Revenue: 고객으로부터 얻는 수익
AARRR 프레임워크의 마지막 단계인 Revenue는 유저가 실제로 프로덕트에 돈을 쓰는 단계이다.
이 단계에서 얼마나 수익을 창출했는지는 당연히 중요한 지표이며, 각 유저가 프로덕트에 지불한 금액이 어느 정도인지도 확인할 필요가 있다.
대표적인 수익 지표는 다음과 같다.
- ARPU (Average Revenue Per User): 1인당 평균 수익
- ARPPU (Average Revenue Per Paying User): 결제 유저당 평균 수익
- CLV (Customer Lifetime Value): 고객 생애 가치
이때 CLV는 다음 공식을 기반으로 계산된다.
💡 CLV = 평균 주문 금액 × 구매 빈도 × 고객 수명
ARPU와 ARPPU는 이 글에서 다뤄보았다.
고객 한 명이 프로덕트를 사용하는 동안 발생시키는 총 매출을 추정하는 것으로, 마케팅 전략 수립과 고객 세그먼트 전략의 기초가 되는 중요한 지표다. 또한 CAC (Customer Acquisition Cost, 고객 획득 비용)와 함께 비교하여 LTV > CAC를 유지하는 것이 매우 중요하다.
CLV Revenue를 계산해 보자.
1. 데이터 로드 및 확인
사용할 데이터는 Kaggle의 고객의 거래 내역을 담은 전자상거래 E-commerce 데이터로,
InvoiceNo, CustomerID, InvoiceDate, Quantity, UnitPrice 등 주요 컬럼이 포함되어 있다.
import kagglehub
import os
# 데이터셋 다운로드
path = kagglehub.dataset_download("carrie1/ecommerce-data")
df = pd.read_csv(path + '/' + os.listdir(path)[0], encoding='ISO-8859-1')
df.head(3)

2. 전처리 및 CLV 계산을 위한 컬럼 구성
고객 식별이 불가능한 경우는 제거하고, 날짜는 datetime 포맷으로 변환한다. 이후 TotalPrice 컬럼을 만들어 총 구매 금액을 계산한다.
# CustomerID 없는 행 제거 및 날짜형 변환
df = df.dropna(subset=['CustomerID'])
df['InvoiceDate'] = pd.to_datetime(df['InvoiceDate'])
# 매출액 계산 (수량 × 단가)
df['TotalPrice'] = df['Quantity'] * df['UnitPrice']
3. 고객별 분석 데이터 준비
# 고객별로 주요 통계 계산
customer_data = df.groupby('CustomerID').agg({
'InvoiceNo': 'nunique', # 구매 횟수
'TotalPrice': 'sum', # 총 지출 금액
'InvoiceDate': ['min', 'max'] # 첫 구매일, 마지막 구매일
}).reset_index()
# 컬럼 이름 정리
customer_data.columns = ['CustomerID', 'PurchaseFrequency', 'TotalRevenue', 'FirstPurchaseDate', 'LastPurchaseDate']
4. 구매 빈도, 평균 구매 금액, 고객 수명 계산
핵심 지표는 다음과 같다.
AverageOrderValue: 1회당 평균 구매 금액PurchaseFrequency: 총 구매 횟수CustomerLifetime: 고객이 활동한 일수CLV: 고객 생애 가치
💡 CLV
= 고객의 평균 주문금액 평균구매 빈도 (고객들의 방문일수)/365
# 고객 생애 기간 (일 단위)
customer_data['CustomerLifetime'] = (customer_data['LastPurchaseDate'] - customer_data['FirstPurchaseDate']).dt.days
# 평균 구매 금액
customer_data['AverageOrderValue'] = customer_data['TotalRevenue'] / customer_data['PurchaseFrequency']
# CLV 계산
customer_data['CLV'] = customer_data['AverageOrderValue'] * customer_data['PurchaseFrequency'] * (customer_data['CustomerLifetime'] / 365)
5.CLV가 높은 고객 확인
# CLV 상위 10명의 고객 출력
print("CLV 상위 10명의 고객")
print(customer_data[['CustomerID', 'CLV']].sort_values(by='CLV', ascending=False).head(10))
CLV 상위 10명의 고객
CustomerID CLV
1703 14646.0 270300.339890
4233 18102.0 257141.061205
3758 17450.0 184400.271315
1895 14911.0 135115.108603
1345 14156.0 112452.215562
55 12415.0 106098.810548
3801 17511.0 89332.576986
3202 16684.0 63725.765041
1005 13694.0 63339.709315
2192 15311.0 60721.681699이처럼 CLV가 높은 고객들을 정렬하여 고객 리스트를 만들면, 높은 가치를 가진 고객을 선별할 수 있다. 이들은 충성도 높은 핵심 고객으로 분류되며, 별도의 리텐션 전략이 필요할 수 있다.
6.전체 평균 CLV 계산
average_clv = customer_data['CLV'].mean()
print(f"\n전체 고객의 평균 CLV: {average_clv:.2f}")
전체 고객의 평균 CLV: 1397.59이 지표는 제품이나 서비스가 유저로부터 기대할 수 있는 평균 수익을 보여준다.
7. CLV 분포 시각화
import matplotlib.pyplot as plt
import seaborn as sns
plt.figure(figsize=(10, 6))
sns.histplot(customer_data['CLV'], kde=True)
plt.title('CLV Distribution')
plt.xlabel('Customer Lifetime Value')
plt.ylabel('Frequency')
plt.xlim(0, 5000)
plt.show()
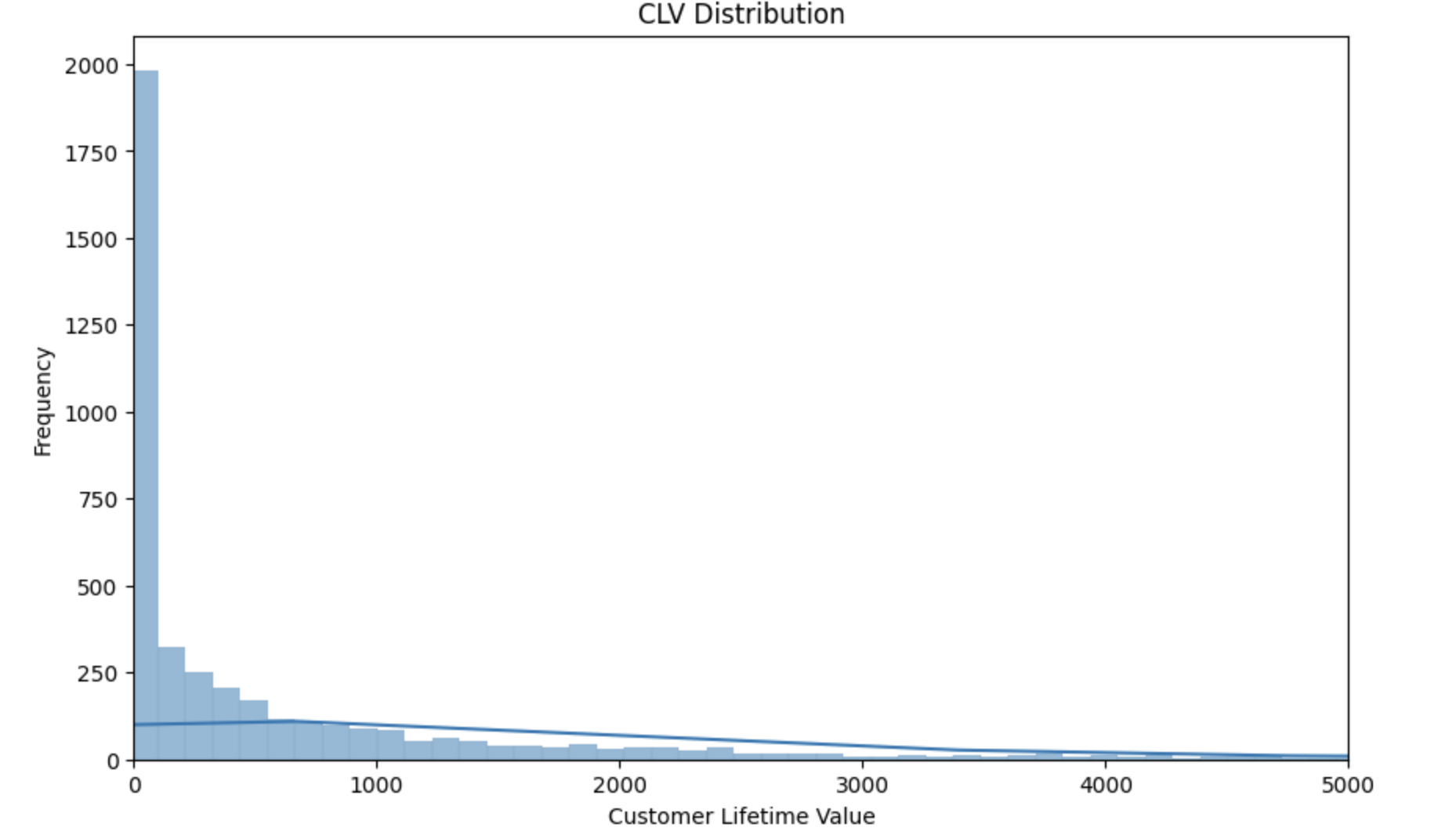
CLV 분포 히스토그램통해, 특정 고객군이 CLV 상위에 몰려있는지, 아니면 분산이 큰지 등을 시각적으로 확인할 수 있다.
Revenue 단계에서는 고객 개개인이 어느 정도의 수익을 발생시키는가, 그리고 장기적으로 어떤 고객군이 가치가 높은가를 파악하는 데 중점을 둔다.
CLV는 제품 또는 서비스에 대한 고객의 관계 깊이, 재방문 가능성, 이탈 확률 등을 모두 담고 있기 때문에, Revenue 단계에서의 정밀한 고객 분석은 전체 비즈니스 전략의 기반이 된다.
