Auto Scaling
- 클라우드 리소스를 자동으로 조정하여 지정된 조건에 따라 필요할 때만 필요한 만큼의 컴퓨팅 리소스를 사용 할 수 있도록 하는 AWS 서비스
- 사용량이 증가하면 Auto Scaling은 사용자 정의 규칙에 따라 자동으로 EC2 인스턴스를 추가하여 용량을 늘 리고, 사용량이 감소하면 리소스를 줄여 비용을 절감
“ 수요 예측을 정확히 하기란 사실상 불가능 하므로 트래픽 변화에 유연하게 대응하자 ! ”
Scale up vs Scale out
Scale Up <-> Scale Down
하나의 인스턴스의 리소스(예: CPU, 메모리)를 늘리는 것을 의미
예) 더 강력한 CPU나 더 많은 RAM을 갖는 더 큰 인스턴스 유형으로 전환(리소스 업그레이드 / 다운그레이드)
주로 수동으로 수행 (리부팅, 서비스 중단 야기 -> 수평 확장 선호)
Scale Out <-> Scale In
더 많은 인스턴스를 추가하여 전체 시스템의 용량을 늘리는 방식 (리소스 개수 추가 / 축소)
AWS Auto Scaling - AWS의 관리형 서비스들은 주로 Scale out & in을 지원
AWS Auto Scaling Resource

EC2 Auto Scaling
: EC2 인스턴스에 대한 Scale in & out을 제어할 수 있는 서비스
이점
- 비용절감: 필요에 따라 용량을 동적으로 늘리거나 줄임, 사용한만큼만 비용 지불
- 내결함성 향상 : 인스턴스가 비정상 상태일 때 이를 종료하고, 새로운 인스턴스를 시작 -> 하나의 가용 영역이 불가 상태가 되면 다른 가용 영역에서 새 인스턴스를 시작
- 가용성 향상 : 현재 트래픽 요구를 처리할 수 있는 적정 용량을 갖추도록 도움을 주고, 가용 영역 전반에 인스 턴스 분산
EC2 Auto Scaling 구성요소
1. Launch Configurations / Launch Templates: 인스턴스를 시작할 때 사용할 EC2 인스턴스 설정을 정의. 여기에 는 인스턴스 유형, AMI, 키 페어, 보안 그룹 및 기타 구성 세부 정보가 포함됨
-
Auto Scaling Groups (ASGs): Auto Scaling이 관리할 EC2 인스턴스의 집합입니다. ASG는 최소, 최대, 원하는
용량을 설정하여 그 범위 내에서 인스턴스를 유지하도록 합니다.
-
Scaling Policies: 인스턴스 수를 언제 확장하거나 축소할지 결정하는 규칙을 정의. 메트릭(예: CPU 사용률, 네트워 크 입출력 등)에 기반하여 동작.
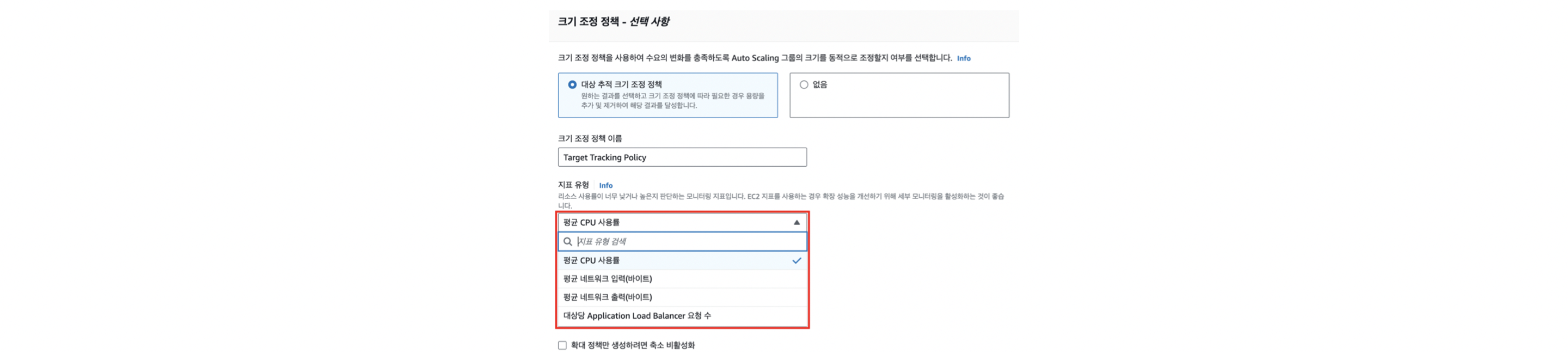
(1) CPU 사용률: 애플리케이션의 CPU 사용이 높고, 이것이 서비스 성능에 직접적인 영 향을 미치는 경우 이 지표를 사용하면 좋다!
ex. 계산 작업이 많은 애플리케이션 또는 서버가 최대 성능으로 운영되어야 하는 게 임 서버, 데이터베이스 서버 등
2.네트워크 입출력: 네트워크 트래픽이 성능의 제한 요소가 되는 환경에서는 이 지표가 유용하다.
ex. 큰 파일을 전송하거나 스트리밍 서비스를 운영하는 경우
3.ALB 요청 수 (LoadBalancerRequestCountPerTarget): 웹 애플리케이션이나 API 게이트웨이를 운영하고 요청 처리 능력을 기반으로 스케일링을 하고 싶을 때 적합하 다.이 지표를 사용하면 각 인스턴스가 처리해야 하는 HTTP/HTTPS 요청의 수를 기준 으로 인스턴스 수를 조정할 수 있다.
4.사용자 지정 지표 (Custom Metrics): Amazon CloudWatch를 통해 사용자가 직접 지표를 생성하고 이를 Auto Scaling에 활용할 수 있음. 이는 표준 지표로는 해결되 지 않는 특수한 요구 사항을 가진 시스템에 적합.
ex. 특정 애플리케이션 큐의 길이나 특정 데이터베이스의 쓰기/읽기 지연 시간 등
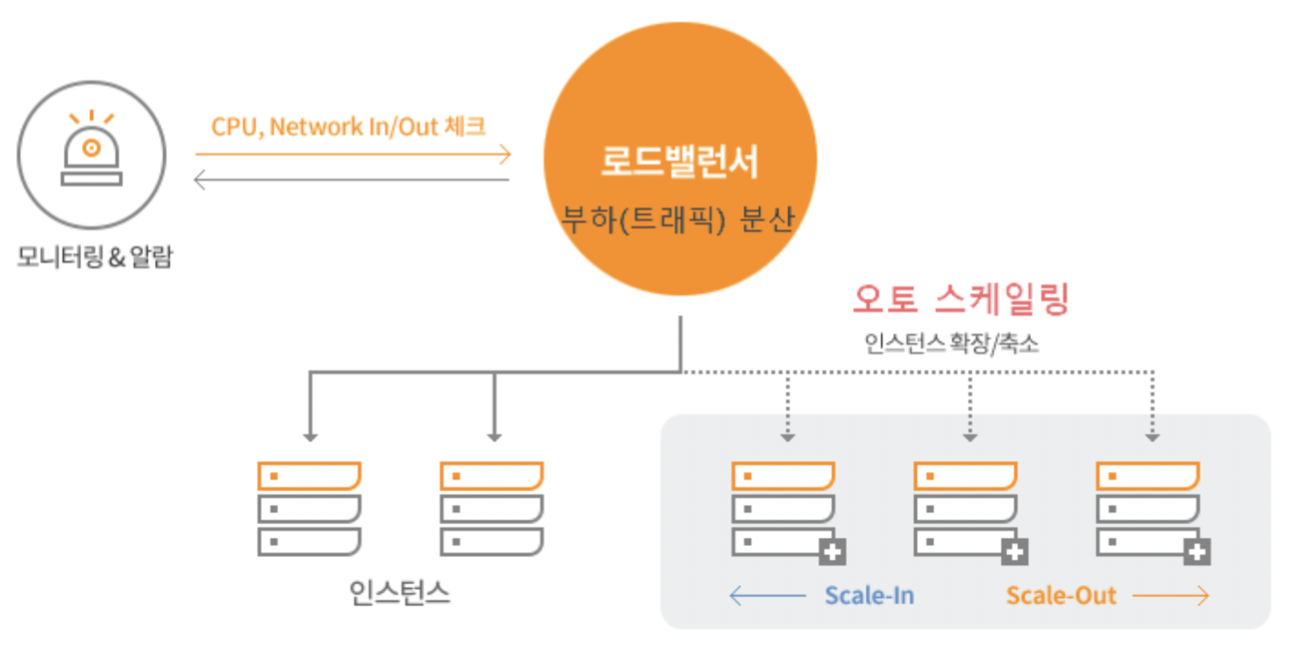
Load Balancer
네트워크 트래픽을 여러 서버에 균일하게 분산시키는 장치 또는 소프트웨어. 웹사이트 또는 어플리케이션의 가 용성과 내구성을 높이기 위해 사용
대표적인 AWS의 서비스 : Elastic Load Balancer
Load Balancing
여러 리소스에 부하를 분산시키는 기술
- 부하 분산 처리
하나의 리소스에 트래픽이 과도하게 몰려 서비스 중단되는 현상을 막기 위함 - 하나의 엔드포인트 제공
트래픽을 하나의 경로로 받아 여러 인스턴스에 분산시키기 때문에, 사용자 입장에서는 서로 다른 인스턴스에 접속하게 되더라도 같은 엔 드포인트(주소)로 접속하면 됨
Scale in & out으로 사이즈 조절하는 Auto Scaling과 뗄레야 뗄 수 없는 관계!
Load Balancer + Auto Scaling
Elastic Load Balancer
트래픽을 여러 대상에 자동으로 분산시켜주는 서비스
VPC에 탑재되며, 사용자의 요청을 받아 VPC 내의 리소스를 적절한 부하 분산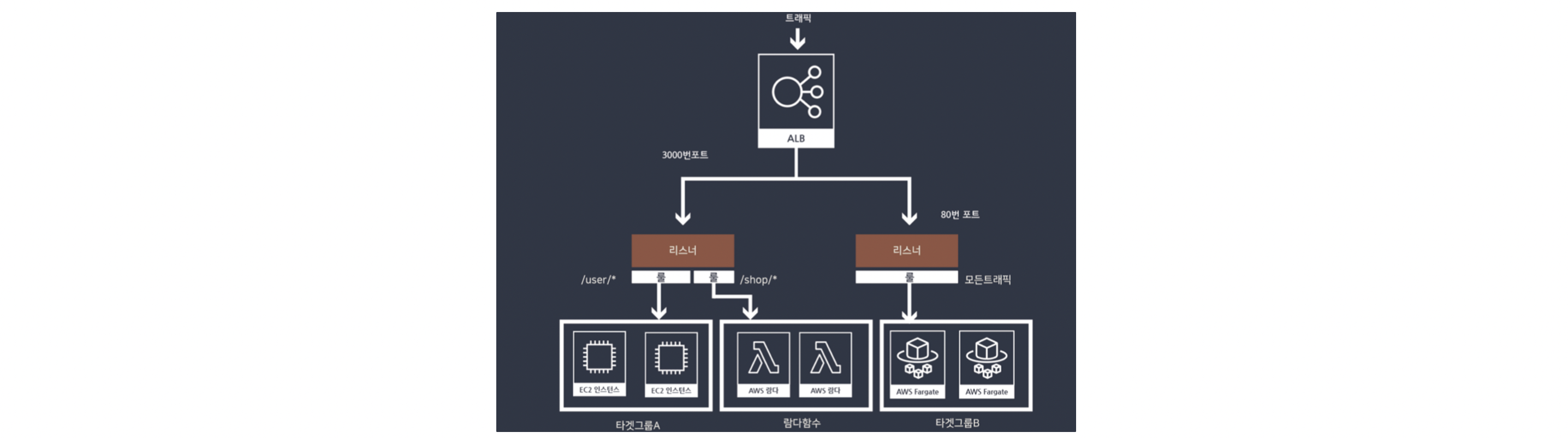
Elastic Load Balancer 내부 구성요소
리스너(Listener)
- 프로토콜과 포트를 기반으로 요청을 받아 검사하고 이를 적절한 타겟으로 전달하는 기능을 수행
- 리스너가 외부의 요청을 받아들이기 때문에 모든 로드 밸런서는 최소 한 개 이상의 리스너를 필요로 하며 최대 10개까지 설정 가능.
+ SSL 인증서를 게시하여 SSL Offload를 실시할 수도 있다
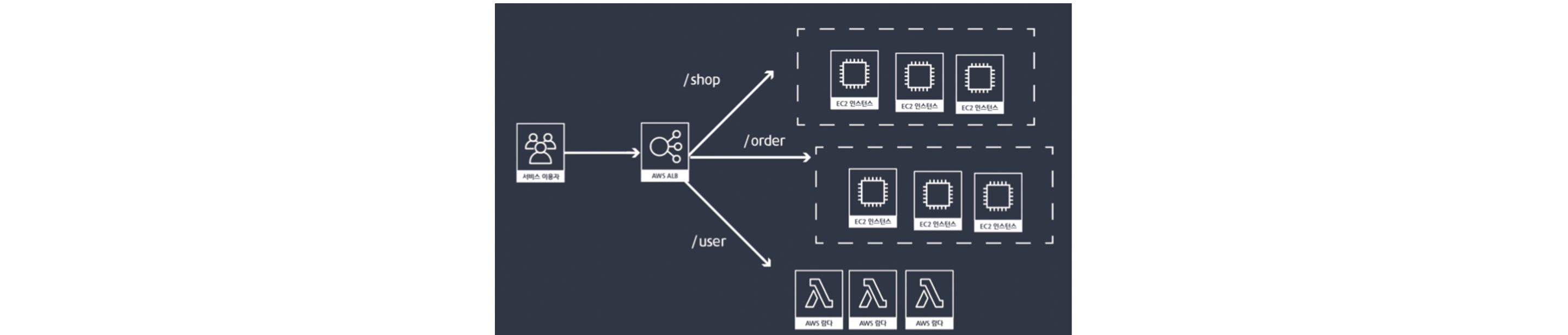
규칙(Rule)
- 리스너와 타겟그룹 사이의 트래픽 분배를 위한 라우팅 규칙
- 우선순위, 액션, 조건 등의 정보를 담고 있으며 특정 조건이 만족되었을 때 지정된 액션을 수행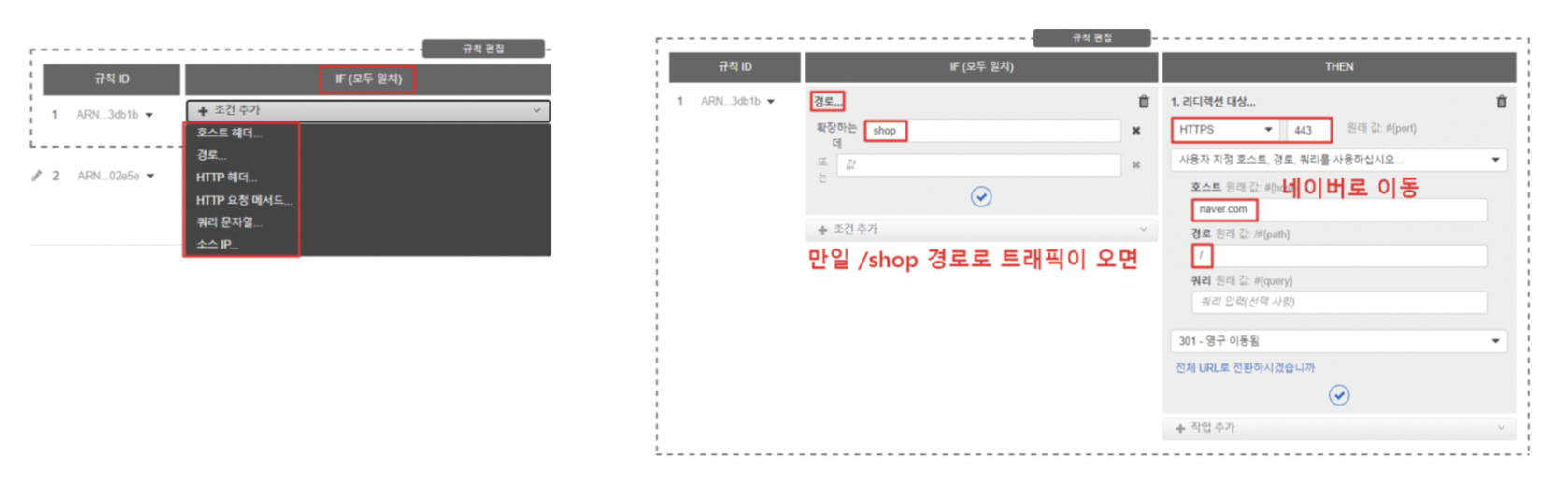
대상 그룹 (Target Group)
- 리스너가 전달한 요청을 처리하기 위한 부하 분산 대상들의 모임
- 대상 그룹에 등록된 인스턴스의 정보 + EC2가 전달받은 요청을 처리할 수 있는 지를 체크하는 헬스체크 + 이 대상 그룹에 요청처리가 가능한 EC2가 몇 개인지, 불가능 한 EC2는 몇 개인지를 확인하는 모니터링 기능이 들어있다
- 쉽게 말해 오토스케일링 하기 위해 오토스케일링 그룹 만든 것처럼, 로드 밸런싱 하기 위해 대상 인스턴스들 묶어 놓은 그룹 -> 그리고 이 대상 그대로 오토스케일링 그룹으로도 만들 수 있다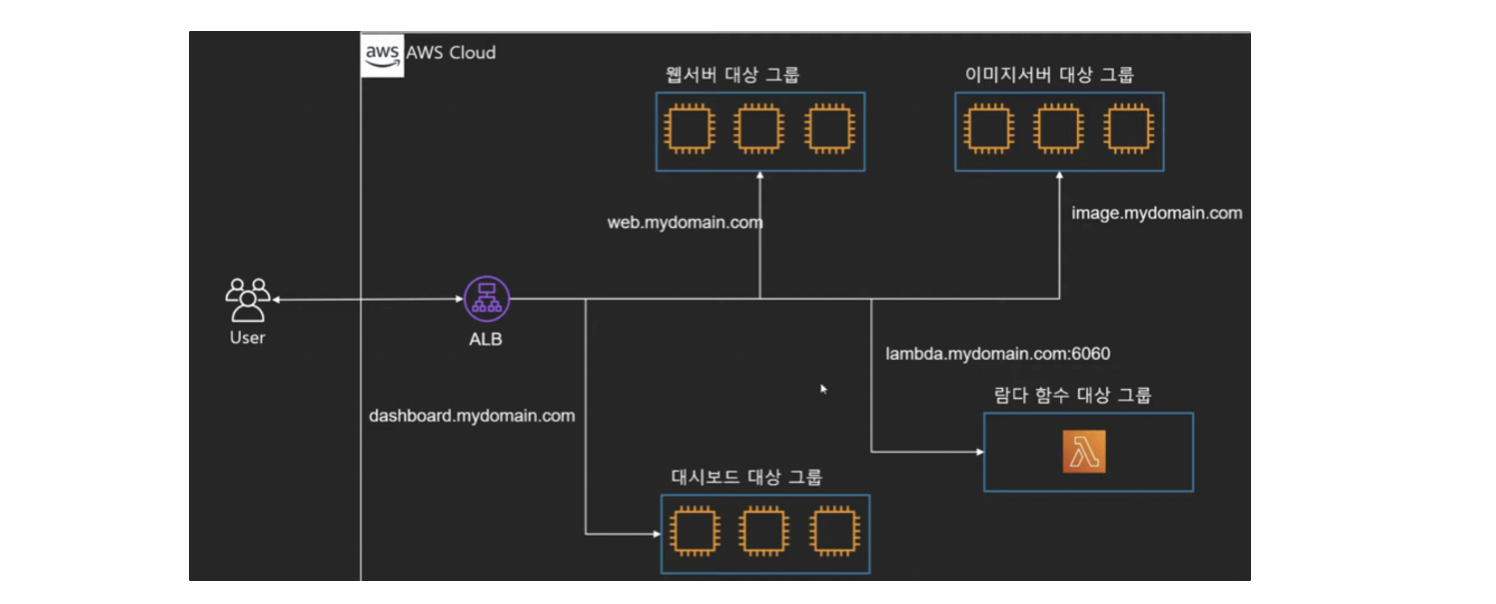
유휴 제한 시간 (Connection Time out)
- 사용자가 ELB를 거쳐 EC2에 접근하여 서비스를 접속하면 Connection이 생성됨
- 이 커넥션으로 통신하는데, 더 이상의 통신이 없을 때엔 유후 제한 시간이 작동하게 되고 그 시간이 지나면 커 넥션이 사라짐
Cross-Zone Load Balancing
두 개의 AZ 영역이 있고 각 영역에서 로드 밸런서가 위치하고 있다면
Cross-Zone Load Balancing이 이를 보완
AZ를 가리지 않고 고르게 분배 / ALB는 기본적으로 활성화 / NLB는 기본적으로 비활성화

Health Check
ELB에 연결된 인스턴스에 직접 트래픽을 발생시켜 인스턴스가 살아있는지 체크함 타겟그룹에 대한 헬스 체크를 통해 정상적으로 작동하는 인스턴스로만 트래픽을 분배
- InService : 서비스 살음 / OutofService : 서비스 죽음
Elastic Load Balancer의 종류
Application Load Balancer(ALB)
- ALB는 OSI 7 Layer에서 일곱 번째 계층에 해당하는 Application Layer를 다루는 로드밸런서
- ALB는 HTTP/HTTPS 프로토콜의 헤더를 보고 적절한 패킷으로 전송 (지능적인 라우팅)
- ALB는 IP주소 + 포트번호 + 패킷 내용을 보고 스위칭
- ALB는 IP 주소가 변동되기 때문에 Client에서 Access 할 ELB의 DNS Name을 이용
- ALB는 L7단을 지원하기 때문에 EC2 대신에 SSL 적용이 가능
Network Load Balancer(NLB)
- NLB는 L4(Transport Layer)단의 로드 밸런서를 지원
- NLB는 TCP/IP 프로토콜의 헤더를 보고 적절한 패킷으로 전송 (당연히 HTTP헤더는 해석 못함)
- NLB는 IP + 포트번호를 보고 스위칭
- NLB는 할당한 Elastic IP를 Static IP로 사용이 가능하여 DNS Name과 IP주소 모두 사용이 가능 (IP 고정 가능!)
- NLB는 SSL 적용이 인프라 단에서 불가능하여 애플리케이션에서 따로 적용해 주어야 함
=>ALB처럼 똑똑하게 주소로 보내주는게 아닌 단순한 라우팅이 필요하고,트래픽이 극도로 많은 경우에는 ALB 보다는 NLB를 사용하는 것이 적합하다고 할 수 있다.

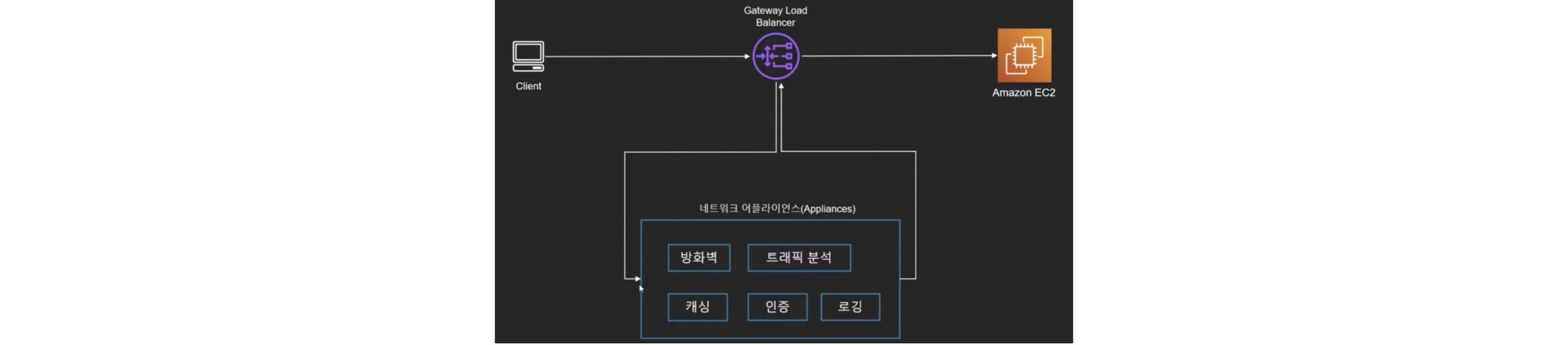
Gateway Load Balancer(GLB)
- GWLB는 L3단의 로드 밸런서를 지원
- 트래픽이 EC2에 도달하기 전에 먼저 트래픽을 검사하거나 분석하거나 인증하거
나 로깅하는 작업을 수행
- 트래픽을 체크하는 애, 위의 일반 로드밸런서와 조금 역할이 다름