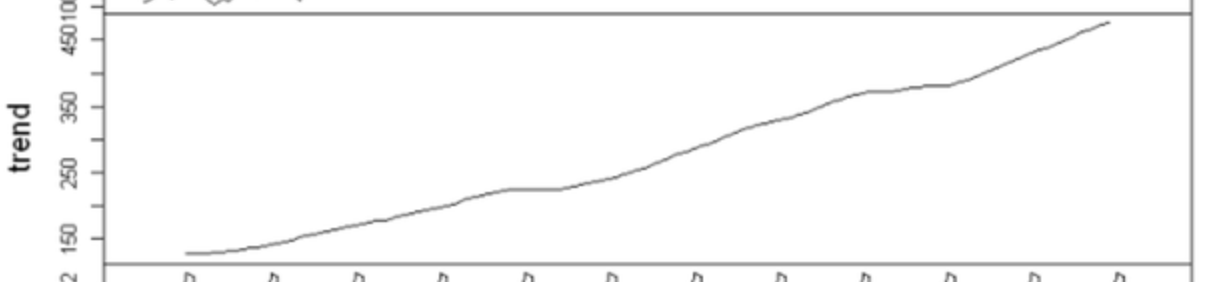
추세(Trend)는 시계열 데이터가 장기적으로 증가하거나 감소하는 경향성을 의미한다. 시간이 지남에 따라 데이터가 점진적으로 증가하거나 감소하는 패턴을 말하며, 시계열의 기반 흐름이라고 볼 수 있다.
분해된 추세 그래프를 보면 아래의 특징을 확인할 수 있다.
- 계절성과 노이즈가 제거되어 부드럽게 연결된 선 형태
- 상승 혹은 하강하는 장기 흐름이 명확히 보임
- 예측 모델링에서 기초선 또는 기준선 역할을 수행
예시 그래프에서는 약 1950년부터 1960년까지의 지속적인 상승 추세가 뚜렷하게 나타난다. 이는 시간 흐름에 따라 축적되는 데이터에서 자주 보이는 구조다.
✓ Seasonal – 계절 성분
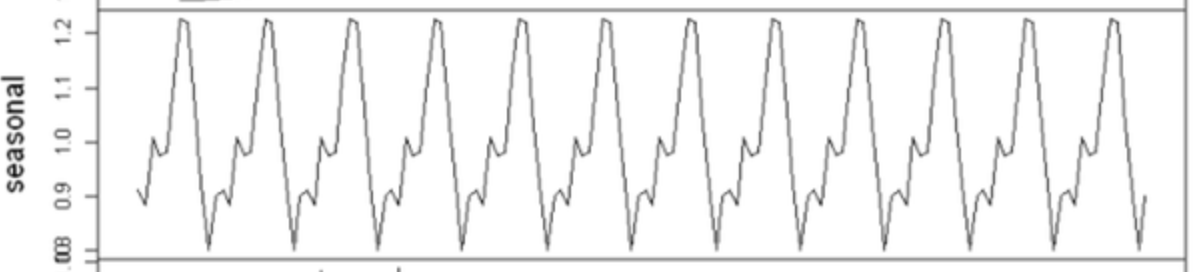
계절성(Seasonality)은 일정한 주기를 가지고 반복되는 패턴이다.
이 성분은 주로 내부 요인 또는 반복적인 외부 요인에 의해 발생한다. 분해 과정에서는 Trend와 Random 성분을 제거한 후 순수한 반복 구조만을 시각화한다.
- 일반적으로 연간, 월간, 주간, 일간 주기를 가진다.
- 비즈니스에서는 휴일, 세일 시즌, 시간대별 고객 행동 등과 관련된다.
- 이 성분은 예측 정확도에 큰 영향을 주며, 예측 모델에 반드시 반영되어야 한다.
예시에서는 12개월마다 반복되는 패턴이 나타나므로 이 시계열은 연간 반복되는 계절성을 가진다고 볼 수 있다. 각 해의 패턴이 유사하게 반복된다는 점은 이 시계열이 규칙적인 예측 가능성을 갖고 있음을 보여준다.
✓ Random – 잔차 성분(오차)
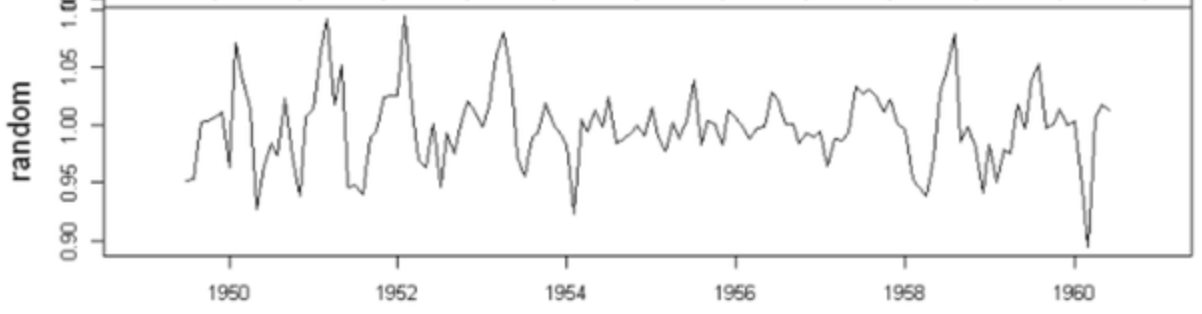
잔차(Random 또는 Residual)는 앞서 분리한 추세와 계절성을 제거하고도 남는 설명되지 않는 성분이다.
즉, 모델이 포착하지 못한 불규칙한 움직임, 예외적 사건, 센서 오류 등이 여기에 포함된다.
- 이상적인 경우에는 랜덤하게 흩어진 상태를 보여야 한다.
- 평균을 중심으로 편향되지 않고 고르게 분포되어야 한다.
- 특정 주기나 방향성이 나타날 경우, 모델이 구조를 완전히 포착하지 못했다는 의미로 해석된다.
예시에서는 잔차가 특정 구간에서 뚜렷한 이상값 없이 전반적으로 안정적으로 분포하고 있어, 분해된 모델이 시계열의 구조를 비교적 잘 설명하고 있음을 보여준다.
🖇 시계열 분해가 필요한 이유
시계열 데이터를 분석할 때는 그 안에 포함된 구조적인 성분들을 먼저 분해해 보는 것이 중요하다. 이를 통해 데이터가 어떤 패턴으로 구성되어 있는지를 명확히 파악할 수 있고, 이후의 모델링이나 해석 과정에서도 큰 도움이 된다.
예를 들어 ARIMA, Prophet과 같은 대표적인 시계열 예측 모델들은 추세(Trend), 계절성(Seasonality), 잔차(Residual)처럼 구조적으로 분리된 성분들을 기반으로 작동하기 때문에 사전에 이러한 성분을 분해해두면 더 정밀하고 효과적인 예측이 가능하다.
또한, 추세를 제거함으로써 비정상적인 시계열을 정상성(stationarity)을 가진 시계열로 변환할 수 있다. 대부분의 통계 기반 시계열 모델이 요구하는 전제 조건을 만족시키는 데 유리하다. 마케팅이나 정책 효과를 분석할 때는 고정된 계절 패턴의 영향을 제거하여 더 명확한 수요 변동을 파악할 수 있는 것을 생각해 보면 이해하기 쉽다.
마지막으로, 분해된 잔차 성분을 활용하면 추세나 계절성과 무관한 갑작스러운 이상값(anomaly)을 탐지할 수 있다. 이를 통해 실시간 모니터링이나 품질 관리 측면에서도 유용하게 사용할 수 있다.
인사이트 및 회고
시계열 데이터를 제대로 이해하려면 내부에 어떤 구조적 흐름이 있는지를 분해해 살펴보는 것이 필요하다. Trend, Seasonality, Random의 세 가지 성분을 잘 구분하고 해석하면 데이터의 본질을 더 정확히 이해할 수 있게 된다.
이렇게 시계열을 분해해서 보는 것이 왜 필요하고, 이를 어떻게 해석할 수 있는지 방향을 잡을 수 있었다. 변동성이 함께 커지는 데이터에서는 곱셈적 모델을 적용해 분해하는 것이 적절하는 것도 이해할 수 있었다.
이것들도 결국 예측 모델링이나 비즈니스 의사결정에서 신뢰도 높은 결과를 도출하기 위해 중요한 것이다.
