1. 단일 도메인 내의 이동
최소한의 클릭수를 찾기
원하는 정보들의 공통점 찾기
ex url중 /wiki/로 시작, id=bodyContent인 div안에 존재, 콜론이 포함x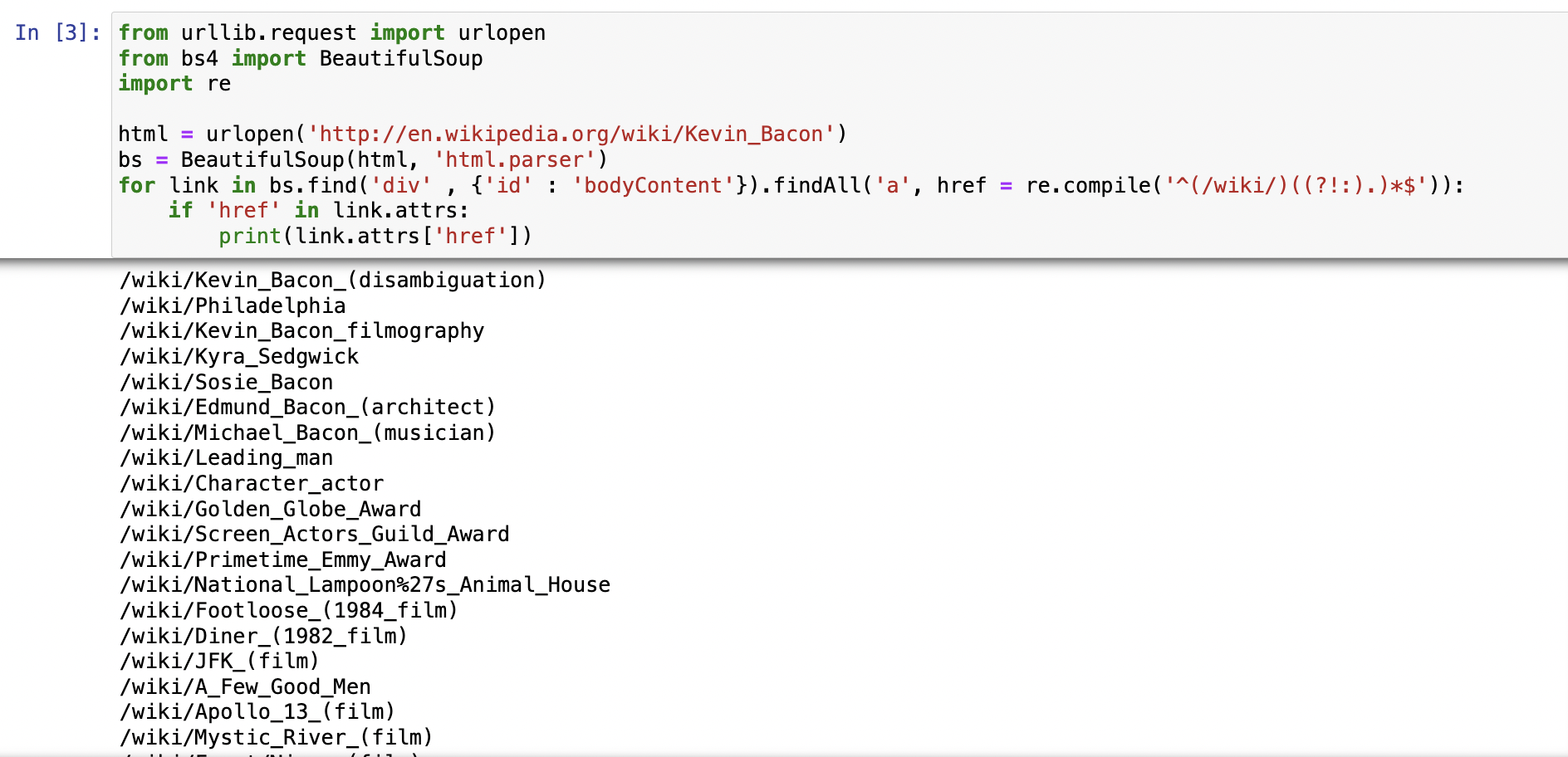
-> getLinks함수로 정의해 사용

2. 전체 사이트 크롤링
사이트맵 생성
데이터 수집
파이썬을 재귀 호출을 1000회로 제한
같은 페이지를 두번 크롤링 하지 않기 위해 이전 getLinks()예제에서 if link.attrs['href'] not in pages: 추가
전체 사이트에서 데이터 수집
페이지 패턴 찾기
- 제목은 항상 h1태그 안에
- 모든 바디 텍스트는 div#bodyContent태그
- 편집 링크는 항목 페이지에만 존재 li#ca-edit -> span -> a
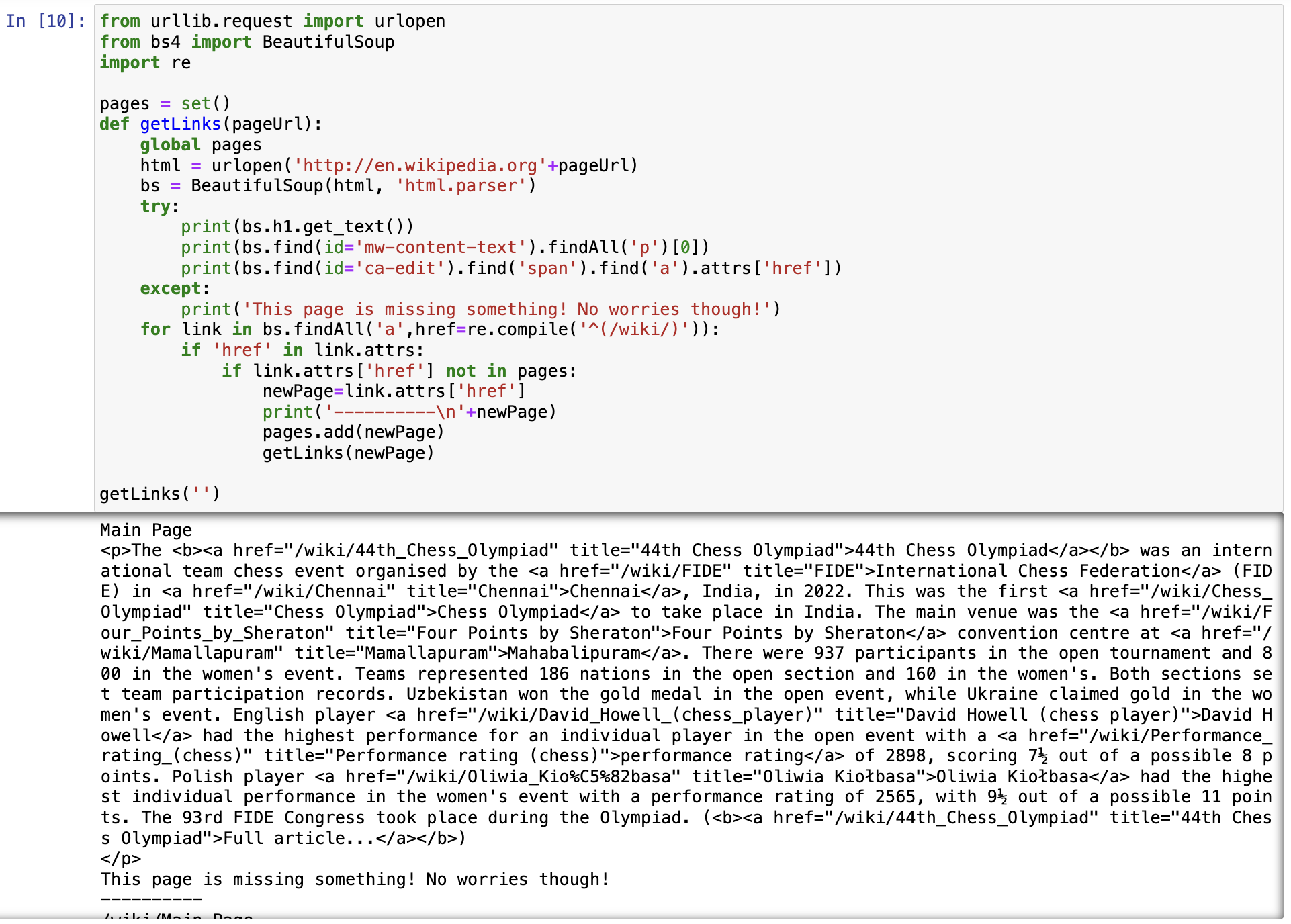
print문으로 값이 있는지 확인, 존재 확률 높은 순서대로
예외 핸들러 안에 여러 행 넣는것은 위험
(출력한거지 수집은 6장)
3. 인터넷 크롤링
from urllib.request import urlopen
from urllib.parse import urlparse
from bs4 import BeautifulSoup
import re
import datetime
import random
pages = set()
random.seed(datetime.datetime.now())
# 페이지에서 발견된 내부링크를 모두 목록으로
def getInternalLinks(bs, includeUrl):
includeUrl = '{}://{}'.format(urlparse(includeUrl).scheme, urlparse(includeUrl).netloc)
internalLinks = []
#Finds all links that begin with a "/"
for link in bs.find_all('a', href=re.compile('^(/|.*'+includeUrl+')')):
if link.attrs['href'] is not None:
if link.attrs['href'] not in internalLinks:
if(link.attrs['href'].startswith('/')):
internalLinks.append(includeUrl+link.attrs['href'])
else:
internalLinks.append(link.attrs['href'])
return internalLinks
# 페이지에서 발견된 외부 링크를 모두 목록으로
def getExternalLinks(bs, excludeUrl):
externalLinks = []
#Finds all links that start with "http" that do
#not contain the current URL
for link in bs.find_all('a', href=re.compile('^(http|www)((?!'+excludeUrl+').)*$')):
if link.attrs['href'] is not None:
if link.attrs['href'] not in externalLinks:
externalLinks.append(link.attrs['href'])
return externalLinks
def getRandomExternalLink(startingPage):
html = urlopen(startingPage)
bs = BeautifulSoup(html, 'html.parser')
externalLinks = getExternalLinks(bs, urlparse(startingPage).netloc)
if len(externalLinks) == 0:
print('No external links, looking around the site for one')
domain = '{}://{}'.format(urlparse(startingPage).scheme, urlparse(startingPage).netloc)
internalLinks = getInternalLinks(bs, domain)
return getRandomExternalLink(internalLinks[random.randint(0,
len(internalLinks)-1)])
else:
return externalLinks[random.randint(0, len(externalLinks)-1)]
def followExternalOnly(startingSite):
externalLink = getRandomExternalLink(startingSite)
print('Random external link is: {}'.format(externalLink))
followExternalOnly(externalLink)
followExternalOnly('http://oreilly.com')
http://oreilly.com에서 시작해 외부 링크에서 외부링크로 무작위 이동
