Retention: 코호트 기반 사용자 유지율 시각화
서비스의 성공을 논할 때 단순히 사용자 수만으로 판단하는 것은 부족하다. 사용자들이 처음 방문한 뒤 다시 우리 서비스를 사용하는지를 확인하는 것이 훨씬 더 중요하다.
이때 사용하는 대표적인 분석 방법이 Retention 분석이며, 이를 구체화한 것이 코호트(Cohort) 분석이다.
코호트 분석을 통해 시기별 사용자군의 리텐션 패턴을 파악하고, 이탈 시점을 예측하거나 유지 전략을 설계할 수 있다. 리텐션 곡선은 장기적인 서비스 생존력을 보여준다고 할 수 있다.
Retention이란?
Retention은 일정 기간 동안 서비스를 재방문하거나 다시 사용하는 사용자 비율을 의미한다. 이는 제품이 사용자에게 가치를 제공하고 있는지를 가늠하는 핵심 지표 중 하나다.
💡 Day N Retention
: Day 0에 유입된 사용자가 Day N에도 활동을 유지하는 비율💡 Churn Rate(이탈율)
: 반대로, 서비스를 떠난 사용자 비율을 나타낸다
코호트 분석이란?
코호트(Cohort)란 "같은 특성 또는 행동을 공유하는 사용자 집단"을 의미한다.
대표적인 코호트 기준은 가입일, 첫 구매일, 마케팅 유입 경로 등이 있다. 이 글에서는 월별 가입일을 기준으로 분석을 진행한다.
- 코호트 리텐션으로 동일한 가입월(cohort_month) 사용자들이 이후 몇 개월 간 서비스를 얼마나 유지하고 있는지를 시각화한다.
- 리텐션 커브(Retention Curve)로 이러한 패턴을 시각화하여 직관적으로 보여준다.
1. 데이터 불러오기 및 확인
Kaggle에서 전자상거래 사용자 이벤트 데이터를 가져온다.
event_time, event_type, product_id, user_id, user_session 등 주요 필드를 포함한다.
import kagglehub
import os
# kaggle dataset 다운로드
path = kagglehub.dataset_download("mkechinov/ecommerce-events-history-in-electronics-store")
df = pd.read_csv(path + '/' + os.listdir(path)[0])
df.head(3)
| event_time | event_type | product_id | category_id | category_code | brand | price | user_id | user_session |
|-------------------------|------------|------------|----------------------|------------------------------|---------|-------|----------------------|--------------|
| 2020-09-24 11:57:06 UTC | view | 1996170 | 2144415922528452715 | electronics.telephone | NaN | 31.90 | 1515915625519388267 | LJuJVLEjPT |
| 2020-09-24 11:57:26 UTC | view | 139905 | 2144415926932472027 | computers.components.cooler | zalman | 17.16 | 1515915625519380411 | tdicluNnRY |
| 2020-09-24 11:57:27 UTC | view | 215454 | 2144415927158964449 | NaN | NaN | 9.81 | 1515915625513238515 | 4TMArHtXQy |
2. 샘플링 및 날짜 전처리
이벤트가 발생한 월을 기준으로 정규화하고, 사용자별 최초 방문 월(cohort month)을 추출하여 코호트 기준을 마련한다.
# 데이터의 10%만 샘플링
df = df.sample(frac=0.1, random_state=42)
# 날짜형 처리 및 월 단위로 변환
df['current_month'] = pd.to_datetime(df['event_time']).dt.year.map(str) + "-" + pd.to_datetime(df['event_time']).dt.month.map(str) + '-01'
df['current_month'] = pd.to_datetime(df['current_month']).dt.date
# 각 유저의 최초 활동 월을 cohort_month로 설정
df['cohort_month'] = df.groupby('user_id')['current_month'].transform('min')
3. Cohort Index 생성
가입 이후 몇 개월이 지났는지를 의미하는 cohort_index를 계산해 코호트 분석의 가로축 기준을 만든다.
예를 들어
가입한 달 = 0, 다음 달 = 1, ... 이런 식으로 설정할 수 있다.
# 월 차이 계산 함수
def months_diff(df, col1, col2):
current_month = pd.to_datetime(df[col1]).dt.month
cohort_month = pd.to_datetime(df[col2]).dt.month
return current_month - cohort_month
# 년도 차이 계산 함수
def years_diff(df, col1, col2):
current_year = pd.to_datetime(df[col1]).dt.year
cohort_year = pd.to_datetime(df[col2]).dt.year
return current_year - cohort_year
# 코호트 인덱스 = (년도 차이 * 12) + 월 차이
def cohort_index(df, col1, col2):
return df[col1] * 12 + df[col2]
# 적용
df['months_diff'] = months_diff(df, 'current_month', 'cohort_month')
df['years_diff'] = years_diff(df, 'current_month', 'cohort_month')
df['cohort_index'] = cohort_index(df, 'years_diff', 'months_diff')
4. 사용자 수 집계 및 Retention Rate 계산
각 코호트 그룹에서 시간별로 얼마나 많은 사용자가 남아있는지(유지되고 있는지)를 계산하여 retention_rate를 구한다.
[참고]
churn_rate= 1 - retention_rate
# 각 cohort_month, cohort_index별 고유 사용자 수 계산
cohort_counts = df.groupby(['cohort_month', 'cohort_index'])['user_id'].nunique()
cohort_counts_df = cohort_counts.to_frame().rename(columns={'user_id': 'users'}).sort_values(by=['cohort_month'])
# 각 cohort_month 기준 초기 유저 수 대비 비율로 retention rate 계산
cohort_counts_df['retention_rate'] = cohort_counts_df['users'] / cohort_counts_df.groupby('cohort_month')['users'].transform('max')
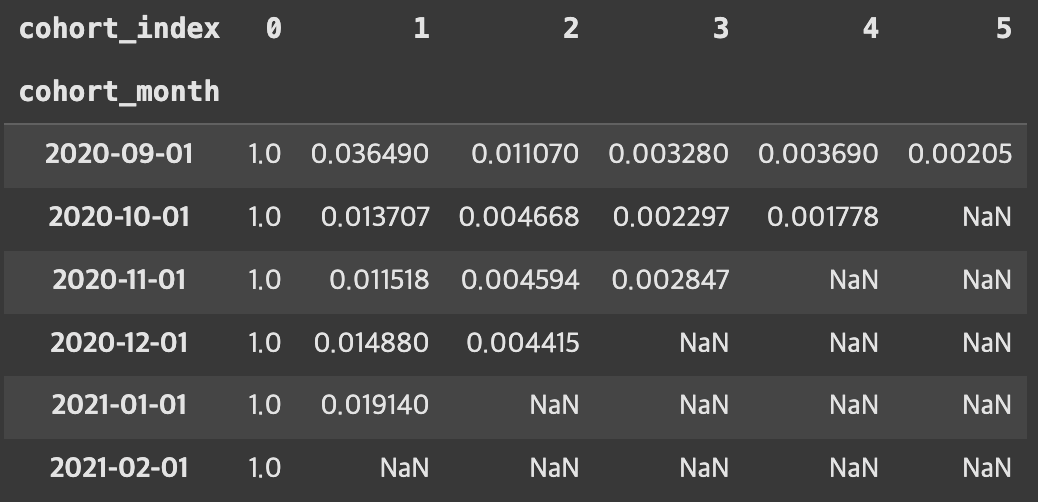
5. 리텐션 테이블 피벗 및 시각화
# 피벗 테이블로 변환 (행: cohort_month, 열: cohort_index, 값: retention_rate)
cohorts_pivot = cohort_counts_df.pivot_table(
index='cohort_month', columns='cohort_index', values='retention_rate')
# 시각화
import seaborn as sns
import matplotlib.pyplot as plt
plt.figure(figsize=(12, 10))
sns.heatmap(data=cohorts_pivot, annot=True, fmt='.2%', vmin=0.0, vmax=0.1, cmap='BuGn')
plt.title('Cohort-based Retention Heatmap')
plt.show()
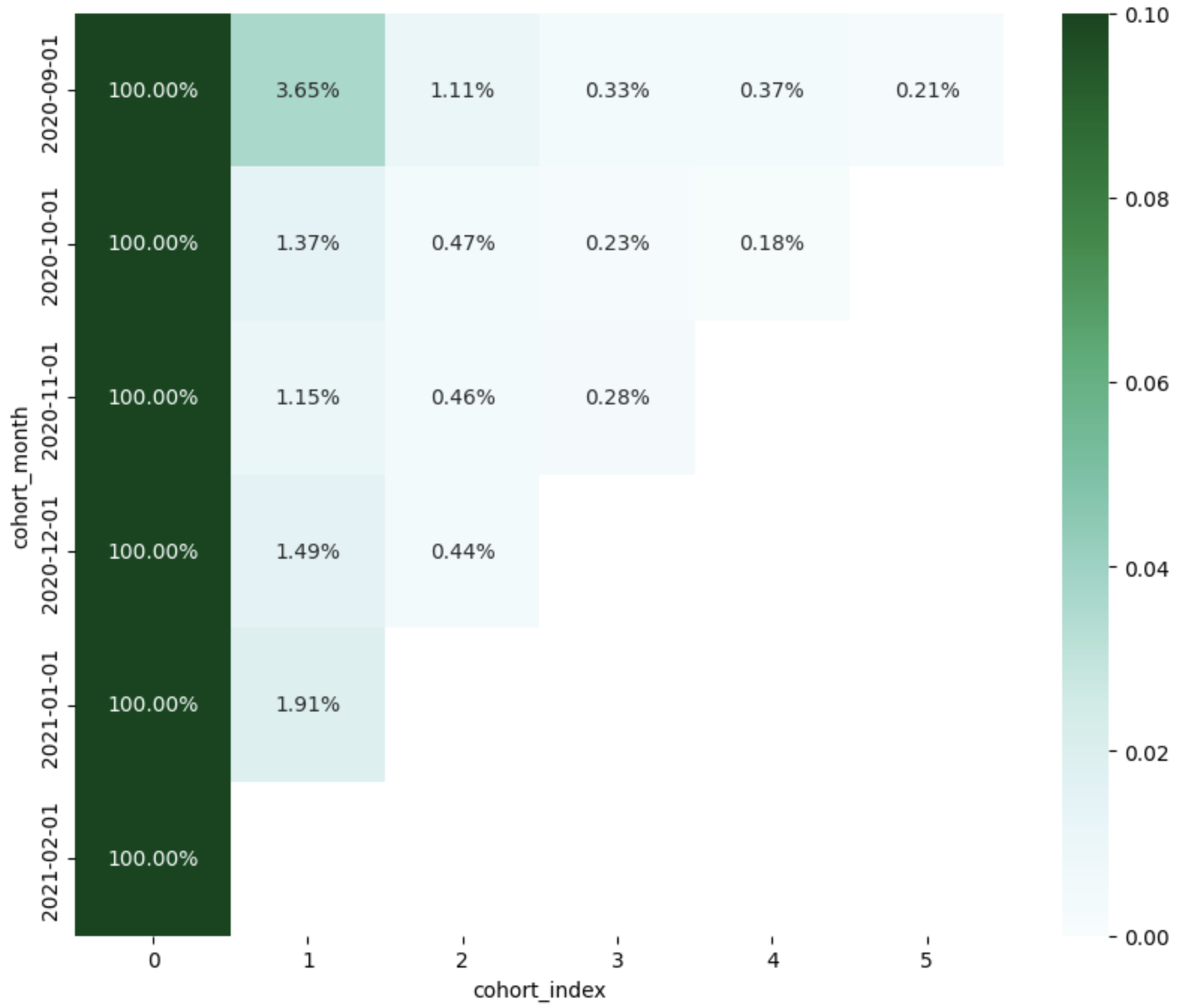
이 히트맵은 월별로 유입된 사용자들이 이후 몇 개월 동안 얼마나 서비스를 유지했는지를 시각적으로 보여준다. 색이 진할수록 높은 유지율을 나타낸다.
이때 주의할 점은, 0개월차는 항상 100%이므로 이후 유지율 추이를 중심으로 분석한다.
코호트 기반 리텐션 분석은 유지율을 수치로 보는 것에서 더 나아가, 특정 시점에 유입된 사용자들의 행동 패턴과 이탈 시점을 파악할 수 있도록 도와준다.
단기 성장이 아니라 지속 가능한 성장을 목표로 한다면, 신규 유입 못지않게 유지율에 집중해야 한다.
Retention 분석은 성장 지표가 아닌 지속 지표다.
새로운 사용자를 많이 유입시키는 것도 중요하지만, 이들을 얼마나 잘 유지시키느냐가 서비스의 진짜 성장을 의미한다.
