
Pandas의 DDA 부분에서 분산과 표준편차에 대한 부분, 그리고 시각화, EDA 부분에서 상관관계와 상관계수, 공분산 행렬에 대한 내용을 간략하게 설명하고 넘어갔는데, 이번 글에서는 이에 대한 설명을 덧붙이고자 한다.
수학적인 부분이여서 오직 이해를 돕기 위해서지, 이에 대해 자세히 아는 분야는 통계쪽이다. 인공지능을 바라보는 나와 같은 사람들은 이 부분에 너무 목매지 말고 이런 내용들을 써서 결국 머신러닝을 위해 사용하는 함수들에 조금 더 집중하면 좋을 거 같다.
1. 분산과 표준편차
산포도란, 데이터의 중심으로 부터 얼마나 떨어져 있는지를 말한다.
그러면 그 산포도를 구하기 위해서는 당연히 중심이 되는 값이 있을 것이고
당연히 중심으로 부터 떨어진 값이 있을 것이다.
만약 반에 학생들이 5명이 있고 이 5명의 학생들의 성적의 평균을 내보니,
80점이라는 평균이 나왔다.
그리고 각 학생들은 70점, 75점, 80점, 85점, 90점을 맞았다고 하자.
그렇다면 80점 평균보다 잘본 학생들이 2명, 못본 학생들이 2명, 그리고 딱 평균만큼 본 학생이 1명이 있을 것이다.
즉 다시말해 80점이 중심이 되며, 80점을 기준으로 못보거나(-), 잘본(+) 성적인 것이다.
이 70점은 평균보다,
-10점 만큼 못봤고, 75점은 -5점, 80점은 0점, 85점은 +5점, 90점은 +10점 만큼 잘봤다.
이게 바로 편차다.
즉, 편차 = 개별값 - 평균 인 것이다.
그렇다면 표준 편차를 구하려면? 우선 편차 평균을 구해야 하는데, 이게 불가능하다.
편차의 평균을 구하기 위해서는 편차의 합을 개수로 나누기 때문에, -10 + -5 + 0 + 5 + 10 = 0이되며, 0/5가 되기 때문에 불가능하다.
이렇게 예시를 5개라고 찍었지만 실제로도 각 개별값이 퍼져있어도 모든 값은 평균보다 못보거나 잘 본 값이 있기 때문에, 합치면 0에 수렴한다.
따라서 편차에 절대값을 취하던가, 제곱을 하여 음수를 양수로 바꿔줘야 한다.
보통 평균을 위해서는 제곱을 해주는 경우가 많다.
이렇게 제곱을 해주면 이제 나눌 수 있게 되며, 편차 제곱의 합을 n개로 나누면 편차 제곱의 평균이 나온다. 그리고 이를 분산이라고 한다.
하지만 이 분산은 제곱을 통해 나온 값으로 값이 뻥튀기 되었기 때문에, 이 값에 루트를 씌워주는데, 이를 바로 표준 편차라고 한다.
수식으로보면 다음과 같다.
평균:
편차: (각 데이터 값 ) - (평균)
편차 제곱
편차 제곱의 합
분산(Variance): 편차 제곱의 평균
표준편차: 분산의 제곱근
이렇게 구한 표준편차는 분산을 기반으로 데이터가 평균에서 얼마나 벗어나는지를 직접적으로 나타낸다.
즉 표준편차가 이라면 평균으로부터 10씩 떨어져 있다고 해석할 수 있다.
2. 상관관계와 상관계수, 공분산 행렬
다변수를 시각화하는 과정에서 히트맵 그래프를 사용하여 상관 분석을 하는 과정을 보였는데 그에 대해 조금 자세히 다루면 다음과 같다.
먼저 상관 관계는 두 변수인 와 가 어떻게 함께 변화하는지를 설명한다.
날씨가 더운날에 아이스크림이 더 많이 판매되고, 연봉이 높은 사람이 더 많은 지출이 발생하는 우상향의 그래프를 띄는 관계는 양의 상관관계이며, 날이 추운 날에 아이스크림 판매량이 더 떨어지고, 연봉이 낮은 사람이 더 적은 지출이 발생하는 우하향의 그래프를 띄는 관계는 음의 상관관계이다.
또한 이제 이런 상관관계의 정도를 수치로 나타낼 수 있는데, 이 수치를 상관계수 이라고 한다.
상관계수 r은 서로 같이 변하는 정도를 서로 각기 변하는 정도로 나눈 값을 말한다.
즉, 아래와 같다.
수식으로보면 아래와 같다.
x와 y가 다음과 같다고 가정하자.
그렇다면 각 평균은,
,
분자는,
분모는,
즉 상관계수는,
이와 같이 나온다.
이렇게 나온 상관계수()는 다음과 같이 표현한다.
= -1: 음의 상관관계가 강하다.
-1<<0: 음의 상관관계가 있기는 하다.
= 0: 상관관계가 없다.
0<<1: 양의 상관관계가 있기는 하다.
= +1: 양의 상관관계가 강하다.
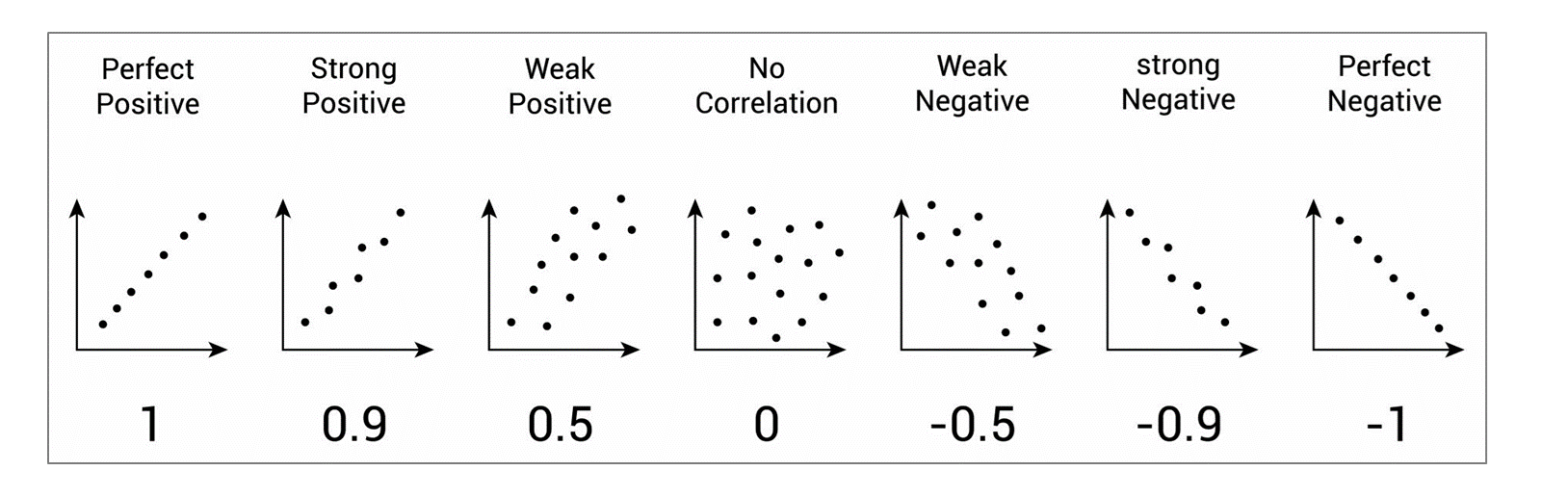
[사진출처] 위키독스 - 상관관계와 인과관계
이렇게 표현하고, 조금 더 크기로 봤을 때는,
0.8~1.0: 매우 강한 상관관계,
0.6~0.8: 강한 상관관계,
0.4~0.6: 중간 정도 상관관계,
0.2~0.4: 약한 상관 관계,
0.0~0.2: 매우 약한 상관관계라고 한다.
( - 가 붙었다고 상관이 없는것은 아니다)
이런 수학적으로 계산하는 과정을 Pandas에서 제공하는 corr() 함수를 사용하면 아주 쉽게 구할 수 있는 것이다.
import pandas as pd
data={
"x": [1, 2, 3, 4, 5, 6, 7, 8, 9, 15],
"y": [10, 20, 30, 40, 50, 60, 70, 80, 90, 100]
}
df=pd.DataFrame(data)
print(df.corr()) x y
x 1.00000 0.94388
y 0.94388 1.00000
x yx 1.00000 0.94388
y 0.94388 1.00000
따라서 이제 공분산에 대해 알아보자면, 먼저 말하지만 공분산과 상관계수는 정말 비슷해서 헷갈릴 수 있다.
공분산은 두 변수가 함께 변하는 방향을 알려준다. 따라서 상관계수와 같이 양의 공분산, 음의 공분산이 존재한다.
하지만 공분산은 단위가 있기 때문에, 두 변수의 단위가 다르면 공분산의 값이 이해하기 어려울 수 있다.
예를 들어, 는 기온을 다루는 °C, y는 아이스크림 판매량을 따루는 개수일 경우두 값이 얼마나 관련 있는지 알기 어렵다.
그리고 공분산을 표준화한 값, 공분산을 두 변수의 표준편차로 나눠준 값이 바로 상관계수()다.
그래서 -1에서 1 사이의 값으로만 나오는 것이고, 두 변수 간의 관계의 강도와 방향을 알 수 있다.
또 상관계수는 단위에 영향을 받지 않는다.
따라서 변수들의 단위가 달라도 비교할 수 있다.
즉 공분산보다 더 간단하고 직관적으로 관계를 파악하는 데 도움을 준다.
다시 위에서 나온 결과를 보면

이게 바로 공분산 행렬이다.
①과 ②는 각각 변수 X와 Y의 분산(단일변수)으로 자기 자신이다. 따라서 항상 1이 나온다.
③과 ④는 각각 변수 X와 Y의 공분산으로 서로 같은 값이다. 공분산 행렬은 대칭행렬이므로 같은 값이다.
⭐ 마무리
이로써 통계 수학에 대한 부분을 정리했으나, 공부를 진행하면서 추가적으로 나오는 부분은 계속해서 추가해 나갈 예정이다.
