python
1.파이썬 핵심 기초 다지기: 헷갈리지 말자!
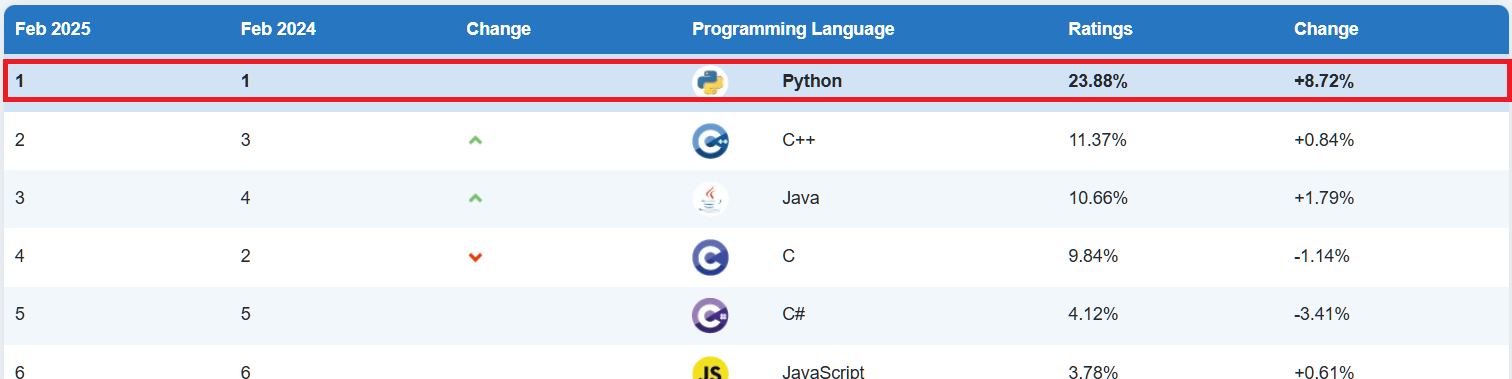
매년 프로그래밍 언어의 순위를 공개하는 기업인 [티오베(TIOBE)](https://www.tiobe.com/tiobe-index/)의 지수를 보면 알 수 있듯, **파이썬은 현재 압도적인 1위**를 차지하고 있는 언어다. 그 이유에는 인공지능(AI)와 데이터 사
2.[파이썬 핵심 기초 다지기] 문자열

저번 글에 이어 자료형(data type)인 기본 자료형에 이어, 컬렉션 자료형이라는 분류가 또 있다. 하지만 컬렉션 자료형에 분류되긴 하지만 대부분 기본 자료형으로 보는 **문자열(str)**에 대해 조금 더 자세히 알아보고자 한다. # 1. 문자열 자료형 문
3.[파이썬 핵심 기초 다지기] 컬렉션 자료형과 리스트

# 1. 컬렉션 자료형(Collection data types) 자료형(data type)인 기본 자료형에 이어, 이번에는 **컬렉션 자료형**이다. 컬렉션 자료형은 여러 요소를 하나로 묶어 다룰 수 있게 하는 데이터 타입으로, 다양한 컬렉션 자료형이 있다. 컬렉션의
4.[파이썬 핵심 기초 다지기] 컬렉션 자료형과 set, dictionary

컬렉션 자료형의 마지막 부분인 set,과 dictionary다. 다시 정리하자면 다음과 같다. > ### 컬렉션 자료형 > 순서형: str(문자열), list(리스트), tuple(튜플) 비순서: set(수학집합), dictonary(사전형태) `set`
5.[파이썬 핵심 기초 다지기] 제어문과 조건문

- 조건문: if, if\~else, if\~elif - 반복문: while, for - 흐름 제어: break, continue 다른 언어에 비해 제어문의 종류가 많지 않다. 하지만 내용은 비슷하다. C, C#, Java 등은 중괄호로 열고 닫지만(`if(조
6.[파이썬 핵심 기초 다지기] 컬렉션 자료형과 튜플

# 1. 튜플(Tuple) - 읽기 전용 List - 선언 - 함수 - 활용 컬렉션 자료형 중 순서형의 문자열(str), 리스트(List)에 이어 마지막 **튜플(tuple)**이다. 튜플은 오직 유일하게 파이썬에만 있는 자료형으로, 반드시 알아야 하는 개념이다
7.[파이썬 핵심 기초 다지기] 반복문, 흐름제어 & Comprehension

- 조건문: if, if\~else, if\~elif - **반복문: while, for** - 흐름 제어: break, continue 지난 조건문(if)문에 이어 반복문이다. 반복문을 쓰는 경우는 두가지가 있다. 1. 만약 apple을 100번 써야 하는
8.[파이썬 핵심 기초 다지기] 함수

- 함수 구조 - 인수 형식 - 변수 유효 범위 - 내장함수 - Lamda # ⭐ 1. 함수 매우 중요한 내용이다. 이 부분을 제대로 이해하지 못한다면 진행이 안되기 때문에 **반드시** 잘 숙지하자. `arr=[1,2,3,4]` 지금까지 이런 데이터를 가지
9.[파이썬 핵심 기초 다지기] 클래스

# 1. 클래스 > 클래스(class) 인스턴스(instance) 객체(object) 속성(attribute) : 변수 메서드(method) : 함수 생성자(constructor) 소멸자(destructor) self 상속, 함수 재정의(override)
10.[Q] iterable이란?

1. iterable iterable을 직역하면 반복할 수 있는이라는 뜻을 가지며, 이는 즉 반복할 수 있는 객체를 의미한다. 하지만 사실 쉽게 말해, 요소를 하나씩 꺼낼 수 있는 자료 구조들을 iterable이라고한다. 즉 요소에 접근할 수 있는 str, list
11.[파이썬 핵심 기초 다지기] 모듈

# 1. 모듈 - 포준모듈: python 설치와 함께 따라오는 모듈 - **사용자모듈**: 프로그래머가 생성한 모듈 - 서드파티(3rd Party) 모듈: 업체에서 제공하는 모듈 모듈이란 함수나 변수 또는 클래스르 모아 놓은 파일이다. 그리고 그 파일은 a.py라
12.[파이썬 핵심 기초 다지기] 파일 입출력

# 1. 파일 입출력 형식은 간단하다. ```python open(파일명, 모드) close() # 열었으면 닫아줘야 한다. ``` 사용했으면 닫아주는 것의 반복이다. 만든 파일이 소스 밖으로 나가는 것은 리소스를 사용한 것이다. 만약 네트워크로 나가는데
13.[프로젝트] 인스타그램 크롤링(1)

웹 크롤링(Web Crawling)을 진행하며 조금 더 난이도를 올려보고 싶어서 이번에는 인스타 그램을 크롤링 해보고자 했다. 삽질을 많이 하다보니 과정이 매끄럽지 못해 글을 둘로 나눠 설명하고자 한다. 이번 글에서는 인스타그램 크롤링의 과정을, 다음 글에서는 검색
14.[프로젝트] 인스타그램 크롤링(2)

저번 글에 이어 상위 10개의 태그들을 기준으로 네이버 쇼핑에서 검색하고 판매 많은순으로 정렬한 상위 5개의 상품들을 크롤링하여 마무리 하고자 한다. 1. 네이버 쇼핑 요소 값 탐색 먼저, 판매 많은순의 url은 다음과 같다. "https://search.shopp
15.[데이터 전처리] Numpy

지금까지 해온 BeautifulSoup, Selenium으로 데이터를 수집하는 과정은 가장 중요한 단계로 가기 위한 초석이 된다. 지금부터는 데이터의 전처리부터 데이터의 분석, 그리고 예측까지 진행할 예정인데 그 중 정말 잘 알아두어야 하는 데이터의 전처리부분
16.[데이터 전처리] Pandas 자료형과 DDA

데이터 전처리는 머신러닝에서 60-70%를 차지하는 중요한 부분이고, 좋은 데이터가 들어와야 학습이 잘 된다. **Pandas는 그 중 가장 중요한 부분**이다. 내용은 쉬운데 구현이 어렵다. 반대로 머신러닝은 내용은 어려운데, 구현은 scikit-learn에
17.[데이터 전처리] Pandas, 변형

저번 Pandas 자료형과 DDA에 대한 글에 이어 이번에는 변형에 대한 부분이다. # 1. 변형 > 데이터의 품질을 높이기 위해 불필요한 부분을 제거하거나 필요한 부분을 정리하는 과정 구조변경, 정렬, 필터링 ## 1.1. 데이터 필터링 (추출) > i
18.[데이터 전처리] Pandas, 데이터 요약과 병합

Pandas의 마지막, 데이터 요약과 병합에 대한 부분이다. # 1. 데이터 요약 > 데이터를 간결하고 유의미한 형태로 요약하고 변형하는 작업 집계, 그룹화, pivot ## 1.1. 집계 함수 이제 컬럼별로 집계함수를 보자. - **1개 컬럼에 대한
19.[Q] 통계 수학 1 - 분산, 표준편차, 상관관계와 상관계수, 공분산 행렬

Pandas의 DDA 부분에서 분산과 표준편차에 대한 부분, 그리고 시각화, EDA 부분에서 상관관계와 상관계수, 공분산 행렬에 대한 내용을 간략하게 설명하고 넘어갔는데, 이번 글에서는 이에 대한 설명을 덧붙이고자 한다. 수학적인 부분이여서 오직 이해를 돕기 위해서지
20.[데이터 전처리] EDA, 시각화 심화 - Tips, 기상청 날씨 데이터 분석

1. 위키독스 연습문제 - Tips > https://wikidocs.net/173541 위키독스에서 제공하는 연습문제인 식당의 팁에 관련한 실습을 진행해보자. 먼저
21.[데이터 분석] CDA

Pandas를 이용해서 DDA, Seaborn을 이용해서 EDA를 했다. 그렇다면 다음은 확증적 데이터 분석 CDA(Confirmatory Data Analysis), 검증이다. 먼저 통계에 대한 개념을 다시 잡고가자. 통계란 다양한 데이터를 이용해 현상을 파악하고
22.[데이터 분석] CDA 심화 (1)

이번에는 CDA에 대한 심화과정이다. 한국보건사회연구원에서 발간한 조사 자료인 한국복지패널의 데이터를 가져다가 실습을 진행한다. # 1. 데이터 전처리 >**링크**: https://www.koweps.re.kr:442/data/data/list.do - 회원가
23.[데이터 분석] CDA 심화 (2)

지난 CDA 심화 (1) 글에 이은 두 번째 글이다. **중간중간 흐름의 연결이 부드럽지 않으면 CDA 심화 (1) 글을 참고하자.** 필요한 라이브러리를 먼저 import 해주고 시작하자. ```python import numpy as np import pand
24.[데이터 분석] DDA, EDA, CDA 실습 (1)

머신러닝 PDA 부분으로 넘어가기 전 총 정리하는 느낌으로 데이터 수집부터 정제, DDA, EDA, CDA를 모두 실습하며 개념을 다 잡아놓고 넘어가고자 한다. 1. 영
25.[데이터 분석] DDA, EDA, CDA 실습 (2)

지난 글에 이어 몇가지 주제들에 대해 더 분석을 진행한다. 이용한 데이터들에 정보는 [데이터 분석] DDA, EDA, CDA 실습 (1)글을 참고하자. 영화 산업 분석
26.[머신러닝] 지도학습과 이진분류

드디어 머신러닝이다. 지금까지 해온 프로그램은 컴퓨터가 정해진 기준대로 일을 한다.예를들어 if문을 사용할때이와 같이 20살이 넘으면 성인이라는 정해진 방식대로 일을했다. 그런데 머신러닝은 특징들을 주어주고 학습을 통해서 규칙을 찾는다.예를들어, 음주여부나 대학생인
27.[머신러닝] 지도학습 - KNN 붓꽃 품종 구분

판다스에서 데이터 셋을 제공하는 것처럼 사이킷런에서도 제공한다. 그중 소규모의 연습용 데이터 셋인 붓꽃 데이터셋을 가져올 것이다. 1. 붓꽃 품종 데이터셋 > https://scikit-learn.org/stable/modules/generated/sklearn.da
28.[머신러닝] 지도학습 - KNR

KNR에 대해 들어가기 전에 전 글에 이어 반드시 알아야할 내용이 추가로 있어서 정리하고 간다. Imbalanced Data Sampling으로 분류 모델에서 데이터의 비율이 깨진 경우, 많은 쪽이나 적은 쪽으로 맞추는 기법이다. 이 Imbalanced Dat
29.[머신러닝] 지도학습 - 단순 선형 회귀

K 최근접 이웃 회귀에서 한계점으로 인접한 이웃만 뽑아냈기에 값이 비슷하지 않으면 아무리 멀어도 항상 같은 이웃들을 가져왔었다. 그래서 이번 내용은 머신러닝의 기반이되는 아주 중요한 선형회귀(Linear Regression) 다. 1. 선형회귀(Linear Regg
30.[머신러닝] 지도학습 - 다중 선형 회귀

# 1. 다중 선형 회귀(Multiple Linear Regression) > 나라별 기대 수명 예측 https://www.kaggle.com/datasets/kumarajarshi/life-expectancy-who 그러면 지금까지 X값이 하나인 단일 선형 회귀
31.[머신러닝] 지도학습 - 비선형 회귀

먼저 지금까지 배운 내용을 조금 정리하자. 지금까지 배운 선형 회귀(Linear Regression)는 단일(단순) 선형 회귀와 다중 선형 회귀가 있었다. > **단일 선형 회귀 (Simple Linear Regression)** - $y = wx + b$에
32.[머신러닝] 지도학습 - 로지스틱 회귀

지금까지 K 최근접 이웃을 KNN으로 분류(문자), KNR으로 회귀(숫자)로, 그리고 선형회귀와 비선형회귀까지 진행했는데, 이번에는 이 선형회귀에 로지스틱 회귀라는 것이 있는데, 이는 사실 선형회귀의 분류라고 한다. 즉 선형회귀안에 분류와 회귀가 있는
33.[머신러닝] 의사 결정 트리와 모델 최적화

# 1. 의사 결정 트리(Decision Tree) 요새 가장 많이 사용되는 의사결정트리(Decision Tree)다. 이 또한 분류와 회귀 둘 다 가능하며, 로지스틱 회귀와의 차이를 중점으로 설명한다. 먼저 필요한 라이브러리 import. ```pytho
34.[머신러닝] 비지도학습

비지도학습은 정답이 없이 데이터를 학습하여 그 속의 패턴 또는 각 데이터 간의 유사도를 학습한다. 그 종류에는 크게 군집분석(Clustering)과 차원축소(Dimensionality Reduction), 연관분석(Association Analysis) 등이 있다
35.[머신러닝] 시계열 분석 (1)

전통 시계열은 통계가 들어간다. X 값이 많으면 잘 나오지 않는다. 알고리즘에는 AR, MA, ARIMA, SARIMA, ARIMAX, SARIMAX 등이 있다. 머신러닝 시계열은 랜덤포레스트는 잘 되는데, 선형회귀는 잘 안맞는다. 또 딥러닝 시계열이라
36.[머신러닝] 시계열 분석 (2) - 구간 평균법과 지수 평활법

기존에는 행단위로 읽어서 Y를 예측했는데, 이는 행단위긴 하지만, 한 컬럼만 두고 과거를 가지고 미래를 예측하는 것이다. X 컬럼에 데이터가 쭉있는데, 시점이라는 것이 있다. 과거 데이터 X를 두고 내일과 모레, 글피 등의 주식예측을 한다거나 그런 것이다. 과거 데
37.[머신러닝] 시계열 분석(3) - ARIMA

사실 지금까지 배운 것들 중에서 사용되는것은 자기상관과 구간 평균법 정도만 사용된다. 계절적 요인이나 트렌드가 있는 것은 비정상 시계열이라고 하는데, 사실은 수학적인 것을 이용해서 이런 요인들을 사용해서 비정상 시계열을 예측했었지만 사실을 잘 못한다. 따라서 이런
38.[머신러닝] 딥러닝 (1) - 기본, 분류

딥러닝이다. 딥러닝은 머신러닝 알고리즘 중 하나이다. 머신러닝의 알고리즘은 굉장히 많았는데, 인공지능 이라는 것은 머신러닝, 딥러닝 등을 합쳐서 하나의 큰 학문인 것이고, 인공지능 안에 있는 지도학습, 비지도학습이 있는거고, 지도학습의 수많은 알고리즘 중 하나가 딥러
39.[머신러닝] 딥러닝 (2) - 회귀

딥러닝은 비정형 데이터를 학습하는데 최적화된 모델이라고 했는데, 정형데이터도 가능하다. 이미지는 다 배열로 읽기때문에 pandas의 정형데이터를 다루는 선형과 같은 모델로 사용할 수 없었지만, 딥러닝으로 이런 정형데이터를 다뤄보겠다. 1. 보스턴 집값 예측 다중 선
40.[머신러닝] 딥러닝 (3) - RNN과 LSTM

0. RNN(Recurrent Neural Network) 지금까지 딥러닝의 기본적인 부분을 배웠다. 딥러닝 모델을 설계해봤으며, 이제 배울 것은 RNN이다. 지금까지의 ANN(Arificial NN)에서는 Activation Function을 relu를 사용했는데(
41.[머신러닝] 딥러닝 (5) - 전력 예측

1. 전력 예측 > https://archive.ics.uci.edu/dataset/321/electricityloaddiagrams20112014 > (다운받는데 좀 걸린다.) 날짜와 특정지역코드로 구성되어있다. 그래서 총 140256개의 데이터를 가지고 매 15분
42.[머신러닝] 시계열 프로젝트
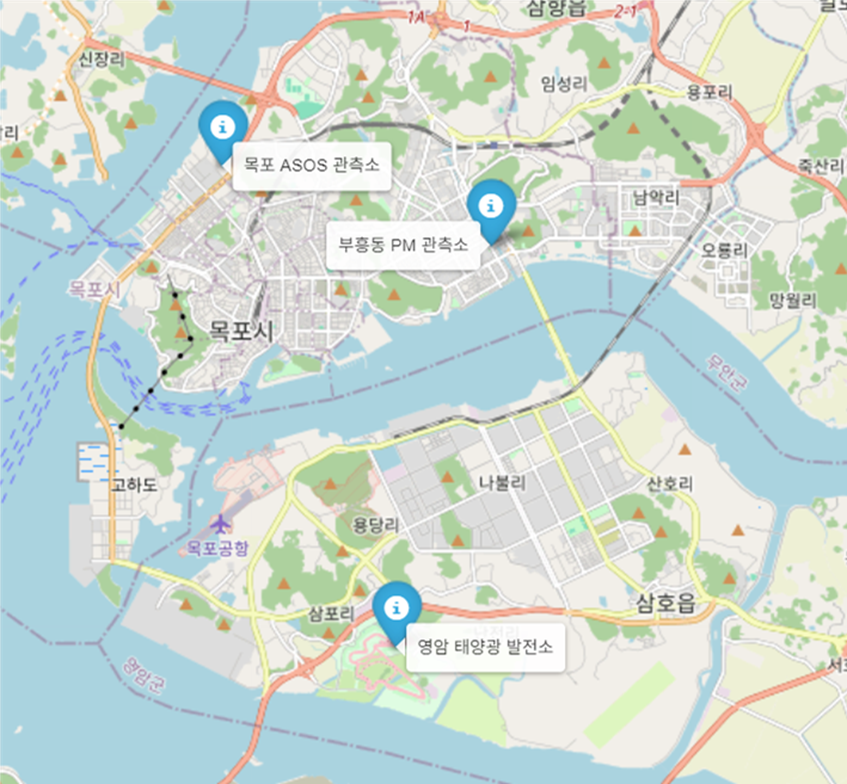
지난 기간동안 시계열 기반 태양광 발전량 예측 프로젝트를 진행했다.지난 머신러닝 프로젝트에서는 따로 정리를 하지 못했는데, 이번 5월 연휴에 맞아 시간이 되어 정리하게 되었다. 기상 및 미세먼지 데이터를 활용하여 태양광 발전량을 시계열 모델로 예측하는 프로젝트다.기상
43.[머신러닝] 딥러닝 (6) - CNN 기초

단층과 다층 퍼셉트론을 ANN이라고 하며 이 다음에 배우는 내용이 CNN이다. 그 다음에 진행하는 내용이 RNN이다. 그런데 프로젝트를 진행하기 위해 RNN으로 잠시 넘어가 LSTM에 대해 배웠던 것이다. 이제 CNN쪽으로 다시 방향을 틀어보자. 1. CNN(Conv
44.[머신러닝] 딥러닝 (7) - CNN 이미지 증강

1. 이미지 증강(Image Augmentation) 실무나 프로젝트를 진행할때 일단 데이터가 있어야하는데.. 그렇다면 이미지를 어떻게 모을까? 크롤링을 진행한다. 그렇다면 다음은? 전처리가 필요하다. 전처리때 무엇을? 만약 동물들의 이미지라면 고양이와 강아지의 사진
45.[머신러닝] 딥러닝 (8) - CNN 전이학습 및 뇌 영상 분류

# 1. 전이학습(Transfer Learning) 전이학습이란 **이미 학습된 모델을 가져와서 활용하는 방법**이다. 딥러닝 모델을 처음 만들다 보면, 레이어를 어떻게 쌓아야 할지 감이 잘 안 온다. 레이어가 많아질수록 조절해야 할 것도 많아지고, 데이터도 그만큼 많
46.[머신러닝] 딥러닝 (9) - CNN 얼굴 이미지 감성 분류

지난 글에 이어서 전이학습 실습을 조금 더 진행해보고자 한다. 이번에는 얼굴 이미지 감성 분류이다. 1. 얼굴 이미지 감성 분류 https://www.kaggle.com/datasets/msambare/fer2013/data 얼굴 이미지로 감정을 분류하는 캐글의 공
47.[머신러닝] 딥러닝 (10) - CNN Xception

이번에는 사진의 진위 여부를 판단하는, 즉 Real과 Fake를 구분하는 실습을 진행한다. 이를 위한 모델은 Xception으로, 항상 이미지는 비슷하게 진행된다. 1. Xception https://www.kaggle.com/datasets/ciplab/real-a
48.[머신러닝] 딥러닝 (11) - CNN AutoEncoder

비지도학습의 오토인코더라는 것이 있다. 오토인코더의 구조는 이와 같다. CNN, encoder를 이용하여 입력 데이터를 받아서 더 작은 차원으로 압축한다. 이는 차원축소같이 생각하면 된다. 그렇게 압축된 잠재 공간(latent space)를 만들어낸다.
49.[머신러닝] 딥러닝 (11) - CNN GAN

❗❗ 어려움 주의 ❗❗ 1. GAN(Generative Adversarial Network) 가상의 생성형 이미지를 만들어내는 GAN이다. 자연어 처리도 챗봇이나 번역쪽으로 포커스가 맞춰지다가 생성형이 나오게 됐다. 질문을 줬을때 만들어주는 것인데, 이미지도 똑같다.
50.[머신러닝] 딥러닝 (12) - CNN GAN (2)

1. CelebA https://www.kaggle.com/datasets/jessicali9530/celeba-dataset 저번 글에 이어서 GAN을 실습해보는데, 이번에는 컬러이미지다. 그런데 크기가 1GB가 넘기 때문에 다 불러올 수 없고, 랜덤하게 100개정
51.[머신러닝] 객체 인식, YOLO

1. 객체 인식 기본적인 이미지 비전 관련 문법들은 이제 어느 정도 익혔고, 비전의 마지막 단계인 객체 인식(Object Detection)을 배워보려고 한다. 사실 순서상으로는 CNN -> 객체 인식 -> GAN이 자연스럽지만, GAN을 먼저 배우고 객체 인식을
52.[머신러닝] YOLO (3) - Dataset

이번에는 이미지와 label을 다 가지고 있는 데이터셋을 가져다가 쓰는 방법을 알아보자. 1. Roboflow Dataset https://public.roboflow.com/object-detection Roboflow의 Public Datasets 중, Aqua
53.[머신러닝] 자연어 처리 (2)

1. 로이터 뉴스 분류 이전 글에서는 간단하게 한번 해봤고, 이번에는 keras에서 제공하는 로이터 뉴스 분류 실습을 진행해보자. 11000개 정도의 뉴스 기사가 있고, 46개의 뉴스 카테고리로 분류 되어있다. 이는 전처리가 다 끝났고, 형태소 분류도 되어있다. 1.
54.[머신러닝] 자연어 처리 (3) - 형태소 분석기

전처리는 토큰화, 정제, 불용어, 어간추출 등이 있고, 이 이후 정수형 인코딩이 들어가서 패딩. 그리고 학습 -> 예측까지. 이렇게 연습해봤는데, 결국에는 다 정리된 것들을 load해서 사용했다. 정제 -> 토큰화 -> 정수형 인코딩의 순서에서 실제 중요한 부분은 정
55.[머신러닝] 자연어 처리 (5) - 시퀀스투시퀀스(Seq2Seq)

0. Seq2Seq 기계번역, 자연어 처리, 챗봇등에서 활용되고 있으며, 기본 단위는 LSTM이다. LSTM은 두개의 정보 처리 흐름을 사용한다. CellState(CS): 장기기억 정보 HiddenState(HS): 단기기억 정보 이렇게 장기기억이 있어서 자연어
56.[머신러닝] 자연어 처리 (6) - Attention과 Transformer

1. Attention & Transformer 지난 글에서는 Seq2Seq에 대해서 다뤘다. 인코더는 입력 시퀀스를 받아서 입력 시퀀스를 압축한 벡터로(Context Vector)로 변환하고, 디코더는 이 벡터를 받아 출력 시퀀스를 생성한다. 그런데 이에는 문제가 있
57.[프로젝트] 안면 인식 기반 추천 프로그램 - (1)
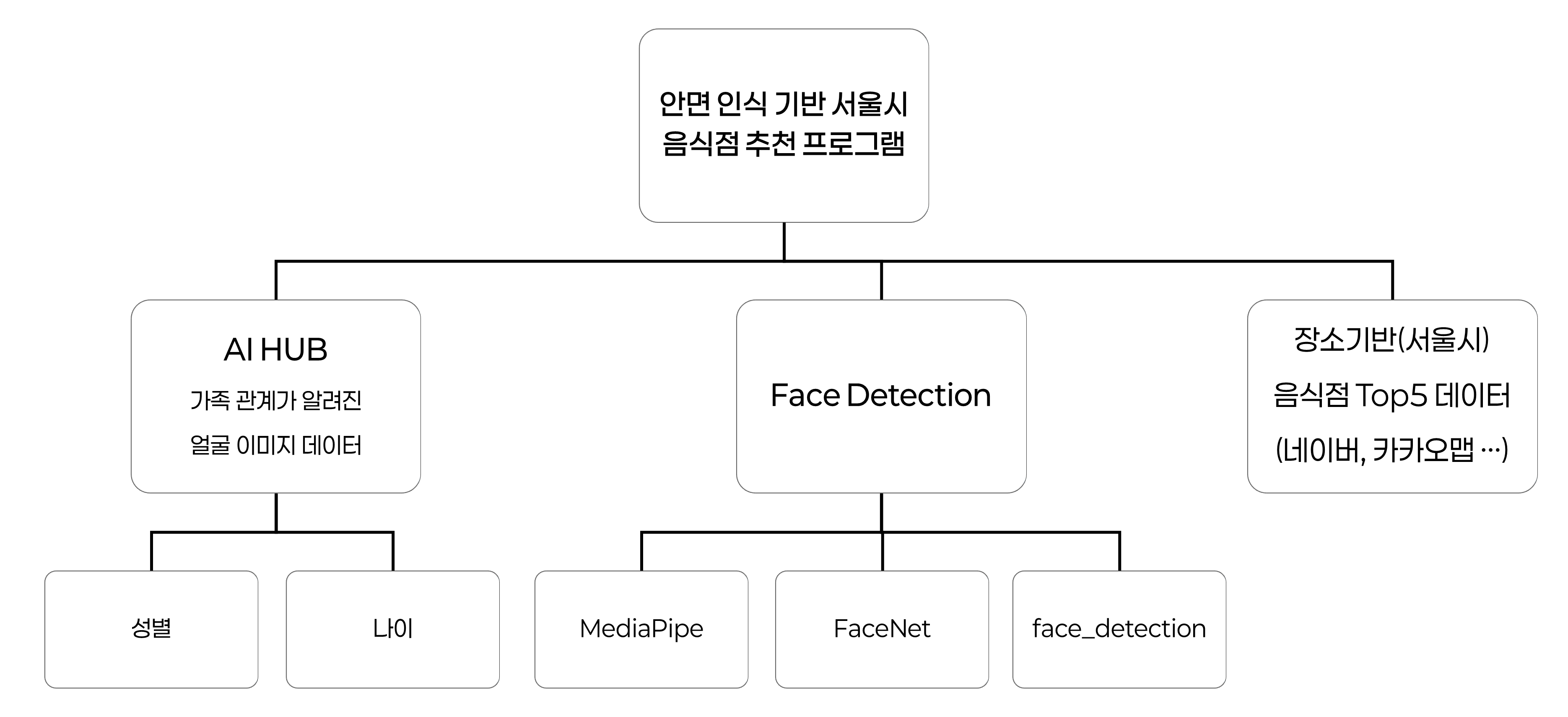
1. 프로젝트 개요 AI HUB에서 제공하는 가족 관계가 알려진 데이터를 이용해 나이와 성별을 예측하도록 학습하고, OpenCV을 이용하여 웹캠을 통해 인식한 인물의 나이와 성별, 인원 수를 기반으로 위치기반 음식점 추천 프로그램이다. 사실 팀프로젝트를 진행 중에 있
58.[프로젝트] 안면 인식 기반 졸음 방지 시스템 - (1)
이번에 안면 관련 CNN 팀 프로젝트를 진행하게 되었다. 그런데 결론부터 말하자면 많이 진행되지는 않았다..😭 그 과정을 담기 위해 작성한다. # 1. 프로젝트 개요 운전자의 안면 인식을 기반으로 졸음 방지 시스템을 만드는 팀 프로젝트를 진행 중에 있다.
59.[프로젝트] 안면 인식 기반 졸음 방지 시스템 - 完
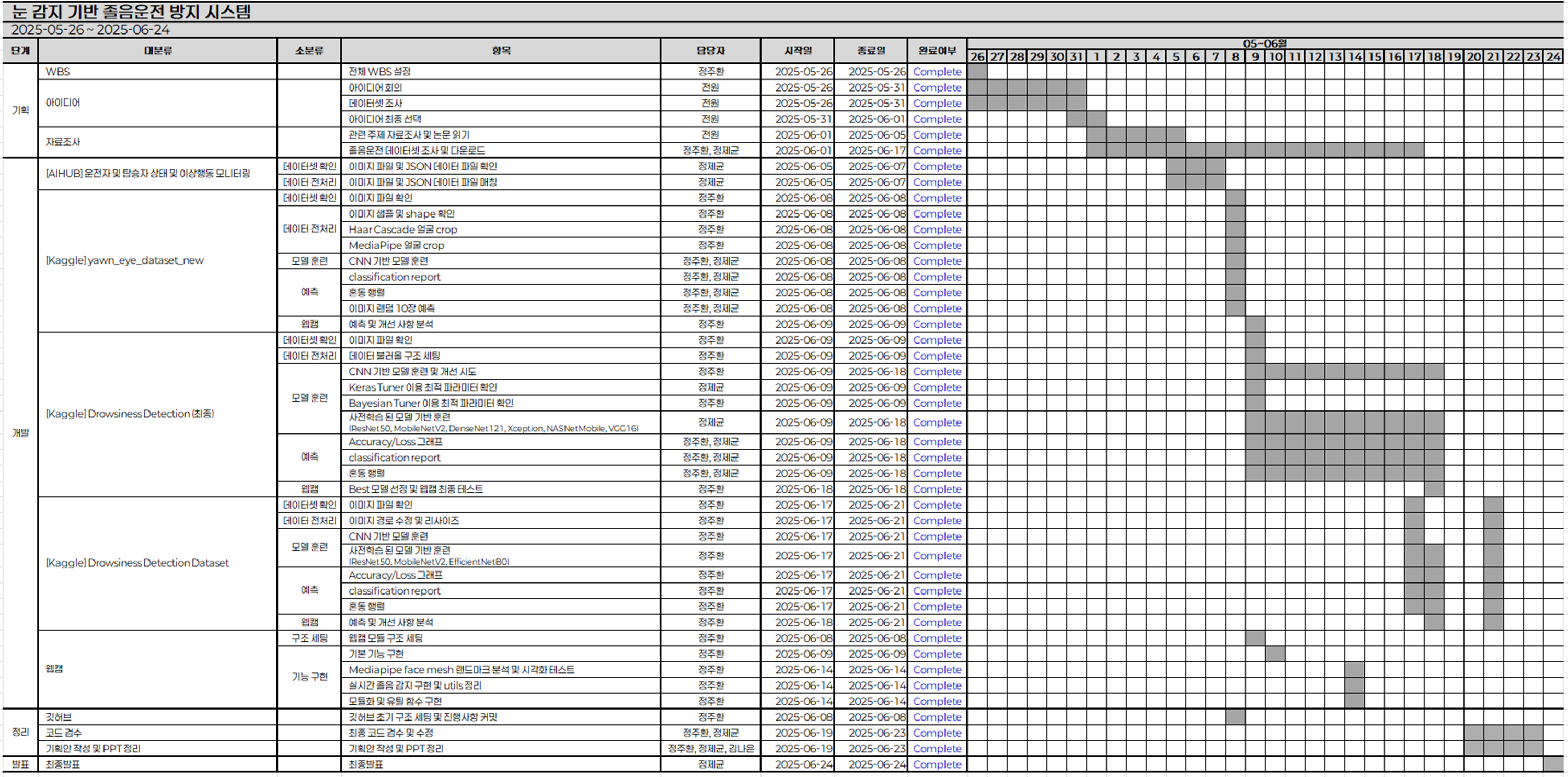
2025년 5월 26일부터 6월 24일까지, 약 한 달간 진행했던 안면 인식 기반 졸음 방지 시스템 개발 프로젝트가 끝났다.동시에 2월 부터 진행했던 이스트캠프 와썹 AI 모델 개발 과정도 6월 25일부로 마무리됐다. 마무리 되는데로 작성하고자 했으나 감기에 걸리고,
60.[프로젝트] 안면 인식 기반 추천 프로그램 - (2)
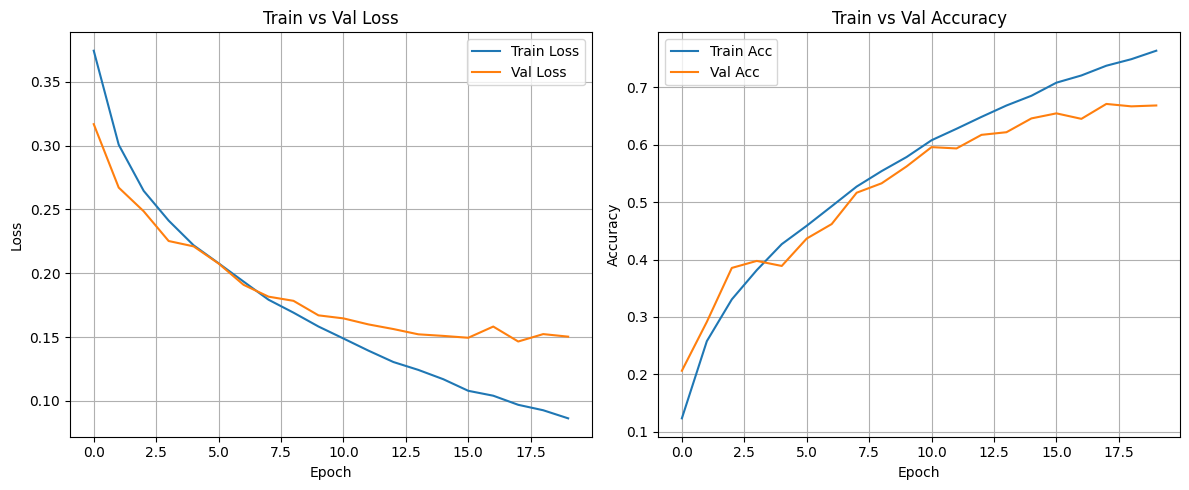
0. 🔥 전달사항 팀 프로젝트가 끝났기에 이번 안면 인식 기반 서울시 음식점 추천 프로그램을 만드는 개인 프로젝트를 진행할 수 있게 됐다. 팀 프로젝트를 진행하면서 매일 하루종일 해당 프로젝트에 시간을 쏟느라 이 부분을 잡지 못해서 시간이 조금 지나서 다시 잡는
61.[ETC] 도커(Docker)

앞선 프로젝트에서 사실 도커 부분도 다뤄보려고 몇시간 정도 이거저거 수정하면서 다뤄보고 공부해봤는데, 생각보다 이번 개인 프로젝트에서는 크게 사용할 이유도 크게 없다고 생각이 들었고, 컨테이너와 로컬 사이에서 환경 설정이 계속 꼬이면서 삽질을 많이해서 아직 개념이 좀
62.[프로젝트] 안면 인식 기반 추천 프로그램 - (3)
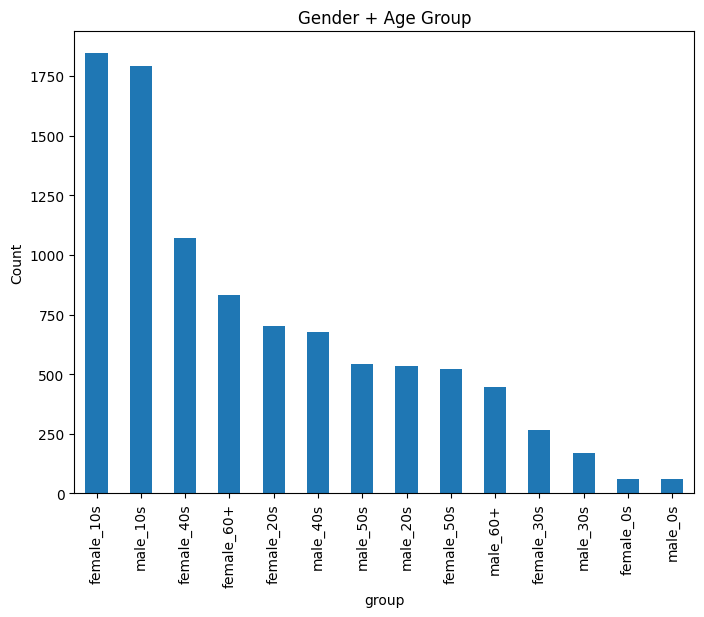
지난 글에 이어서 이번에는 증강부터 다시 진행해서 데이터의 균형을 맞춘 상태로 한번 진행해봤다. 먼저 이번에는 압축해제 후 각도 0(얼굴정면)을 제외한 나머지를 파일 탐색기 에서 미리 삭제 하고난 후 다음 전처리를 진행했다. 또한 이번에는 이미지 파일 자체에 나이도
63.[프로젝트] 안면 인식 기반 추천 프로그램 - (4)
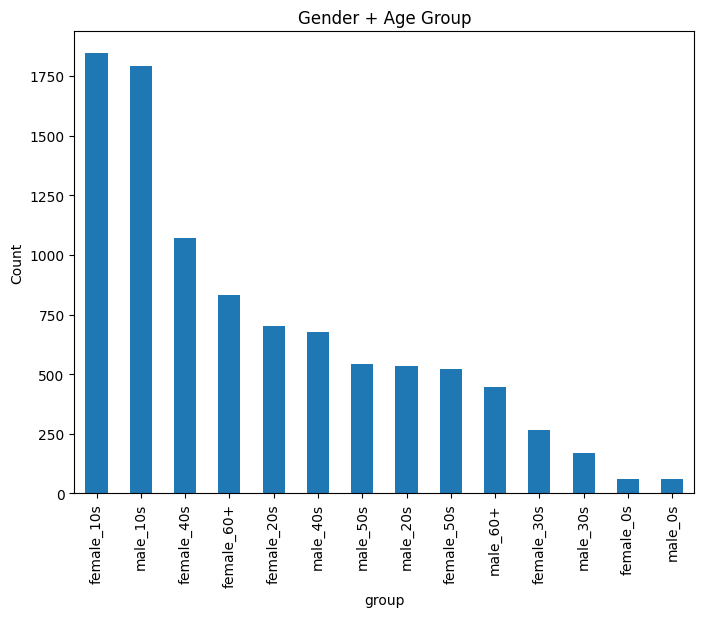
지난 프로젝트 글에서 언급했듯이 직접 CNN 층을 쌓아서 돌린 결과 균형이 많이 깨지고 불안정한 모습을 보였기 때문에 새롭게 전처리를 진행하고서 돌린다고 했었다. 결론부터 말하자면 시간이 굉장히 오래걸리고 결과도 좋지 않았다..우선은 그 과정을 담아본다. 이번에 목
64.[프로젝트] 안면 인식 기반 추천 프로그램 - (5)
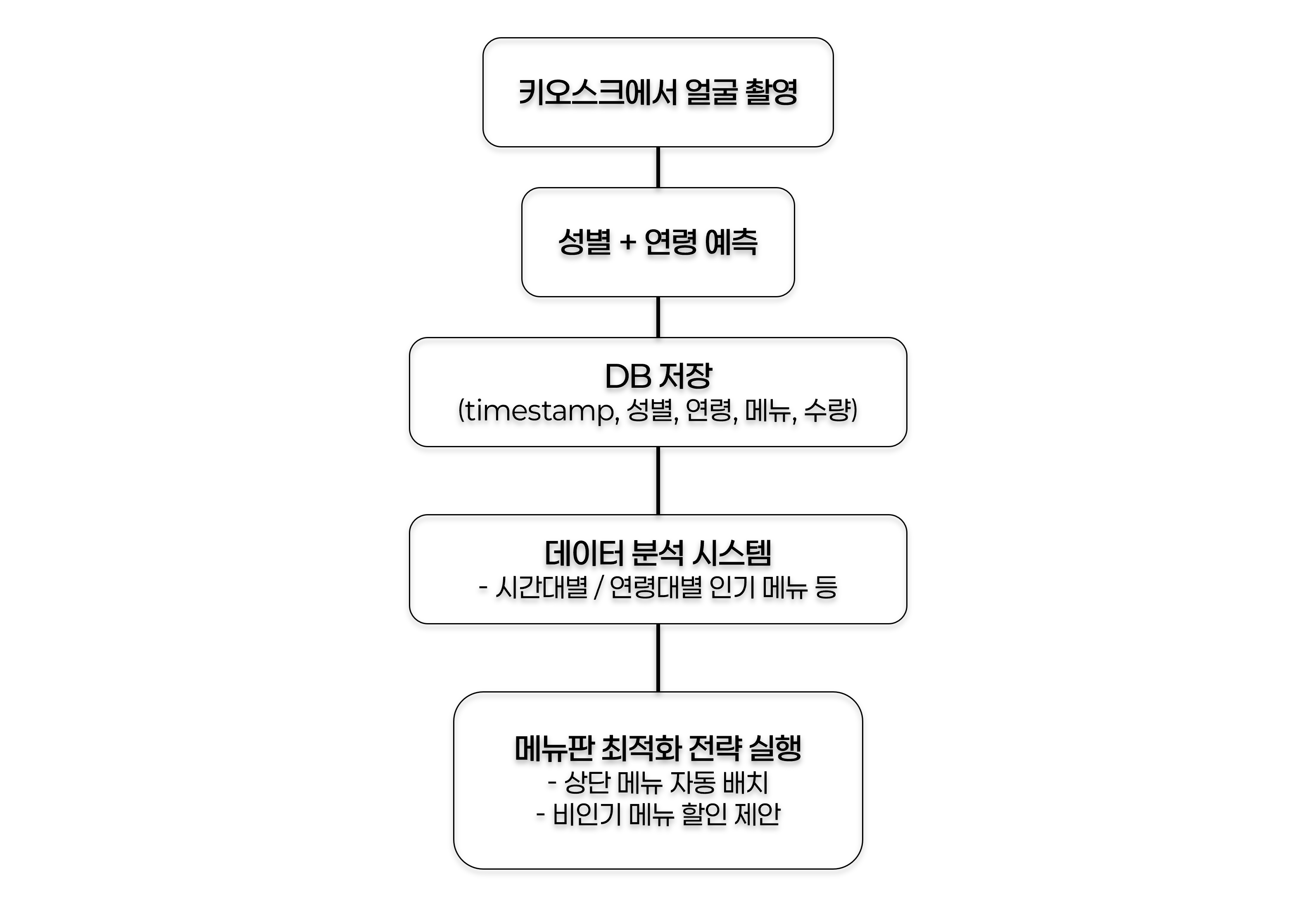
이제 모델 생성을 완료하고 웹캠 기반 얼굴 capture 후 예측하는 코드로 넘어오게 됐다. 이번에 구상한 내용은 우선 다음과 같다. src/models/09_efficientnetb0_best.pth 모델을 이용최종으로 선정한 EfficientNetB0 기반 성별
65.[프로젝트] 안면 인식 기반 추천 프로그램 - (6)
📌 주요 변경사항 이 프로젝트의 마지막 단계인 음식점 추천 부분에 대한 코드만 남은 상태여서 이 추천 시스템을 어떤식으로 작동하게 할지에 대한 고민을 상당히 많이 하게됐다. 처음 프로젝트 구상단계에서 네이버 지도나, 카카오 맵에서 정보를 얻어서 TOP 5를 제공한다
66.[프로젝트] 안면 인식 기반 추천 프로그램 - (7)

기본 기능은 구현완료한 상태로 이제 다듬는 단계다. 먼저 구현하고자 하는 내용은 다음과 같다.1\. 현재 메뉴가 하나만 선택이 가능한데, order_id 를 두어 여러 메뉴를 선택가능하도록 변경2\. 관리자용, 사용자용 두 개로 나누어 관리자용에서는 분석 보기, 사용
67.[프로젝트] 안면 인식 기반 추천 프로그램 - (8)
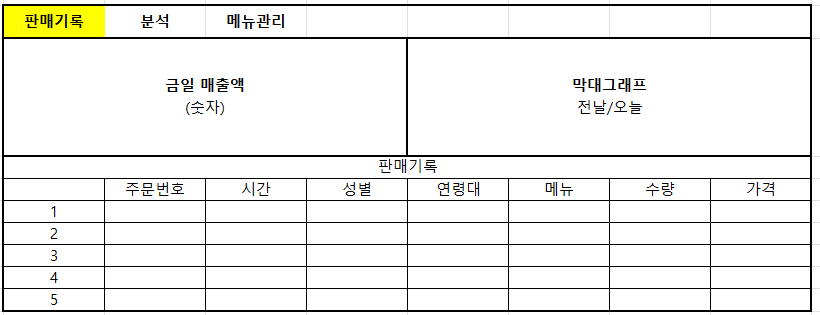
이제 마지막 최종적으로 관리자용 페이지를 좀 더 다듬기만 하면 된다. 현재 로그인하면 그냥 로그인이 완료되었고 네비게이션을 통해 주문 내역으로 들어가도록 되어있으나, 딱 로그인 하여 들어가면 한눈에 볼 수 있는 대시보드를 만드는 것이 좋아보인다.구현하고자 하는 UI
68.[코테] 코딩테스트 준비 (1)
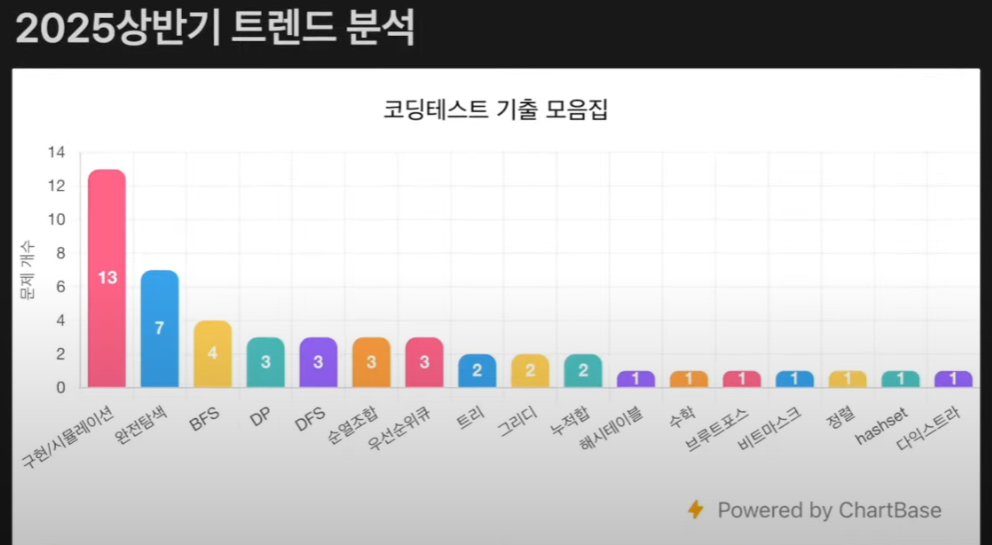
코딩테스트를 준비하는 과정을 따로 Velog에 글로 다루지 않고 백준에서 문제만 풀고 있었는데, 이 과정들을 글로 정리해보면서 되짚어보는 것도 좋을 거 같다. 공부할 때 참고한 영상은 거의 바이블처럼 여겨지는 ⭐ 나동빈님의 이코테 2021 강의 ⭐ 였으며, 이번에는
69.[코테] 코딩테스트 준비 (4)
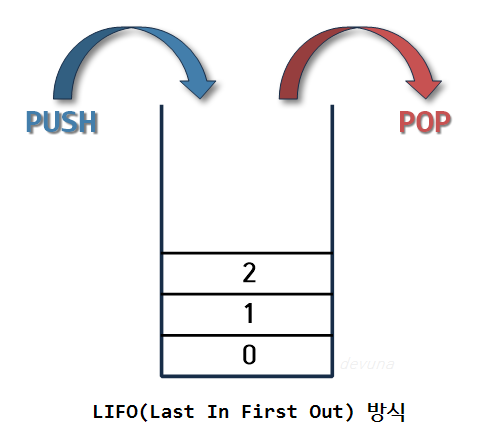
이제부터 코딩테스트에서 출제되는 알고리즘들의 이론에 대한 설명과 그에 상응하는 문제들을 풀어보자. # 1. 그리디 알고리즘 > ## $Greedy, 탐욕적인$ - **⭐ 현재 상황에서 지금 당장 좋은 것만 고르는 알고리즘** - 일반적인 그리디 알고리즘은
70.[코테] 코딩테스트 준비 (5)
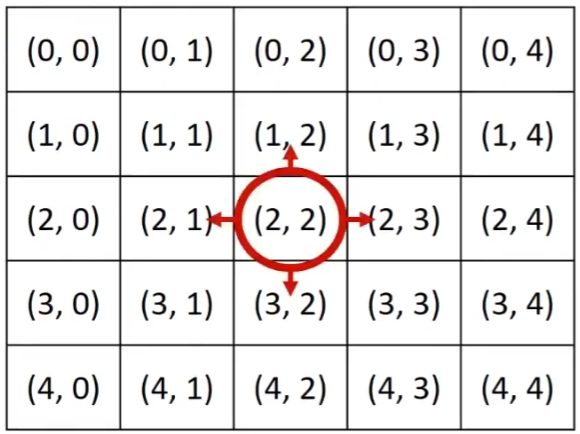
# 1. 구현: 시뮬레이션과 완전 탐색 > ## $Implementation, 구현$ - **⭐ 머릿속에 있는 알고리즘을 소스코드로 바꾸는 과정** - 아무리 알고리즘을 잘 세워도 실제로 코드로 작성해서 프로그램으로 만들지 않으면 그 알고리즘이 동작하지 않을 수
71.[코테] 코딩테스트 준비 (2)

지난 글에 이어서 기본이 되는 문법에 대해 다루는데 역시나 너무 당연한 부분들은 생략하고 놓칠 수 있는 부분들을 다루겠다. # 1. 조건문 ## 1.1. 논리연산자 > 논리 값(T/F) 사이의 연산 수행 - `X and Y`: X와 Y가 모두 참(T)일 때 참(T)
72.[코테] 코딩테스트 준비 (3)
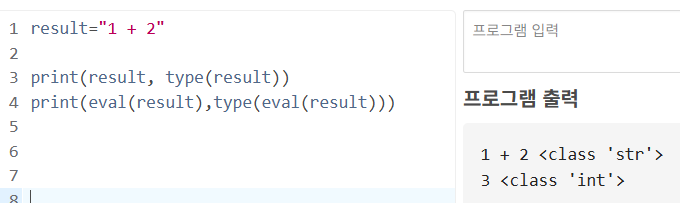
이번에는 파이썬 문법들 중, 자주 사용되는 표준 라이브러리들에 대해 다뤄보자. # 1. 내장 함수 내장 함수는 쭉 자주 다뤘기에 놓치면 안되는 부분들에 대해 조금 정리해보자. ## 1.1. eval() `eval()`함수는 사람의 입장에서 수식으로 표현된 하
73.[코테] 코딩테스트 준비 (6)
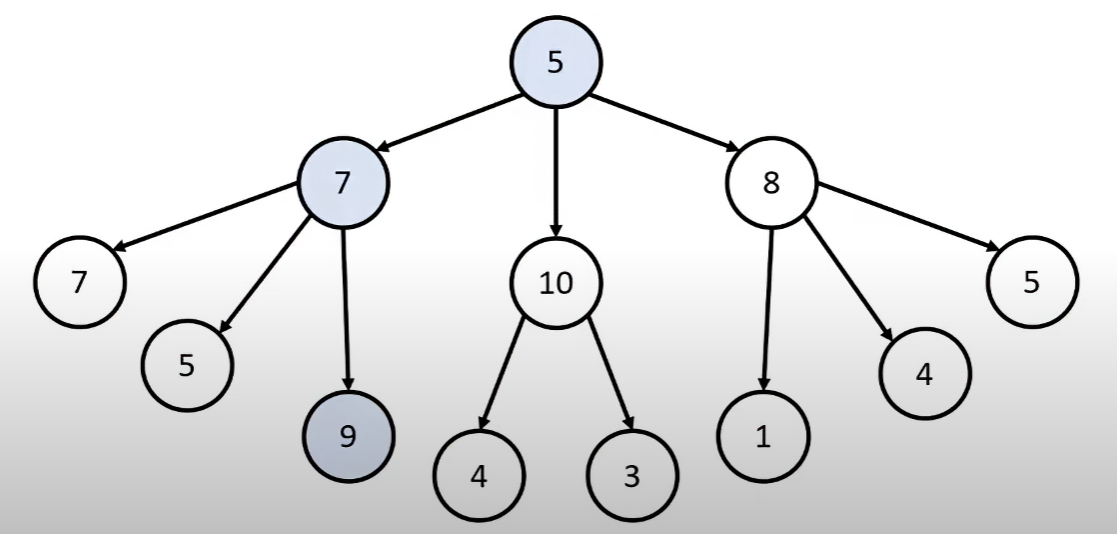
# 1. 그래프 탐색 알고리즘 > ## $탐색, Search$ - 많은 양의 데이터 중 원하는 데이터를 찾는 과정 - **⭐ 대표적인 그래프 탐색 알고리즘: DFS/BFS** - 코딩 테스트에서 매우 자주 등장하는 유형 이에 대해 알기 전에 먼저 반드시 알아야 하는
74.[코테] 코딩테스트 준비 (7)

# 1. 정렬 알고리즘 > ## $정렬, Sorting$ - 데이터를 특정한 기준에 따라 순서대로 나열하는 것 - 데이터가 적을 때, 데이터가 많은데 범위가 특정하게 한정되어 있을 때 등 다양한 상황이 많은데 상황에 맞게 적절한 정렬 알고리즘이 공식처럼 사용된다.