개요
new 주피터 노트북
import numpy as np
넘파이 기반 데이터 타입: ndarray
->다차원 배열을 쉽게 생성, 다양한 연산 수행
array() 함수: 리스트와 같은 인자를 입력받아 ndarray로 변환
ndarray의 shape변수: ndarray의 행과 열을 튜플 형태로 가지고 있음
array1 = np.array([1,2,3])
print('array1 type:', type(array1))
print('arrya1 array 형태(크기)', array1.shape)
array2 = np.array([[1,2,3],[2,3,4]])
print('array2 type:', type(array2))
print('arrya2 array 형태(크기)', array2.shape)
array3 = np.array([[1,2,3]])
print('array3 type:', type(array3))
print('arrya3 array 형태(크기)', array3.shape)
결과:
array1 type: <class 'numpy.ndarray'>
arrya1 array 형태(크기) (3,)
array2 type: <class 'numpy.ndarray'>
arrya2 array 형태(크기) (2, 3)
array3 type: <class 'numpy.ndarray'>
arrya3 array 형태(크기) (1, 3)리스트 []는 1차원, 리스트의 리스트 [[]]는 2차원
[1,2,3]은 (3,) 1차원
[[1,2,3]]은 (1,3) 2차원
차원 확인: ndarry.ndim
print('array1: {0}차원, array2: {1}차원, array3: {2}차원'.format(array1.ndim,array2.ndim,array3.ndim))
결과:
array1: 1차원, array2: 2차원, array3: 2차원ndarray의 데이터 타입
ndarry 데이터값은 숫자 문자열 불 등 모두 가능(int, unsigned int, float, complex)
한 ndarray에 같은 데이터 타입만 가능
dtype 속성으로 데이터 타입 확인 가능
list1 = [2,3,4]
print(type(list1))
array1 = np.array(list1)
print(type(array1))
print(array1, array1.dtype)결과:<class 'list'>
<class 'numpy.ndarray'>
[2 3 4] int64다른 타입을 가진 list를 ndarray로 바꾸면 데이터 크기 큰 타입으로 형변환 일괄 적용
list2 = [1,2,'test']
array2=np.array(list2)
print(array2, array2.dtype)
list3 = [1,2,3.0]
array3=np.array(list3)
print(array3,array3.dtype)
결과:
['1' '2' 'test'] <U21
[1. 2. 3.] float64astype()메서드로 ndarray 내 데이터값의 타입 변경 가능
메모리 절약에 사용
array_int = np.array([1,2,3])
array_float = array_int.astype('float64')
print(array_float,array_float.dtype)
array_int1=array_float.astype('int32')
print(array_int1,array_int1.dtype)
array_float1=np.array([1.1,2.1,3.1])
array_int2=array_float1.astype('int32')
print(array_int2,array_int2.dtype)
결과:
[1. 2. 3.] float64
[1 2 3] int32
[1 2 3] int32ndarray를 편리하게 생성하기 - arrange, zeros, ones
ndarray를 연속값이나 0또는 1로 초기화해 생성하는 경우
arange(): 파이썬 표준 함수 range와 유사한 기능
- default 인자값은
stop: 0부터 stop값-1까지 연속 숫자값 저장됨
sequence_array = np.arange(10)
print(sequence_array)
print(sequence_array.dtype,sequence_array.shape)
결과:
[0 1 2 3 4 5 6 7 8 9]
int64 (10,)start값으로 연속값의 시작점 지정 가능
zeros(): 튜플 형태의 shape값을 인자로->모든 값을 0으로 채운 ndarray반환
ones(): 튜플 형태의 shape값을 인자로->모든 값을 1으로 채운 ndarray반환
dtype지정X=> default로 float64형의 데이터
zero_array = np.zeros((3,2),dtype='int32')
print(zero_array)
print(zero_array.dtype, zero_array.shape)
one_array=np.ones((3,2))
print(one_array)
print(one_array.dtype, one_array.shape)
결과:
[[0 0]
[0 0]
[0 0]]
int32 (3, 2)
[[1. 1.]
[1. 1.]
[1. 1.]]
float64 (3, 2)ndarray의 차원과 크기를 변경하는 reshape()
reshape(): ndarry를 특정 차원, 크기로 변환
지정된 사이즈로 변경 불가능하면 오류 발생
array1=np.arange(10)
print('array1:\n',array1)
array2=array1.reshape(2,5)
print('array2:\n',array2)
array3=array2.reshape(5,2)
print('array3\n',array3)
결과:
array1:
[0 1 2 3 4 5 6 7 8 9]
array2:
[[0 1 2 3 4]
[5 6 7 8 9]]
array3
[[0 1]
[2 3]
[4 5]
[6 7]
[8 9]]인자로 -1을 적용
원래 ndarray와 호환되는 새로운 shape로 자동으로 변환해줌
변경 안되면 에러
array1=np.arange(10)
print(array1)
array2=array1.reshape(-1,5)
print(array2)
print('array2 shape:', array2.shape)
array3=array1.reshape(5,-1)
print(array3)
print('array3 shape:', array3.shape)
결과:
[0 1 2 3 4 5 6 7 8 9]
[[0 1 2 3 4]
[5 6 7 8 9]]
array2 shape: (2, 5)
[[0 1]
[2 3]
[4 5]
[6 7]
[8 9]]
array3 shape: (5, 2)reshape(-1,1) -> 원본이 어떤 형태라도 2차원이고, 반드시 1개의 칼럼
array1=np.arange(8)
array3d=array1.reshape((2,2,2))
print('array3d:\n',array3d.tolist())
# 3차원 ndarray를 2차원 ndarray로 변환
array5=array3d.reshape(-1,1)
print('array5d:\n',array5.tolist())
print('array5 shape:',array5.shape)
# 1차원 ndarray를 2차원 ndarray로 변환
array6=array1.reshape(-1,1)
print('array6:\n',array6.tolist())
print('array6 shape:',array6.shape)
결과:
array3d:
[[[0, 1], [2, 3]], [[4, 5], [6, 7]]]
array5d:
[[0], [1], [2], [3], [4], [5], [6], [7]]
array5 shape: (8, 1)
array6:
[[0], [1], [2], [3], [4], [5], [6], [7]]
array6 shape: (8, 1)넘파이의 ndarray의 데이터 세트 선택하기 - 인덱싱 (Indexing)
- 특정한 데이터만 추출: 원하는 위치의 인덱스 값으로 해당 위치 데이터 반환 가능
- 슬라이싱(Slicing):
시작인덱스:종료인덱스(-1) - 팬시 인덱싱(Fancy Indexing): 일정 인덱싱 집합을 리스트 또는 ndarray형태로 지정해 해당 위치의데이터의 ndarray를 반환
- 불린 인덱싱(Boolean Indexing): 특정 조건에 해당하는지 여부인 T/F값 인덱싱 집합을 기반으로 True에 해당하는 인덱스 위치에 있는 데이터의 ndarray반환
(단일 추출 제외한 2,3,4번의 데이터세트는 모두 ndarray타입)
단일 값 추출
원하는 한개의 데이터의 인덱스 값을 []안에 입력
인덱스는 0부터 시작
array[1]의 type은 데이터 값의 타입
마이너스 기호로 뒤에서부터 추출. -1은 맨뒤의 데이터값
# 1부터 9까지의 1차원 ndarray 생성
array1 = np.arange(start=1, stop=10)
print('array1: ',array1)
# Index는 0부터 시작하므로 array1[2]는 3번째 index위치의 데이터값을 의미
value = array1[2]
print('value: ',value)
print(type(value))
# 마이너스 인덱스로 뒤에서부터 접근 가능
print('맨 뒤의 값: ',array1[-1],'맨 뒤에서 두 번째 값: ',array1[-2])
결과:
array1: [1 2 3 4 5 6 7 8 9]
value: 3
<class 'numpy.int64'>
맨 뒤의 값: 9 맨 뒤에서 두 번째 값: 8단일 인덱스를 이용해 데이터값 수정 가능
array1[0]=9
array1[8]=0
print('array1: ',array1)
결과:
array1: [9 2 3 4 5 6 7 8 0]다차원 ndarray에서도 단일 값 추출 가능
2차원 -> [row,col]
array1d=np.arange(start=1,stop=10)
array2d=array1d.reshape(3,3)
print(array2d)
print('(row=0, col=0) index 가리키는 값: ', array2d[0,0])
print('(row=0, col=1) index 가리키는 값: ', array2d[0,1])
print('(row=1, col=0) index 가리키는 값: ', array2d[1,0])
print('(row=2, col=2) index 가리키는 값: ', array2d[2,2])
결과:
[[1 2 3]
[4 5 6]
[7 8 9]]
(row=0, col=0) index 가리키는 값: 1
(row=0, col=1) index 가리키는 값: 2
(row=1, col=0) index 가리키는 값: 4
(row=2, col=2) index 가리키는 값: 9
axis
axis 0: 로우 방향의 축
axis 1: 칼럼 방향의 축
다차원 ndarray는 로우 칼럼이 아닌 axis 구분을 가짐
-> [axis 0=0, axis 1=1]이 정확한 표현
슬라이싱 Slicing
: 기호로 데이터 슬라이싱해 추출
시작인덱스:종료인덱스 -> 시작인덱스~종료인덱스-1 위치의 데이터 세트(ndarray)
array1=np.arange(start=1,stop=10)
array3=array1[0:3]
print(array3)
print(type(array3))
결과:
[1 2 3]
<class 'numpy.ndarray'>: 사이의 시작, 종료 인덱스 생략 가능 -> 맨 처음 또는 맨 마지막 인덱스로 간주됨
array1=np.arange(start=1,stop=10)
array4=array1[:3]
print(array4)
array5=array1[3:]
print(array5)
array6=array1[:]
print(array6)
결과:
[1 2 3]
[4 5 6 7 8 9]
[1 2 3 4 5 6 7 8 9]2차원 ndarray 슬라이싱
array1d=np.arange(start=1,stop=10)
array2d=array1d.reshape(3,3)
print(array2d)
print('array2d[0:2, 0:2] \n', array2d[0:2, 0:2])
print('array2d[1:3, 0:3] \n', array2d[1:3, 0:3])
print('array2d[1:3, :] \n', array2d[1:3, :])
print('array2d[:, :] \n', array2d[:, :])
print('array2d[:2, 1:] \n', array2d[:2, 1:])
print('array2d[2, 0] \n', array2d[:2, 0])
결과:
[[1 2 3]
[4 5 6]
[7 8 9]]
array2d[0:2, 0:2]
[[1 2]
[4 5]]
array2d[1:3, 0:3]
[[4 5 6]
[7 8 9]]
array2d[1:3, :]
[[4 5 6]
[7 8 9]]
array2d[:, :]
[[1 2 3]
[4 5 6]
[7 8 9]]
array2d[:2, 1:]
[[2 3]
[5 6]]
array2d[2, 0]
[1 4]2차원에서 뒤에오는 인덱스를 없애면 1차원 반환
print(array2d[0])
print(array2d[1])
print('array2d[0] shape: ',array2d[0].shape,' array2d[1] shape: ',array2d[1].shape,)
결과:
[1 2 3]
[4 5 6]
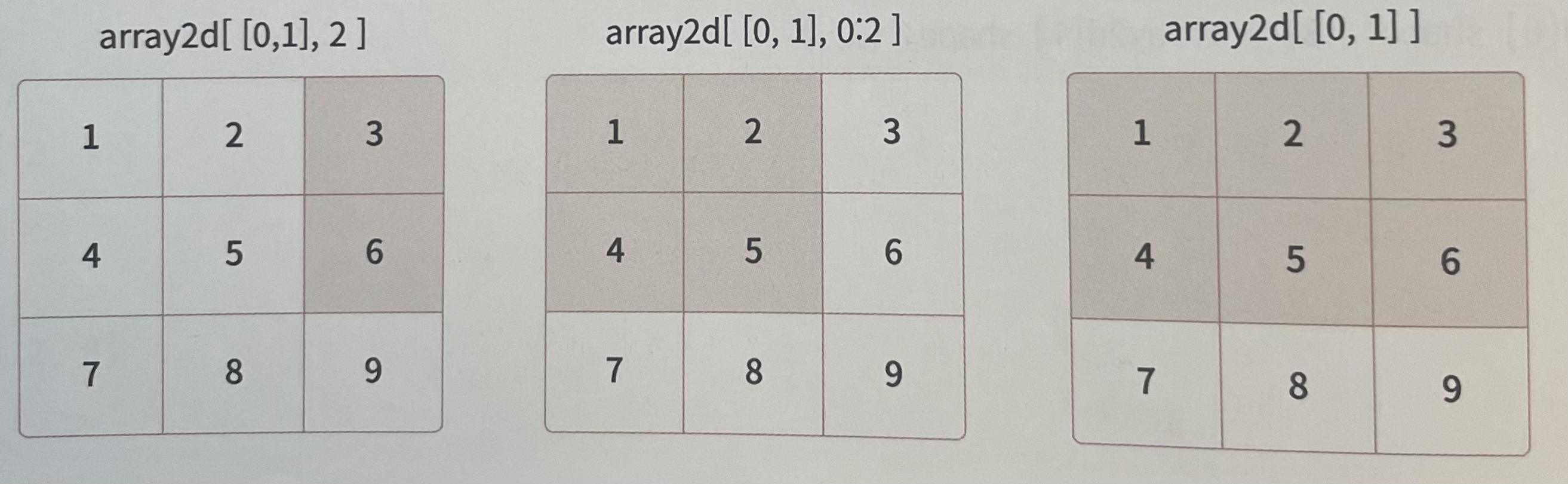
array2d[0] shape: (3,) array2d[1] shape: (3,)팬시 인덱싱 Fancy Indexing
리스트나 ndarray로 인덱싱 집합을 지정하면 해당 위치의 ndarray반환
array1d=np.arange(start=1,stop=10)
array2d=array1d.reshape(3,3)
array3=array2d[[0,1],2]
print('array2d[[0,1],2] => ',array3.tolist())
array4=array2d[[0,1],0:2]
print('array2d[[0,1],0:2] => ',array4.tolist())
array5=array2d[[0,1]]
print('array2d[[0,1]] => ',array5.tolist())
결과:
array2d[[0,1],2] => [3, 6]
array2d[[0,1],0:2] => [[1, 2], [4, 5]]
array2d[[0,1]] => [[1, 2, 3], [4, 5, 6]][0,1],2 -> (0,2) / (1,2)
[0,1],0:2 -> ((0,0), (0,1)) / ((1,0), (1,1))
[[0,1]] -> ((0,:), (1,:))
불린 인덱싱 Boolean Indexing
조건 필터링과 검색을 동시에 하는 기능
[ ]안에 조건문을 그대로 기재
array1d=np.arange(start=3,stop=13)
# [ ] 안에 array1d >5 Boolean Indexing을 적용
array3 = array1d[array1d>5]
print('array1d >5 불린 인덱싱 결과 값: ', array3)
결과:
array1d >5 불린 인덱싱 결과 값: [ 6 7 8 9 10 11 12]원리:
array1d>5실행하면 -> array([False, False, False, True, True, True, True, True, True, True])
조건으로 반환된 ndarray객체를 인덱싱을 지정하는 [ ] 안에 입력하면 False는 무시하고 True값이 있는 위치 인덱스 값으로 자동변환해 해당하는 인덱스 위치의 데이터만 반환
확인
boolean_indexes = np.array([False, False, False, True, True, True, True, True, True, True])
array3 = array1d[boolean_indexes]
print('불린 인덱스로 필터링 결과: ',array3)
결과:
불린 인덱스로 필터링 결과: [ 6 7 8 9 10 11 12]즉 다음과 같이 직접 인덱스 집합을 만들어 대입한 것과 동일
indexes=np.array([3,4,5,6,7,8])
array4 = array1d[indexes]
print('일반 인덱스로 필터링 결과: ',array4)
결과:
일반 인덱스로 필터링 결과: [ 6 7 8 9 10 11]True인 데이터 값을 저장하는 것이 아니라 True를 가지는 인덱스를 저장하는 것
행렬의 정렬 - sort()와 argsort()
정렬 np.sort(), ndarray.sort()
정렬된 행렬의 인덱스 반환 argsort()
행렬 정렬
np.sort() : 넘파이에서 sort호출 -> 원 행렬 유지한 채 정렬된 행렬 반환
ndarray.sort() : 행렬 자체에서 sort호출 -> 행렬 자체를 정렬한 형태로 변환. 반환값 None
org_array = np.array([3,1,9,5])
print('원본 행렬: ',org_array)
# np.sort로 정렬
sort_array1 = np.sort(org_array)
print('np.sort()호출 후 반환되는 정렬 행렬: ',sort_array1)
print('np.sort()호출 후 원본 행렬',org_array)
# ndarray.sort()로 정렬
sort_array2 = org_array.sort()
print('org_array.sort()호출 후 반환되는 정렬 행렬: ',sort_array2)
print('org_array.sort()호출 후 원본 행렬',org_array)
결과:
원본 행렬: [3 1 9 5]
np.sort()호출 후 반환되는 정렬 행렬: [1 3 5 9]
np.sort()호출 후 원본 행렬 [3 1 9 5]
org_array.sort()호출 후 반환되는 정렬 행렬: None
org_array.sort()호출 후 원본 행렬 [1 3 5 9]내림차순 np.sort()[::-1]
sort_array1_desc = np.sort(org_array)[::-1]
print('내림차순으로 정렬', sort_array1_desc)
결과:
내림차순으로 정렬 [9 5 3 1]행렬이 2차원 이상인 경우,
axis축 값 설정을 통해 로우 방향 또는 칼럼 방향으로 정렬 수행 가능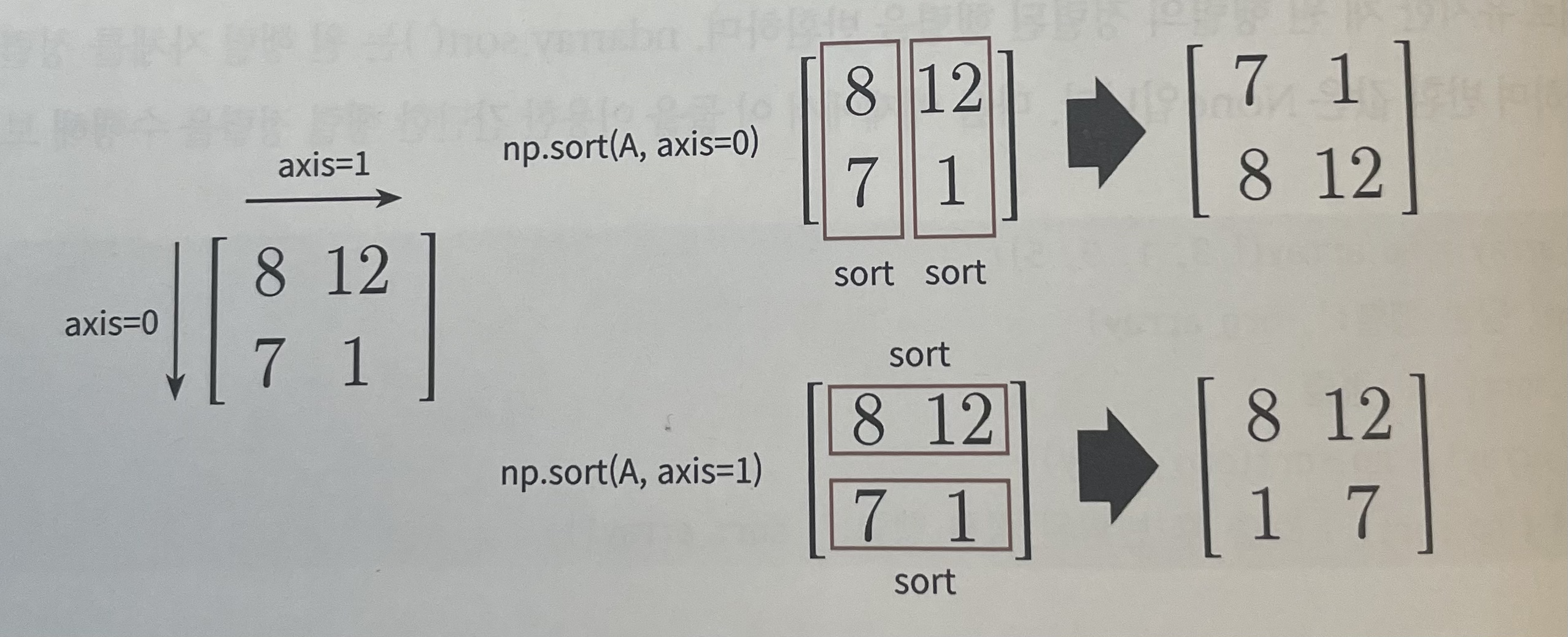
array2d = np.array([[8,12],[7,1]])
sort_array2d_axis0 = np.sort(array2d, axis=0)
print('로우 방향으로 정렬:\n', sort_array2d_axis0)
sort_array2d_axis1 = np.sort(array2d, axis=1)
print('칼럼 방향으로 정렬:\n', sort_array2d_axis1)
결과:
로우 방향으로 정렬:
[[ 7 1]
[ 8 12]]
칼럼 방향으로 정렬:
[[ 8 12]
[ 1 7]]정렬된 행렬의 인덱스를 반환하기
np.argsort()정렬 행렬의 기존 원본 행렬의 원소에 대한 인덱스를 ndarray형으로 반환
org_array = np.array([3,1,9,5])
sort_indices = np.argsort(org_array)
print(type(sort_indices))
print('행렬 정렬 시 원본 행렬의 인덱스', sort_indices)
결과:
<class 'numpy.ndarray'>
행렬 정렬 시 원본 행렬의 인덱스 [1 0 3 2]내림차순 np.argsort()[::-1]
org_array = np.array([3,1,9,5])
sort_indices_desc = np.argsort(org_array)[::-1]
print('행렬 내림차순 정렬 시 원본 행렬의 인덱스', sort_indices_desc)
결과:
행렬 내림차순 정렬 시 원본 행렬의 인덱스 [2 3 0 1]넘파이는 메타데이터를 가질 수 없어 실제 값과 그 값이 뜻하는 메타 데이터를 별도의 ndarray로 각각 저장
ex 학생의 이름과 시험 성적을 각각ndarray로 가질 때 시험 성적 순 학생이름 출력에 유용하게 사용
import numpy as np
name_array = np.array(['Jhohn', 'Mike','Sarah','Kate','Samuel'])
score_array = np.array([78,95,84,98,88])
# np.argsort(score_array)로 반환된 인덱스를 name_array에 챈시 인덱스로 적용해 추출
sort_indices_asc = np.argsort(score_array)
print('성적 오름차순 정렬 시 score_array의 인덱스: ',sort_indices_asc)
print('성적 오름차순으로 name_array의 이름 출력: ',name_array[sort_indices_asc])
결과:
성적 오름차순 정렬 시 score_array의 인덱스: [0 2 4 1 3]
성적 오름차순으로 name_array의 이름 출력: ['Jhohn' 'Sarah' 'Samuel' 'Mike' 'Kate']선형대수 연산 - 행렬 내적과 전치 행렬 구하기
행렬 내적 (행렬 곱)
np.dot()
: 왼쪽 행렬의 로우와 오른쪽 행렬의 칼럼의 원소들을 순차적으로 곱한 뒤 그 결과를 모두 더한 값
: 왼쪽 행렬의 열 개수와 오른쪽 행렬의 행 개수가 동일해야 연산 가능
A = np.array([[1,2,3],[4,5,6]])
B = np.array([[7,8],[9,10],[11,12]])
dot_product = np.dot(A,B)
print('행렬 내적 결과:\n',dot_product)
결과:
행렬 내적 결과:
[[ 58 64]
[139 154]]전치 행렬
transpose()
:행과 열 위치를 교환한 원소로 구성한 행렬
A = np.array([[1,2],[3,4]])
transpose_mat = np.transpose(A)
print('A의 전치 행렬:\n',transpose_mat)
결과:
A의 전치 행렬:
[[1 3]
[2 4]]요약
ndarray
array(): 리스트->ndarray
shape: 크기
ndim: 차원
dtype: 데이터 타입
astype(): 타입 변경
arange(): 연속값으로 초기화 - 인자값 stop,start
zeros(): 0으로 초기화
ones(): 1으로 초기화
reshape(): 차원, 크기 변환
단일 인덱싱 [1]
슬라이싱 [1:8]
팬시 인덱싱 - 리스트로 인덱싱집단을 표현
불린 인덱싱 - [ ] 안에 조건
np.sort() - 원 행렬 유지한 채 정렬된 행렬 반환
ndarray.sort() - 행렬 정렬. 반환 None
np.argsort() - 정렬행렬의 기존 원소 인덱스 반환
