
📌 사용 환경
Python 3.10.2
conda 24.9.0
JupyterLab 4.2.5
머신러닝 PDA 부분으로 넘어가기 전 총 정리하는 느낌으로 데이터 수집부터 정제, DDA, EDA, CDA를 모두 실습하며 개념을 다 잡아놓고 넘어가고자 한다.
1. 영화 산업 분석 프로젝트
- 링크:
- 파일:
- .csv: 통계자료
- .xls: 컬럼 정의서
- 주의사항:
- 계속해서 내용들을 바꾸기 때문에 중간중간 저장을 자주해야함
영화 산업의 현황을 파악하기 위한 데이터 분석을 진행한다.
먼저 필요한 데이터들을 다운로드 받아 내용을 확인한다.
🎬 영화 관람 데이터
- 영화 관람 데이터 통계 자료 (.csv)
2019년도 1분기 부터 2023년도 1분기 까지의 데이터
- 영화 관람 데이터 컬럼정의서 (.xls)

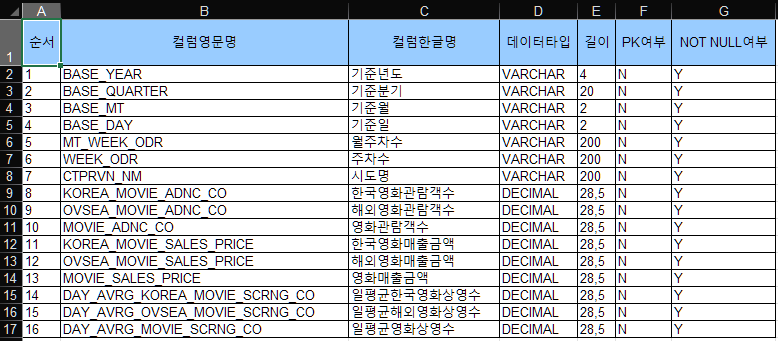
📺 월간 OTT 사용자 수
- 월간 OTT 사용자 수 통계 자료 (.csv)
2019년도 부터 2023년도까지, 각 년도 1월을 기준월으로한 5개의 파일
- 월간 OTT 사용자 수 컬럼정의서 (.xls)

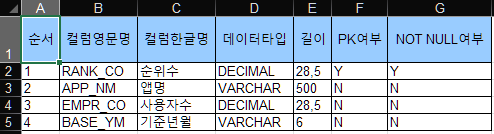
1.1. 라이브러리 설치
먼저 xls 파일을 읽으려면 xlrd를 설치해주어야 한다.
pip install xlrd
이제 필요한 라이브러리를 import해주자.
import numpy as np
import pandas as pd
# 시각화
import seaborn as sns # 통계 전용 시각화
import matplotlib.pyplot as plt # 그래프 및 출력 옵션
import matplotlib as mpl # 환경설정(한글, -옵션 등)
mpl.rc("font", family="Malgun Gothic") # 한글 깨짐 방지
plt.rcParams["axes.unicode_minus"]=False # 마이너스 깨짐 방지
# 검증
import scipy.stats as stats # 통계 검증 lib
import statsmodels.api as sm
from statsmodels.stats.proportion import proportions_ztest # ztest1.2. 데이터 로드 및 정제
먼저 전체적인 전처리를 먼저 해주고 분석하고 싶은대로 변수에 대한 전처리를 진행해야한다.
데이터를 불러오고 파악하자.
1.2.1. 영화 관람 데이터
먼저 영화 관람 데이터다.
movie_data_df=pd.read_csv("../data/data_movie_viewing/CI_MOVIE_VIEWING_INFO_202302.csv")
movie_data_df.shape(3689, 16)총 3689개의 데이터이며, 16개의 컬럼을 가진다.
그러면 간단하게 데이터가 어떤식으로 저장되어있는지 확인하기 위해 head()를 찍어보는데,
16개의 열이라면 가로로 표시하기엔 가독성이 오히려 떨어진다.
따라서 전치행렬을 이용해 보자.
movie_data_df.head().T
그렇다면 컬럼명을 사용하기 편하게 컬럼정의서를 불러와 한글명으로 바꿔주자.
movie_data_column_name=pd.read_excel("../data/data_movie_viewing/영화 관람 데이터_컬럼정의서.xls")
movie_data_column_name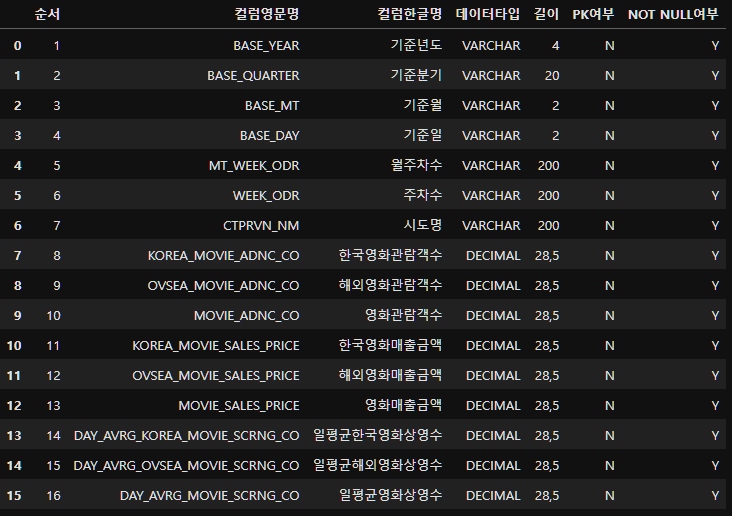
이제 이 컬럼한글명을 가져와 mapping해주어 rename해주면 되는데, 원본 데이터는 두고 copy해서 사용하자.
movie_data = movie_data_df.copy()
# 영문 컬럼명과 한글 컬럼명을 매핑하는 딕셔너리
column_mapping = dict(zip(movie_data_df.columns, movie_data_column_name["컬럼한글명"]))
# 복사본 컬럼명 변경
movie_data.rename(columns=column_mapping, inplace=True)
movie_data.head().T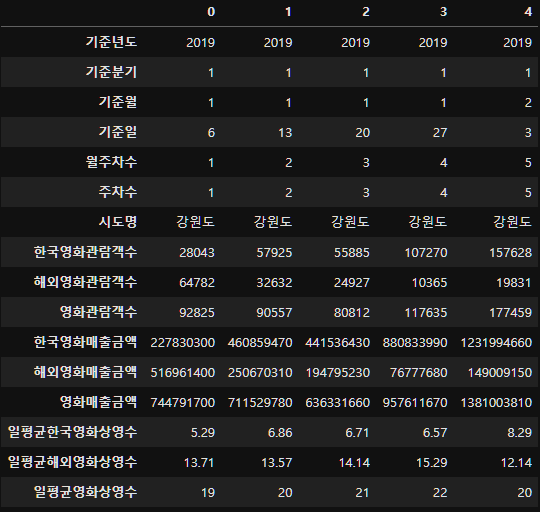
그렇다면 이제 먼저 데이터형과 결측치를 확인해보자.
movie_data.info()movie_data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 3689 entries, 0 to 3688
Data columns (total 16 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 기준년도 3689 non-null int64
1 기준분기 3689 non-null int64
2 기준월 3689 non-null int64
3 기준일 3689 non-null int64
4 월주차수 3689 non-null int64
5 주차수 3689 non-null int64
6 시도명 3689 non-null object
7 한국영화관람객수 3689 non-null int64
8 해외영화관람객수 3689 non-null int64
9 영화관람객수 3689 non-null int64
10 한국영화매출금액 3689 non-null int64
11 해외영화매출금액 3689 non-null int64
12 영화매출금액 3689 non-null int64
13 일평균한국영화상영수 3689 non-null float64
14 일평균해외영화상영수 3689 non-null float64
15 일평균영화상영수 3689 non-null int64
dtypes: float64(2), int64(13), object(1)
memory usage: 461.2+ KB여기서 데이터형을 보니 기준년도, 기준분기, 기준월과 같은 날짜에 관한 부분이 모두 int형인 것을 알 수 있다.
따라서 먼저 파생변수를 하나 만들어서 "날짜"라는 컬럼을 생성하자.
파생변수 생성하기 전 먼저 원본데이터를 건드리지 않기위해 copy한 후 진행한다.
movie_data_copy=movie_data.copy()
movie_data_copy["날짜"] = pd.to_datetime(movie_data_copy["기준년도"].astype(str) + '-' +
movie_data_copy["기준월"].astype(str).str.zfill(2) + '-' +
movie_data_copy["기준일"].astype(str).str.zfill(2))
movie_data_copy.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 3689 entries, 0 to 3688
Data columns (total 17 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 기준년도 3689 non-null int64
1 기준분기 3689 non-null int64
2 기준월 3689 non-null int64
3 기준일 3689 non-null int64
4 월주차수 3689 non-null int64
5 주차수 3689 non-null int64
6 시도명 3689 non-null object
7 한국영화관람객수 3689 non-null int64
8 해외영화관람객수 3689 non-null int64
9 영화관람객수 3689 non-null int64
10 한국영화매출금액 3689 non-null int64
11 해외영화매출금액 3689 non-null int64
12 영화매출금액 3689 non-null int64
13 일평균한국영화상영수 3689 non-null float64
14 일평균해외영화상영수 3689 non-null float64
15 일평균영화상영수 3689 non-null int64
16 날짜 3689 non-null datetime64[ns]
dtypes: datetime64[ns](1), float64(2), int64(13), object(1)
memory usage: 490.1+ KBmovie_data_copy.head()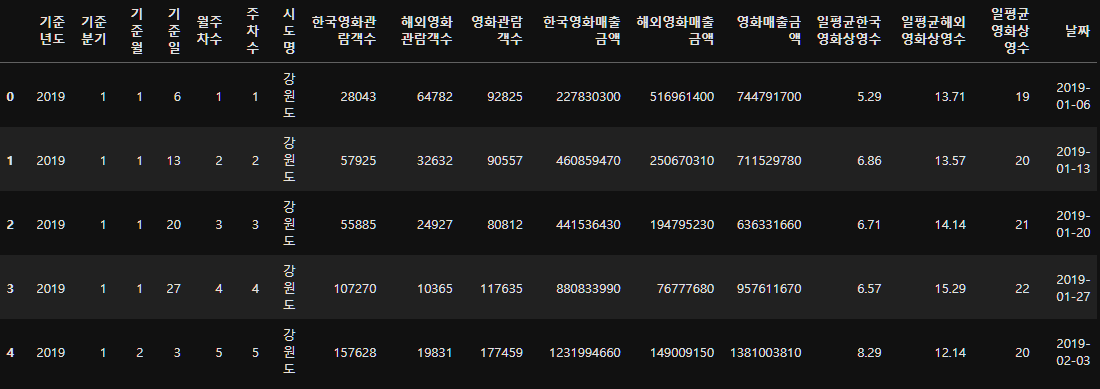
이렇게 날짜라는 컬럼을 새로 생성했다.
datetime형이기 때문에 순서형(시간)으로 사용 가능하다.
이제 다시 결측치를 확인하자.
movie_data_copy.isna().sum()기준년도 0
기준분기 0
기준월 0
기준일 0
월주차수 0
주차수 0
시도명 0
한국영화관람객수 0
해외영화관람객수 0
영화관람객수 0
한국영화매출금액 0
해외영화매출금액 0
영화매출금액 0
일평균한국영화상영수 0
일평균해외영화상영수 0
일평균영화상영수 0
날짜 0
dtype: int64결측치는 없고, 변수들의 분포를 확인해보자.
movie_data_copy.describe().T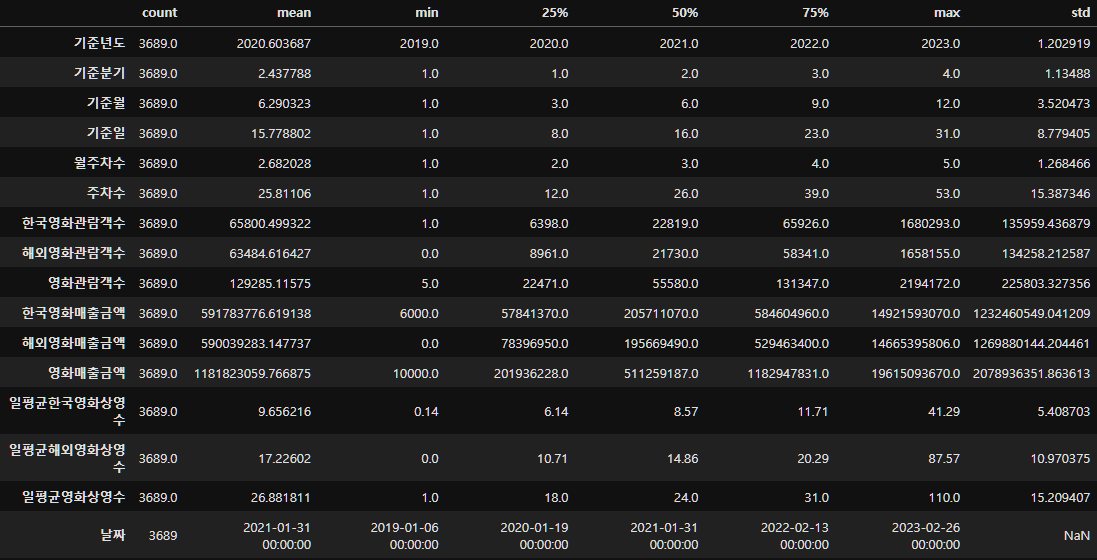
movie_data_copy.describe(include="object").T
movie_data_copy["시도명"].unique()array(['강원도', '경기도', '경상남도', '경상북도', '광주광역시', '대구광역시', '대전광역시', '부산광역시',
'서울특별시', '세종특별자치시', '울산광역시', '인천광역시', '전라남도', '전라북도', '제주특별자치도',
'충청남도', '충청북도'], dtype=object)이제 기본적인 전처리를 완료했으니 이를 사용하기 위해 저장하자.
movie_data_copy.to_csv("../data/data_movie_viewing/movie_data.csv", index=False, encoding="cp949")1.2.2. 월간 OTT 사용자 수
이번에는 월간 OTT 사용자 수 데이터다.
이 데이터는 총 5개의 파일로 이루어져있기 때문에 병합해줘야 한다.
import os
file_paths=[
"../data/data_monthly_ott_users/(sample)IGA_MT_OTT_EMPR_CO_LIST_2019.csv",
"../data/data_monthly_ott_users/(sample)IGA_MT_OTT_EMPR_CO_LIST_2020.csv",
"../data/data_monthly_ott_users/(sample)IGA_MT_OTT_EMPR_CO_LIST_2021.csv",
"../data/data_monthly_ott_users/(sample)IGA_MT_OTT_EMPR_CO_LIST_2022.csv",
"../data/data_monthly_ott_users/(sample)IGA_MT_OTT_EMPR_CO_LIST_2023.csv"
]
lst=[]
for file in file_paths:
df=pd.read_csv(file)
lst.append(df)
merged_ott_user_data=pd.concat(lst, ignore_index=True)
merged_ott_user_data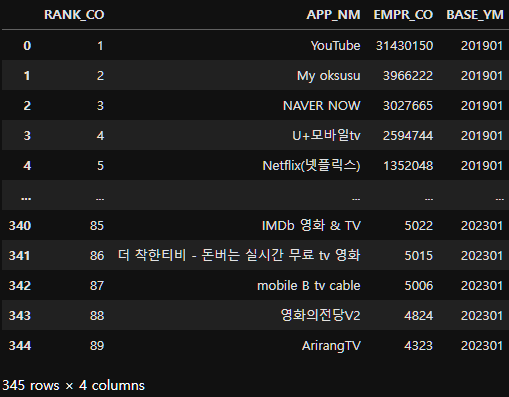
merged_ott_user_data.shape(345, 4)merged_ott_user_data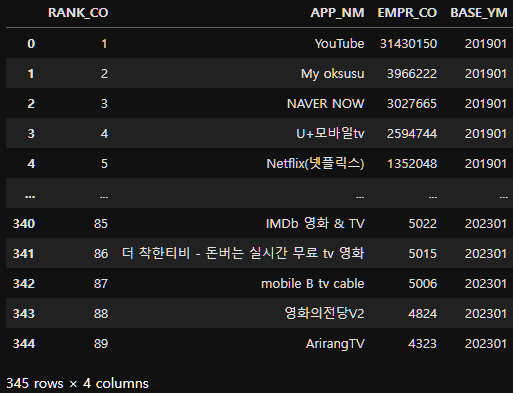
이제 이 dataframe의 컬럼명도 바꿔주자.
ott_user_data_column_name=pd.read_excel("../data/data_monthly_ott_users/월간 OTT 사용자 수_컬럼정의서.xls")
ott_user_data_column_name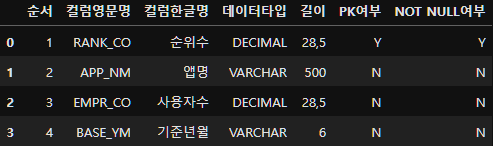
똑같이 원본은 건들지 말고 copy한 후, 컬럼한글명을 가져와 mapping해주어 rename해주자.
merged_ott_user_data_copy=merged_ott_user_data_df.copy()
column_mapping=dict(zip(merged_ott_user_data_copy.columns, ott_user_data_column_name["컬럼한글명"]))
merged_ott_user_data_copy.rename(columns=column_mapping, inplace=True)
merged_ott_user_data_copy.head()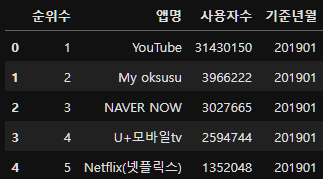
그렇다면 이제 먼저 데이터형과 결측치를 확인해보자.
merged_ott_user_data_copy.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 345 entries, 0 to 344
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 순위수 345 non-null int64
1 앱명 345 non-null object
2 사용자수 345 non-null int64
3 기준년월 345 non-null int64
dtypes: int64(3), object(1)
memory usage: 10.9+ KBmerged_ott_user_data_copy.isna().sum()순위수 0
앱명 0
사용자수 0
기준년월 0
dtype: int64결측치는 없으니 변수들의 분포를 확인하자.
merged_ott_user_data_copy.describe().T
merged_ott_user_data_copy.describe(include="object")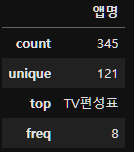
merged_ott_user_data_copy["앱명"].unique()array(['YouTube', 'My oksusu', 'NAVER NOW', 'U+모바일tv', 'Netflix(넷플릭스)',
'seezn(시즌) - 오늘의 즐거운 습관!',
'BuzzVideo버즈비디오 - 화제의 동영상,재미있는 GIF 및 TV 쇼', 'Wavve(웨이브)', 'TVING',
'SBS - 온에어, VOD, 방청', '미디어팩 - TV,음악,웹툰을 한 방에!', '스마트ⓜTV', '왓챠', ... '달섬티비 - 지상파, DMB, 실시간TV', '바바요 (babayo)',
'스포키 – 스포츠 라이브 중계, 경기 일정, 커뮤니티', '누누티비 – 한국 실시간TV, noonooTV',
'공중파 실시간TV – MBC,KBS,SBS,JTBC 등'], dtype=object)
merged_ott_user_data_copy["앱명"].unique().size121이제 변경을 완료했으니 저장해주자.
이때, 앱명에 -가 포함되어 있으니 제거해준다.
merged_ott_user_data_copy.replace({"–": "-"}, regex=True, inplace=True)
merged_ott_user_data_copy.to_csv("../data/data_monthly_ott_users/ott_user_data.csv", index=False, encoding="cp949")1.3. 분석
이제 어떤 것들을 분석할지를 정하자.
📌 분석 주제
- 서울시 년도별 관람객 수 변화 분석
- 지역별 평균 영화 관람객 수 차이 분석
- 각년도별 국내 영화와 해외 영화 관람객 수 차이 분석
- 영화 관람객 수와 영화 상영횟수 상관 분석
- OTT 사용자 수와 영화 관람객 수 관계 분석
📌 이제 각 주제에 대해 다음과 같은 절차를 거쳐서 진행한다.
- 1단계) DDA, 변수 검토 및 전처리
- 분석에 활용할 변수 전처리
- 변수의 특징 파악, 이상치와 결측치 정제
- 변수의 값을 다루기 편하게 바꾸기
- 2단계) EDA, 변수 간 관계 분석
- 변수 간 관계 분석
- 데이터 요약 표(groupby, pivot_table), 그래프 만들기
- 3단계) CDA, 통계적 가설 검정
- 가설 설정
- 가설 검증 절차
1.3.1. 서울시 년도별 관람객 수 변화 분석
⭐ 서울시의 년도를 기준으로 관람객 수가 어떻게 변하는지
- DDA: 분석에 활용할 변수(날짜, 관람객수) 전처리
- 이상치, 결측치 정제
- 변수값 다루기 편하게 수정: 기준년도 + 기준월 + 기준일 -> 날짜
- EDA: 변수 간 관게 분석
- 데이터 요약표: 년도별 관람객수 합계 요약표
- 그래프 만들기: x(년도(숫자, 시간), y(관람객수(숫자) -> lineplot
- CDA: 검증
- x(년도(숫자), y(관람객수(숫자): 상관분석 -> 정규성 검증 -> Pearson / Spearman
먼저 사용할 데이터를 불러온다.
movie_data=pd.read_csv("../data/data_movie_viewing/movie_data.csv", encoding="cp949")
movie_data.head().T
이 데이터를 기준으로 분석을 진행한다.
이번 분석 주제는 서울시의 년도별 관람객 수의 변화 분석이기 때문에 순서는 다음과 같을 것이다.
- "시도명"을 확인하여 서울특별시인 데이터들만 추출
- 년도를 기준으로 했기때문에 "기준년도" 컬럼의 이상치나 결측치를 확인
- 영화관람객수부터가 유의미한 차이를 보이기 때문에, 이상치나 결측치 확인 후 간단한 시각화
- 기준년도별 영화관람객수 분석
- 통계적 가설 검정
1.3.1.1. 시도명 변수 검토 및 전처리
이제 서울시의 데이터들만 추출해내면 된다.
먼저 시도명들이 어떤 이름들로 저장되어 있는지 확인하자.
movie_data["시도명"].value_counts()시도명
강원도 217
세종특별자치시 217
충청남도 217
제주특별자치도 217
전라북도 217
전라남도 217
인천광역시 217
울산광역시 217
서울특별시 217
경기도 217
부산광역시 217
대전광역시 217
대구광역시 217
광주광역시 217
경상북도 217
경상남도 217
충청북도 217
Name: count, dtype: int64각 지역의 데이터들의 개수는 동일하다.
movie_data["시도명"].unique()array(['강원도', '경기도', '경상남도', '경상북도', '광주광역시', '대구광역시', '대전광역시', '부산광역시',
'서울특별시', '세종특별자치시', '울산광역시', '인천광역시', '전라남도', '전라북도', '제주특별자치도',
'충청남도', '충청북도'], dtype=object)
서울시가 아닌 서울특별시로 저장되어 있음을 확인했기 때문에 이를 이용하여 추출하자.
seoul_movie_data=movie_data[movie_data["시도명"]=="서울특별시"]
seoul_movie_data.head()
서울특별시의 영화 정보만 추출했다.
이를 이용하여 나머지 변수들을 처리하자.
1.3.1.2. 날짜 변수 검토 및 전처리
이상치, 결측치 체크
년도를 기준으로 분석을 진행하기 때문에 "기준년도" 컬럼의 이상치나 결측치를 확인해보자.
seoul_movie_data["기준년도"].describe().astype(int)count 217
mean 2020
std 1
min 2019
25% 2020
50% 2021
75% 2022
max 2023
Name: 기준년도, dtype: int32이를보니 이상치는 없는 거 같고, 결측치를 확인하면,
seoul_movie_data["기준년도"].isna().sum()0다른 기준월과 기준일은 전체 데이터 전처리를 하는 과정에서
"날짜"라는 파생변수를 만들때 문제없이 생성한 것을 확인했기 때문에 따로 확인하지 않겠다.
1.3.1.3. 영화관람객수 변수 검토 및 전처리
이제 이 부분부터가 실질적으로 필요한 데이터다.
영화관람객수부터가 유의미한 차이를 보이기 때문에,
먼저 이상치나 결측치 확인 후 간단한 시각화를 진행한다.
구조는 아래와 같았다.
seoul_movie_data.head()
seoul_movie_data["영화관람객수"].info()<class 'pandas.core.series.Series'>
Index: 217 entries, 416 to 3680
Series name: 영화관람객수
Non-Null Count Dtype
-------------- -----
217 non-null int64
dtypes: int64(1)
memory usage: 3.4 KB통계량을 확인할때는 표준편차와 평균 등을 나타내기 때문에 float형으로 나타나니까 .astpye(int)를 붙여준다.
seoul_movie_data["영화관람객수"].describe().astype(int)count 217
mean 573679
std 419191
min 50904
25% 244508
50% 420232
75% 838043
max 1985574
Name: 영화관람객수, dtype: int32이를 보니 영화관람객수의 최소 min값이 50904다.
코로나 때를 생각했을때 조금 더 적을 거라고 생각했는데 큰 차이는 없는 거 같다.
결측치가 있는지만 확인해보고 시각화해보자.
seoul_movie_data["영화관람객수"].isna().sum()0이제 연속형(숫자)인 영화관람객수를 시각화하려면 histplot을 사용하면 된다.
sns.histplot(data=seoul_movie_data, x="영화관람객수", kde=True)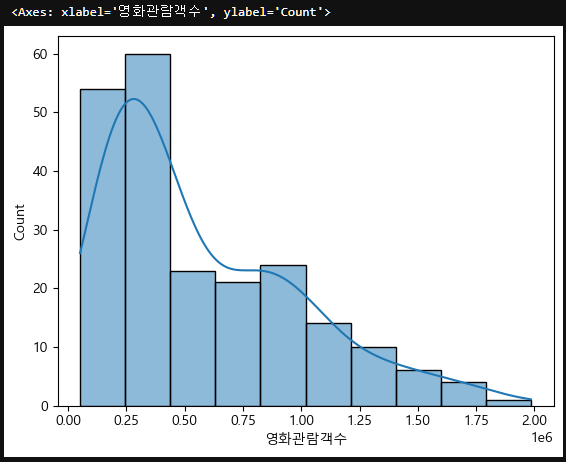
1.3.1.4. 기준년도별 영화관람객수 분석
데이터 요약표, 시각화
이제 변수들의 전처리는 다 끝났으니 기준년도별 영화관람객수를 분석해보자.
x는 기준년도도 연속형임과 동시에 순서형이며, y는 영화관람객수로 연속형이다.
lineplot을 사용하자.
sns.lineplot(data=seoul_movie_data, x="기준년도", y="영화관람객수", errorbar=None)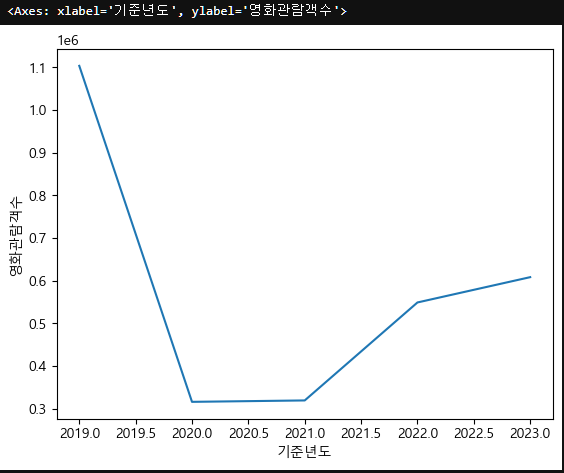
시각화를 이렇게 표현할 수 있고, x와 y가 둘 다 연속형일때 상관분석을 진행할 수 있다.
먼저 필요없는 컬럼들은 drop 해주자.
단, drop하기 전에는 반드시 copy를 한 후 진행하자.
seoul_movie_data_copy=seoul_movie_data.copy()
seoul_movie_data_copy=seoul_movie_data_copy.drop(["기준분기",
"월주차수",
"주차수",
"한국영화관람객수",
"해외영화관람객수",
"한국영화매출금액",
"해외영화매출금액",
"일평균한국영화상영수",
"일평균해외영화상영수"],
axis=1)이후 연속형들의 상관분석을 진행하자.
seoul_movie_data_copy_num=seoul_movie_data_copy.select_dtypes(include="number")
round(seoul_movie_data_copy_num.corr(), 2)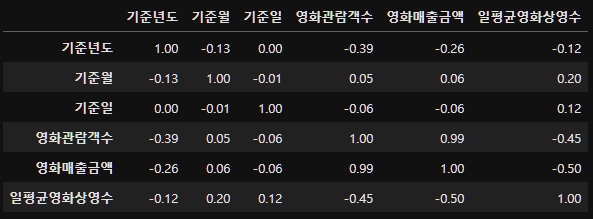
그리고 이를 heatmap으로 표현하면 다음과 같다.
plt.figure(figsize=(10,5))
sns.heatmap(seoul_movie_data_copy_num.corr(), annot=True)
plt.show()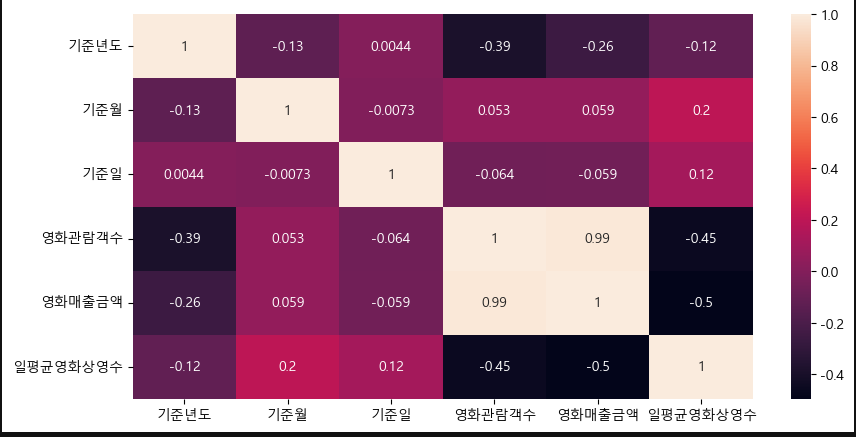
그렇다면 기준년도와 영화매출금액둘의 scatterplot을 보면 다음과 같다.
sns.scatterplot(data=seoul_movie_data_copy_num, x="기준년도", y="영화매출금액")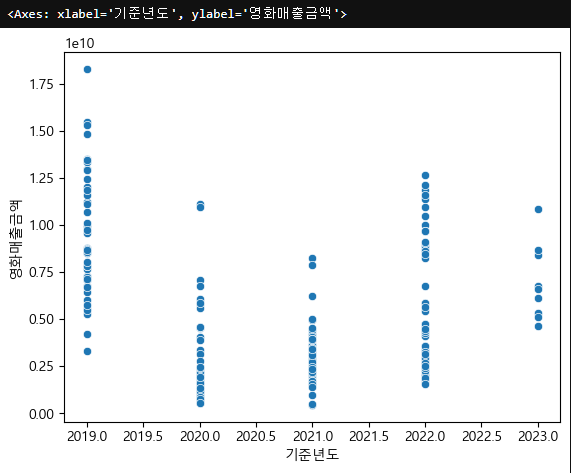
1.3.1.5. 통계적 가설 검정
년도별 영화관람객수가 지역에 따라 다를지
다변수, x(년도(연속(숫자))), y(영화관람객수(연속(숫자)))
가설:
- 귀무가설: 년도별 영화관람객수의 차이는 없다.
- 대립가설: 년도별 영화관람객수의 차이가 있다.
이제 이렇게 분석을 완료했으니 이제 CDA, 통계적 가설 검정을 해야한다.
정규성 검정을 먼저 진행해자.
y에 따라 움직이지만 둘 다 확인해보자.
stats.normaltest(seoul_movie_data_copy_num["기준년도"])NormaltestResult(statistic=73.36442024548982, pvalue=1.172515411232013e-16)pvalue 0.00...117 < 0.05 유의수준 이므로 비정규분포이며,
stats.normaltest(seoul_movie_data_copy_num["영화관람객수"])NormaltestResult(statistic=30.778346279926943, pvalue=2.0728459352682257e-07)pvalue 0.00...207 < 0.05 유의수준 이므로 비정규분포이다.
따라서 spearmanr() 함수를 사용한다.
stats.spearmanr(seoul_movie_data_copy_num["기준년도"], seoul_movie_data_copy_num["영화관람객수"])SignificanceResult(statistic=-0.2770086239911602, pvalue=3.498956625114585e-05)pvalue 0.00..349 < 0.05 유의수준으로 대립가설이 참이고, 귀무가설이 기각된다.
이렇게하여 분석결과는 Spearman 검정을 통해 년도에 따라 영화관람객수의 차이로 음의 상관 관계가 있다(통계량: -0.277, pvalue < 0.05)가 나온다.
분석결과를 한장으로 요약하려면, 시각화한 사진과 년도별 영화관람객수 비교표 사진으로 연도별로 차이가 있다는 점, Spearman 검정 결과를 통해 가설까지 검증하면 된다.
이번에는 데이터를 찾는데 시간이 오래걸려 주제를 한가지만 진행했다.
다음글에서 주제들을 이어서 진행한다.
