판다스: 데이터 처리를 위한 라이브러리
행과 열로 이뤄진 2차원 데이터를 효율적으로 가공/처리하는 다양한 기능 제공
넘파이보다 유연하고 편리하게 데이터 핸들링(넘파이는 저수준 api가 대부분)
csv, tab과 같은 다양한 유형의 분리 문자로 칼럼을 분리한 파일을 손쉽게 DataFrame으로 로딩
주요 객체 :
DataFrame: 여러개의 행과 열로 이뤄진 2차원 데이터를 담는 데이터 구조체 (칼럼이 여러개)
Index: rdbms의 pk처럼 개별 데이터를 고유하게 식별하는 Key값
Series: 칼럼이 하나뿐인 데이터 구조체
판다스 시작 - 파일을 DataFrame으로 로딩, 기본 API
import pandas as pd pd로 alias해 import하는 것이 관례
Kaggle의 타이타닉 탑승자 파일 다운로드
- 캐글에 로그인
- https://www.kaggle.com/competitions/titanic/data

- 주피터 노트북 디렉터리로 titanic_train.csv파일명으로 저장
맨 윗줄은 칼럼명, 각 필드는 콤마로 분리
read_csv(): csv파일(칼럼을 ','로 구분) 포맷 변환을 위한 api
csv뿐만 아니라 어떤 필드구분문자 기반의 파일 포맷도 DataFrame으로 변환 가능
인자 sep에 해당 구분문자 입력 (default 콤마)
인자 filepath에 로드하려는 데이터 파일 경로를 포함한 파일명 입력
read_table(): 탭('\t')으로 필드를 구분
read_fwf(): Fixed Width, 고정길이 기반의 칼럼 포맷을 DataFrame으로 로딩하기 위한 API
.read_csv()
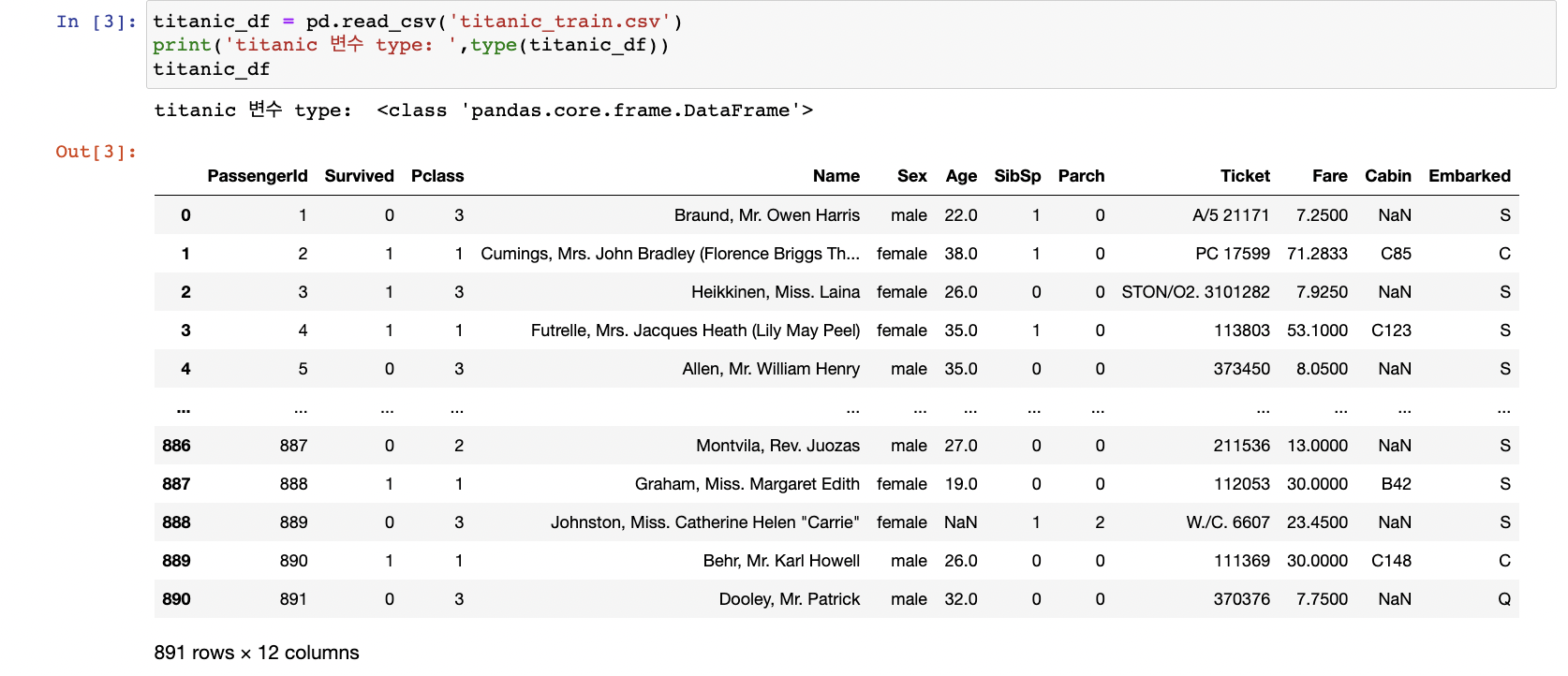 데이터파일 첫줄의 칼럼문자열이 DataFrame의 칼럼으로 할당
데이터파일 첫줄의 칼럼문자열이 DataFrame의 칼럼으로 할당
별다른 파라미터 지정 없으면 맨 처음 로우를 칼럼명으로 인지 후 변환
맨 왼쪽의 0,1,2 ...의 데이터값: Index
.head()
DataFrame.head(n): 맨 앞 n개의 로우 반환 (default 5개)
.shape
DataFrame.shape: 행과 열을 튜플 형태로 반환
DataFrame.info(): 총 데이터 건수, 데이터 타입, Null건수 조회 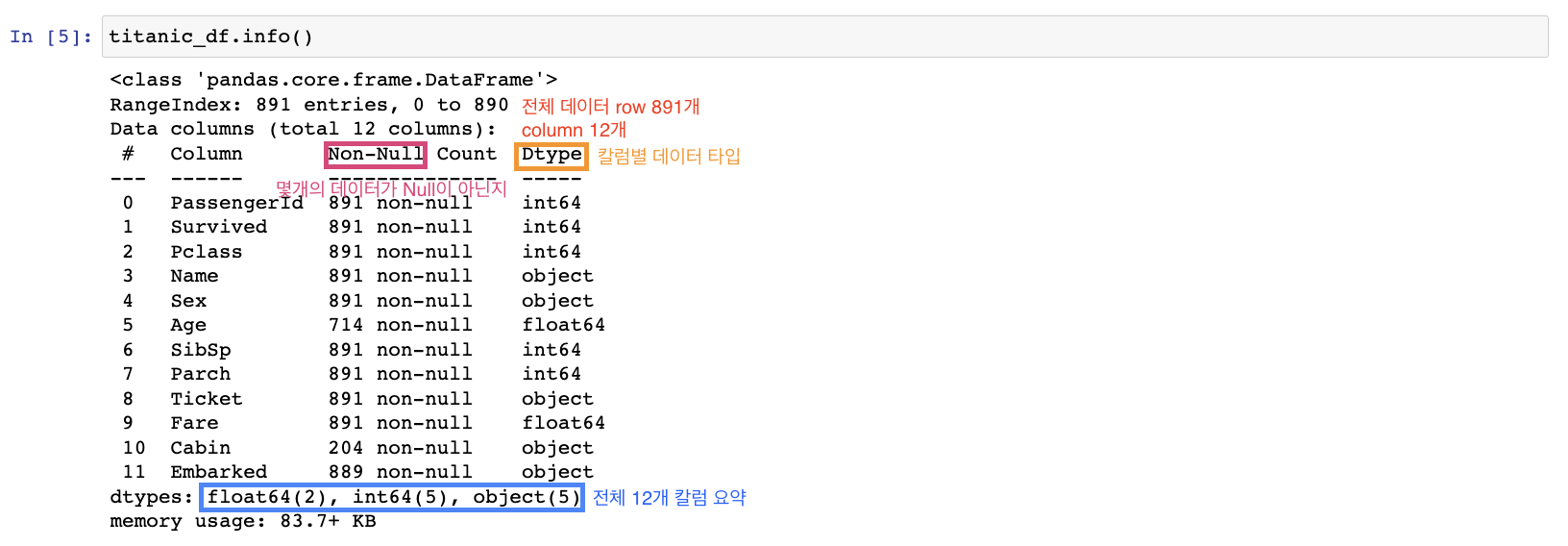
.describe()
describe(): 칼럼별 숫자형 데이터값의 n-percentile분포도, 평균값, 최댓값, 최솟값
오직 숫자형 칼럼의 분포도만 조사(object(문자열)은 제외)
(회귀에서 결정 값이 정규분포가 아니라 이상치가 많으면 예측성능 저하->개략적 분포도 확인 가능)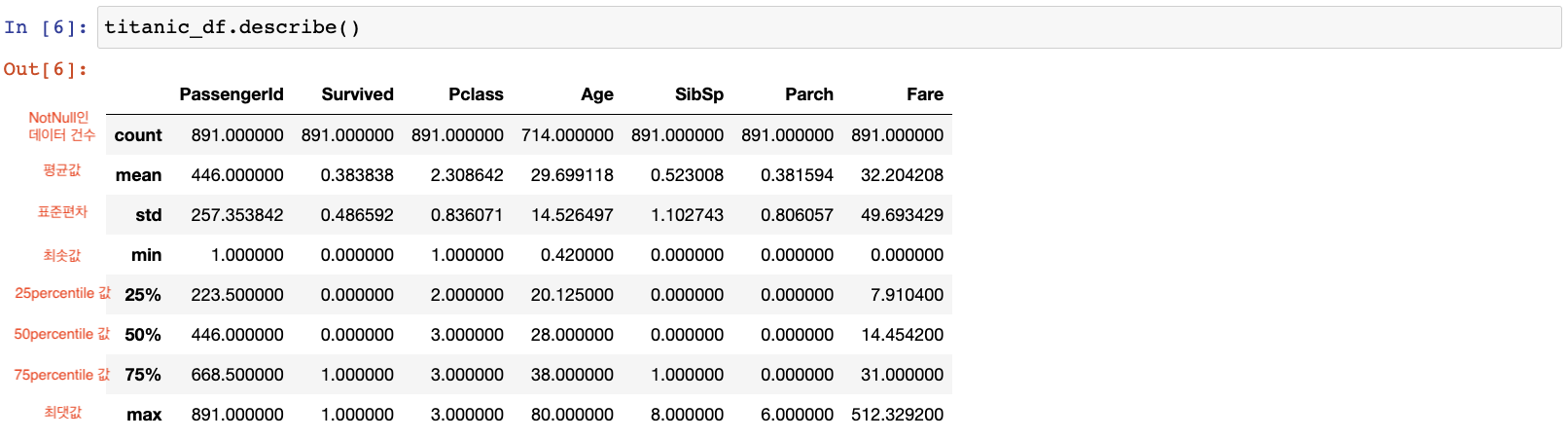
카테고리 칼럼: 특정 범주에 속하는 값을 코드화 한 칼럼 ex 남 1 / 여 2
describe로 확인 가능
survived: min 0, 25~75% 0, max 1 -> 0과 1로 이뤄진 숫자형 카테고리 칼럼
Pclass: min 1, 25~75% 2와3, max 3 -> 1,2,3으로 이뤄진 숫자형 카테고리 칼럼
DataFrame의 [ ]안에 칼럼명 입력하면 Series형태로 특정 칼럼 데이터 세트 반환
많은 건수 순서로 정렬
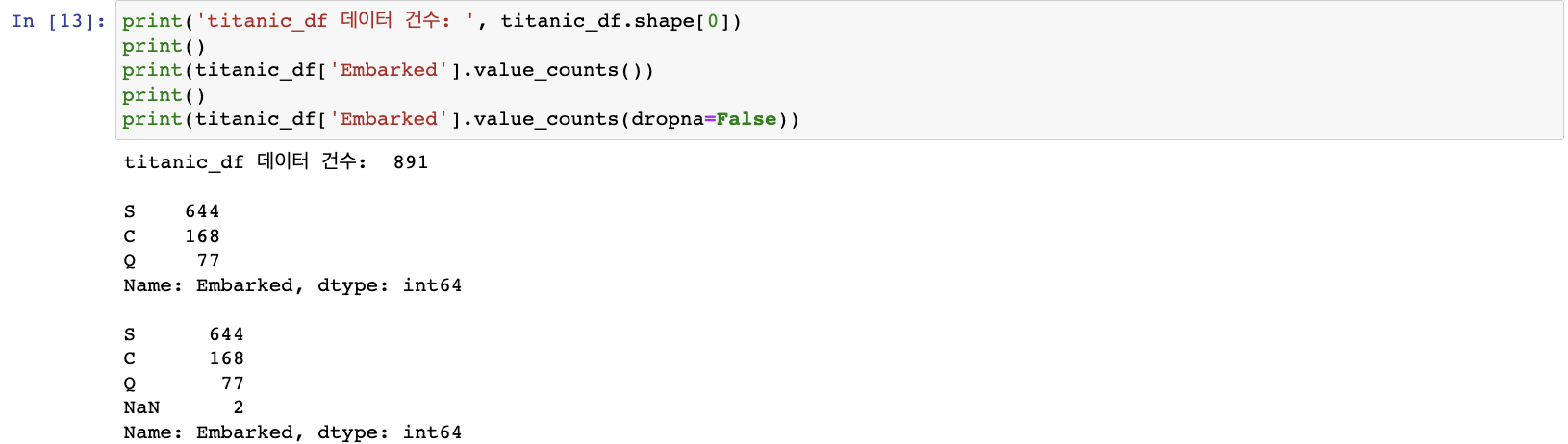
.value_counts()
Series객체.value_counts(): 해당 칼럼값의 유형과 건수를 확인 가능, 데이터 분포도 확인에 유용
Series: Index와 단 하나의 칼럼으로 구성된 데이터 세트
판다스 1.1.0 이후부터 DataFrame객체도 .value_counts()호출 가능 Index에 단순 순차 값이 아닌 고유성이 보장되는 의미있는 데이터 값 할당도 가능
Index에 단순 순차 값이 아닌 고유성이 보장되는 의미있는 데이터 값 할당도 가능
Index DataFrame, Series만들어진 후에 변경 가능
고유성이 보장된다면 문자열도 가능
dropna인자로 Null값 포함하여 데이터값 건수 계산할지말지 판단 (default True(Null 무시))
DataFrame과 리스트, 딕셔너리, 넘파이 ndarray 상호 변환
넘파이 ndarray,리스트, 딕셔너리를 DataFrame으로 변환하기
DataFrame은 칼럼명을 가짐->DataFrame로 변환 시 칼럼명 지정, 2차원 이하의 데이터만 변환가능
생성인자 data: 리스트·딕셔너리·ndarray 입력
생성인자 columns: 칼럼명 리스트 입력
1차원 리스트, 넘파이 ndarray -> DataFrame
칼럼명 하나만 필요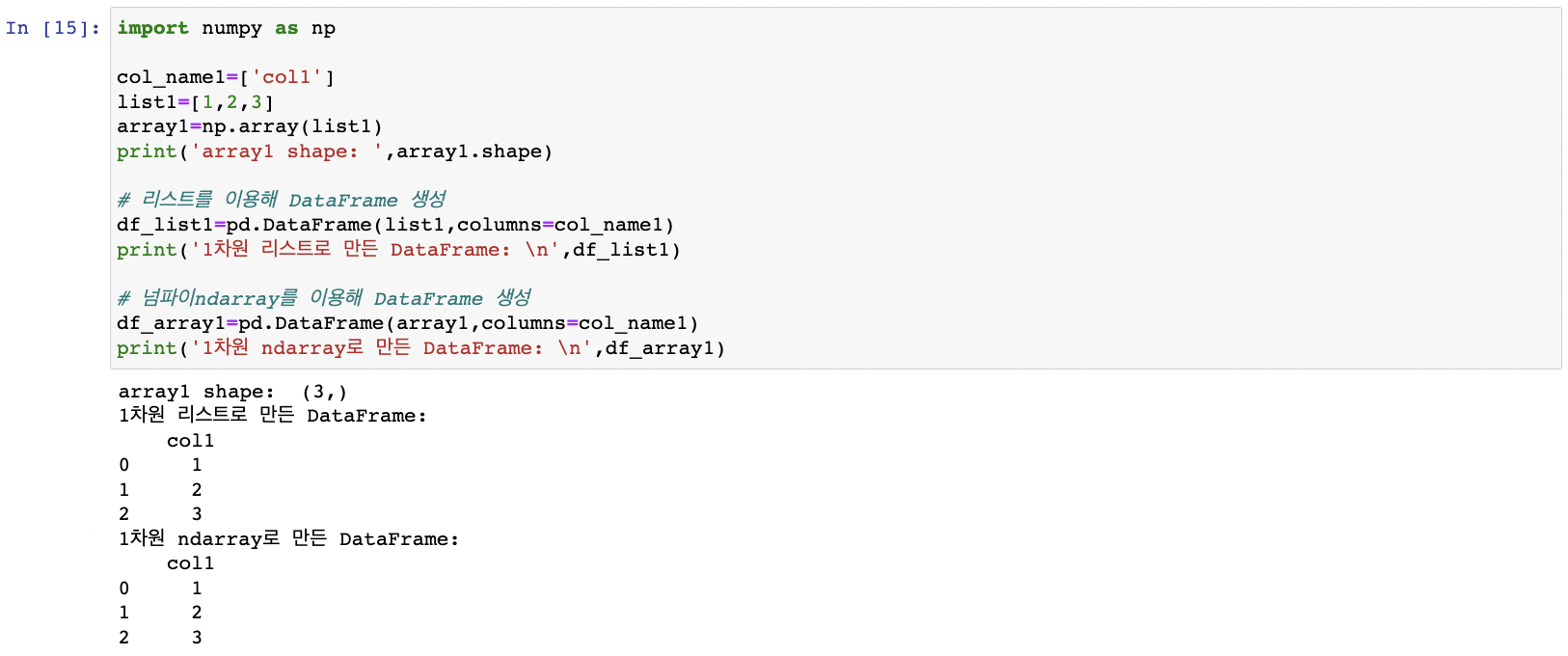
2차원 리스트, 넘파이 ndarray -> DataFrame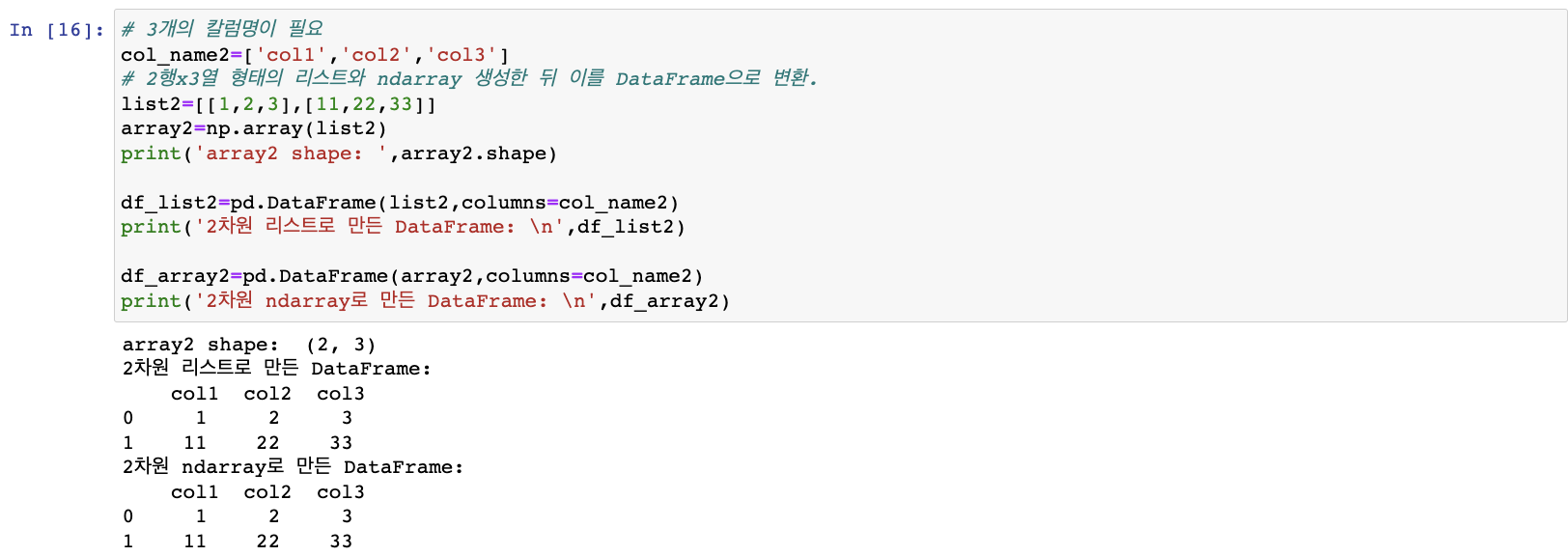
딕셔너리 -> DataFrame
딕셔너리 Key -> 칼럼명 (문자열)
딕셔너리 Value -> 칼럼 데이터 (리스트·ndarray)
DataFrame을 넘파이 ndarray,리스트, 딕셔너리로 변환하기
데이터 핸들링은 DataFrame이용해도 종종 머신러닝패키지의 입력 인자 등에 적용 위해 넘파이ndarray로 변환필요
DataFrame -> 넘파이 ndarray
.values

DataFrame -> 리스트, 딕셔너리
리스트: values로 얻은 ndarray에tolist() 호출
딕셔너리: DataFrame객체에 to_dict() 호출
인자 list -> 딕셔너리값이 리스트형으로 반환

DataFrame의 칼럼 데이터 세트 생성과 수정
[ ] 연산자 사용해 DataFrame의 칼럼데이터 세트 생성 수정
Titanic DataFrame의 새로운 칼럼 Age_0을 추가하고 일괄적으로 0 할당
DataFrame []내에 새로운 칼럼 입력 후 값 할당하면 됨
기존 칼럼 Series의 데이터를 이용해 새로운 칼럼 Series 생성
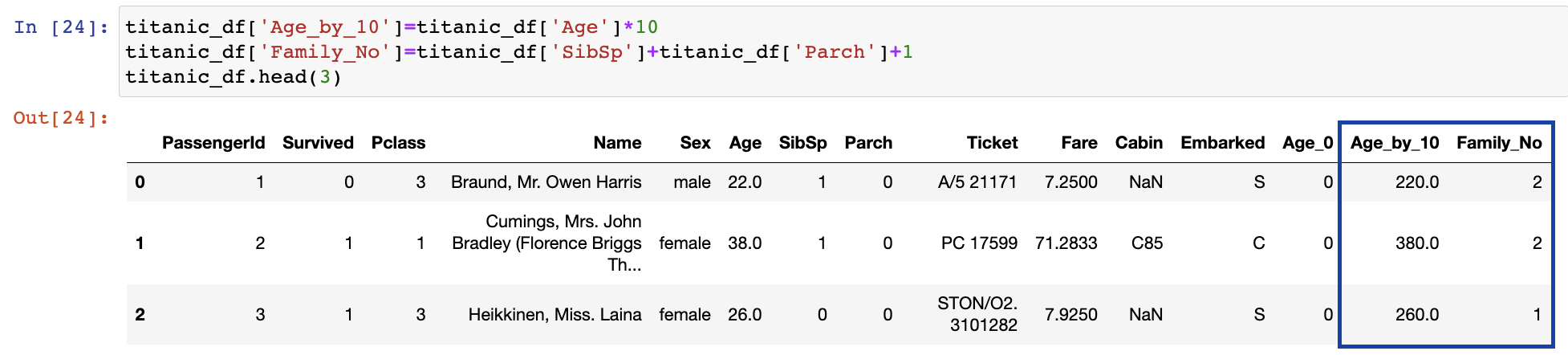
기존 칼럼값 일괄적으로 업데이트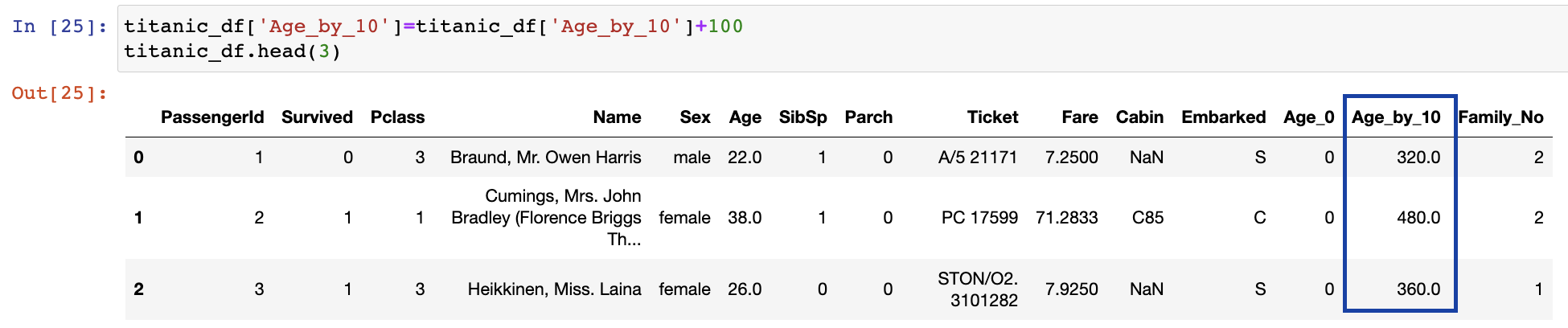
DataFrame 데이터 삭제
drop() 메서드로 데이터 삭제
DataFrame.drop(labels=None, axis=0, index=None, columns=None, level=None, inplace=False, errors='raise')
axis: 0->로우 방향 축(이상치제거), 1->칼럼 방향 축(주로 사용)
labels: 원하는 칼럼명
ex 지난 예제의 Age_0칼럼 삭제
inplace: 자기자신의 DataFrame의 데이터 삭제여부
False(default) - 자기자신데이터 유지, 삭제된 결과 반환
True - 자기자신데이터 삭제, 반환값 X None
 원본 데이터에 'Age_0'존재
원본 데이터에 'Age_0'존재
여러 칼럼 삭제하려면 리스트 형태의 칼럼명 입력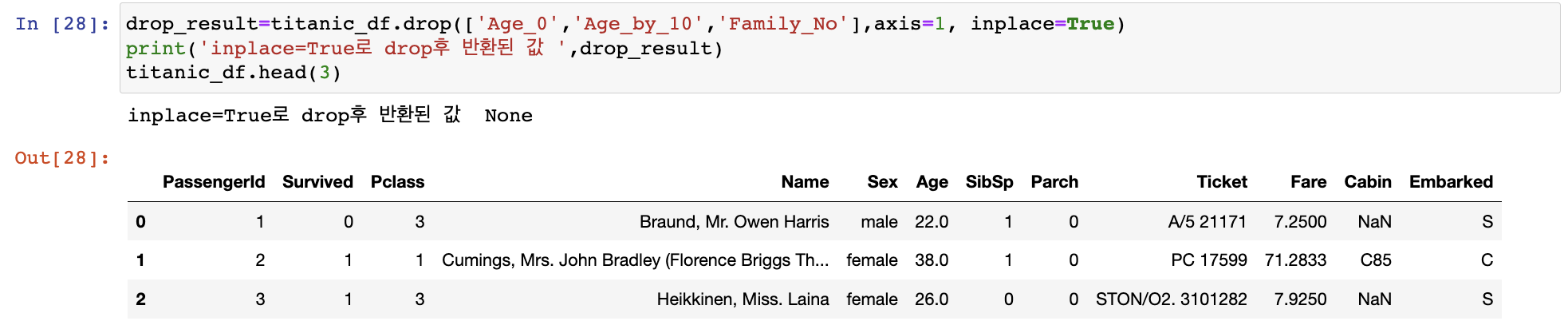
drop_result=titanic_df.drop(['Age_0','Age_by_10','Family_No'],axis=1, inplace=True)
== titanic_df=titanic_df.drop(['Age_0','Age_by_10','Family_No'],axis=1, inplace=False)
로우 삭제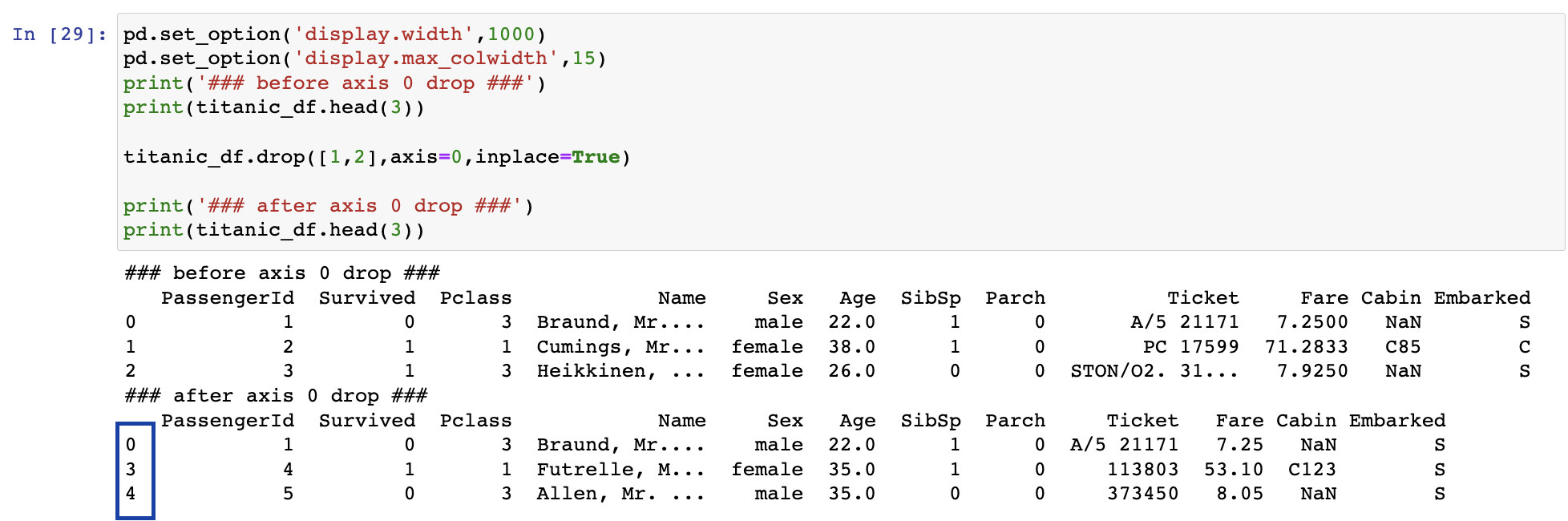
Index 객체
.index: DataFrame,Series의 인덱스 객체만 추출 -> 1차원 array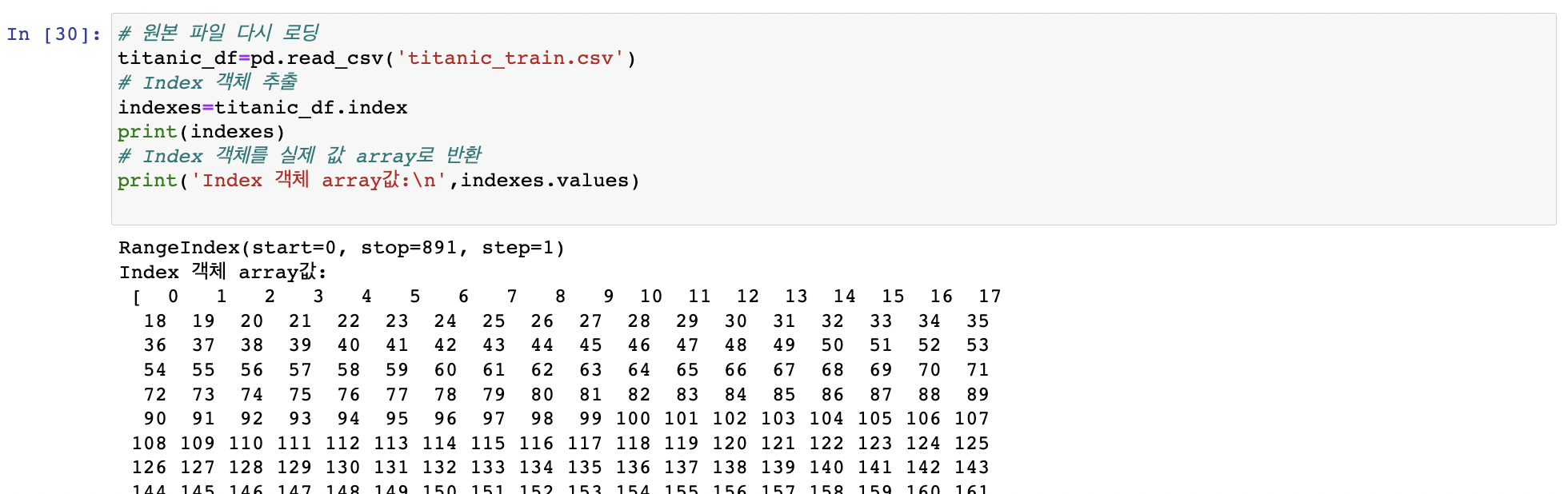 ndarray와 유사하게 단일 값 반환, 슬라이싱 가능
ndarray와 유사하게 단일 값 반환, 슬라이싱 가능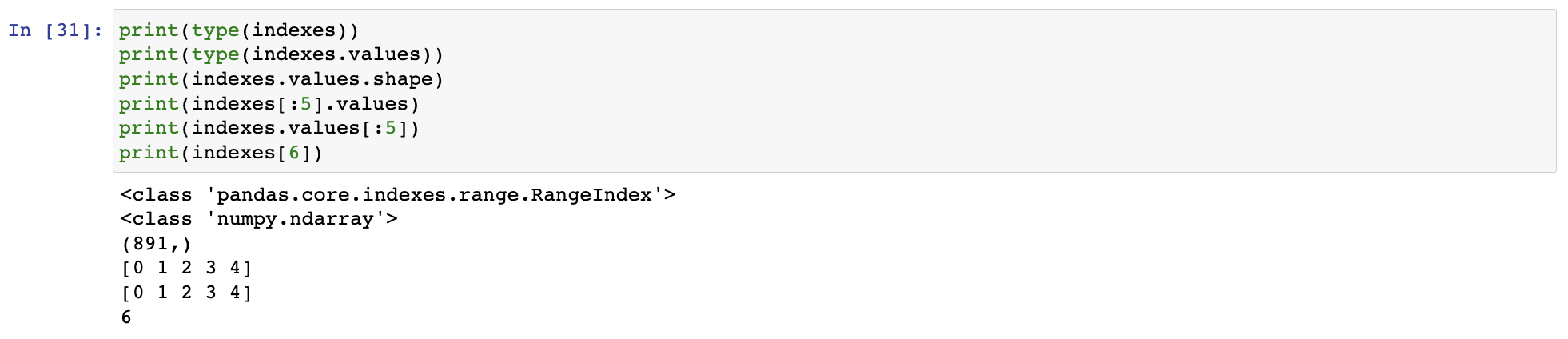 값 변경은 불가
값 변경은 불가 Series에 index가 포함되지만 Series에 연산 함수를 적용할땐 Index는 연산에서 제외. Index는 오직 식별용
Series에 index가 포함되지만 Series에 연산 함수를 적용할땐 Index는 연산에서 제외. Index는 오직 식별용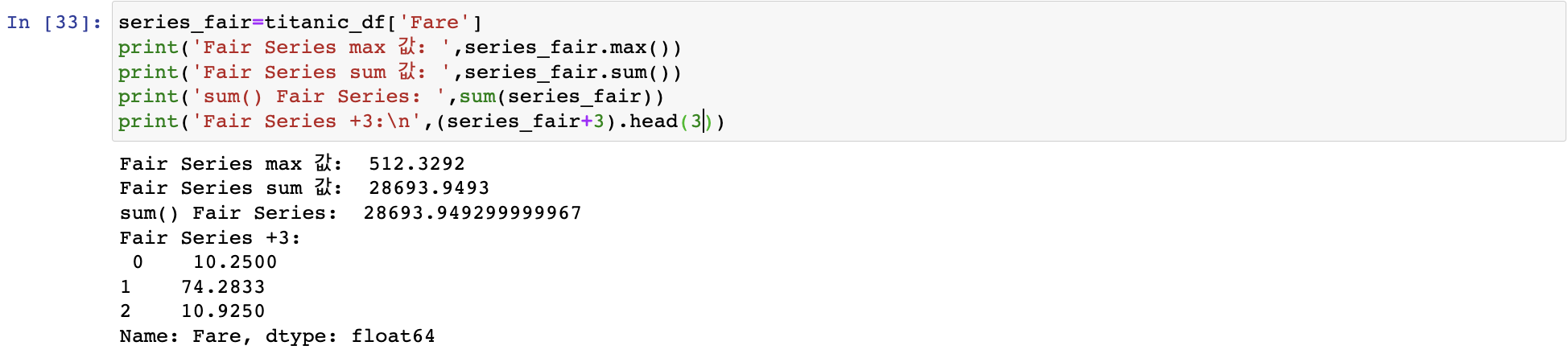
reset_index(): 새롭게 인덱스를 연속 숫자 형으로 할당. 기존 인덱스는 index라는 새로운 칼럼명으로 추가
인덱스가 연속된 int숫자형이 아닐 경우 주로 사용
Series에 reser_index() 적용하면 Series아닌 DataFrame 반환 ex Pclass value_counts() 수행 -> Pclass 고유값이 식별자 인덱스 역할 => 인덱스 다시 생성
ex Pclass value_counts() 수행 -> Pclass 고유값이 식별자 인덱스 역할 => 인덱스 다시 생성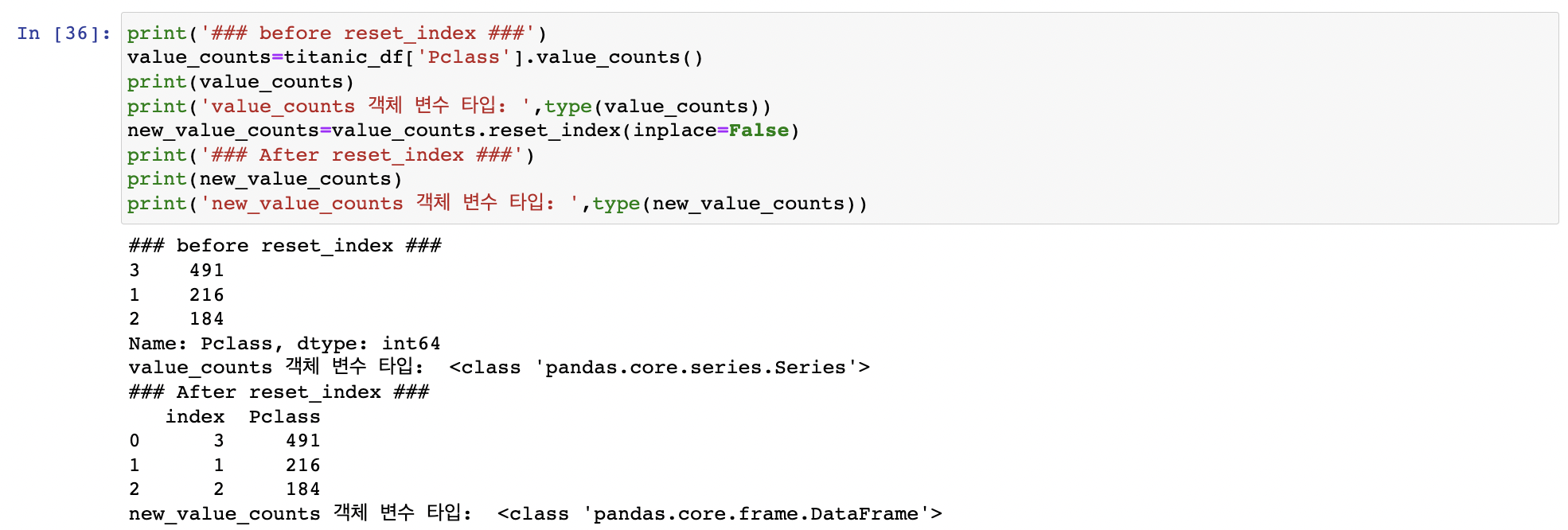
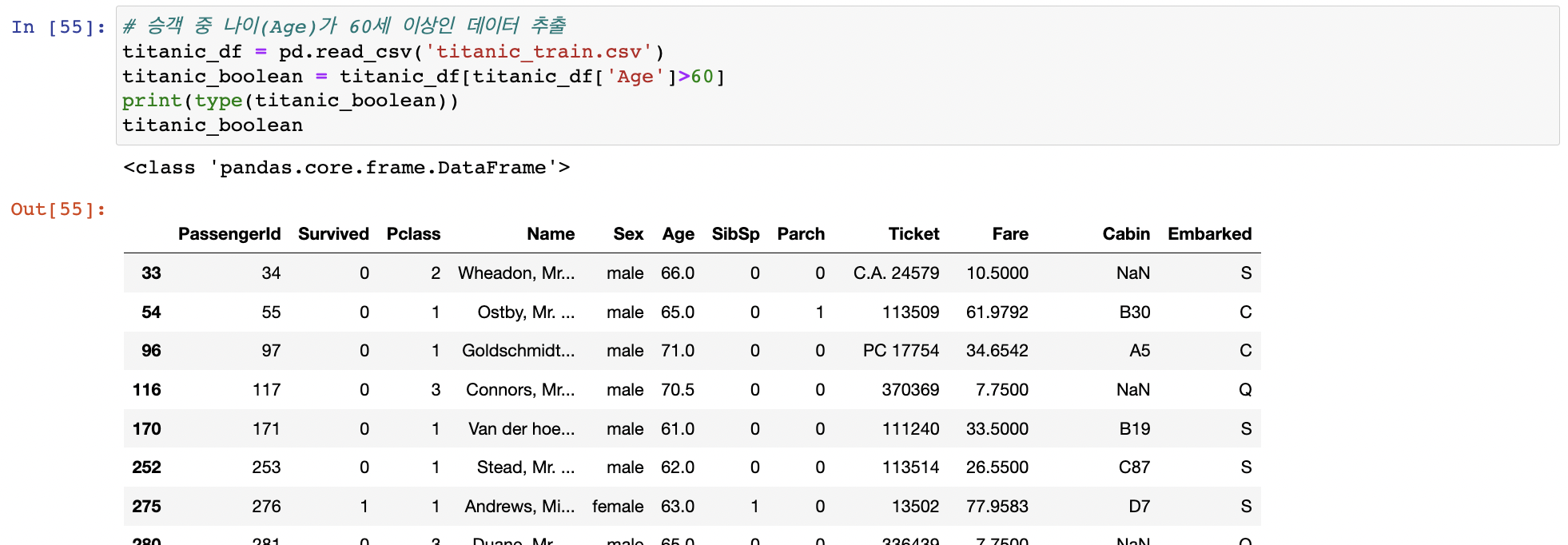
데이터 셀렉션 및 필터링 11
넘파이는 [ ] 연산자 내 단일 값 추출, 슬라이싱, 챈시 인덱싱, 불린인덱싱으로 데이터 추출
판다스의[]연산자는 넘파이랑 어떤차이가 있을까
DataFrame의 [ ] 연산자
[ ]안에 들어갈 수 있는 것은 칼럼명 문자 or 인덱스로 변환 가능한 표현식
[칼럼명], [칼럼명 리스트] O / [0] X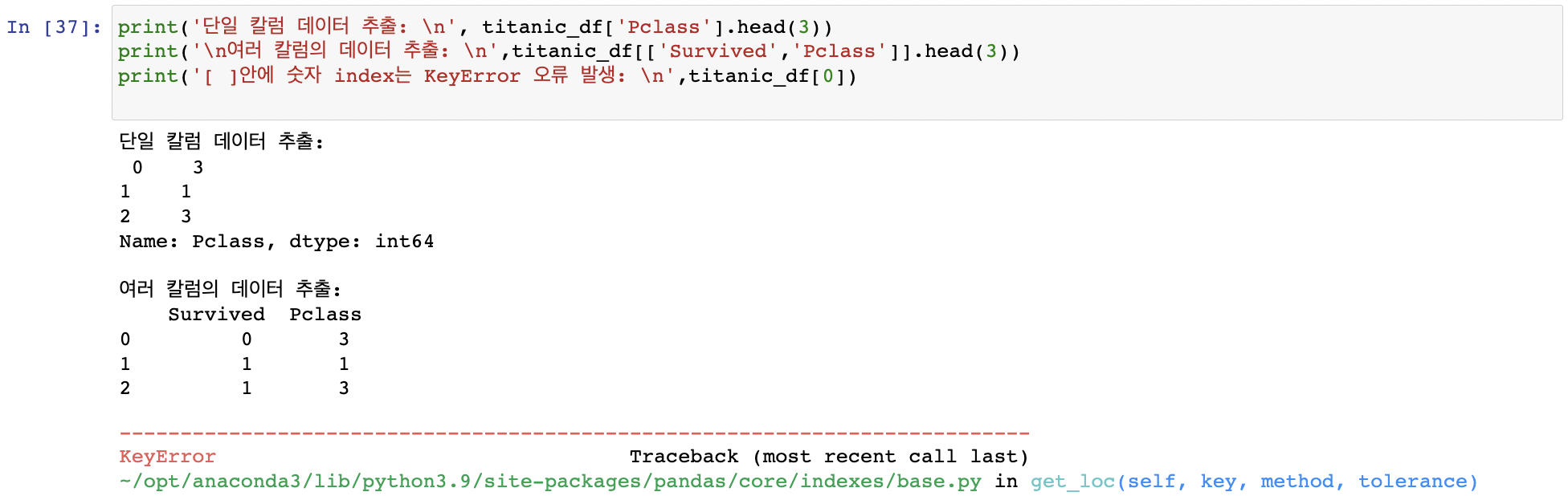 인덱스로 변환 가능한 표현식- [0:2]같은 슬라이싱 이용가능 (추천X)
인덱스로 변환 가능한 표현식- [0:2]같은 슬라이싱 이용가능 (추천X) 불린인덱싱 표현도 가능
불린인덱싱 표현도 가능
DataFrame iloc[] 연산자
iloc[] 위치(Location) 기반 인덱싱 방식으로 동작
행과 열 위치를, 0을 출발점으로 하는 세로축, 가로축 좌표 정숫값으로 지정하는 방식
iloc[행 위치 정숫값, 열 위치 정숫값]
datadf.iloc[0,0] 칼럼명칭이나 인덱스 입력하면 오류 발생
칼럼명칭이나 인덱스 입력하면 오류 발생
 정숫값 또는 정수형의 슬라이싱, 팬시리스트 값 입력(불린 인덱싱X)
정숫값 또는 정수형의 슬라이싱, 팬시리스트 값 입력(불린 인덱싱X)
 열 위치 -1을 입력해 마지막 열 데이터를 가져오는데 자주 사용
열 위치 -1을 입력해 마지막 열 데이터를 가져오는데 자주 사용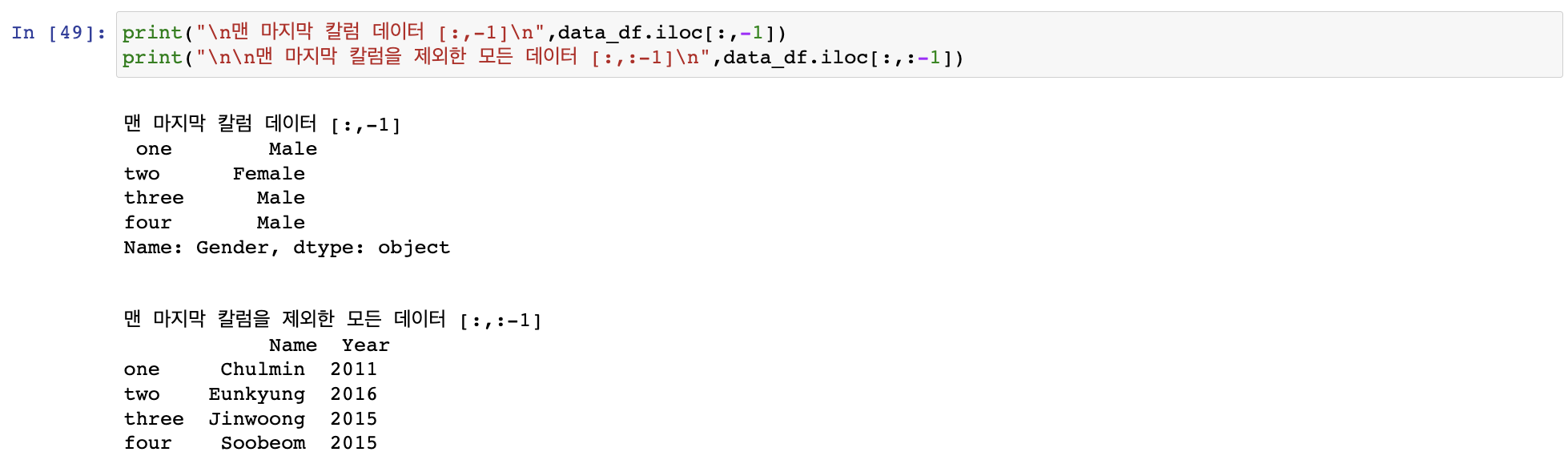
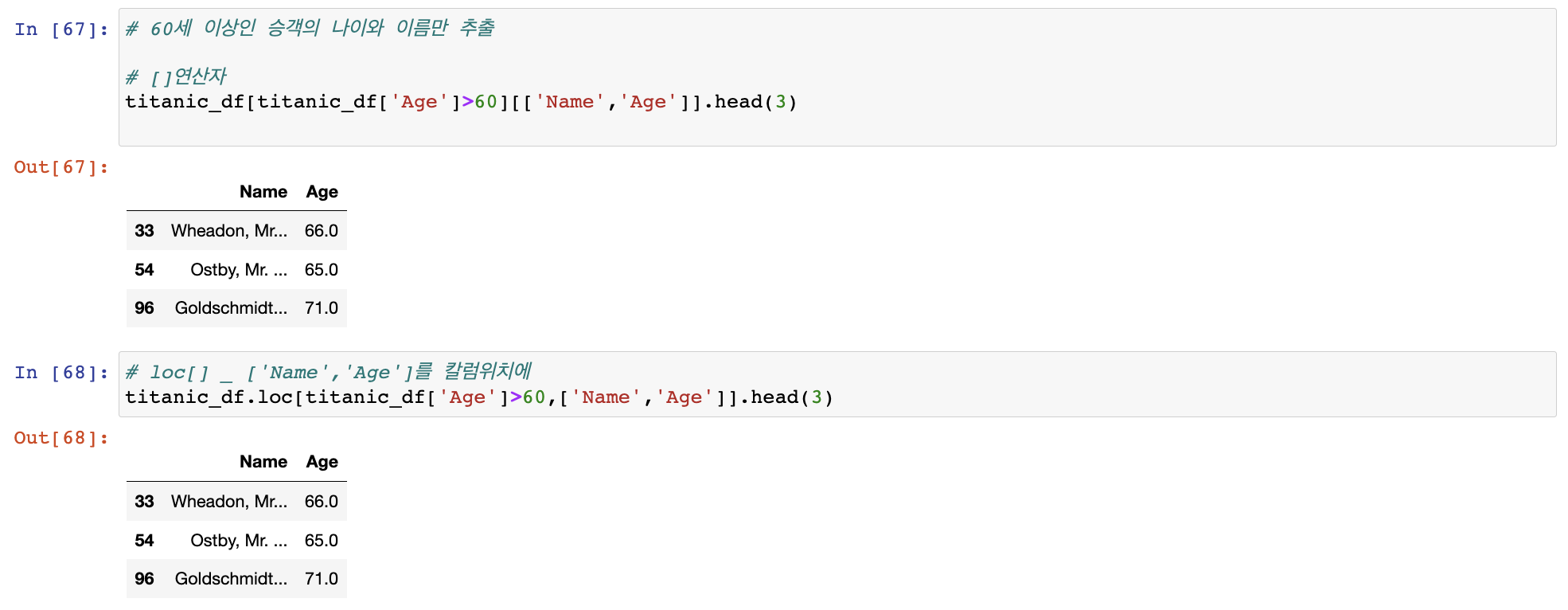
DataFrame loc[] 연산자
loc[] 명칭(Label) 기반 인덱싱 방식으로 동작
데이터 프레임의 인덱스 값으로 행 위치를, 칼럼의 명칭으로 열 위치를 지정하는 방식
loc[인덱스값, 칼럼명] 따로 인덱스가 존재하는 경우 무턱대고 정숫값 입력하면 오류 발생
따로 인덱스가 존재하는 경우 무턱대고 정숫값 입력하면 오류 발생 loc[]에 슬라이싱 기호
loc[]에 슬라이싱 기호 :적용 시 시작값:종료값-> 시작값~종료값 종료값에서 -1안함! 명칭기반 인덱싱이라 숫자형이 아닐 수 있기에 -1할 수 없음
loc[]는 iloc[]와 다르게 불린 인덱싱 가능

불린 인덱싱
[], loc[]에서 지원
and &, or |, Not ~ 개별 조건을 변수에 할당하고 변수를 결합해서 불린 인덱싱 수행 가능
개별 조건을 변수에 할당하고 변수를 결합해서 불린 인덱싱 수행 가능
정렬, Aggregation 함수, GroupBy 적용
DataFrane, Series의 정렬 - sort_values()
RDBMS SQL의 order by와 유사
입력 파라미터:
by: 특정 칼럼 입력하면 해당 칼럼으로 정렬 수행
ascending: True - 오름차순(Default), False - 내림차순
inplace: True - 호출한 DataFrame의 정렬 결과를 그대로 적용
False - 호출한 DataFrame은 그대로 유지하며 정렬된 DataFrame을 결과로 반환 (Default) 여러 개의 칼럼으로 정렬: by에 리스트 형식으로 정렬하려는 칼럼 입력
여러 개의 칼럼으로 정렬: by에 리스트 형식으로 정렬하려는 칼럼 입력
Aggregation 함수 적용
DataFrame에 Aggregation 함수 min(), max(), sum(), count() 적용
-> 모든 칼럼에 해당 aggregation을 적용
count()는 Null을 반영X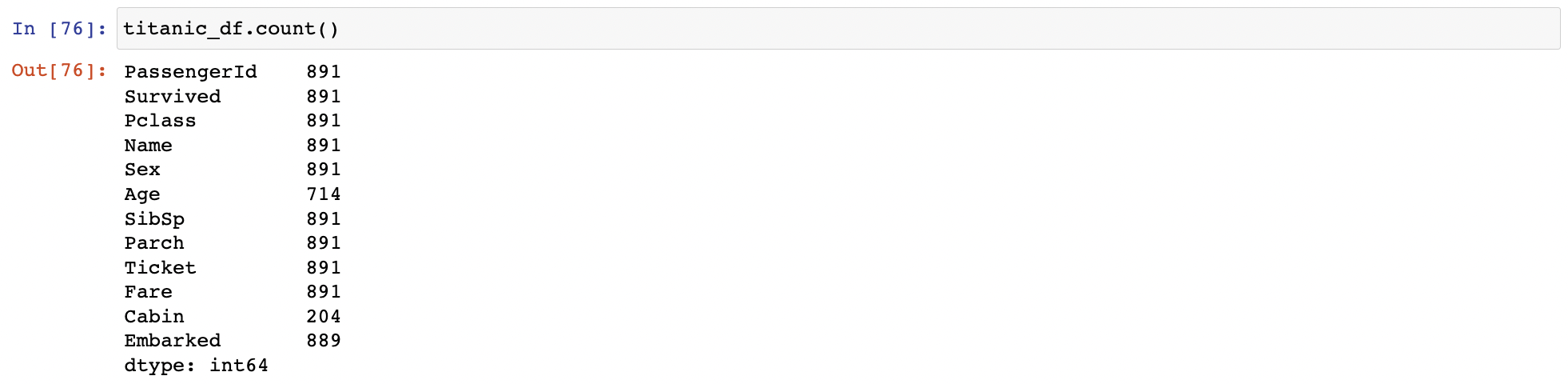
특정 칼럼에 aggregation 적용하려면 DataFrame에 대상 칼럼들만 추출해 적용

groupby() 적용
입력 파라미터:
by: 대상 칼럼
대상 칼럼 시준으로 GroupBy된 DataFrameGroupBy 객체 반환
groupby()를 호출해 반환한 결과에 aggregation 함수 호출하면 groupby() 대상 칼럼을 제외한 모든 칼럼에 해당 aggregation함수를 적용

여러 칼럼에 aggregation 함수 적용
(SQL는 groupby적용 시 여러 칼럼에 aggregation함수를 호출하려면 대상 칼럼을 모두 Select절에 나열)
Select count(ID), count(Survived), ... from titanic_table group by Pclass
DataFrame의 특정 칼럼만 aggregation함수를 적용하려면 groupby()로 반환된 DataFrameGroupBy 객체에 해당 칼럼을 필터링한 뒤 aggregation함수를 적용
DataFrameGroupBy 객체에 [['PassengerId', 'Survived']]로 필터링해 두 칼럼에만 count()를 수행
서로 다른 aggregation함수 적용
(SQL은 서로 다른 함수를 Select 절에 나열하기만 하면 됨)
Select max(Age), min(Age) from titanic_table group by Pclass
DataFrame은 적용하려는 여러 함수 명을 DataFrameGroupBy객체의 agg()내에 인자로 입력해서 사용

여러 개의 칼럼에 서로 다른 aggregation함수 적용
(SQL이 dataframe보다 덜 복잡하고 유연성이 높음)
Select max(Age), sum(SibSp), avg(Fare) from titanic_table group by Pclass
DataFrame에선 agg()내에 입력값으로 딕셔너리 형태로 aggregation이 적용될 칼럼과 함수를 입력

결손 데이터 처리하기
결손데이터: 칼럼 값이 NULL인 경우. 넘파이의 NaN으로 표시 => 머신러닝 알고리즘을 위해 다른 값으로 대체
isna()로 결손 데이터 여부 확인
isna() 데이터가 NaN인지 아닌지 알려줌 결손 데이터 개수: isna()결과에 sum()추가 -> True는 1, False는 0으로 반환되어 결손데이터 개수 알 수 있음
결손 데이터 개수: isna()결과에 sum()추가 -> True는 1, False는 0으로 반환되어 결손데이터 개수 알 수 있음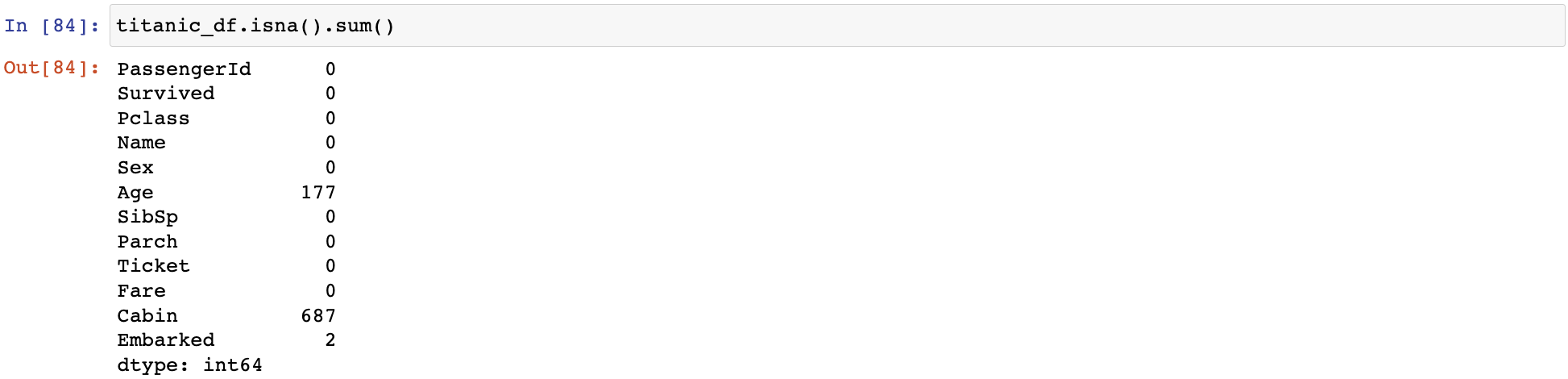
fillna()로 결손 데이터 대체하기
 fillna()를 이용해 반환 값을 다시 받거나 inplace=True를 추가해야 실제 데이터 세트 값이 변경됨
fillna()를 이용해 반환 값을 다시 받거나 inplace=True를 추가해야 실제 데이터 세트 값이 변경됨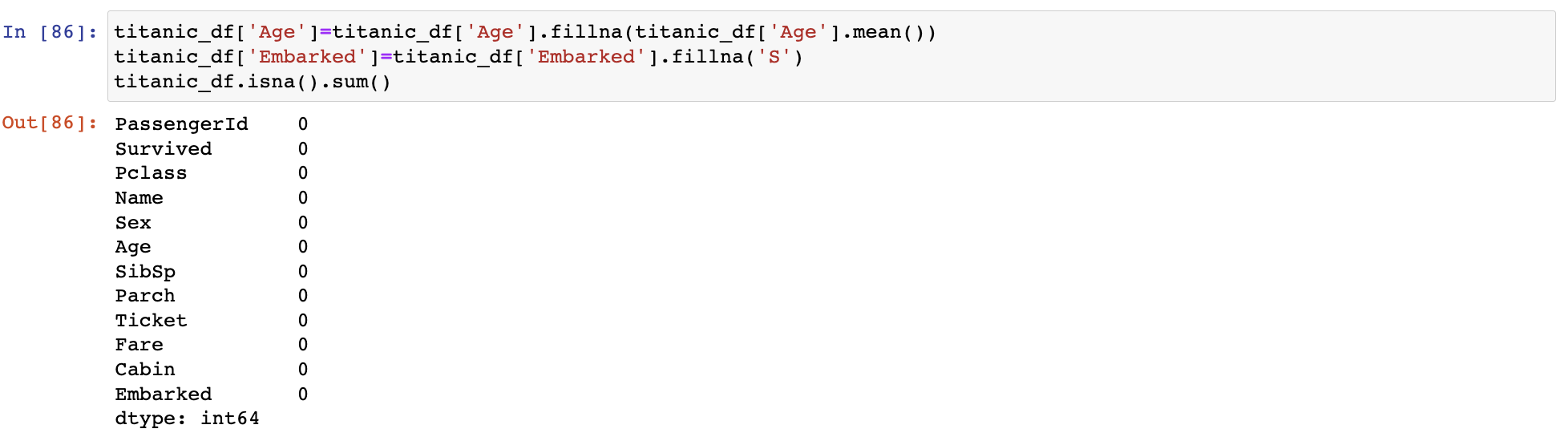
apply lambda 식으로 데이터 가공
lambda식
파이썬에서 함수형 프로그래밍을 지원하기 위해 만듦
- 함수의 선언과 함수 내의 처리를 한줄의 식으로 쉽게 변환


:로 입력 인자와 반환될 입력 인자의 계산식을 분리
- 여러 개의 값을 인자로 사용할 경우
map()사용

apply함수에 lambda식을 결합해 레코드별로 데이터 가공
- 우선 이름 길이를 나타내는 칼럼 추가

if else
if절의 경우 if식보다 반환 값을 먼저 기술
나이 15 미만 -> child , 15 이상 -> Adult :lambda x:'Child' if x <= 15 else 'Adult'
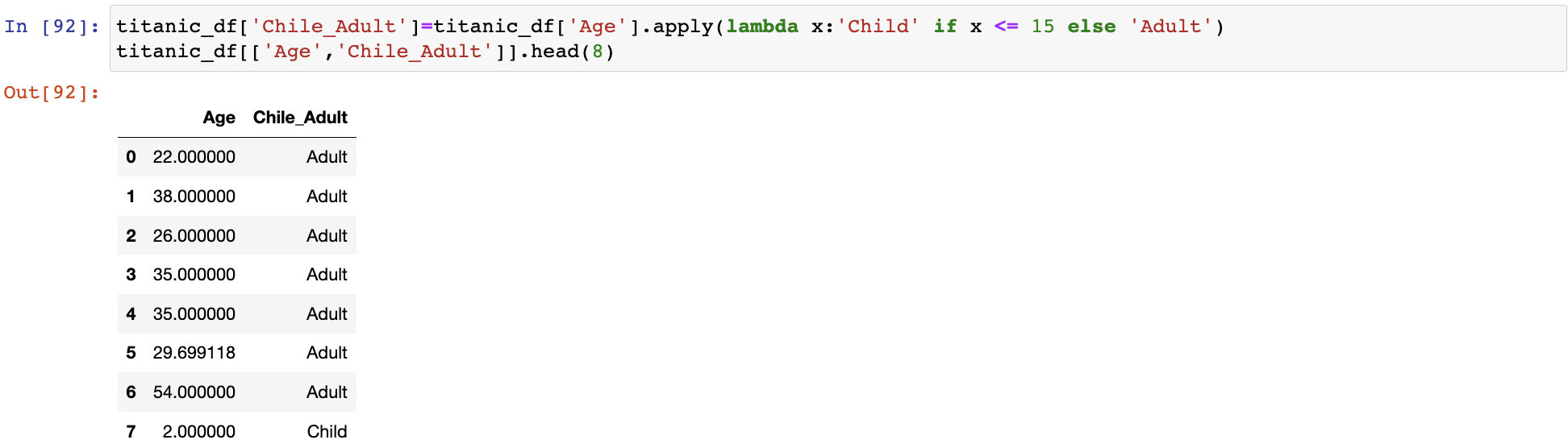
else if는 지원x
else 절을 ()로 내포해 다시 if else 적용

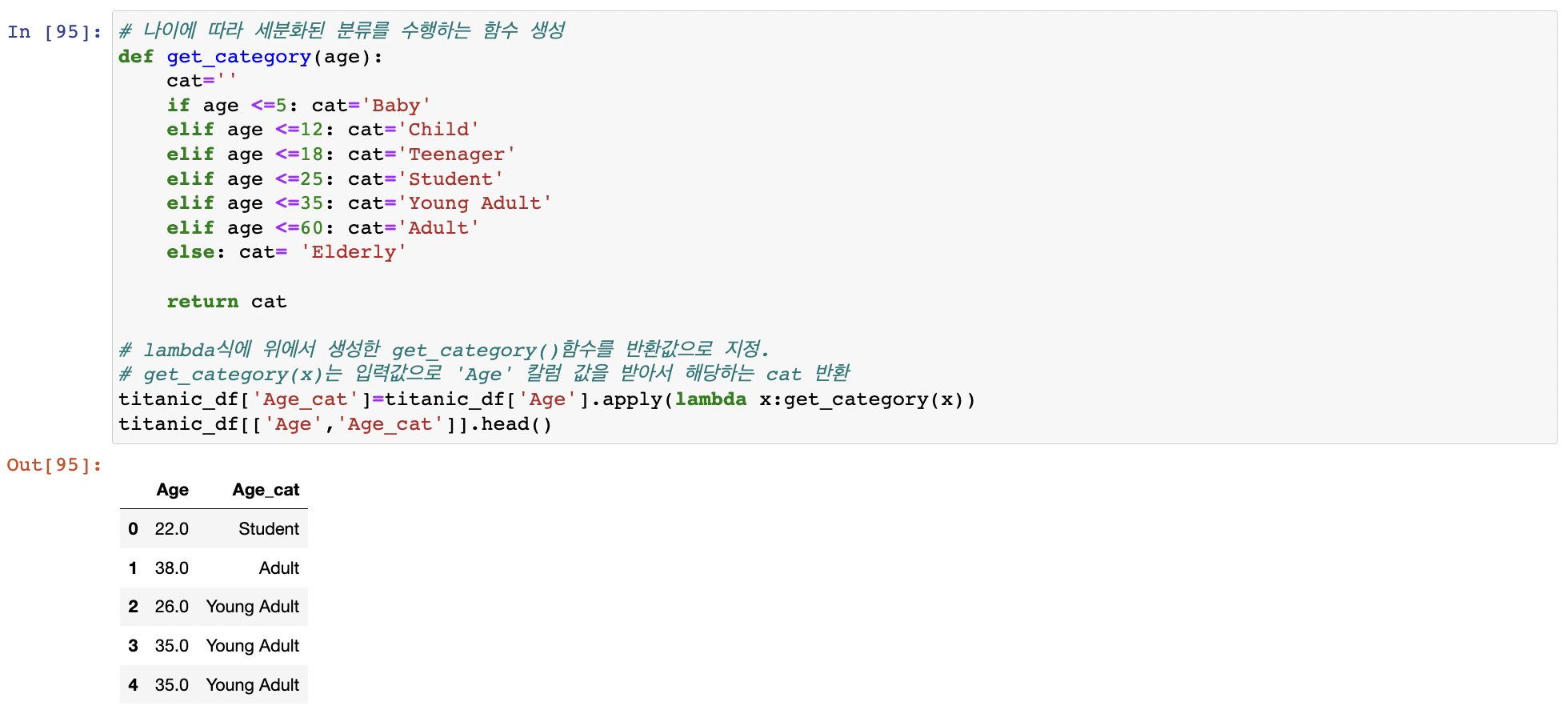
switch case문
세분화된 분류를 수행하는 함수 생성
명령어 요약
.read_csv() 파일 DataFrame으로 변환
.head(n) 맨 앞 n개의 로우 반환
.shape() 행과 열 반환
.info() 총 데이터 건수, 데이터 타입, Null건수 조회
.describe() 숫자형 데이터값의 n-percentile분포도, 평균값, 최댓값, 최솟값
.value_counts() 칼럼값의 유형, 건수 확인
pd.DataFrame(data,columns) data를 DataFrame으로 변환
.values DataFrame를 넘파이 ndarray로 변환
[]로 DataFrame내의 칼럼 생성 및 일괄 수정
drop() 메서드로 데이터 삭제
.index 인덱스 객체만 추출
reset_index() 새롭게 연속 숫자 형 인덱스 할당
[칼럼명], [칼럼명 리스트], [인덱스로 변환 가능한 표현식]
iloc[행 위치 정숫값, 열 위치 정숫값]
loc[인덱스값, 칼럼명]
sort_values() 정렬 - by ascending inplace
Aggregation 함수 - min(), max(), sum(), count()
groupby() + agg()
결손 데이터
여부 확인 isna()
대체 fillna()
데이터 가공: lambda함수와 apply()함수 결합
