📌 공부할 때 참고한 영상은 나동빈님의 이코테 2021 강의 입니다.
지난 글에 이어서 기본이 되는 문법에 대해 다루는데 역시나 너무 당연한 부분들은 생략하고 놓칠 수 있는 부분들을 다루겠다.
1. 조건문
1.1. 논리연산자
논리 값(T/F) 사이의 연산 수행
X and Y: X와 Y가 모두 참(T)일 때 참(T)X or Y: X와 Y 중에 하나만 참(T)이어도 참(T)not X: X가 거짓(F)일 때 참(T)
응용
if True or False: print("Yes") # Yesa=10 if a<=20 and a>=10: print("Yes") # Yes
1.2. 기타연산자
in/not in: 다수의 데이터를 담는 자료형에서 사용됨- 리스트, 튜플, 문자열, 딕셔너리
x in 리스트: 리스트 안에 들어가 있을 때 참(T)x not in 문자열: 문자열 안에 들어가 있지 않을 때 참(T)
pass: 조건문에서 아무것도 처리하고 싶지 않을 때 사용- 보통 디버깅 과정에서 사용
a=10 if a>=10: pass else: print("a<30")
1.3. ⭐ 조건문 간소화
- 조건부 표현식 if~else문 한 줄에 작성
a=10
result="a>=10" if a>=10 else "a<10"
print(result) # a>=101.4. ⭐ 조건문 내에서의 수학의 부등식 그대로 사용 가능
대부분의 프로그래밍 언어에서는 조건문이 반복적으로 사용되면 순차적으로 처리한다.
다음을 보면 알 수 있다.

이렇게 본다면 문제가 없이 출력된다고 생각할 수 있지만 실상은 다르다.
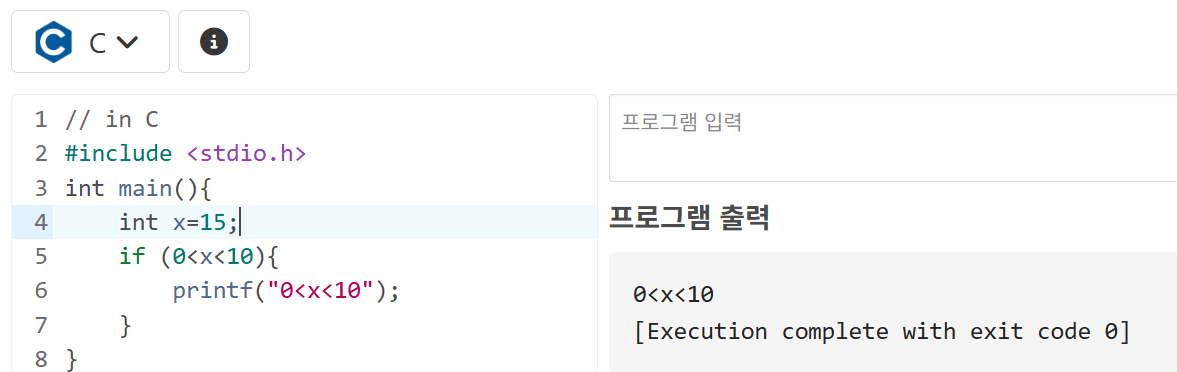
이와 같이 범위를 벗어난 x=15로 두더라도 똑같이 출력되는 모습을 볼 수 있다.
이유는 논리식 표현의 값이 항상 참 값으로 출력되기 때문이다.
대부분의 언어에서 조건문이 반복적으로 사용되면 순차적으로 처리된다고 했는데, 순서로 보면 다음과 같다.
0<x->True- 여기서
True값은 1,False값은 0으로 처리되기 때문에 - 0이든 1이든 10보다 작기 때문에 항상
True로 처리되어 출력되는 것이다.
이렇게 다른 언어에서는 이런 예기치 못한 문제가 발생할 수 있다.
🤔 참고로 이를 해결하기 위해서는 아래와 같이
and를 달아줘야 한다.
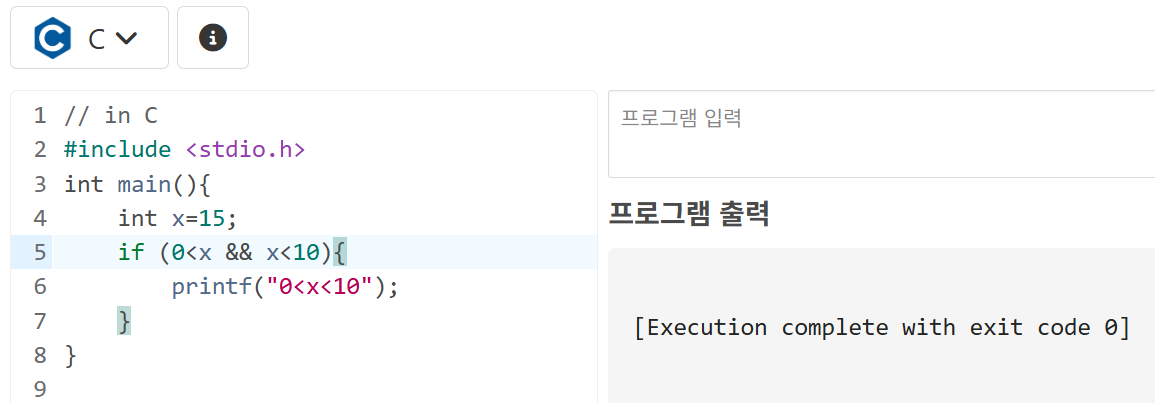
🔥 하지만 파이썬에서는 가능하다.
x>0 and x<10 == 0<x<10 으로 아래 두 식은 같다.
x=5
if x>0 and x<10: print("x는 0 이상 10 미만")x=5
if 0<x<10: print("x는 0 이상 10 미만") 
2. 반복문
2.1. for문
in뒤에 오는 데이터(리스트, 튜플 등)에 포함되는 원소를 순서대로 방문
arr=(1,3,5,4,2)
arr=[1,3,5,4,2]
for i in arr: print(x)
# 1
# 3
# 5
# 4
# 2range(시작, 끝+1): 연속적인 값을 차례대로 순회할 때 (인자 하나만 있으면 시작 값 0)
result=0
# 1~9
for i in range(1,10): result+=i
print(result) # 453. 함수
- 특정 작업을 묶어 놓아 불필요한 코드의 반복을 줄임
3.1. 함수의 정의
def 함수명(매개변수):
소스코드
return 반환 값
함수명(인자)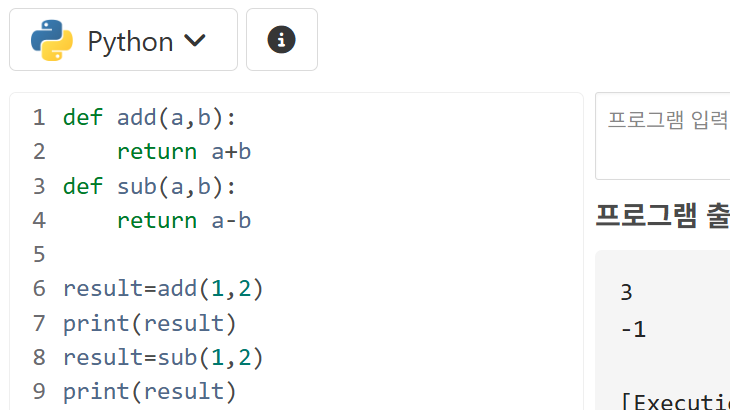
이때 파라미터는 순서를 바꾸어 직접 지정해도 된다.
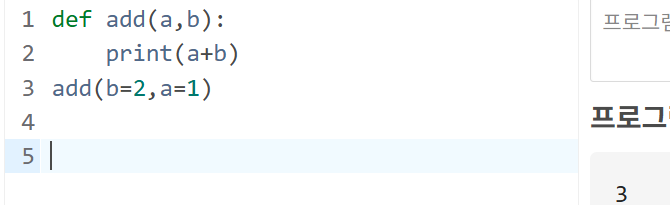
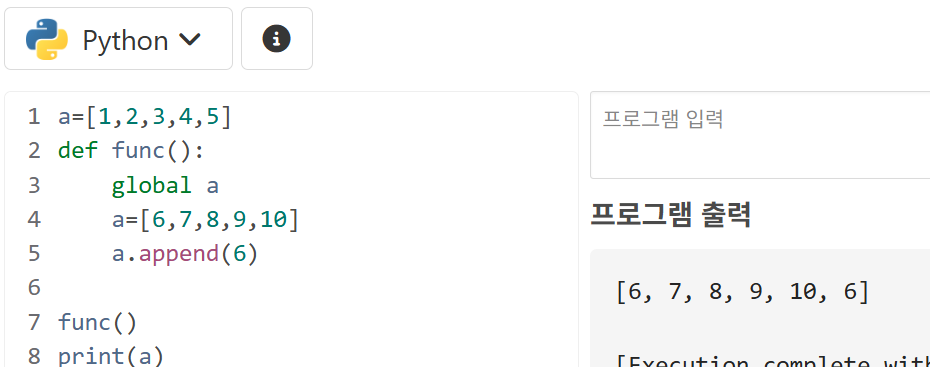
3.2. global
global 키워드로 변수를 지정하면, 함수 내에서 지역 변수를 만들지 않고, 함수 바깥의 전역 변수를 바로 참조하게 된다.

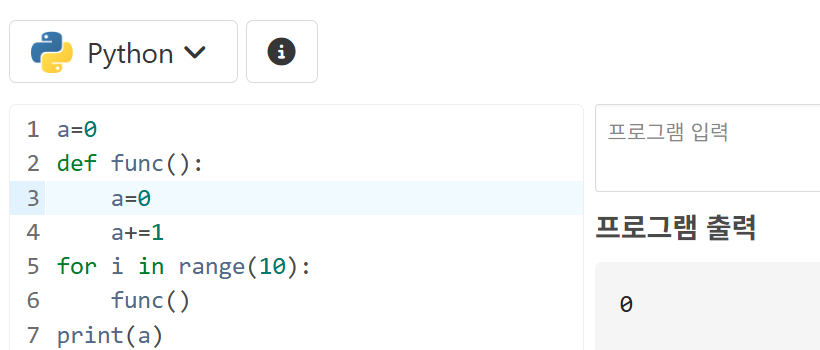
이렇게 global 키워드를 붙이지 않고 함수 내부에서 선언한 a를 참고하도록 한다면 아래와 같이 된다.
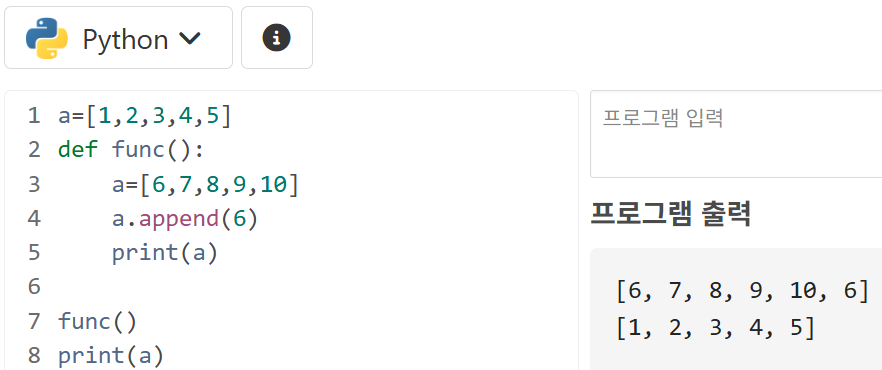
⭐ 또한 만약 함수 밖에 리스트가 선언되어 있을 때, 전역 변수로 선언된 객체에 내부 메서드를 호출하는 것은 오류가 발생하지 않는다.

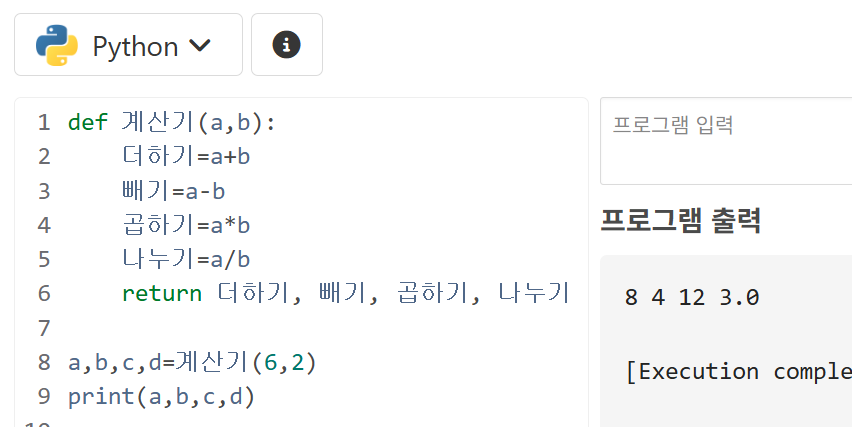
3.3. 여러 반환 값
3.4. ⭐ lambda
- 함수를 한 줄에 작성할 수 있도록 하는 표현식
def add(a,b):
return a+b
print(add(6,2)) # 8
print((lambda a,b: a+b)(6,2)) # 83.4.1. 예시 1
이런 람다 표현식은 내장 함수에서 자주 사용되는데, 정렬하는 sort에서 사용되는 예시를 보자.
정렬하는 함수로는 sort와 sorted가 있는데, 이 두 함수 모두 key라는 것을 사용하여 정렬 기준을 지정해 줄 수 있다.
이때 key의 값은 단일 인자를 가지며 정렬 목적으로 사용할 키를 반환하는 함수여야 한다.
따라서 보통 람다를 사용하여 key의 값으로 함수를 넘겨준다.
arr=[("a",3), ("b",1), ("c",2)]
def my_key(x):
return x[1]
print(sorted(arr, key=my_key)) # [("b",1), ("c",2), ("a",3)]이렇게 되면 key값으로 my_key를 지정해 줬기 때문에 리스트의 원소들로 튜플이 들어가 있고, x[1]을 찾아가기 때문에 3, 1, 2를 기준으로 (default값인 오름차순으로) 정렬하게 된다.
그리고 여기서 lambda를 사용할 수 있다.
arr=[("a",3), ("b",1), ("c",2)]
print(sorted(arr, key=lambda x: x[1])) # [("b",1), ("c",2), ("a",3)]🤔 sorted() vs .sort()
sorted(): 반환값이 없이 해당 리스트 자체를 다시 정렬 시킴.sort(): 반환값으로 정렬된 새로운 리스트가 나옴

3.4.2. 예시 2
또한 람다 표현식은 여러 개의 리스트에 동일한 규칙을 가지는 하나의 함수를 적용하고자 할 때, 효과적으로 사용할 수 있다.
lst1=[1,2,3,4,5]
lst2=[6,7,8,9,10]이런 두 리스트가 있을때 각 위치에 있는 값들 끼리 더해서,
[1+6, 2+7, ..., 5+10] 과 같이 새로운 리스트에 담고자 한다고 가정하자.
이럴 때는 각각의 원소에 어떠한 함수를 적용하고자 할 때 사용하는 map 함수를 이용할 수 있는데, 다음과 같다.
lst1=[1,2,3,4,5]
lst2=[6,7,8,9,10]
result=map(lambda a,b: a+b, lst1, lst2)
print(list(result)) # [7, 9, 11, 13, 15]- a와 b가 주어졌을때
- a+b를 반환하는 하나의 함수를 정의해서 이 함수를
- lst1과 lst2에 적용을 하는 것이다.
