ONCE: 사용 기술 정리
ONCE 소개
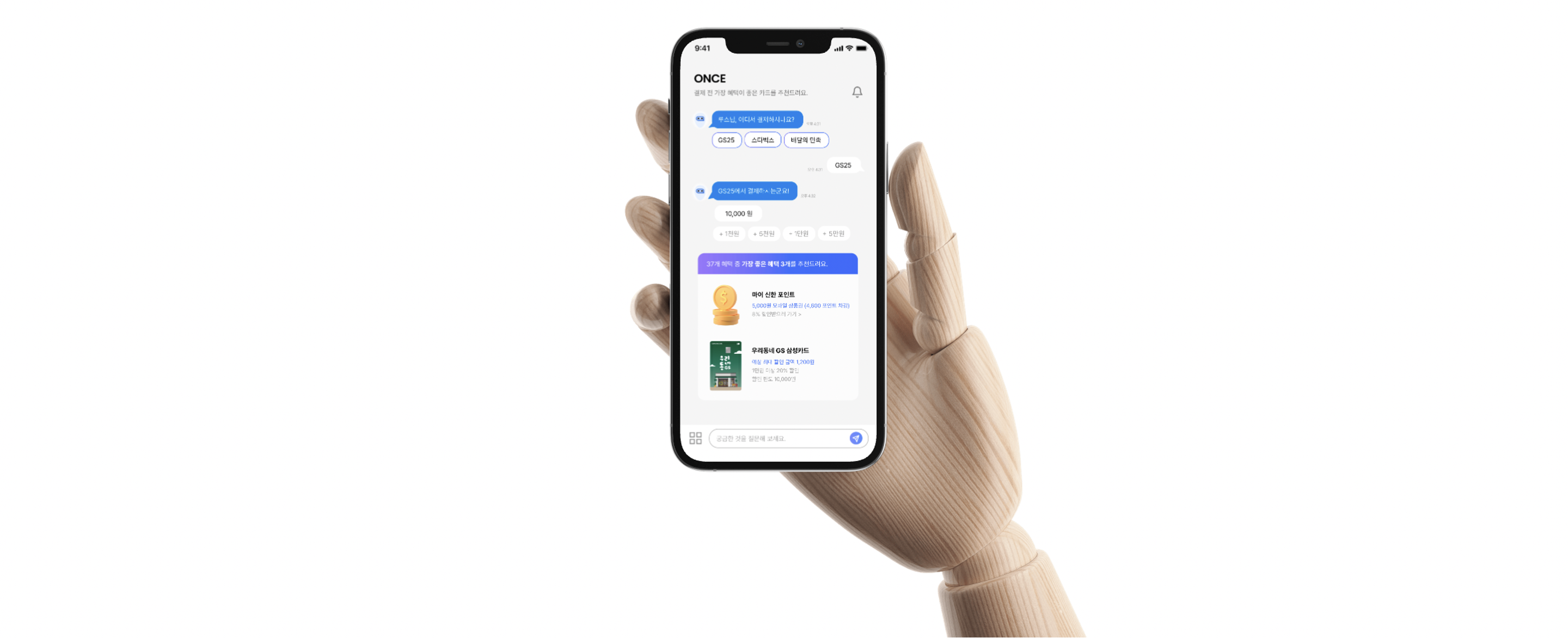
ONCE는 카드 결제 전 보유한 카드 중 결제처에서 최적의 혜택을 받을 수 있는 카드를 미리 추천해주는 AI 모바일 어플리케이션이다.
[ 매년 사라지는 카드 포인트 1000억원, 이대로 괜찮을까? ]
우리나라 1인당 신용카드 보유 개수는 3.6장이며, 개인의 신용카드 보유율은 80.2%에 달한다. 하지만 전체 발급 카드 중 1년 동안 사용 실적이 없는 휴면카드가 1300만장에 육박하며, 매년 사라지는 카드 포인트 1000억원이 소비자가 아닌 카드사의 부가 수입으로 들어가는 이유에 의문을 가지고 프로젝트를 시작하게 되었다.
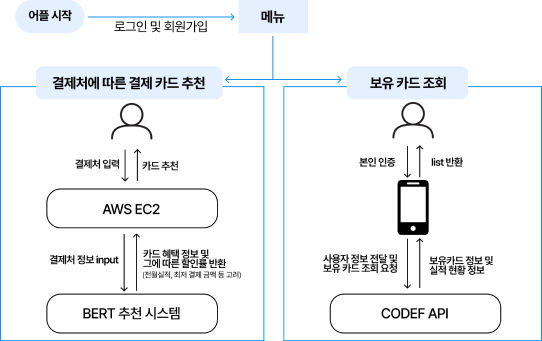
필요 기술 1 : 스크래핑 기반 금융 API를 이용한 사용자 정보 조회 (*스크래핑 : 각 카드사와 통신하여 실제 데이터를 제공)
→ CODEF API를 이용하여 실제 카드 보유 목록, 혜택 정보 및 실적을 불러올 수 있다.
필요 기술 2 : 크롤링을 이용한 카드사 별 카드 혜택 정보 실시간 수집
→ 파이썬 크롤링 라이브러리 BeautifulSoup, Selenium, Requests 등을 이용하여 카드별 혜택의 상세 정보를 불러올 수 있다.
필요 기술 3 : 자연어 처리 사전 훈련 언어 모델을 활용한 카드 혜택 학습
→ 사용자가 이용 중인 카드가 어떤 혜택을 제공하는지 분석하기 위해 수집한 상세 카드 혜택 정보를 BERT 모델을 활용하여 이해 및 학습시킨다.
필요 기술 4 : 트랜스포머 모델을 활용한 사용처에 맞는 최적의 카드 추천
→ 자연어 처리 기술을 활용하여 아이템을 벡터로 표현한 후, 사용자가 입력한 결제처와의 유사도를 계산하여 사용처에서 최적의 혜택을 제공하는 카드를 추천한다.
필요 기술 5 : 챗봇을 통한 사용자와의 상호작용
→ ChatGPT API를 활용하여 메인화면에서 사용자와의 주요 상호작용을 처리할 수 있도록 한다.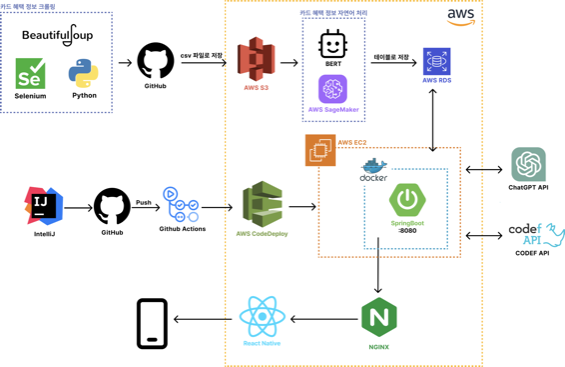
CODEF API를 이용해 금융정보 가져오기
-
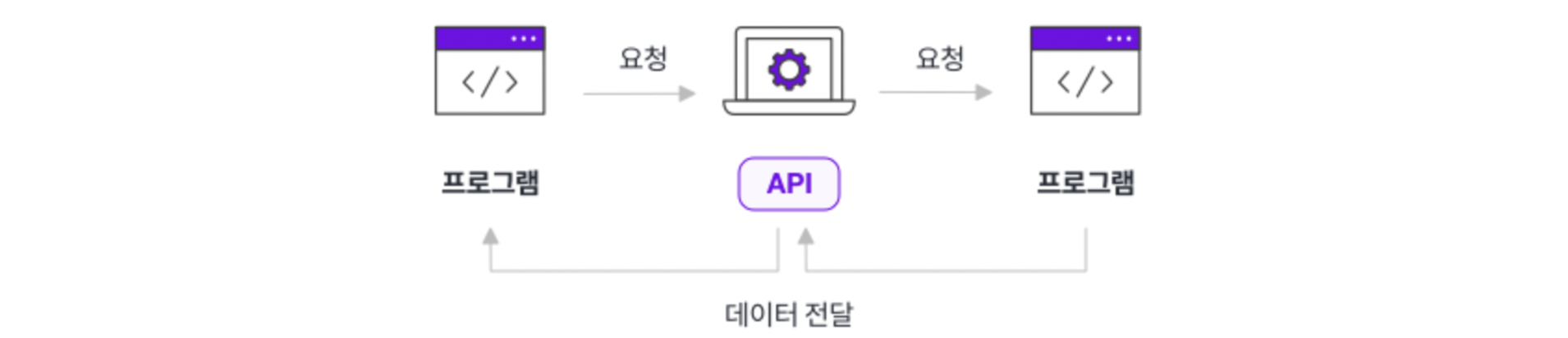
API란?
-
응용 프로그램에서 사용할 수 있도록, 운영 체제나 프로그래밍 언어가 제공하는 기능을 제어할 수 있게 만든 인터페이스
-
어떠한 응용프로그램에서 데이터를 주고 받기 위한 방법
오픈 API:
오픈API란 누구나 사용할 수 있도록 공개된 API
데이터를 표준화하고 프로그래밍해 외부 소프트웨어 개발자나 사용자가 바로 개발(어프리케이션)에 활용할 수 있는 형태의 개방 형식
업데이트가 빈번하고 활용도가 높은 대용량의 데이터를 연계 개발할 때, 날씨나 교통 정보 등 실시간 업데이트되는 데이터를 연계가 필요할 때 유용
-
-
ONCE에서의 필요
ONCE는 사용자에게 맞춤화된 서비스를 제공하기 위해서, 사용자의 카드 관련 정보들이 필요하다.
기본적으로 사용자가 보유하고 있는 카드의 종류를 파악하고 있어야 하고, 전월 실적을 파악해 혜택의 조건을 고려할 때 활용해야 한다. 또한 이번 달의 받은 혜택 정보와 실적이 얼마나 채워졌는지 등의 정보를 실시간 업데이트 하여 저장할 수 있어야 한다.
ONCE는 금융, 카드 관련 서비스로 보안 또한 중요한 지점이기 때문에, 이 정보들을 믿을 수 있는 방식으로 활용 가능한 금융 API를 활용하기로 결정하였다.
- CODEF API 선정 이유
카드 관련 api를 제공하는 여러 사이트가 존재하고, 우리가 대학생 창업 프로젝트의 과정에서 사용할 수 있는 서비스를 조사하였다.
해당 정보들이 민감한 개인정보인 만큼 금융결제원 오픈API과 바로빌 카드 정보 조회 API는 실제로 사업자 등록을 한 경우에만 회원가입이 되었고, API를 활용하기 위해서는 기업간 계약 체결을 진행해야 했기에, 현재 우리의 단계에는 적합하지 않았다.
신한 Open API에서 원하는 API를 제공 중인 것을 보았지만, 신한 카드의 정보만으로는 우리의 서비스를 완성시킬 수 없고, 다른 카드 회사들의 API를 모두 따로따로 불러오기는 어렵다는 결론을 내렸다.
토스 페이먼츠 개발자센터에서는 "카드사 혜택 조회" API를 제공중인데, 이는 하나하나 카드 상품의 혜택 정보를 원하는 우리 서비스의 의도와 맞지 않았다.
이에 따라 현재 대학생 신분에 사업자 등록 없이도 돈을 지불한다면 활용이 가능하고, 실제 창업 전에 DEVELOPER 모드로 기술 검증을 해볼 수 있으며 "보유 카드 목록 조회", "승인 내역 조회", "실적 조회"가 가능한 CODEF API를 활용하기로 결정하였다.
- API 활용 과정
CODEF에서 정보를 제공해주는 과정은 다음과 같다.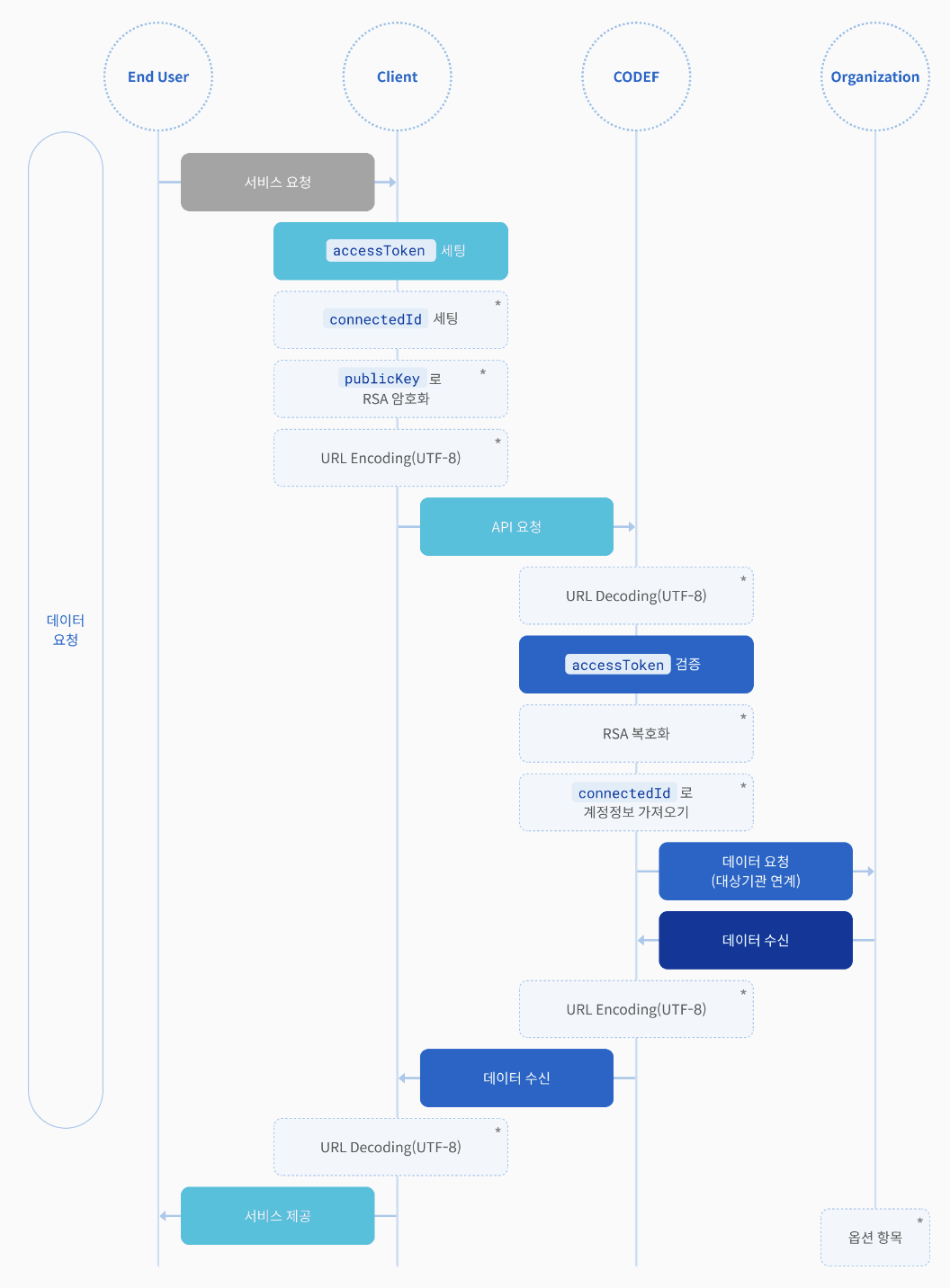 CODEF의 모든 api를 사용하기 위해서는 헤더에 accessToken이, body에 connectedID가 필요하다.
CODEF의 모든 api를 사용하기 위해서는 헤더에 accessToken이, body에 connectedID가 필요하다.
connectedID는 CODEF에서 사용하는 개념으로, 한개의 커넥티드 아이디로 엔드 유저가 사용하는 N개의 기관에 등록이 가능하다. 제공하는 여러 API들은 커넥티드 아이디 계정 등록으로 받은 accessToken과 connectedID, 필수 파라미터들을 담아 요청하여 원하는 정보들을 반환받을 수 있다.
- 구현
해당 실습은 API 요청이 제대로 실행되는지 확인하는 test용으로, 실제 서비스에서는 서버에서 자동으로 처리되는 로직을 가진다.
Django를 이용해 진행하였다. Django는 urls.py에 써있는 url에 접속하면 해당하는 views.py의 함수가 실행된다.
1) accessToken, connectedID 발급
urls.py
path('tocken/',tockenView),
views.py
@api_view(['GET'])
def tockenView(request):
client_id="[키 관리>client_id]"
client_secret="[키 관리>client_secret]"
url='https://oauth.codef.io/oauth/token'
authHeader = stringToBase64(client_id + ':' + client_secret).decode("utf-8")
headers = {
'Acceppt': 'application/json',
'Content-Type': 'application/x-www-form-urlencoded',
'Authorization': 'Basic ' + authHeader
}
response = requests.post(url, headers = headers, data = 'grant_type=client_credentials&scope=read')
print(response.status_code)
response_text=response.text
json_data = json.loads(response_text)
access_token = json_data.get('access_token')필요한 정보(client_id,client_secret)를 담아 https://oauth.codef.io/oauth/token에 요청을 보내 access_token을 받는다.
공동인증서를 이용한 로그인도 가능하지만, 서비스 이용 비용이 있어 카드사별 계정으로 직접 로그인하는 방식을 사용한다.
bank_code='0306' # 신한 코드
user_id='[신한 카드 홈페이지 아이디]'
user_password='[신한 카드 홈페이지 패스워드]'
pubkey="[키 관리>public_key]"
codef_account_create_url = 'https://development.codef.io/v1/account/create'
codef_account_create_body = {
'accountList':[
{
'countryCode':'KR', # KOREA
'businessType':'CD', # CARD
'clientType':'P', # PERSONAL
'organization':bank_code,
'loginType':'1', # 아이디 패스워드로 로그인
'id':user_id,
'password':publicEncRSA(pubKey, user_password) # 퍼블릭 키로 패스워드 암호화
}
]
}
response_account_create = http_sender(codef_account_create_url, access_token, codef_account_create_body)
decoded_response_text = urllib.parse.unquote(response_account_create.text) # URL 디코딩필요한 파라미터들을 담아 데이터를 만들고, 해당 url에 요청한다. 이때 CODEF에서 제공해주는 API 명세서를 잘 참고해야 한다.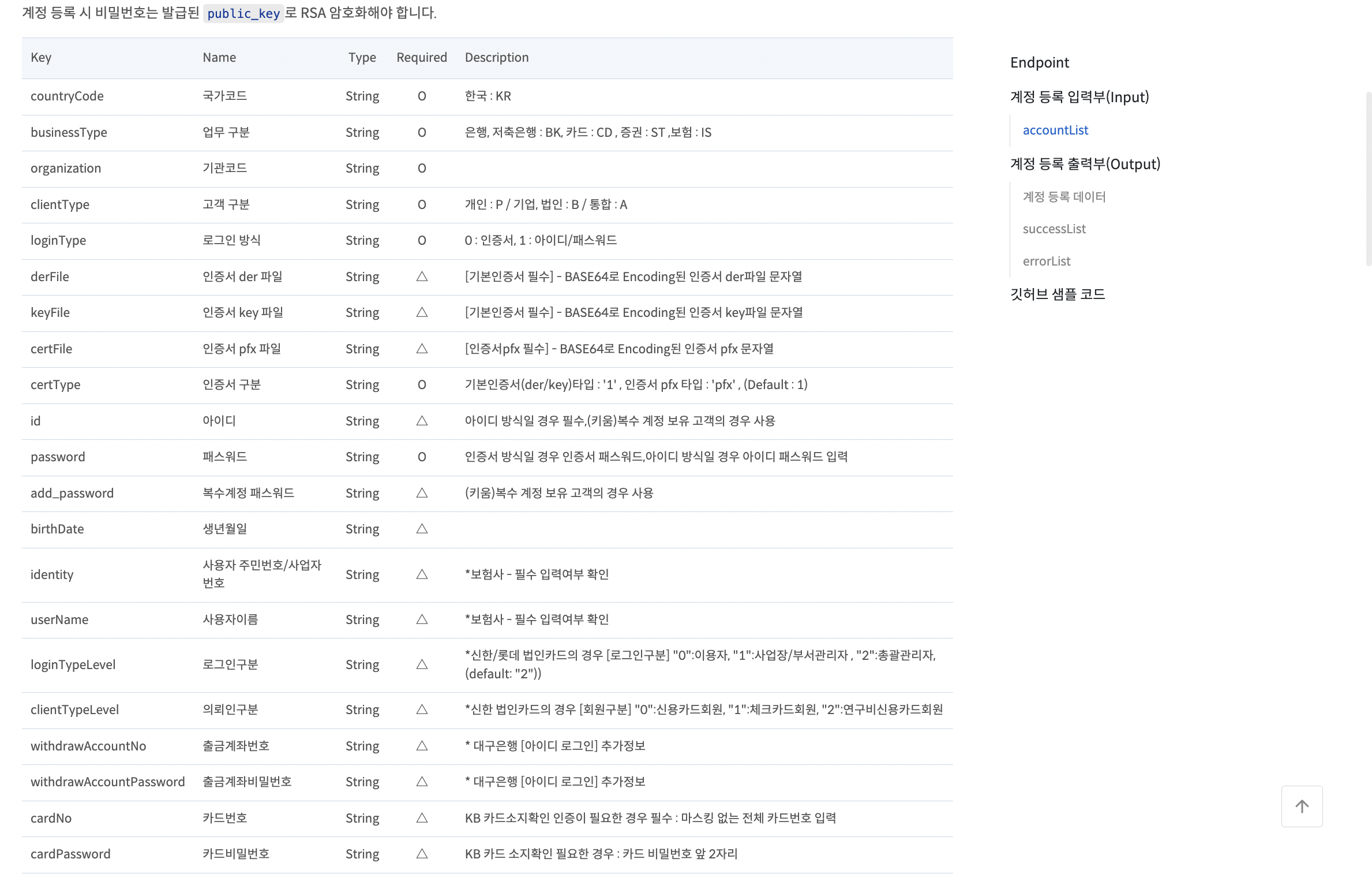
try:
response_data = json.loads(decoded_response_text)
connected_id = response_data['data']['connectedId']
return render(request,'home.html',{'tocken':access_token,'connectedID':connected_id})
# 예외처리완료되어 얻은 access_token과 connected_id를 담아 home.html를 호출한다.
home.html은 access_token과 connected_id를 화면에 보여주고 세가지 api를 호출하는 버튼으로 구성하였다.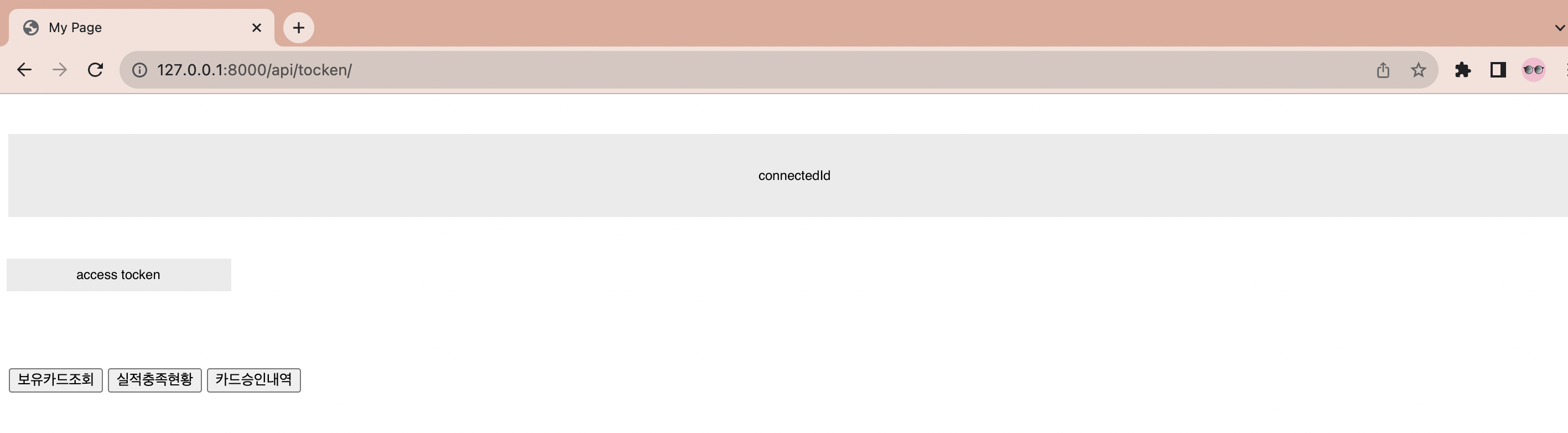
2) 보유 카드 조회
보유카드 조회 버튼 클릭 시 실행되는 함수이다.
@api_view(['GET'])
def mycardView(request,tocken,connectedID):
codef_mycard_url = 'https://development.codef.io/v1/kr/card/p/account/card-list'
codef_account_create_body = {
'organization':'0306',
'connectedId':connectedID,
'loginType':'1',
'inquiryType':'1'
}
response_account_create = http_sender(codef_mycard_url, tocken, codef_account_create_body)
my_data=unquote(response_account_create.text)
my_data=json.loads(my_data)
my_data=json.dumps(my_data,ensure_ascii=False)
return render(request,'home.html',{'my_data': my_data,'tocken':tocken,'connectedID':connectedID})토큰을 header에, connectedId와 카드회사, 로그인type등 정보를 담아 보유카드를 조회하는 EndPoint에 정보를 전달한다.
그 결과는 다음과 같다.
카드 이름과 카드 번호, 카드 종류 뿐만아니라 교통카드 기능이 있는지, 카드 이미지 등의 정보가 반환된다.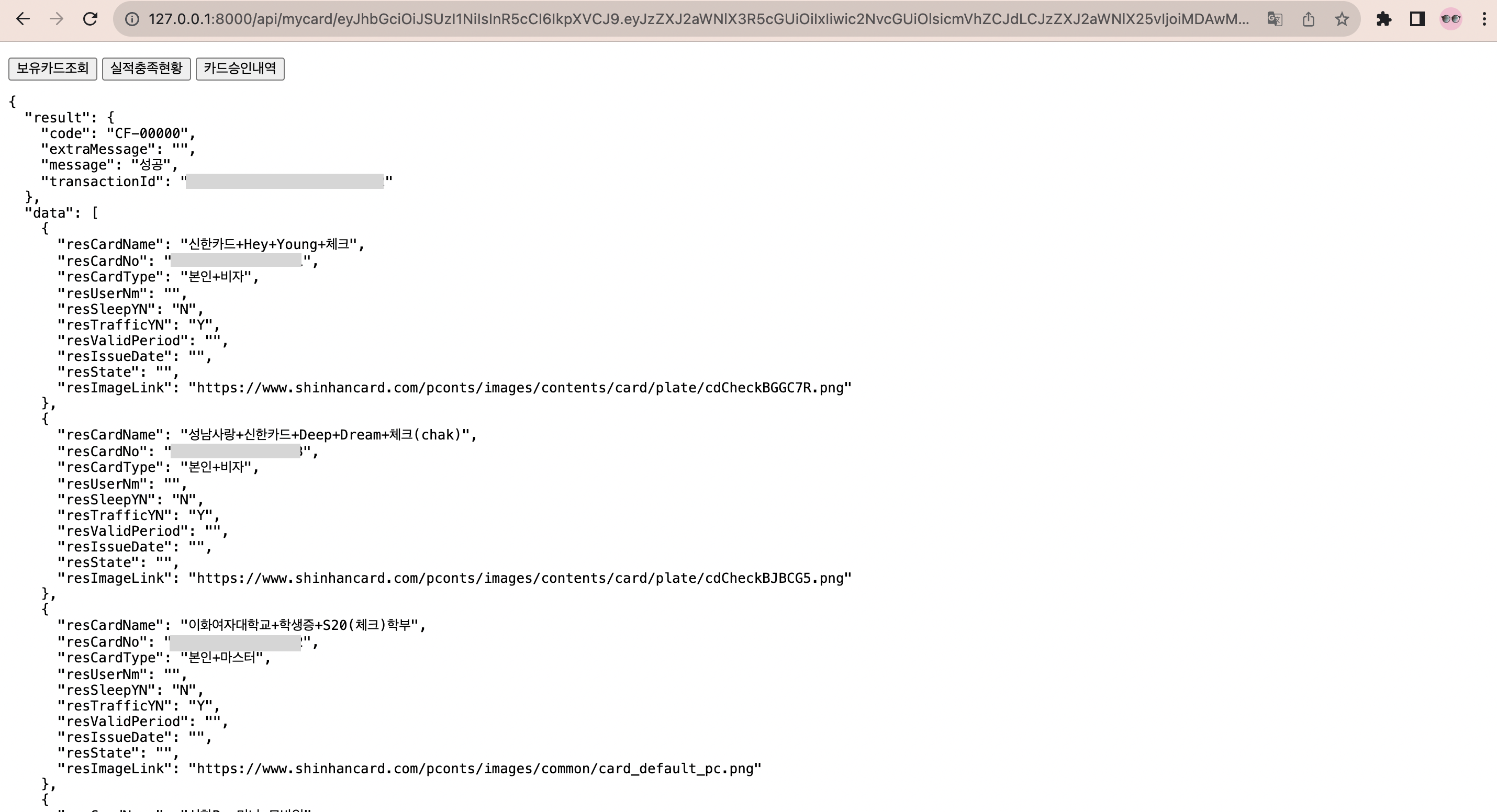
3) 승인 내역 조회
(2)번 보유 카드 조회처럼 api 명세서의 필수 파라미터들을 담고, 해당 엔드포인트에 요청을 보내면 된다.
카드 승인 내역 정보로, 날짜와 시간, 금액과 사용한 결제처 등의 정보를 확보 가능하다. 사용자가 자주 들른 매장인 경우 GPS를 이용해 근처일 경우 알림을 울리는 기능을 구현할 때, 사용자의 단골 매장을 찾는데 사용될 API이다.
4) 실적 현황 조회
각 카드가 가지고 있는 혜택들과 해당 혜택을 받기 위한 실적이 채워졌는지 여부를 알려준다.
이번 달 해당 카드로 사요한 금액도 확인이 가능하다.
카드 혜택 정보 크롤링
- 크롤링이란?
Web상에 존재하는 Contents를 수집 하는 작업 (프로그래밍으로 자동화 가능)
1) HTML 페이지를 가져와서, HTML/CSS등을 파싱하고, 필요한 데이터만 추출하는 기법
2)Open API(Rest API)를 제공하는 서비스에 Open API를 호출해서, 받은 데이터 중 필요한 데이터만 추출하는 기법
3)Selenium등 브라우저를 프로그래밍으로 조작해서, 필요한 데이터만 추출하는 기법
- ONCE에서의 필요
원스는 사용자의 결제처, 전월실적, 혜택을 받기 위한 최저 결제 금액과 최고 할인 금액을 파악하고 있어야 한다.
그러기 위해 각 카드 상품들의 페이지에 나와있는 유의사항 하나하나까지 파악해야 한다.
이에 따라 카드 혜택 정보 저장을 위해 크롤링을 이용하기로 하였다. - 크롤링 종류
정적 크롤링:
웹에 있는 정적인 데이터를 수집할 때 사용. 주소를 통한 단발적 접근.
정적 데이터: 변하지 않는 데이터. 한 페이지 안에서 사전 작업 없이 드러나는 정적인 데이터
수집속도가 빠르지만, 수집 대상에 한계가 있음
사용 라이브러리: requests, BeautifulSoup
동적 크롤링:
웹에 있는 동적인 데이터를 수집할 때 사용. 브라우저를 사용한 연속적 접근.
동적 데이터: 입력, 클릭, 로그인 등과 같이 페이지 이동이 있어야 얻을 수 있는 데이터.
속도가 느리지만 더 많은 정보 수집 가능
사용 라이브러리: selenium, chromedriver
- 구현
1) 정적 크롤링, csv파일로 저장
import csv
csvFile = open('kb_test.csv', 'w+')
writer = csv.writer(csvFile)
writer.writerow(('card name', 'part', 'discount','notice'))카드 혜택을 저장할 csv파일을 연다. 칼럼명에는 카드이름, 혜택 분야, 할인 내용, 유의사항이 있다.
from urllib.request import urlopen
from bs4 import BeautifulSoup
html=urlopen('https://card.kbcard.com/CRD/DVIEW/HCAMCXPRICAC0076?mainCC=a&cooperationcode=09123')
bs=BeautifulSoup(html,'html.parser')urlopen함수를 이용해 원하는 카드 상품의 페이지를 연다.
name = bs.find('h1', {'class':'tit'}).get_text()
soups=bs.findAll('div',{'id':'tabCon011'})
for i in range(1, 3):
partname=soups[i].find('h2').text[7:]
parts=soups[i].findAll('div', {'class':'titArea'})
for part in parts:
discount=part.find('h2', {'class':'titDep2'}).text
notice=part.find('div', {'class':'benefitBox1'}).text
writer.writerow((name,partname,discount,notice))html의 구조를 파악하고, 원하는 정보의 class, id등을 이용하여 경로를 찾고 값을 저장한다.
writerow함수로 찾은 값들을 csv파일에 한줄씩 적는다.
생성된 결과는 다음과 같다. 카드의 이름과 혜택 분야별 할인 내용이 잘 저장되었음을 확인 가능하다.

저장이 완료되면 csvFile.close()명령어로 csv파일을 닫는다.
2) 동적 크롤링
# selenium의 webdriver를 사용하기 위한 import
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
# selenium으로 키를 조작하기 위한 import
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
# 페이지 로딩을 기다리는데에 사용할 time 모듈 import
import time필요 라이브러리들을 import
# 크롬드라이버 실행
driver = webdriver.Chrome()
url = 'https://card.kbcard.com/CRD/DVIEW/HCAMCXPRICAC0076?mainCC=a&cooperationcode=09123'
#크롬 드라이버에 url 주소 넣고 실행
driver.get(url)
# 페이지가 완전히 로딩되도록 3초동안 기다림
time.sleep(2)크롬드라이버를 이용해 해당 url의 페이지를 연다.
# 링크 클릭
link = driver.find_element(By.ID,'topTab1').find_element(By.TAG_NAME,'a')
link.click()상세 혜택을 보기 위해 "상세 혜택" 버튼을 클릭한다. 크롬 드라이버에서 코드의 명령에 따라 click해준다.
# 페이지 소스 가져오기
page_source = driver.page_source
# BeautifulSoup을 사용하여 파싱
soup = BeautifulSoup(page_source, 'html.parser')
# 원하는 데이터 추출
title = soup.find('div', {'id':'tabCon010'}).get_text()클릭을 통해 새롭게 나타난 페이지에서 원하는 데이터를 추출한다.
동적 크롤링만으로 정보를 얻을 수 없는 카드사 사이트인 경우 위와 같이 Selenium을 이용해 원하는 데이터를 추출할 예정이다. csv파일에 저장하는 과정은 (1)과 같으므로 생략하겠다
3) AWS RDS에 연결해 크롤링한 데이터를 바로 저장
host_name = "[RDS 엔드포인트]"
username = "[rds username]"
password = "[rds password]"
database_name = "[데이터베이스 이름]"
db = pymysql.connect(
host=host_name,
port=3306,
user=username,
passwd=password,
db=database_name,
charset='utf8'
)이 코드를 실행하여 AWS의 RDS와 연결한다
cursor.execute("DROP DATABASE IF EXISTS once;")
db.commit()
cursor.execute("CREATE DATABASE itta DEFAULT CHARSET=utf8 COLLATE=utf8_bin;")
db.commit()
cursor.execute("USE once;")
db.commit()
cursor.execute("DROP TABLE IF EXISTS `CARD`;")
db.commit()
cursor.execute("""
CREATE TABLE `CARD` (
# 테이블 구성..
) DEFAULT CHARSET=utf8;
""")
db.commit()SQL문을 직접 입력하여 동작을 수행한다. 이 코드는 CARD 테이블을 생성한다.
이후 (1), (2)처럼 원하는 데이터를 추출하는 크롤링을 진행한다.
원하는 데이터들을 변수에 저장해둔 뒤,
cursor.execute()``db.commit()을 이용해 INSERT문을 실행하면 된다.
GPT 파인튜닝으로 카드 추천
- 파인튜닝이란?
사전 학습된 인공지능 모델의 가중치를 새로운 데이터에 맞게 세밀하게 조정하여 성능을 향상시키고 학습 시간을 줄이는 과정 (이미 배운 것을 기반으로 새로운 문제를 해결하는 과정)
인공지능 모델 활용 시 파인튜닝이 필요한 이유:
- 특정 도메인이나 작업에 최적화:
사전 학습된 인공지능 모델은 대규모 데이터셋으로 학습되어 일반적인 작업에 적합하지만, 특정 작업에 대한 성능이 제한적일 수 있기에, 파인튜닝으로 특정 작업에 맞게 조정해 성능을 향상시킨다.
- 자원 및 시간 절약:
사전 학습된 모델을 기반으로 파인튜닝하여, 작은 양의 데이터와 상대적으로 짧은 학습 시간으로도 좋은 성능을 얻을 수 있다.
- 새로운 데이터에 대한 적응: 모델이 새로운 데이터에 더 잘 적응하고, 그에 따른 예측이나 추론 성능이 향상된다.
- GPT란?
1) 개념
자동 회귀 언어 모델로 ChatGPT와 같은 생성형 AI 애플리케이션을 지원하는 인공 지능(AI) 분야의 발전을 보여주는 주요 모델
Transformer 아키텍처를 기반으로 구축된 신경망 기반 언어 예측 모델로, 프롬프트라는 자연어 쿼리를 분석하고 언어에 대한 이해를 바탕으로 가능한 최상의 응답을 예측
애플리케이션에서 인간과 유사한 텍스트 및 콘텐츠(이미지, 음악 등) 를 생성하고 대화형 방식으로 질문에 답할 수 있는 기능을 제공
업계 전반의 조직들이 Q&A 봇, 텍스트 요약, 콘텐츠 생성 및 검색에 GPT 모델 및 생성형 AI를 사용
2) 실습
GPT를 파이썬으로 실행시켜보자.
① OpenAI API 신청
OpenAI에 접속해 회원가입해준다. 여러 모델이 존재하고, 특징 및 가격이 다르니 사이트를 잘 참고하자.
API활용을 위해 Settings>Billing에 카드를 등록했다.
프로필 클릭 > Views API keys 나온 API key를 복사한다.
나온 API key를 복사한다.
② 파이썬 openai 모듈 설치
터미널에pip install openai를 입력해 openai 관련 패키지를 다운받는다.
③ 파이썬 코드 실행하기
GPT3.5를 지원해주는 text-davinci-003 모델을 사용해보자
import os import openai openai.api_key = "[API 키]" response = openai.Completion.create( model = "text-davinci-003", prompt = "my name is chaerin.\n\nQ: who am I?\nA:", temperature = 0, max_tokens=100, top_p = 1, frequency_penalty = 0.0, presence_penalty = 0.0, stop = ["\n"] ) print(response) print(response.choices[0].text.strip())
model: openai가 제공해주는 모델 중 사용할 모델의 이름
prompt: 원하는 실행어 입력 - 좋은 결과를 위해 많은 테스트 필요
max_tokens: 입력+출력 값으로 잡을 수 있는 최대 토큰 길이. 초과되면 에러가 난다 (한글은 토큰이 많이 쓰여 영어 위주로 사용할 예정)
stop: stop 지점을 설정한다. 여기서는 "\n"이다
결과는 다음과 같다. 내 이름을 알려준 뒤 내가 누군지 물었는데, 의도대로 내 이름을 답해준다.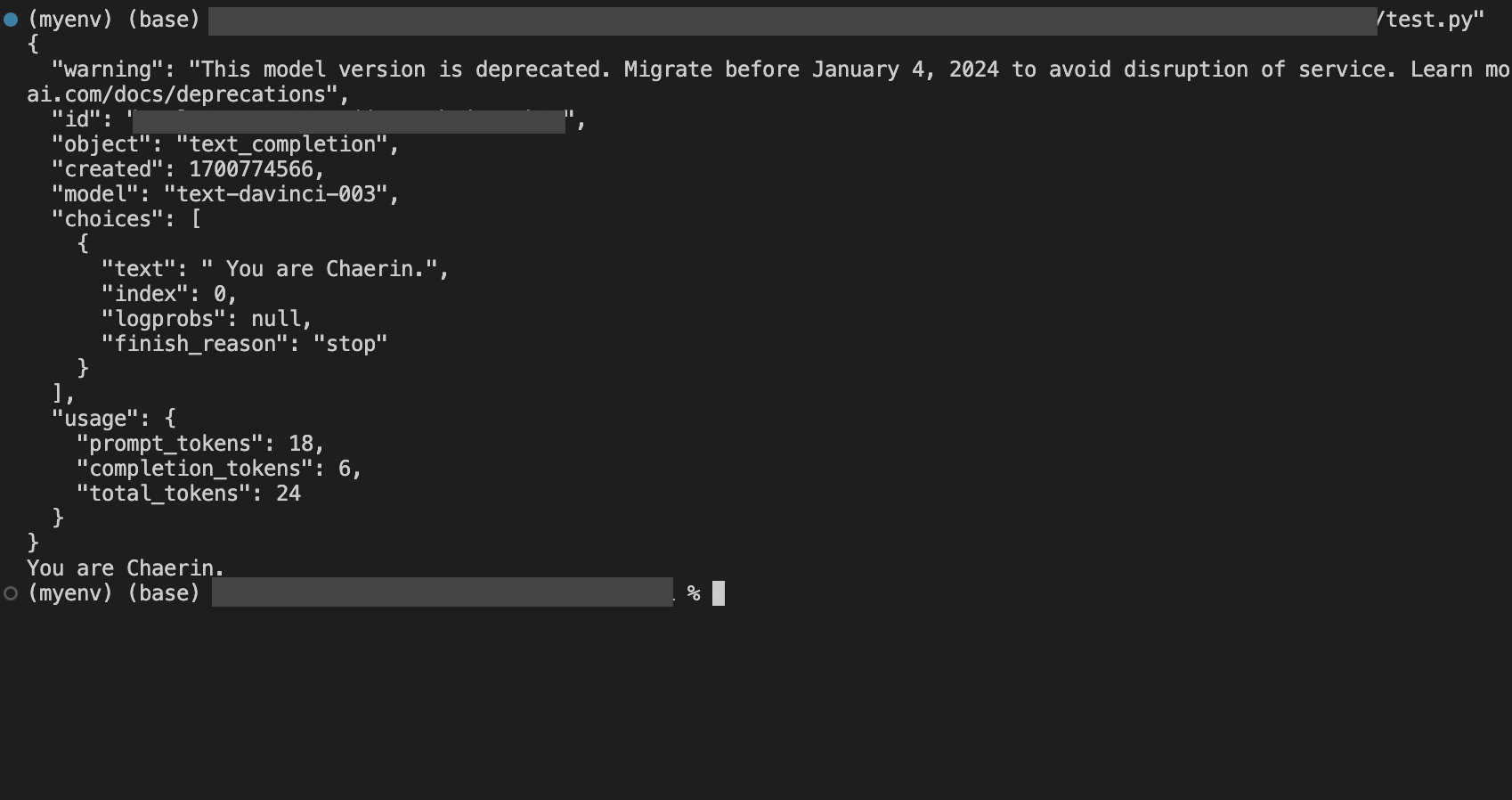
- GPT 파인튜닝이란?
GPT 3.5 "davinci-003"모델은 2021년까지의 데이터만 학습되어 있어, 2022년도에 대한 답을 하지 못한다. 또한 ChatGPT는 웹 페이지, 책, 기타 문서 등 방대한 양의 일반 텍스트 데이터로 학습하여 언어의 패턴과 구조를 학습한 상태이므로, 특정 주제에 대한 질문에 대한 텍스트를 생성할 때 최적의 성능을 발휘하지 못할 수 있다.
예를 들어 특정 제품이나 서비스에 대한 고객의 질문에 답변할 수 있는 챗봇을 만들려면 해당 제품이나 서비스에 대한 고객 문의 및 응답 데이터 세트에 대해 ChatGPT를 Fine-tuning 하여 해당 도메인에서 사용되는 언어의 패턴과 뉘앙스를 더 잘 이해하고 보다 관련성 있고 정확한 응답을 생성할 수 있다.
질문에 대한 답을 알려주기도 하고, 원하는 format으로 답이 나오도록 유도할 수 도 있다.
-
OpenAI의 Fine-tuning API 장점
1) 프롬프트 디자인보다 높은 품질의 결과
2) 프롬프트에 맞지 않는 예제를 학습할 수 있는 능력
3) 짧은 프롬프트로 인한 토큰 절약
4) 낮은 지연 요청 시간
파인튜닝은 프롬프트에 맞지 않는 예제를 포함한 훨씬 많은 예제로 학습함으로써 다양한 작업에서 더 나은 결과를 얻을 수 있다. 모델을 파인튜닝한 후에는 더 이상 프롬프트에서 예제를 제공할 필요가 없기에 비용을 절감하고 지연 시간이 낮은 요청이 가능하다. -
모델 별 파인튜닝 비용
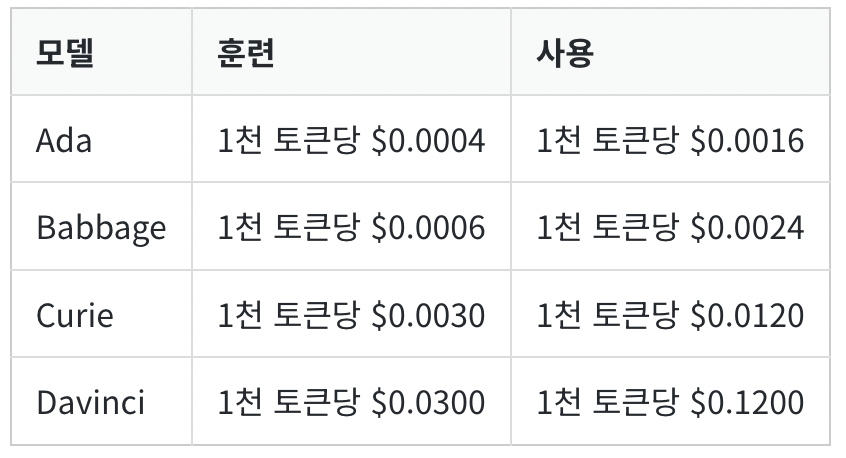
-
ONCE에서의 필요
GPT는 뛰어난 모델이지만, 카드 추천이라는 우리의 서비스에 적합하게 학습된 상태가 아니다.
따라서 우리가 질문할 예정인 문장과, 이에 원하는 대답의 형식을 정해주어 학습시킬 것이다.
또한 GPT는 모든 은행의 카드 혜택 정보를 가지고 있지 않으며, 더더욱이 2022 이후의 데이터는 알 수 없기 때문에 두번째 기술 크롤링을 통해 얻은 카드 및 혜택 정보들을 입력하여 우리의 서비스에 관련된 정확한 응답을 생성하도록 할 것이다. -
GPT 파인튜닝 과정
① 데이터 준비(format 맞추기)
모델을 파인튜닝하기 위한 데이터를 먼저 준비해야 한다.
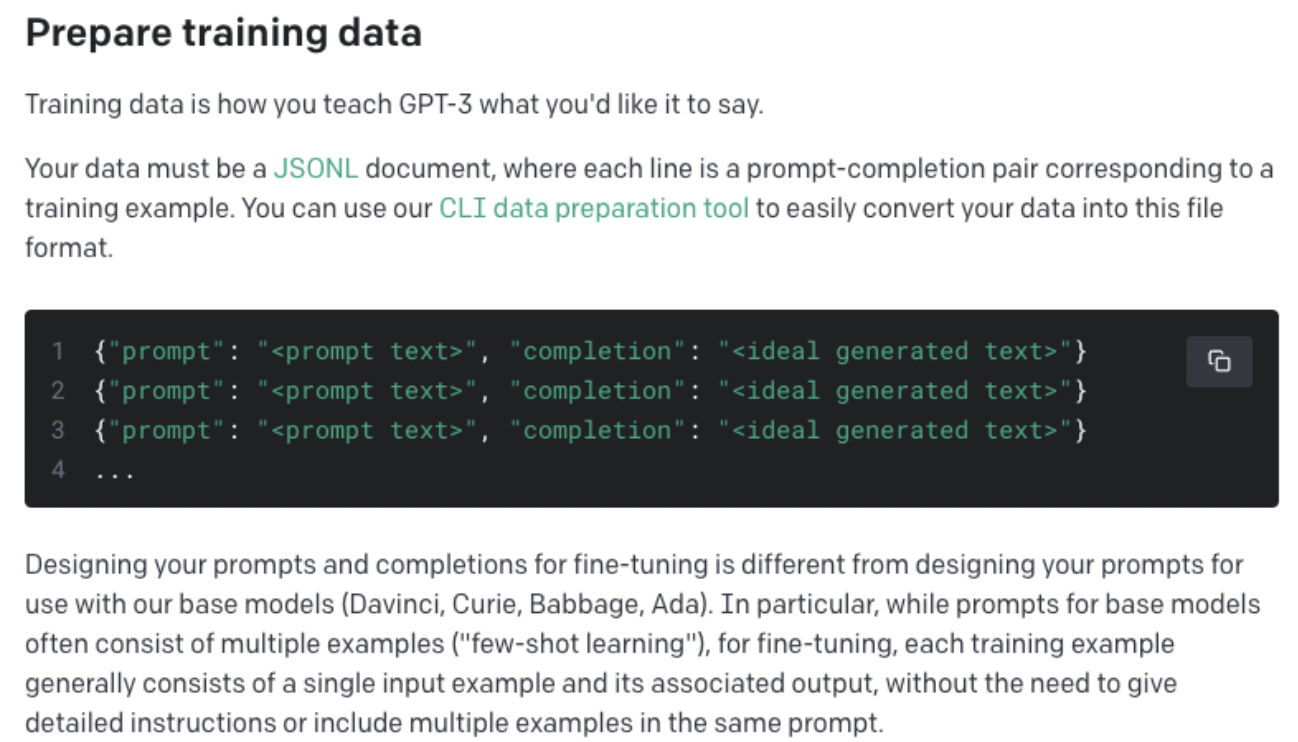
prompt(원하는 프롬프트)-completion(원하는 답 형태) 쌍으로 이루어진 JSON 형태의 데이터
단일 입력 예제와 해당하는 출력으로 구성
CLI 데이터 준비 도구로 Fine-tuning 할 수 있는 데이터 생성:
openai tools fine_tunes.prepare_data -f <로컬_파일>
② Fine-tuning 모델 생성
OpenAi에서 제공하는 base model을 활용 (ada, babbage, curie, davinci)
OpenAI CLI를 사용하여 파인튜닝 작업 시작
openai api fine_tunes.create -t <TRAIN_FILE_ID_OR_PATH> -m <BASE_MODEL>
ex. openai --api-key [YOUR_KEY] api fine_tunes.create -t example_prepared.jsonl -m davinci
이 코드의 작업:
- 파일을 파일 API를 사용하여 업로드 (또는 이미 업로드된 파일을 사용)
- 파인튜닝 작업을 생성
- 작업이 완료될 때까지 이벤트를 스트리밍 (보통 몇 분 소요, 대기 중인 작업이 많거나 데이터셋의 크기에 따라 몇 시간)# 추가 명령어들 # 생성된 모든 파인튜닝 작업 나열 openai api fine_tunes.list # 파인튜닝 상태 검색. 결과 객체에는 작업 상태 (대기 중, 실행 중, 완료 또는 실패 중 하나일 수 있음)와 기타 정보가 포함됩니다. openai api fine_tunes.get -i <YOUR_FINE_TUNE_JOB_ID> # 작업 취소 openai api fine_tunes.cancel -i <YOUR_FINE_TUNE_JOB_ID>
③ Fine-tuning 모델 사용
OpenAI 내 계정 정보 > Fine-tune training에 정보 추가됨, playground에서 확인 및 사용 가능
작업이 성공 시, fine_tuned_model 필드에 모델의 이름 저장됨
이 모델을 Completions API의 매개변수로 지정하여 Playground를 사용하여 요청 보내기 가능
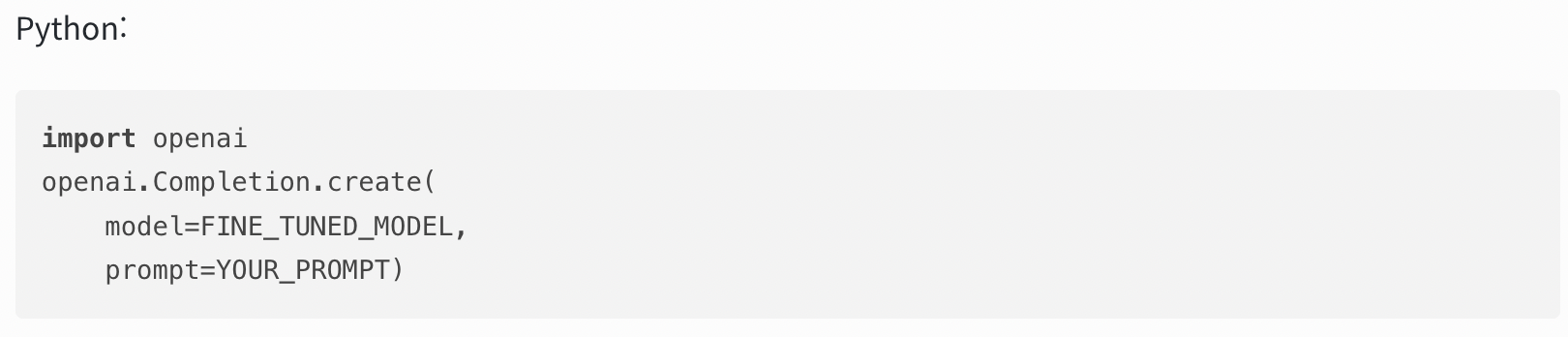
+ 파인튜닝된 모델 삭제
-
오버피팅과 언더피팅 대응 전략
데이터 추가 수집: 더 많은 데이터는 모델이 다양한 패턴을 학습하고 오버피팅의 위험을 줄이는 데 도움이 된다
데이터 증강: 백트랜스레이션과 유의어 대체와 같은 데이터 증강 기법을 사용하여 추가적인 훈련 예제를 생성하고 오버피팅을 줄일 수 있다
모델 단순화: 모델이 오버피팅되었다면, 모델의 크기나 복잡성을 줄이는 것을 고려하라
모델 복잡성 증가: 언더피팅이 문제라면, 데이터의 패턴을 파악하기 위해 더 복잡한 모델이 필요할 수 있다 -
파인튜닝 모델 평가
모든 인공지능 모델은 학습 및 테스트 후 모델이 학습한 내용을 얼마나 잘 일반화했는짖 명확하고 객관적으로 측정할 수 있어야 한다.
평가를 통해 모델이 세밀 조정 과정에서 실제로 유용한 내용을 학습했는지 아니면 훈련 데이터에만 과적합되었는지를 정량적으로 판단할 수 있다.
자연어 처리(NLP)에서 사용되는 일반적인 지표:
- 정밀도(Precision):
이 지표는 양성으로 예측한 사례 중 실제 양성인 경우의 비율로, "모델이 양성으로 예측한 사례 중 실제로 양성인 것이 얼마나 많은가?"라는 질문에 대답한다.
정밀도 = TP / (TP + FP) - 재현율(Recall, 민감도 또는 진양성 비율):
실제 양성 사례 중 모델이 정확하게 양성으로 예측한 경우의 비율로, "실제 양성 사례 중 모델이 얼마나 정확하게 양성으로 예측했는가?"라는 질문에 대답한다.
재현율 = TP / (TP + FN) - F1-Score:
F1-Score는 정밀도와 재현율의 조화 평균으로, 이 둘을 균형 있게 조합한다. 데이터에 클래스 불균형이 있는 경우 특히 유용하다.
F1-Score = 2 (정밀도 재현율) / (정밀도 + 재현율) - 정확도(Accuracy):
정확하게 예측한 사례의 비율로, 데이터의 클래스 불균형이 있는 경우에는 신뢰할 수 없는 지표이다. 다수 클래스의 사례가 소수 클래스의 사례보다 많은 경우에는 특히 그렇다.
정확도 = (TP + TN) / (TP + TN + FP + FN) - AUC-ROC (Receiver Operating Characteristic Curve의 면적):
모든 가능한 분류 임계값에서의 성능을 종합적으로 제공한다. 모델이 클래스를 구별할 수 있는 정도를 나타낸다.
- GPT 파인튜닝 실습
현재 감정을 표현하고 이름을 말하면 기분에 맞는 반응을 해주고, 이름을 다시 출력하도록 만들자
파인튜닝 전, 기존 "text-davinci-003"모델을 사용해 다음과 같은 입력을 주면
prompt = "Feel: Smile \nMSG:my name is Chaerin.\n ->",

이러한 결과가 나온다.
하지만 내가 원하는 형식대로 데이터를 만들어 보겠다.
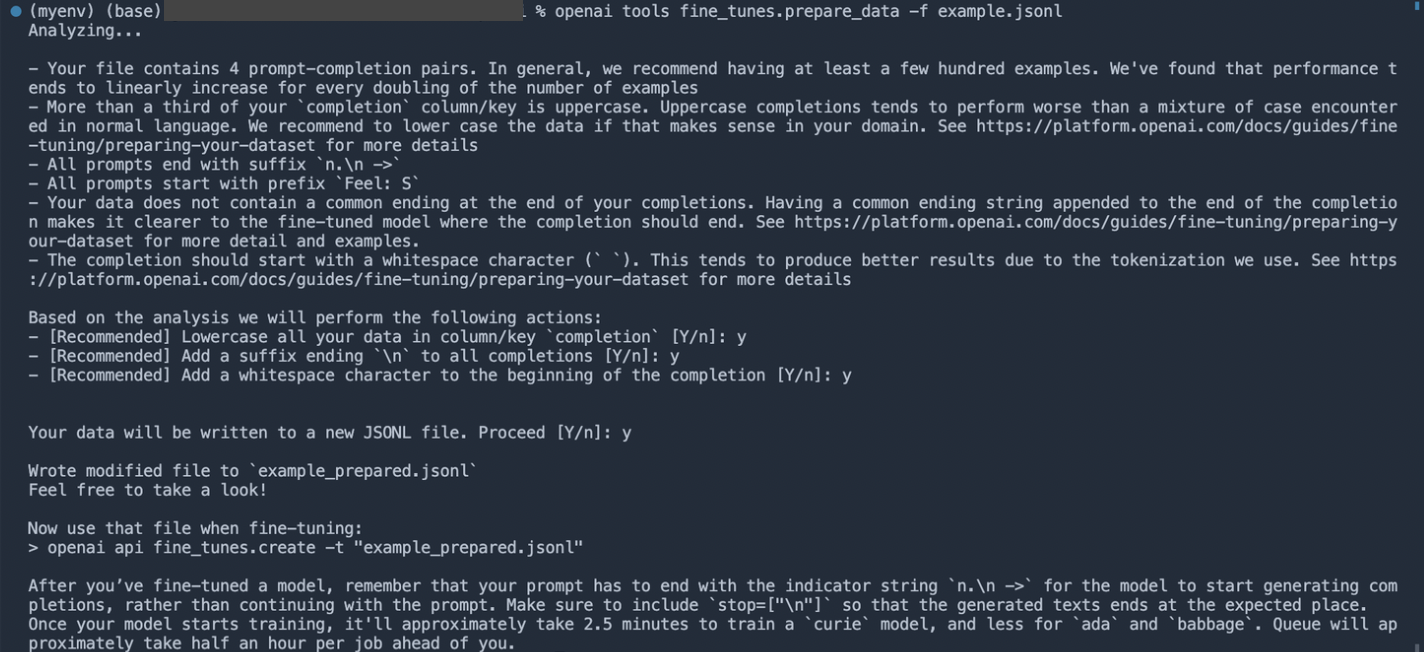 example_prepared.jsonl이 생성되었다.
example_prepared.jsonl이 생성되었다.

openai --api-key [API KEY] api fine_tunes.create -t example_prepared.jsonl -m ada
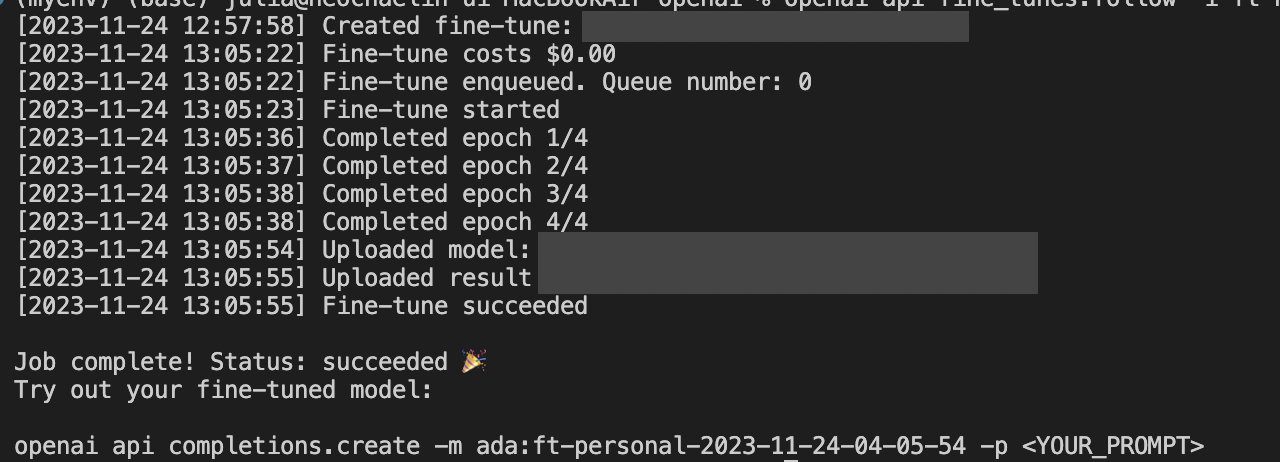 만들어진 모델을 이용해 prompt를 보내보았다.
만들어진 모델을 이용해 prompt를 보내보았다.
- ONCE에 GPT 파인튜닝 적용 방안
prompt와completion의 형식에서, 카드 추천을 위해 파인튜닝을 적용할 방법을 구상해 보았다.
1) 각 사용자가 가진 카드와 해당 카드의 혜택 정보를 원하는 결제처와 함께 입력하여 그 중 하나의 카드를 도출해낸다.
{”prompt” : “<결제처, [카드 1, 카드 1 상세 혜택, 카드 1 실적 충족 여부], ..., [카드 N, 카드 N 상세 혜택, 카드 N 실적 충족 여부]>”, “completion” : “<결제처에서 사용할 카드>”}
-> 각 사용자마자 파인튜닝을 진행해야 하므로 현실성이 떨어진다.
2) 한 카드의 혜택정보와 결제처를 입력하여 해당 결제처에서 받을 수 있는 하나의 혜택 항목만을 뽑아낸다. 사용자가 보유한 모든 카드에 대한 혜택 추출이 완료되면, 이 결과들을 비교해 최적의 카드를 찾는다.
GPT 모델 1 :{”prompt” : “<결제처, 카드명, 그 카드의 혜택, 실적 조건>”, “completion” : “<결제처에서 해당 카드로 누릴 수 있는 혜택(실적 채운 경우와 채우지 못한 경우 나눠서)>”}
→ [결제처, 카드명, 카드의 혜택]을 보고 누릴 수 있는 혜택을 찾아주는 역할
GPT 모델 2 : 모델 1에서 나온 결과들을 비교하여 가장 최대 혜택을 제공하는 카드 선택
{”prompt” : “<[결제처 A, 카드명1, 결제처에서 해당 카드로 누릴 수 있는 혜택1], ... , [결제처 A, 카드명N, 결제처에서 해당 카드로 누릴 수 있는 혜택N]>”, “completion” : “<결제처, 사용할 카드, 그 카드의 혜택>”}
→ 직접 사용자가 [결제처]를 입력했을 때, [사용할 카드]를 출력
3) Chat Completion을 이용해 사용자가 가진 카드의 정보들을 GPT에게 준 다음, 결제처를 입력해 하나의 최선의 카드를 출력하도록 한다.
Chat Completion: openai로 요청을 보낼 때 과거의 대화 기록을 포함하게 한다(원래 openai는 과거 요청을 기억x)
- user 메시지 : 사용자의 질문이나 설명
- assistant 메시지 : 이전 assistant 메시지(openai 응답)을 저장, 사용자가 원하는 동작의 예를 제공하기 위해 작성하기도
"user": "A카드, B카드, D카드의 혜택이 뭐야?",
"assistant": "A카드 혜택: [A 카드 혜택 정보],B카드 혜택: [B 카드 혜택 정보],C카드 혜택: [C 카드 혜택 정보]"
"user": "GS25에서 10000원 결제하려면 이 중 어느 카드를 쓸까?"
이와 같은 형식으로, user의 질문에 대한 GPT의 답변을 지정해주어 카드의 혜택을 GPT가 파악하도록 하고, 결제처 입력을 통해 이 중 사용할 카드를 출력하도록 한다.
여기서 카드 목록, 카드별 헤택 정보, 결제처는 백엔드 파트에서 입력받은 입력들을 알맞은 자리에 대입하여 완성한다.
파인 튜닝 관련 자문 및 조사를 통해 3번의 방식대로 파인 튜닝을 진행하기로 하였다.
크롤링한 정보를 어떤 형식으로 넘길지를 포함하여 input과 output의 형식에 따라 GPT의 답변과 정확도가 달라질 것이다. 이를 모두 고려해 test해보며, 최고의 서비스를 구현해보자

안녕하세요 혹시 실제 codef API 사용까지로 이어졌나요? 금액이 얼마정도 나왔는지 궁금합니다.