A/B 테스트는 두 개의 그룹(A와 B)에 서로 다른 조건을 부여한 뒤, 이들 간의 차이가 통계적으로 유의미한지를 확인하는 실험 기법이다. 웹 페이지 개편, 광고 효과 측정, 신제품 런칭 전 UI 변경 검증 등에 많이 사용된다.
예를 들어 어떤 쇼핑몰에서 기존 페이지(A)를 개선한 페이지(B)로 바꾸었을 때, 구매 전환율이 실제로 높아졌는지를 확인하고자 할 때 A/B 테스트가 활용된다. 단순히 어떤 디자인이 더 좋아 보인다고 판단할 수는 없다. 실험을 통해 그 변화가 실제로 유의미한 효과를 가지는지 확인해야 한다.
핵심은 단순한 수치 비교가 아닌, 그 차이가 우연이 아닌지 통계적으로 검정하는 것이다.
A/B 테스트를 직접 구현해보면서 실험군·통제군 구성, 표본 수 결정, 중복 제거, 통계적 검정까지의 과정을 경험해 보는 유익한 시간이 되었다.
이제, 신규 페이지에 따른 전환율이 유의미한 변화가 있는지 측정는 A/B 테스트를 시행해 보자.
1. 데이터 로드 및 환경 설정
statsmodels, scipy.stats 는 통계 분석, matplotlib, seaborn 은 시각화에 사용된다.
# 필요한 라이브러리 불러오기
import kagglehub
import os
import numpy as np
import pandas as pd
import scipy.stats as stats
import statsmodels.stats.api as sms
import matplotlib.pyplot as plt
import seaborn as sns
from math import ceil
# 데이터 다운로드
path = kagglehub.dataset_download("zhangluyuan/ab-testing")
df = pd.read_csv(path + '/' + os.listdir(path)[0])
df.head(3)
이 코드에서는 KaggleHub에서 실험용 데이터 zhangluyuan/ab-testing 를 다운로드하고 불러온다. 주요 변수는 다음과 같다.
user_id: 사용자 IDtimestamp: 세션 시간group: 실험군/통제군 구분landing_page: 사용자가 본 페이지 버전converted: 전환 여부(1: 전환, 0: 비전환)
2. 그룹 간 페이지 매칭 확인
교차표를 통해 그룹과 랜딩페이지 간 매칭이 올바르게 구성되어 있는지 확인한다. 예를 들어, control 그룹이 control 페이지를 보고 있는지 검토한다.
pd.crosstab(df['group'], df['landing_page'])
| user_id | timestamp | group | landing_page | converted |
|---------|----------------------------|-----------|---------------|-----------|
| 851104 | 2017-01-21 22:11:48.556739 | control | old_page | 0 |
| 804228 | 2017-01-12 08:01:45.159739 | control | old_page | 0 |
| 661590 | 2017-01-11 16:55:06.154213 | treatment | new_page | 0 |
3. 효과 크기와 필요 표본 크기 계산, 필요한 표본 수 계산
현재 사이트의 전환율은 12%이며, 14%로 올리고 싶다고 가정할 때 필요한 최소 표본 수를 계산한다.
effect_size = sms.proportion_effectsize(0.12, 0.14) # 기대 전환율 차이 # 기대 효과크기: 전환율 12% → 14%
required_n = sms.NormalIndPower().solve_power(
effect_size,
power=0.8,
alpha=0.05,
ratio=1
)
required_n = ceil(required_n)
print(required_n) # 4433
기대 효과 크기(effect size)를 기준으로, 유의수준 0.05, 검정력 0.8 조건에서 필요한 최소 표본 수는 약 4433명이다.
4. 중복 사용자 제거
한 유저가 여러 번의 세션을 생성할 수 있기 때문에 중복된 세션을 가진 사용자(double_users)를 식별해 중복을 제거한다.
동일 사용자가 A/B 둘 다 노출되면 실험의 무작위성이 무너지기 때문이다.
session_counts = df.user_id.value_counts()
double_users = session_counts[session_counts > 1].index
5. 실험/통제 그룹 샘플링
통제군과 처리군을 각각 4,433명씩 랜덤 추출하여 실험군과 통제군을 구성하고 통합한 데이터프레임을 구성한다.
control_group = df.query('group == "control"').sample(required_n)
treatment_group = df.query('group == "treatment"').sample(required_n)
# 병합 및 초기 확인
ab_test = pd.concat([control_group, treatment_group], axis=0)
ab_test.reset_index(drop=True, inplace=True)
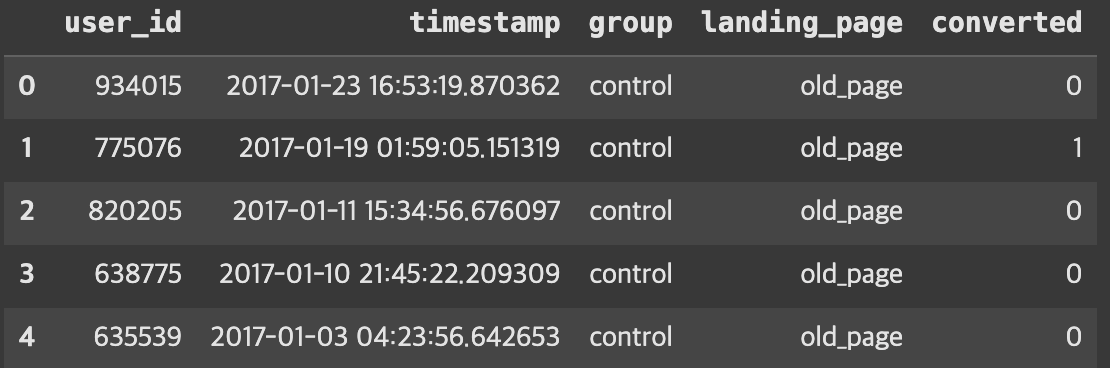
ab_test.head()
6. 전환율 집계 및 통계 요약
각 그룹의 전환율, 표준편차, 표준오차를 집계하여 기본 통계량을 확인한다.
conversion_rates = ab_test.groupby('group')['converted']
std_p = lambda x: np.std(x, ddof=1)
se_p = lambda x: stats.sem(x, ddof=1)
conversion_rates = conversion_rates.agg([np.mean, std_p, se_p])
conversion_rates.columns = ['conversion_rate', 'std_deviation', 'std_error']
conversion_rates
| 그룹 | 전환율 | 표준편차 | 표준오차 |
| --- | --- | --- | --- |
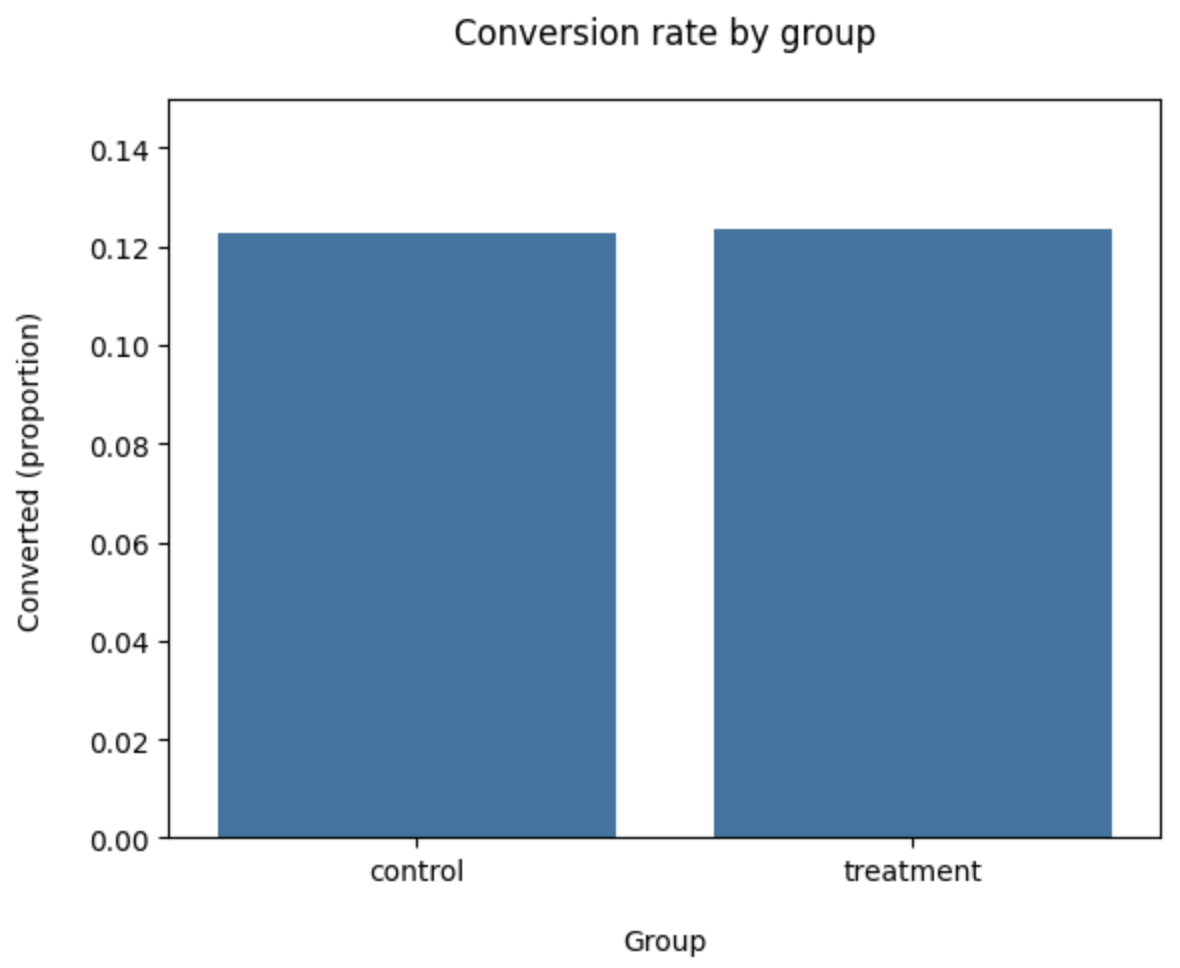
| control | 0.123 | 0.328 | 0.005 |
| treatment | 0.124 | 0.329 | 0.005 |7. 시각화
이제 전환율 0.113에서 0.124가 된 것이 의미가 있는지를 Z-test를 통해 검증한다.
다만, 시각적으로 차이가 보여도 통계적으로 유의하다는 결론을 내리면 안 된다. 다음 단계가 중요하다.
sns.barplot(x=ab_test['group'], y=ab_test['converted'], ci=False)
plt.ylim(0, 0.15)
plt.title('Conversion rate by group', pad=20)
plt.xlabel('Group', labelpad=15)
plt.ylabel('Converted (proportion)', labelpad=15)
plt.show()
8. Z-test를 통한 유의성 검정 및 신뢰구간 계산
이 단계는 이 A/B 테스트 분석의 핵심이자 가장 중요한 절차이다.
두 그룹의 전환율 차이가 우연일 가능성인지, 통계적으로 의미 있는 차이인지를 판단하는 기준이 되는 Z 통계량(Z-statistic)과 P-value를 구하고 해석해야 한다.
🔍 왜 Z 통계량과 P-value가 중요한가?
- Z 통계량은 두 집단의 평균 차이가 표준 오차 대비 얼마나 큰지를 나타내는 값으로, 이 값이 클수록 두 집단의 차이가 우연이 아닐 가능성이 높아진다.
- P-value는 이 Z 통계량이 관측될 확률로, P-value가 작을수록 귀무가설(두 집단 간 차이 없음)을 기각할 수 있다.
즉, 이 두 지표를 통해 실제 전환율 차이가 유의미한지 여부를 객관적으로 판단할 수 있게 된다.
Z 통계량, P-value 계산 및 신뢰구간 추정
from statsmodels.stats.proportion import proportions_ztest, proportion_confint
# 컨트롤, 실험 그룹의 전환 데이터 추출
control_conversion = ab_test.query('group == "control"')['converted']
treatment_conversion = ab_test.query('group == "treatment"')['converted']
# 각 그룹의 샘플 수 (nobs) 및 전환 수 (successes)
nobs = [control_conversion.count(), treatment_conversion.count()]
successes = [control_conversion.sum(), treatment_conversion.sum()]
# Z-검정 수행
z_stat, pval = proportions_ztest(successes, nobs=nobs)
# 신뢰구간 계산 (각 그룹별)
(lower_con, lower_treat), (upper_con, upper_treat) = proportion_confint(
successes, nobs=nobs, alpha=0.05
)
# 결과 출력
print(f'z statistic: {z_stat:.2f}')
print(f'p-value: {pval:.3f}')
print(f'95% Confidence interval for control group: [{lower_con:.3f}, {upper_con:.3f}]')
print(f'95% Confidence interval for treatment group: [{lower_treat:.3f}, {upper_treat:.3f}]')
z statistic: -1.03
p-value: 0.305
95% Confidence interval for control group: [0.112, 0.132]
95% Confidence interval for treatment group: [0.119, 0.139]
- Z 통계량이 -1.03이라는 것은 두 그룹 간 전환율 차이가 표준오차 기준 약 1배 정도의 수준이라는 의미이다.
- P-value가 0.035로 유의수준(α=0.05)을 초과하므로, 통계적으로 유의하지 않다. 따라서 귀무가설(두 그룹 간 전환율 차이는 없다)을 기각할 수 없다.
즉, 새로운 페이지의 전환율이 더 높다고 통계적으로 말할 수 없다는 결론을 낼 수 있다.
또한, 두 그룹의 신뢰구간이 서로 겹치고 있으며 이는 전환율 차이가 표본 오차 범위 내의 차이라는 것을 의미한다. 따라서 전환율 개선이 실제로 존재하더라도 해당 실험에서는 그 차이를 검출할 만큼의 통계적 증거가 부족하다는 결론이 도출된다.
| 요소 | 의미 | 예제에서의 결론 |
|---|---|---|
| Z 통계량 | 그룹 간 차이의 상대 크기 | -1.03 (차이가 크지 않음) |
| P-value | 차이가 우연일 확률 | 0.305 → 기각 불가 |
| 신뢰구간 | 전환율의 신뢰 가능한 범위 | 두 그룹이 겹침 → 차이 없음 시사 |
Z-test와 P-value를 확인하면 우리가 하는 실험이 ‘진짜로 효과가 있는가’를 데이터 기반으로 판단할 수 있다. 이를 통해 우리는 직관이나 추측이 아닌, 통계적 근거에 기반해 결정을 내릴 수 있게 된다.
이번 A/B 테스트에서는 실험군의 전환율이 더 높았지만, 그 차이는 통계적으로 유의하지 않다는 사실을 알 수 있었다. 이는 이후 제품 및 서비스 개선 여부를 결정하는 중요한 기준이 될 것이다.
전환율 차이가 보이더라도, 그 차이가 의미 있는 것인지는 통계적으로 검증되어야 한다.
