📌 공부할 때 참고한 영상은 나동빈님의 이코테 2021 강의 입니다.
1. 그래프 탐색 알고리즘
- 많은 양의 데이터 중 원하는 데이터를 찾는 과정
- ⭐ 대표적인 그래프 탐색 알고리즘: DFS/BFS
- 코딩 테스트에서 매우 자주 등장하는 유형
이에 대해 알기 전에 먼저 반드시 알아야 하는 내용들에 대해 먼저 짚고 넘어가자.
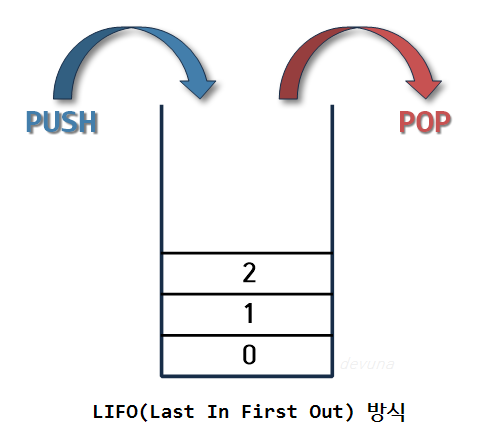
1.1. 스택(Stack) 자료구조
- 입구와 출구가 동일한 형태로 LIFO(Last In First Out)의 구조를 가짐
출처: https://wikidocs.net/198491
-
파이썬에서는 다른 라이브러리를 사용하는 것이 아닌 기본 제공 객체인 List를 이용해 Stack으로 사용할 수 있다.
Java나 C++의 경우는 Stack을 지원하며 각각 스택 최상단 원소를 출력하기위해.top(),.peek()메서드를 사용한다. -
삽입(Push)과 삭제(Pop)의 두 연산으로 계산됨
stack=[]
stack.append(0)
stack.append(1)
stack.append(2)
stack.append(3)
stack.pop()
stack.append(4)
print(stack) # [0, 1, 2, 4]
print(stack[::-1]) # [4, 2, 1, 0] # 역순append()나pop()은 맨 위에 데이터를 삽입하거나 삭제하기 때문에 시간복잡도는O(1)- 하지만 Stack안에 쌓인 데이터 중 특정 데이터를 찾기 위해서는 찾을 때까지 계속 수행을 해야하므로 시간복잡도가
O(n)
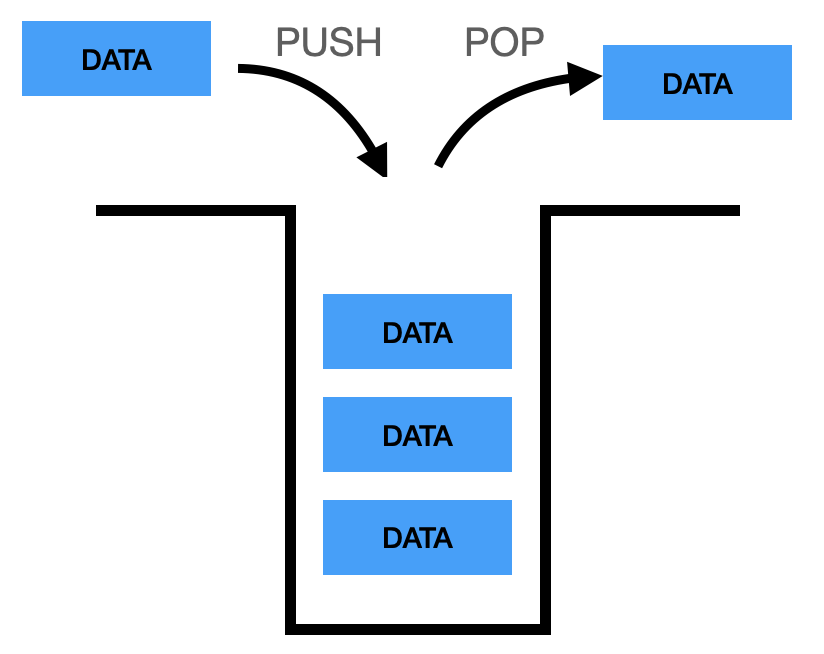
1.2. 큐(Queue) 자료구조
- 입구와 출구가 모두 뚫려 있는 터널 같은 형태로 FIFO(First In First Out)의 구조를 가짐
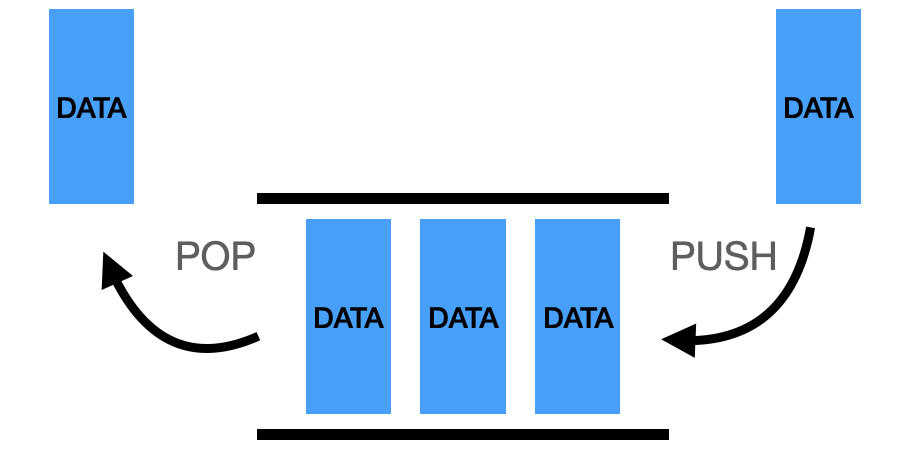
출처: https://wikidocs.net/198491
- 큐(Queue) 또한 List를 이용하여 구현할 수는 있지만, 만약 List를 이용하여 구현한다면 특정 데이터에 접근할때 다른 데이터들을 따로 리스트에 담고 정렬하여 다시 넣어주는
O(k)의 시간복잡도가 걸리기 때문에collection모듈의deque를 사용할 수 있다.
from collections import deque
# deque 객체 생성
queue=deque()
queue.append(0)
queue.append(1)
queue.append(2)
queue.append(3)
queue.popleft()
queue.append(4)
print(queue) # deque([1, 2, 3, 4])
queue.reverse()
print(queue) # deque([4, 3, 2, 1])- 이를 살펴보면 알겠지만 먼저 deque 객체를 생성해 준 다음 앞선 리스트로 데이터를 삽입했던 것과 마찬가지로
append()를 통해 입력하고 제거할 때는popleft()를 사용하는 모습이다. - 사실 이 deque는 큐(Queue)의 역할 뿐만 아닌 자유로이 구현이 가능하다.
from collections import deque
# deque 객체 생성
queue=deque()
queue.append(0)
queue.append(1)
queue.append(2)
queue.append(3)
queue.popleft() # 0 제거
queue.append(4)
queue.pop() # 마지막에 쌓인 4 제거
queue.appendleft(5) # 가장 앞에 5 삽입
queue.insert(0, 3) # 0번 자리(가장 앞)에 3 삽입
queue.insert(9999, 3) # 9999번 자리(없으니까 가장 뒤)에 3 삽입
queue.remove(3) # 같은 원소 존재 -> 왼쪽부터 삭제
queue[2] = 7 # 인덱스로 원소 수정
print(queue) # deque([5, 1, 7, 3, 3])
queue.reverse()
print(queue) # deque([3, 3, 7, 1, 5])그리고 Queue를 검색해보면 보통 왼쪽에서 입력되어 오른쪽으로 나오는 그림을 자주 볼 수 있는데 여기서는 반대 방향임을 꼭 기억하고 popleft()를 사용해야 한다.
1.3. ⭐ 재귀 함수(Recursive Func)
-
자기 자신을 다시 호출하는 함수
-
이후 다루게 되는 DFS 를 실질적으로 구현하고자 할 때 자주 사용되는 것이므로 반드시 알아야 한다.
-
아래 코드는 간단한 재귀 함수 호출 코드다.
def recursive_func():
print("재귀 함수 호출!")
recursive_func()
recursive_func()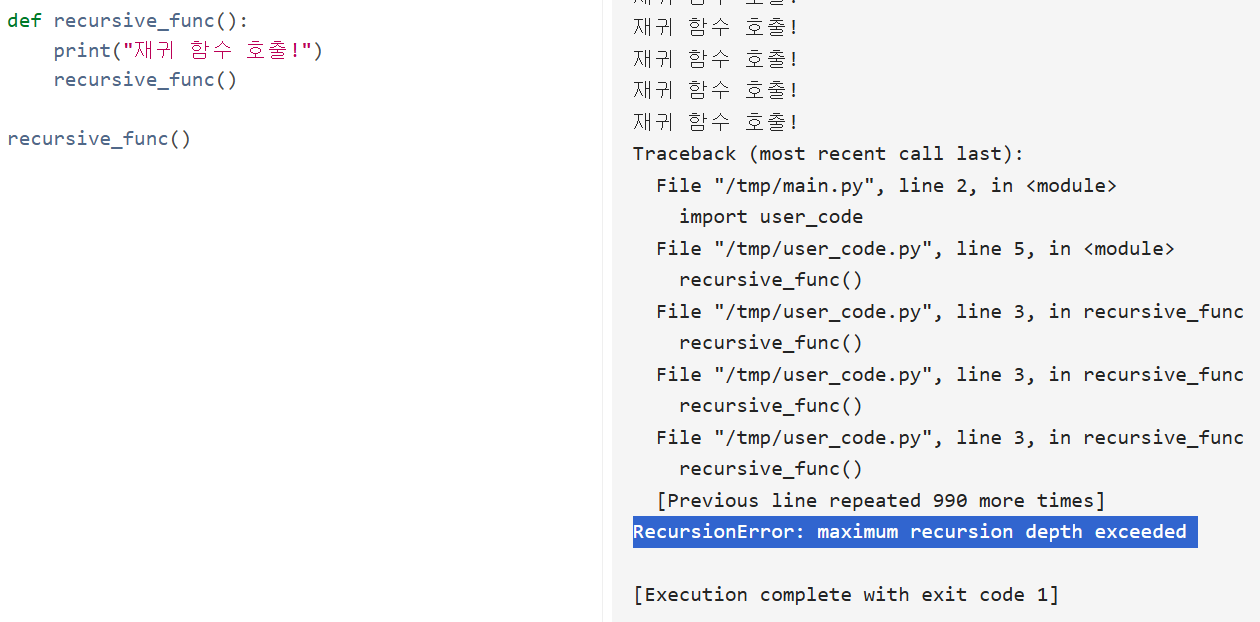
-
이를 잘 보면 메인에서 함수를 호출하고 해당 함수에서 자기 자신을 호출하기에 무한히 반복되어야 하는 코드인데, 이 파이썬에서는 최대 재귀 깊이 라는 것이 존재하기 때문에 별다른 설정없이 해당 코드를 실행하면 어느 정도 출력하다가 최대 재귀 깊이가 초과되었다는 메세지와 함께 프로그램이 종료된다.
-
여기서 잘 알아둬야하는 내용이 있다.
실제 컴퓨터 상에서 함수가 재귀적으로 호출이 되면, 컴퓨터 시스템의 스택 프레임(Stack Frame)에 이러한 함수가 반복적으로 쌓여서 가장 마지막에 호출되는 함수가 처리가 된 이후, 그 함수를 불렀던 함수까지 처리가 되는 방식이다.
즉 스택 자료구조 안에 함수에 대한 정보가 차례대로 담겨서 컴퓨터 메모리에 올라간다는 것이다. -
컴퓨터 메모리는 당연히 한정된 크기의 자원을 가지기에 함수가 종료되지 않고 계속해서 쌓아올려서 재귀적으로 호출만 하게되면 빠르게 메모리가 가득차서 문제가 발생할 수 있다. 따라서 재귀 깊이 제한을 걸어둘 수 있다.
만약 제한 없이 재귀함수를 호출하고자 한다면, 이러한 재귀 제한을 느슨하게 만드는 방법을 이용하거나 별도로 스택 자료구조를 이용해서 스택 객체를 따로 만들어서 이용하는 방법이 있다.
코딩테스트에서는 이와같이 일반적인 재귀함수를 사용해도 통과할 수 있도록 출제되는 경우가 많다.
그래서 간단히 재귀함수를 이용해서 무한히 어떤 내용을 반복하도록 만들어 보았던 것이다.
이렇게 한다면 while이나 for문을 이용하지 않고도 어떤 내용을 반복적으로 수행할 수 있다. -
다만 일반적인 경우 무한루프를 이용할 것이 아니라면 일반적인 코딩테스트에서 이 재귀함수를 문제풀이에 사용할 때는 재귀함수의 종료 조건을 반드시 명시해야 한다.
그렇지 않다면 함수가 무한히 호출될 수 있고 오류 또는 예기치 못한 결과가 발생할 수 있다. -
이제 코드로 보면 앞서 말한 스택 프레임에 쌓인다는 뜻도 이해라 수 있을 것이다.

- 이처럼 10번째 재귀함수를 호출하면 바로 종료되도록 조건을 걸었기에 종료됨과 동시에
- 스택에 데이터를 넣었다가 빼는 것과 마찬가지로 각 함수에 대한 정보가 실제로 스택프레임에 담기게 되어서 차례대로 호출이 되었다가
- 가장 마지막에 호출된 함수부터 차례대로 종료되어 결과적으로 첫번째 호출했던 시점의 함수까지 종료된다.
1.3.1. 팩토리얼 구현 예제
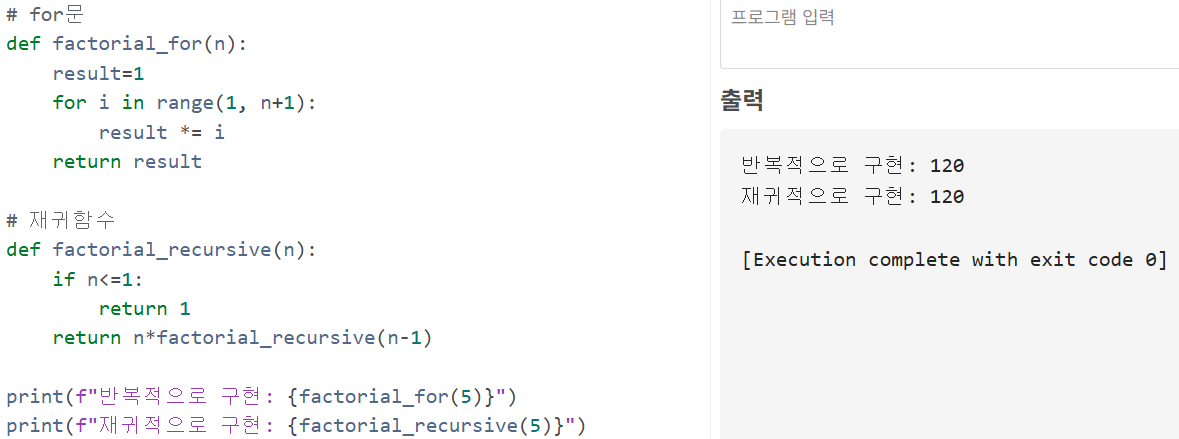
이와 같이 모든 재귀 함수는 반복문을 이용하여 동일한 기능을 구현할 수 있다.
1.3.2. 최대공약수 계산(유클리드 호제법) 예제
- 최대공약수(GCD(Greatest Common Divisor)): 두 개의 자연수가 있을 때 두 자연수의 공통된 약수 중 가장 큰 값
- 유클리드 호제법
- 최대공약수를 구할때 사용할 수 있는 대표적인 알고리즘
- 자연수 A, B(A>B)에 대하여
A를 B로 나눈 나머지를 R이라고 할 때, A와 B의 최대공약수는 B와 R의 최대공약수와 같다.
- 이러한 원리를 이용하여 재귀 함수로 구현해서 최대공약수를 빠르게 구할 수 있는 알고리즘을 작성할 수 있다.
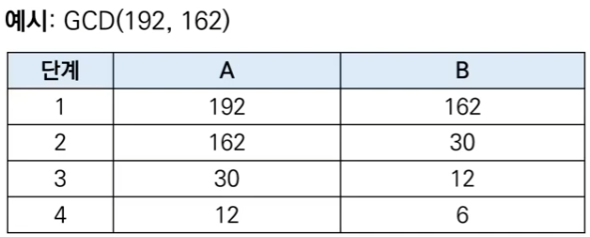
- 0단계: 192(A)와 162(B)의 최대공약수는..
1단계: 192(A)를 162(B)로 나눈 나머지인 30(R)을 구한뒤에..
2단계: 이제 162(B)와 30(R)의 최대공약수와 같은 값을 가진다! - 이런식으로 "192와 162의 최대공약수" 라는 식을 더 낮은 값의 형태인 "162와 30의 최대공약수"를 구하는 문제로 바꿀 수 있다.
- 결과적으로 192와 162의 최대공약수는 12와 6의 최대공약수와 같으며 12는 6의 배수이기 때문에, 6이 최대공약수다.
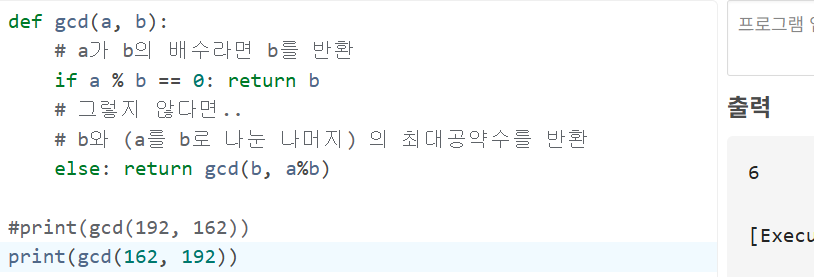
- 이를 코드로 구현하면 다음과 같다.

그리고 이렇게 함수를 작성하면 동작 과정상 함수 호출시 A>B가 아니더라도, 순서에 상관없이 정상적으로 동작한다.
1.3.3. 재귀 함수 정리 및 유의사항
- 재귀 함수를 잘 사용한다면 복잡한 알고리즘을 간결하게 표현할 수 있지만 방해가 될 수도 있기에 신중하게 사용해야 한다.
- 반복문보다 유리한 경우도 있고 불리한 경우도 있기 때문에, 이는 후에 특정한 문제에서 더 좋은 방법을 고려해서 사용하면 된다.
- 앞서 말했듯 함수가 연속적으로 호출되면 실제로는 컴퓨터 메모리 내부의 스택 프레임에 쌓이기에 이런 특성 때문에, 우리가 스택을 사용해야 할 때, 구현상, 스택 라이브러리 대신 재귀 함수를 이용하는 경우가 많다.
대표적으로 DFS를 간결하고 짧은 코드로 작성하기 위해서 재귀 함수를 이용해서 구현하곤 한다.
1.2. DFS(Depth-First Search)
깊이 우선 탐색
- DFS는 이름에서 알 수 있듯 깊이 우선 탐색이기 때문에 그래프에서 깊은 부분을 우선적으로 탐색하는 알고리즘이며, 스택 자료구조 혹은 재귀 함수를 이용한다.
- 동작 과정
- 탐색 시작 노드를 스택에 삽입하고 방문 처리
- 스택의 최상단 노드에 방문하지 않은 인접한 노드가 하나라도 있으면 그 노드를 스택에 넣고 방문 처리
방문하지 않은 인접 노드가 없으면 스택에서 최상단 노드를 꺼냄
즉 매번 최상단 노드를 기준으로해서 방문하지 않은 인접노드가 있으면 그 인접한 노드로도 방문을 수행하는 것 - 더 이상 2번의 과정을 수행할 수 없을 때까지 반복
1.2.1. DFS 동작 예시
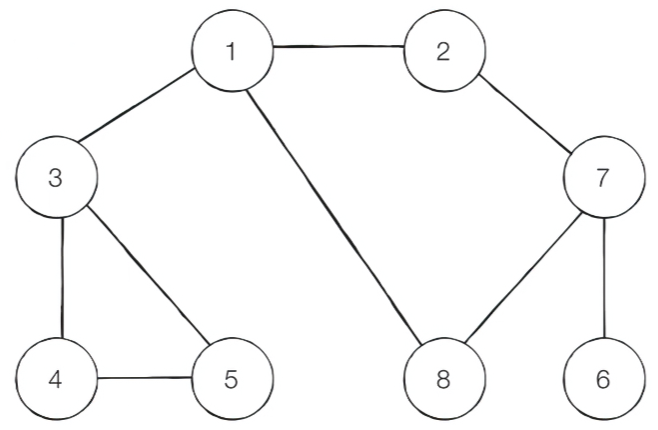
-
간선에 방향이 없는 무방향 그래프
-
DFS는 인접한 노드가 여러 개 일수 있다.
이럴 때는 어떤 노드부터 방문할지를 위한 기준이 필요하다.
기준은 문제에서 요구하는 기준에 따라서 조금씩 달라질 수 있고, 어떤 노드부터 방문하더라도 상관없는 경우도 있다. -
본 예시에서는..
시작 노드: 1
방문 기준: 번호가 낮은 인접 노드부터 방문 -
동작 과정 (1->2->7->6->8->3->4->5)
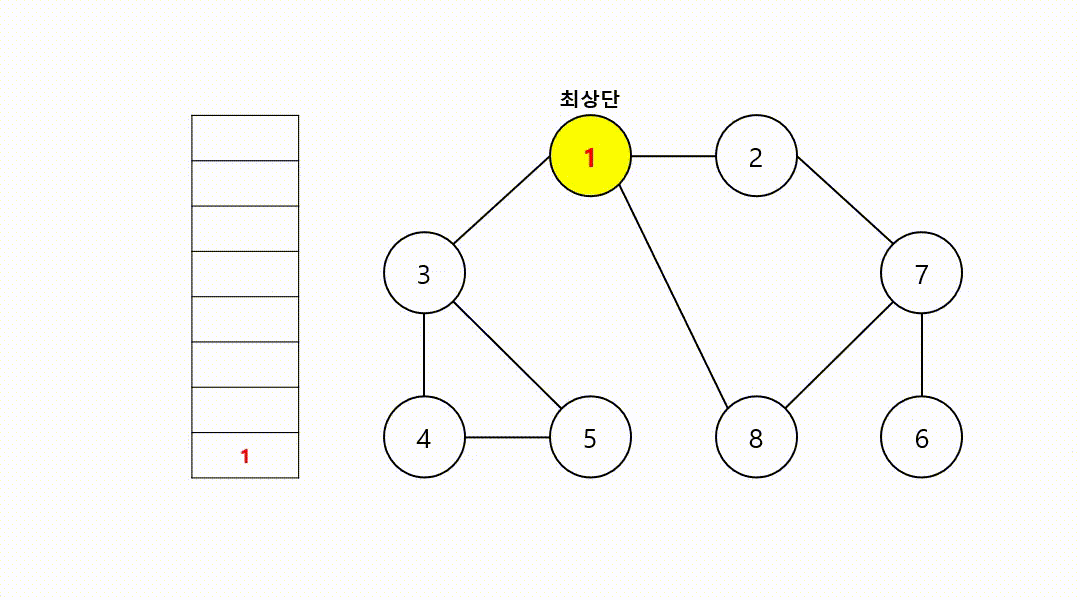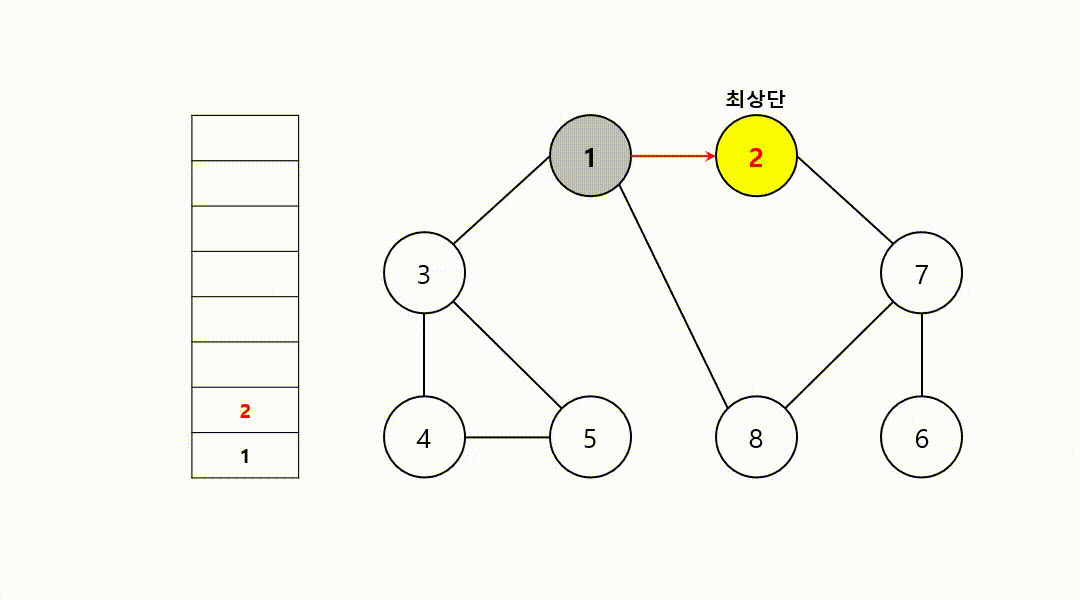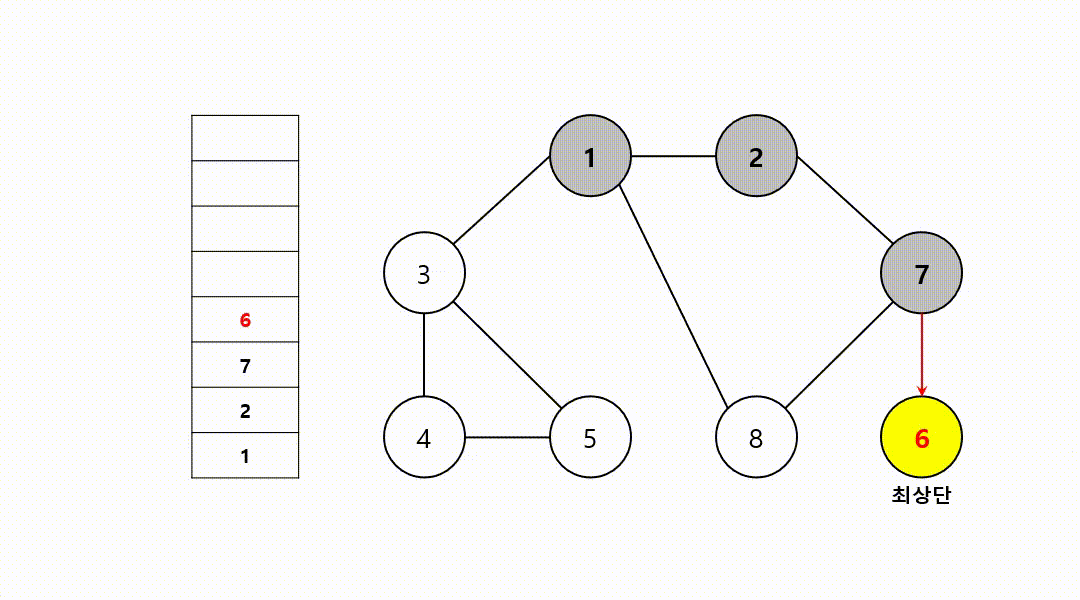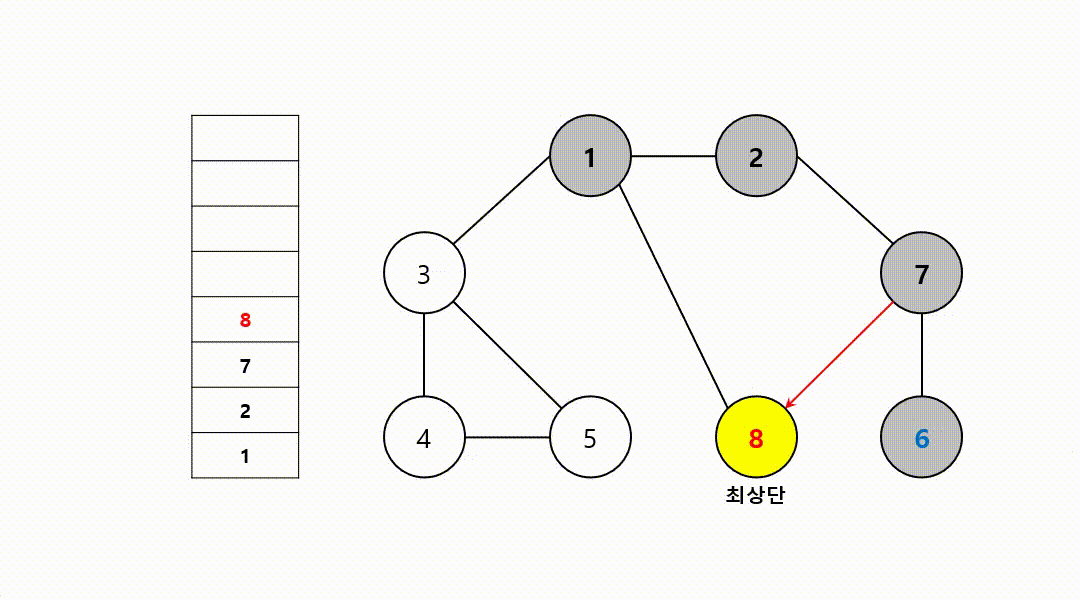
‼️여기서
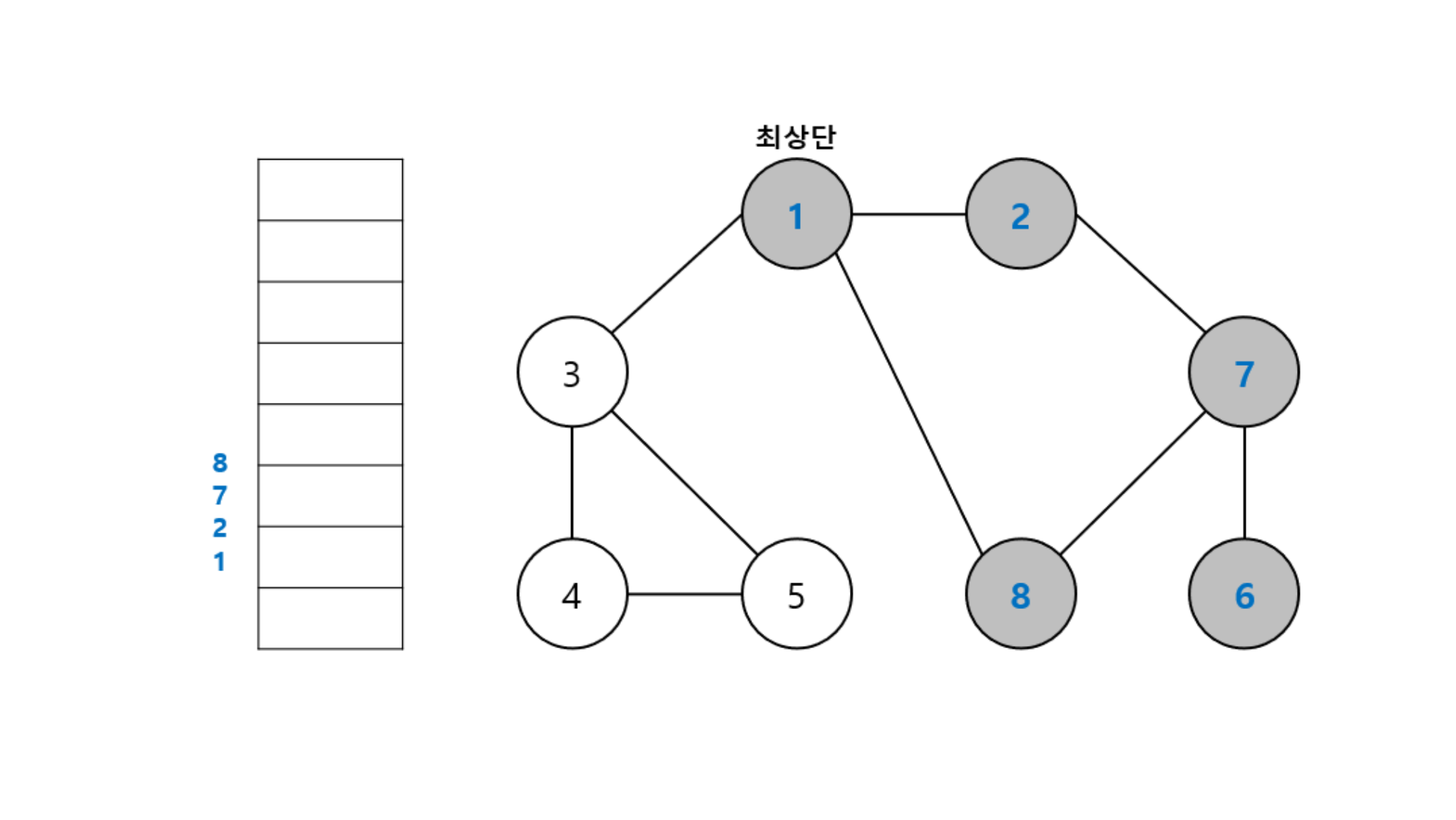
스택의 최상단 노드인 6에 방문하지 않은 인접 노드 X
따라서 스택에서 노드 6 제거
그 다음 다시 최상단 노드가 된 7에, 방문하지 않은 인접 노드 8부터 다시 반복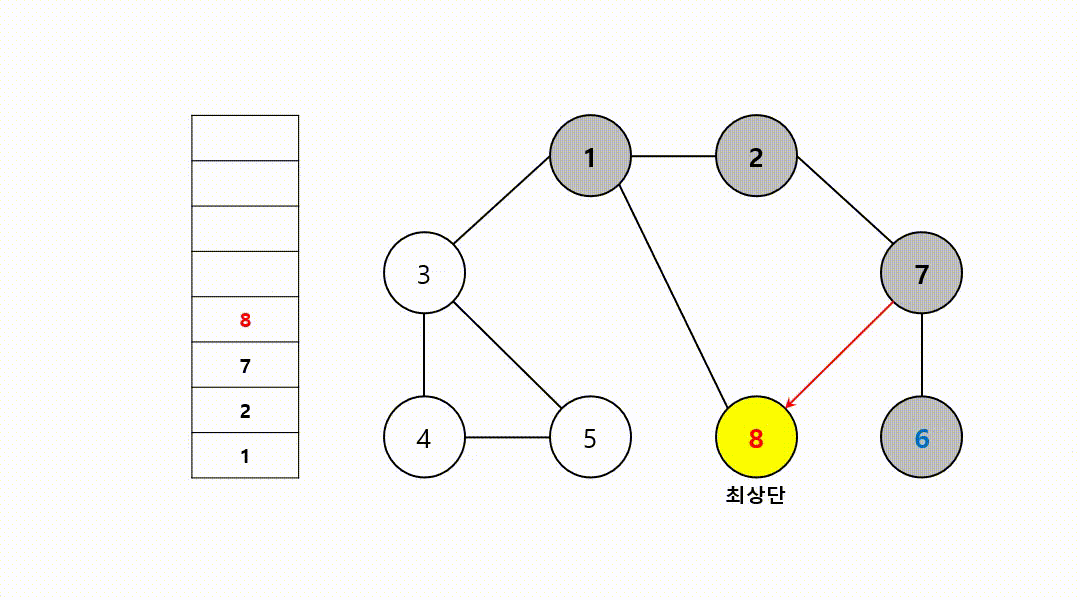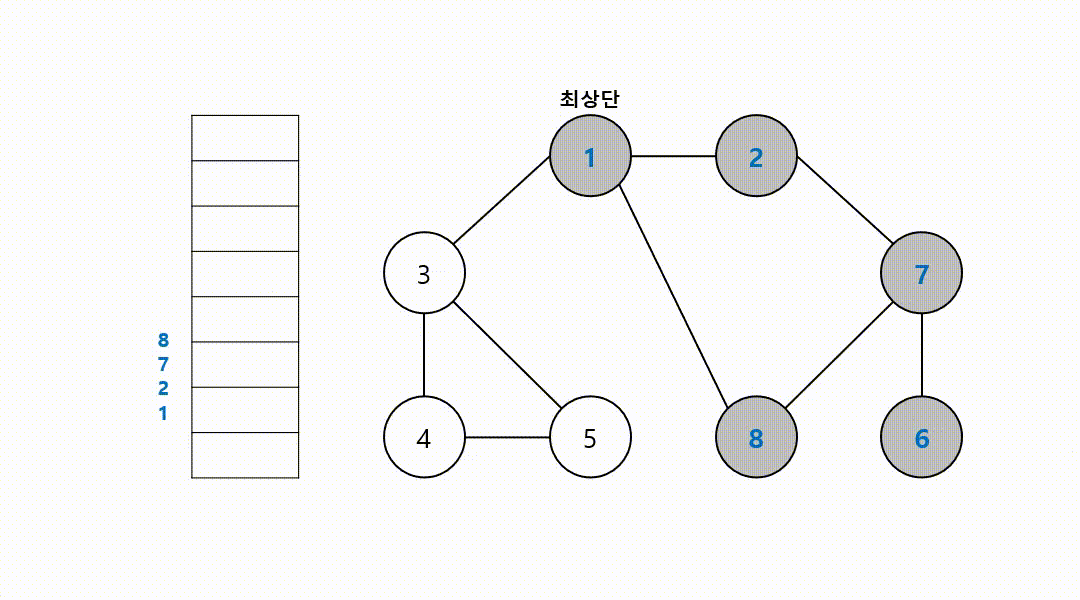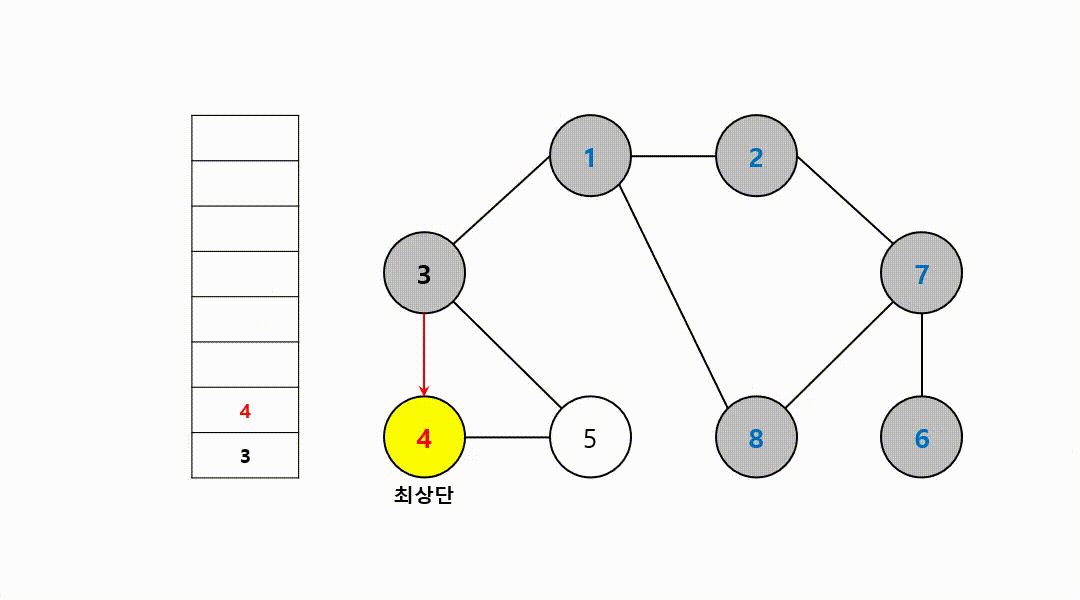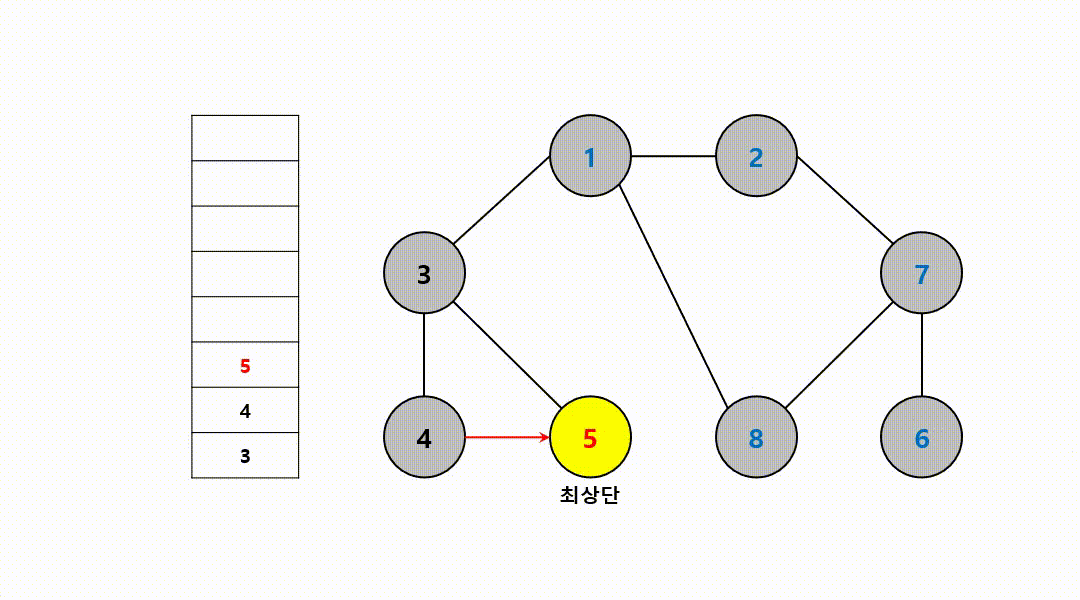
-
실제로 이렇게 깊게 들어가는 형태로 동작하기 때문에 스택 자료구조 대신에 재귀함수를 이용해서 구현할 수 있다.
자세한 내용들은 주석으로 걸어두었기에 반드시 읽어보자!
# DFS 메서드 정의
# graph: 그래프 정보 리스트 / visited: 방문 처리 여부 리스트
def dfs(graph, current_v, visited):
# 현재 노드 방문 처리
visited[current_v] = True # 방문 했음 표시 -> True로
print(current_v, end=" ") # 현재 해당 노드 번호 출력
# 현재 노드(스택 최상단 원소)와 연결된 다른 노드들을 하나씩 확인하면서
for i in graph[current_v]:
# 만약 그 인접한 노드가 방문되지 않은 상태(False)라면,
if not visited[i]:
# 그 노드에 대해서도 재귀함수를 이용해 방문 진행.
"""
재귀적으로 방문하지 않은 노드들을 계속해서 방문한다는 점에서
깊이 우선으로 최대한 깊게 그래프를 탐색할 수 있게 됨
"""
dfs(graph, i, visited)
# 2D List를 이용해 그래프에서 각 노드가 연결된 정보들을 표현
"""
그래프 문제가 출제되면
노드 번호가 보통 1번 부터 시작하는 경우가 많기 때문에 인덱스 0에 대한 내용은 비워두는 것이 일반적임
그리고 나서 인덱스 1부터 해당 노드에 인접한 노드가 무엇인지 리스트 형태로 담아 줄 수 있음
따라서 1번 노드와 연결되어 있는 건 2, 3, 8. 2번 노드와 연결되어 있는 건 1, 7.
"""
graph = [
[], # 0번 인덱스 (사용 안 함)
[2, 3, 8], # 1번 노드와 연결된 노드들의 리스트
[1, 7], # 2번 노드와 연결된 노드들의 리스트
[1, 4, 5], # ...
[3, 5],
[3, 4],
[7], # ...
[2, 6, 8], # 7번 노드와 연결된 노드들의 리스트
[1, 7] # 8번 노드와 연결된 노드들의 리스트
]
# 1D List를 만들어 방문 처리 기록 (방문 T / 미방문 F)
# 1번~8번 노드는 8개지만 인덱스 0은 사용하지 않기 위해서 하나 더 큰 크기 9로 설정
visited = [False]*9
# DFS 함수 호출
dfs(graph, 1, visited)1.3. BFS(Breadth-First Search)
너비 우선 탐색
-
깊은 부분이 아닌 자신에게 가까운 노드부터 우선적으로 탐색하는 알고리즘이며 큐 자료구조를 이용한다.
-
특정 조건에서의 최단 경로를 해결하기 위한 목적으로 사용되기도 한다.
-
큐 자료구조가 사용되기 때문에 각 프로그래밍 언어마다 큐 자료구조를 어떻게 사용할 수 있는가에 대한 내용도 숙지할 필요가 있다.
-
동작 과정
- 탐색 시작 노드를 큐에 삽입하고 방문 처리
- 큐에서 노드를 꺼낸 뒤, 해당 노드의 인접 노드 중 방문하지 않은 노드를 모두 큐에 삽입하고 방문 처리
DFS에서는 인접하지 않은 노드에 대해서 다시 한번씩 스택에 넣으면서 방문 수행했었는데, BFS에서는 해당 시점에서 인접 노드를 한번에 전부 큐에 넣는다. - 더 이상 2번의 과정을 수행할 수 없을 때까지 반복
1.3.1. BFS 동작 예시
-
앞서 DBF에서 사용했던 간선에 방향이 없는 무방향 그래프
-
DFS와 조건 동일
시작 노드: 1
방문 기준: 번호가 낮은 인접 노드부터 방문
특정 노드에 대해서 인접한 노드가 여러 개일 경우
인접한 노드들 중 번호가 낮은 노드부터 방문할 수 있도록 처리 -
동작 과정 (1->2->3->8->7->4->5->6)
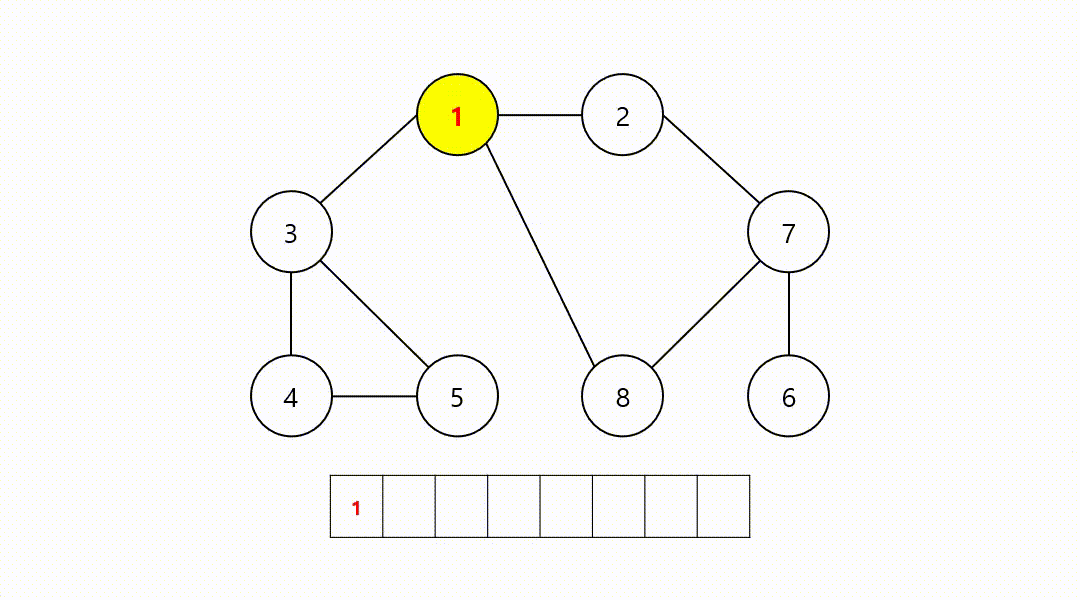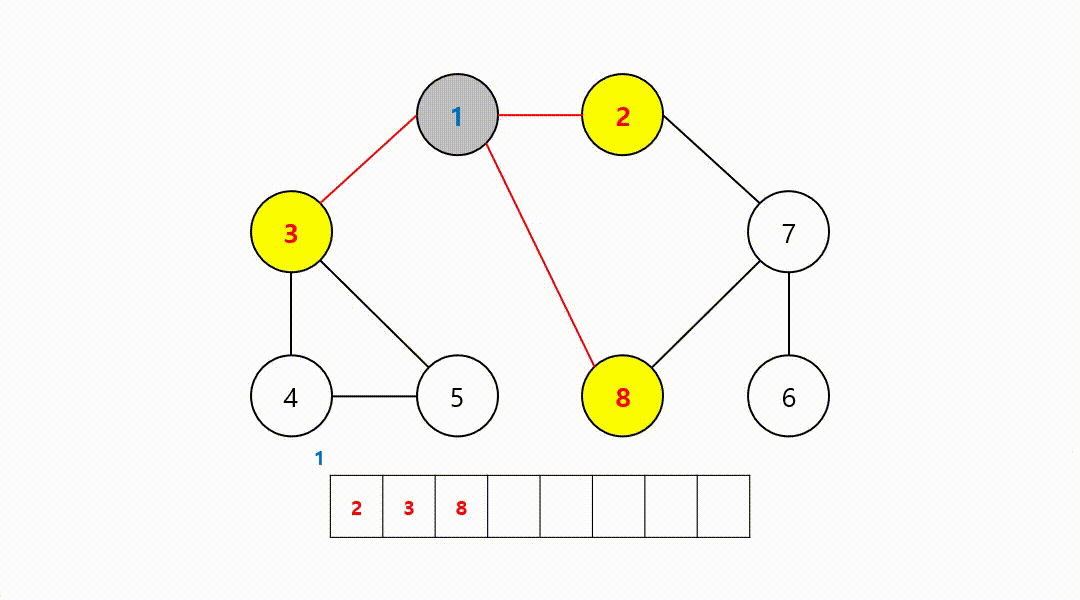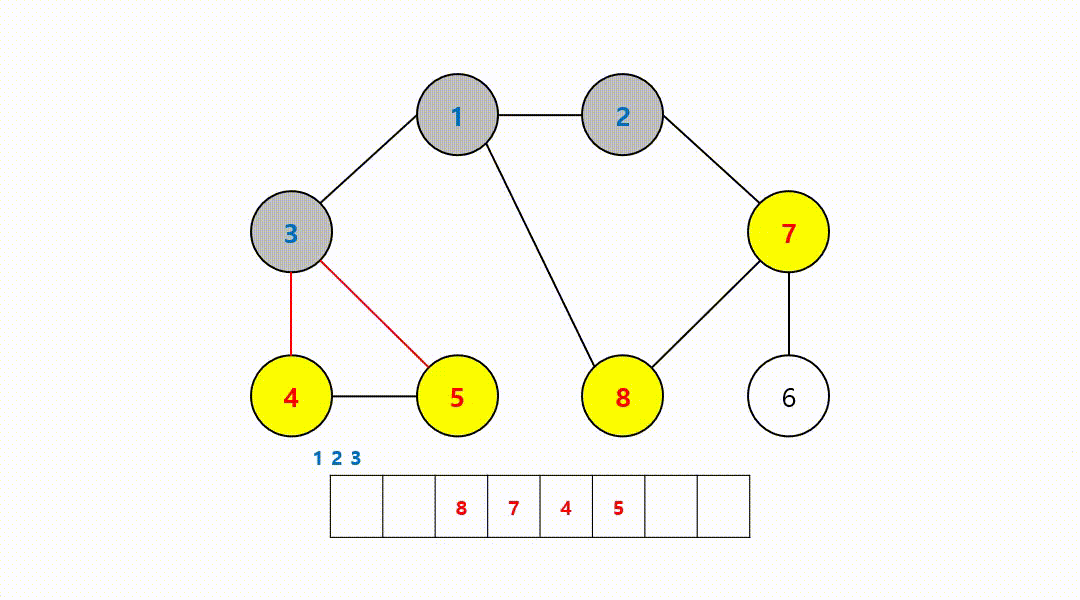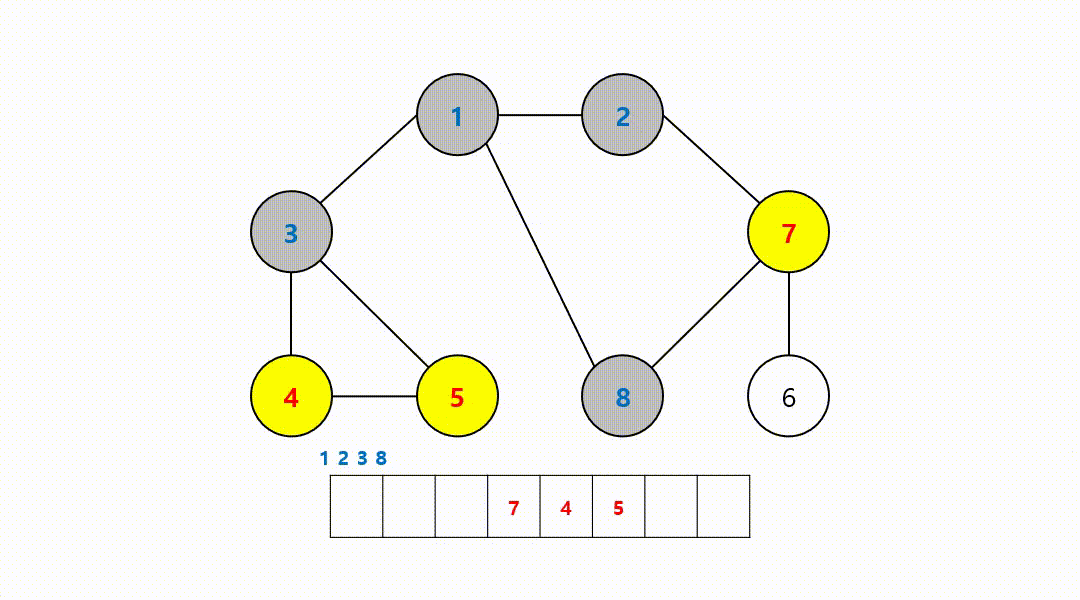
‼️여기서
큐에서 8번 노드를 꺼내고 방문하지 않은 인접 노드는 없기 때문에 무시하고 다음 노드 번호로 이어간다.
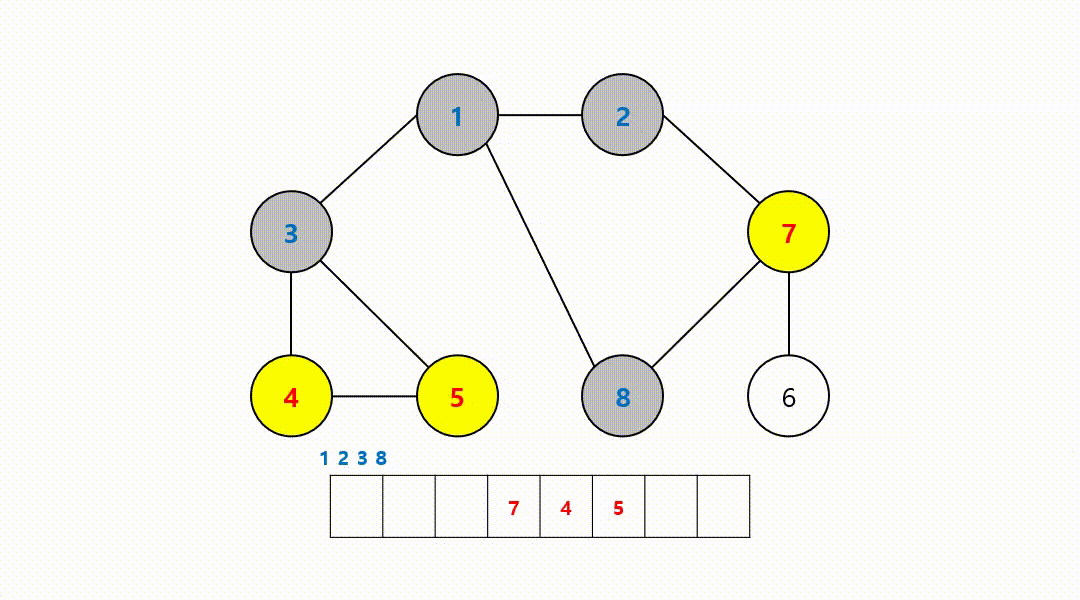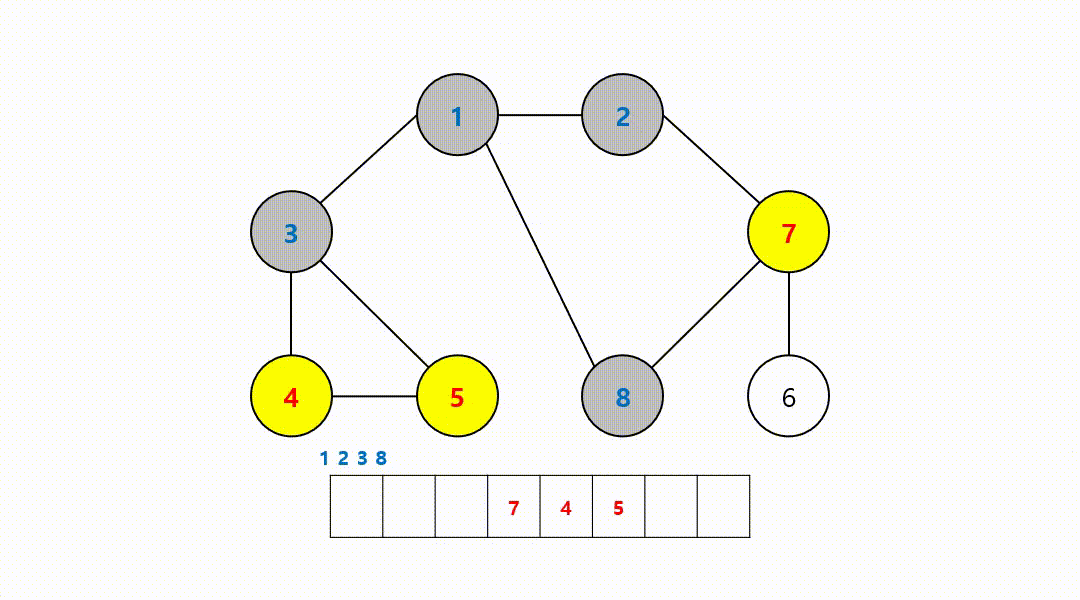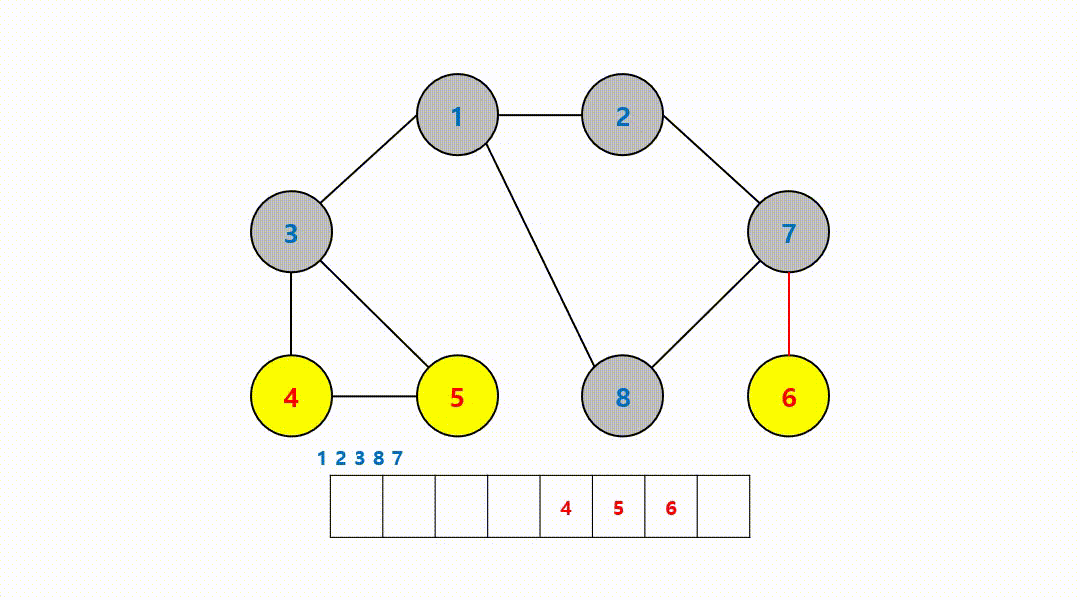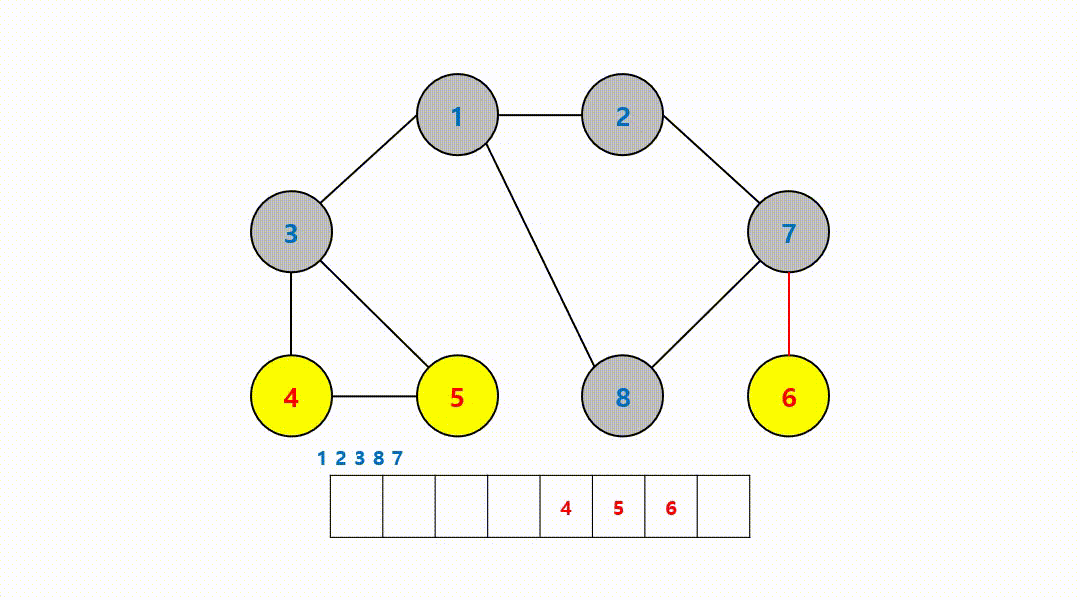
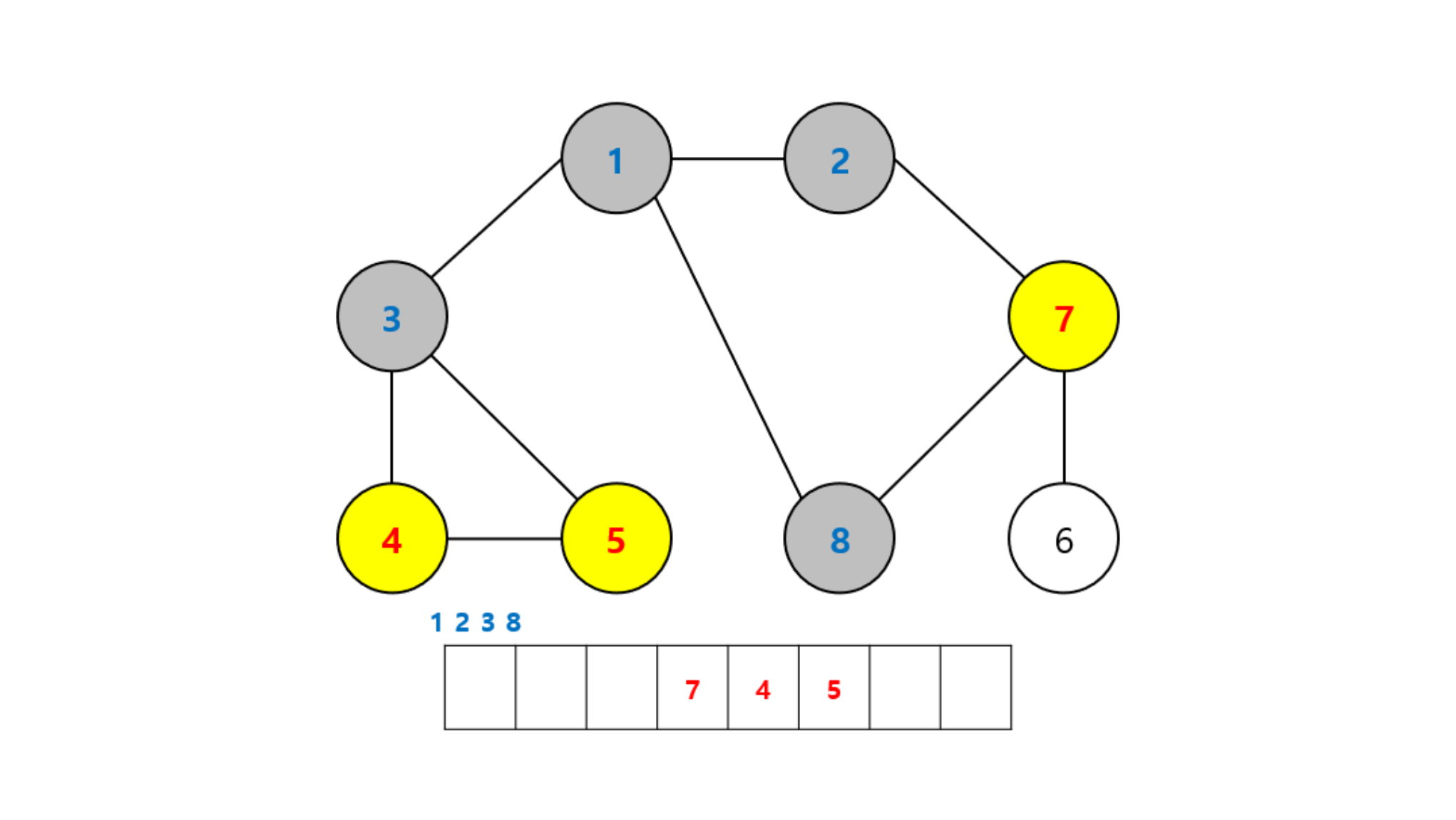
-
시작 노드부터 가까운 노드를 우선적으로 탐색하는 모습을 볼 수 있다. 그래서 다시 살펴보면 시작 노드인 1번 노드에서부터...
- 2, 3, 8번 노드의 거리는 모두 1이기 때문에 먼저 방문된 모습
- 이어서 7, 4, 5번 노드는 거리가 모두 2
- 마지막으로 거리가 가장 먼 6번 노드가 가장 마지막으로 탐색된 모습
-
BFS는 이러한 특성 때문에 각 간선의 비용이 동일한 상황에서 최단거리 문제를 해결하기 위한 목적으로도 사용될 수 있다는 것을 기억하자.
-
코드로 보면 다음과 같다.
from collections import deque
# BFS 메서드 정의
def bfs(graph, start, visited):
# 시작 노드를 큐 객체에 삽입
queue = deque([start])
# 현재 노드를 방문(True) 처리
visited[start] = True
# 큐가 비워질 때까지 반복
while queue:
# 큐에서 하나의 원소 뽑을 때: popleft()
current_v = queue.popleft()
print(current_v, end=" ")
"""
꺼낸 노드와 아직 방문하지 않은 인접한 노드들을 확인하면서
아직 방문하지 않은 노드들이 있다면 모두 큐에 삽입한다.
그 다음 방문처리한다.
"""
for i in graph[current_v]:
if not visited[i]:
queue.append(i)
visited[i] = True
graph = [
[],
[2, 3, 8],
[1, 7],
[1, 4, 5],
[3, 5],
[3, 4],
[7],
[2, 6, 8],
[1, 7]
]
visited = [False]*9
bfs(graph, 1, visited)1.4. DFS/BFS 문제
1.4.1. 문제 1
- NxM 크기의 얼음 틀이 있다.
- 구멍이 뚫려 있는 부분은 0, 칸막이가 존재하는 부분은 1
- 구멍이 뚫려 있는 부분끼리 상하좌우로 붙어있는 경우, 서로 연결되어 있는 것으로 간주
- 얼음 틀의 모양이 주어졌을 때 생성되는 총 아이스크림의 개수를 구하라.
- 4x5 얼음 틀 예시 -> 아이스크림 총 3개 생성됨
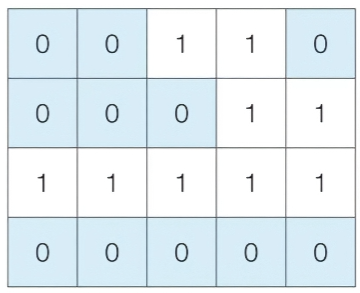
- 입력 조건
첫 번째 줄에 얼음 틀의 세로 길이 N과 가로 길이 M이 주어짐(1<=N, M<=1,000)
두 번째 줄부터 N+1번쨰 줄까지 얼음 틀의 형태가 주어짐 - 출력 조건
한 번에 만들 수 있는 아이스크림의 개수 출력 - 입력 예시
5 5
00010
11111
11101
00000
00110- 출력 예시
31.4.1.1. 해결 아이디어
- 이 문제는 DFS 혹은 BFS로 해결 가능하다.
- 상하좌우로 연결되어 있는 것을 인접한 노드라고 생각하면 그래프 형태로 모델링이 가능하다.
- 따라서 여기서는 하나의 특정 노드에서 인접한 노드(얼음) 들을 모두 방문 처리할 수 있으니 해당 방문 처리가 이루어지는 부분에 대해서 count 하면 된다.
- DFS를 활용하는 알고리즘
- 특정 노드의 상하좌우를 살펴본 뒤, 주변 노드 중 값이 0이면서 아직 방문하지 않은 노드가 있으면 해당 노드를 방문한다.
- 방문한 노드에서 다시 상하좌우를 살펴보면서 1번과 같이 방문을 진행하는 과정을 반복하면 연결된 모든 노드를 방문할 수 있게 된다.
즉 DFS를 이용해서 모든 노드에 대해서 현재 방문하고 있는 노드와 연결된 그런 인접한 노드에 대해서도 반복적으로 DFS를 호출해서 연결된 모든 노드들을 방문할 수 있도록 하는 것이다.
그렇게 되면 칸막이(1)로 감싸져있는 안쪽에 있는 모든 노드들을 방문하게 된다. - 모든 노드에 대하여 1~2번의 과정을 반복하며, 방문하지 않은 지점의 수를 카운트한다.
1.4.1.2. ⭐ 코드로 확인
# DFS로 특정 노드를 방문하고 연결된 모든 노드들도 방문
def dfs(x, y):
# 주어진 범위를 벗어나는 경우 종료
if x <= -1 or x >= N or y <= -1 or y >= M:
return False
# 현재 노드를 아직 방문하지 않았다면 이제 방문 처리를 진행한다.
if graph[x][y] == 0:
# 해당 노드 방문 처리
graph[x][y] = 1
"""
상하좌우의 연결된 모든 노드들에서
방문 처리를 진행할 수 있도록 하기위해서 모두 재귀적으로 dfs 호출
여기서는 리턴값이 없이 연결된 모든 노드들에 대해서 방문처리만 진행한다.
"""
dfs(x-1, y) # 상
dfs(x+1, y) # 하
dfs(x, y-1) # 좌
dfs(x, y+1) # 우
return True
return False
N, M = map(int, input().split()) # 5 5
graph = []
for i in range(N):
# 00010
# 11111
# 11101
# 00000
# 00110
graph.append(list(map(int, input())))
count = 0
# 모든 노드에 얼음 채우기
for i in range(N):
for j in range(M):
"""
이 dfs가 한번 수행되면 현재 해당 노드와 연결된 모든 노드들에 방문 처리할 수 있도록 하고
그 시작점, 해당 노드가 방문처리가 되었다면(return True를 받았다면),
즉 처음 방문한 것이라면 그때만 count를 증가시킨다.
"""
if dfs(i, j) == True:
count += 1
print(count) # 31.4.2. 문제 2
- NxM 크기의 직사각형 미로에 갇힌 A, 미로에는 여러 괴물이 있어 탈출해야 함
- A의 위치는 (1, 1)이며 출구는 (N, M)에 위치함
- 한 번에 한 칸씩만 이동 가능
- 괴물이 있는 부분은 0, 없는 부분은 1
- A가 탈출하기 위해 움직여야 하는 최소 칸의 개수를 구하라
- 단, 칸을 셀 때는 시작 칸과 마지막 칸을 모두 포함해서 계산하며 미로는 반드시 탈출할 수 있는 형태로 제시됨
- 입력 조건
첫째 줄에 두 정수 N, M(4<=N, M<=200)이 주어짐
다음 N개의 줄에는 각각 M개의 정수(0/1)로 미로의 정보가 주어짐
각각의 수들은 공백 없이 붙어서 입력으로 제시됨
또한 시작칸과 마지막 칸은 항상 1 - 출력 조건
첫째 줄에 최소 이동 칸의 개수를 출력 - 입력 예시
5 6
100110
111111
110001
110011
011111- 출력 예시
101.4.2.1. 해결 아이디어
- 시작 지점에서 가까운 노드부터 차례대로 그래프의 모든 노드를 탐색한다.
- 이때 상하좌우로 연결되어있는 모든 노드들은 이동이 가능하기 때문에 거리가 1로 동일하다.
- 간선의 비용이 모두 같을 때 (앞서 한 번에 한 칸씩만 이동 가능하다고 했으니) 최단 거리를 탐색하기 위해 사용할 수 있는 알고리즘인 BFS를 사용한다.
- 그래서 가장 왼쪽 위(시작점)인 (1, 1)에서 BFS를 수행해서
모든 노드들에 대한 최단 거리 값을 기록하는 방식으로 알고리즘을 작성할 수 있다. - 만약 3x3크기의 미로는 다음과 같이 표현이 가능하다.
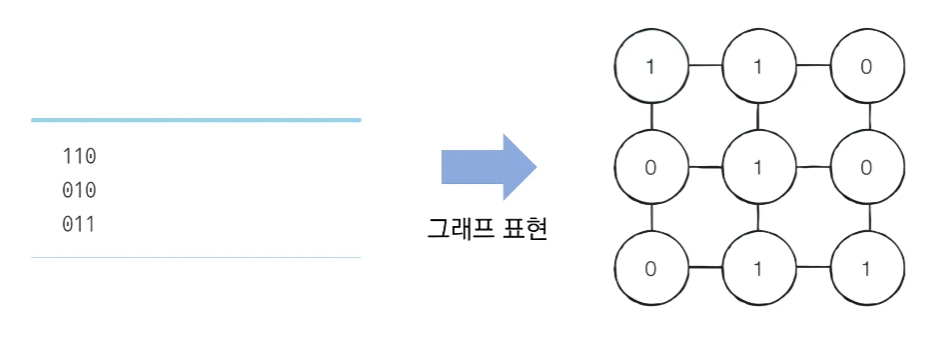
이러한 그래프에서 알고리즘을 수행하게 되면-
(1, 1)에서 BFS를 수행한다.
인접한 노드 중에서 값이 1인 노드로만 이동이 가능하다고 판단하여 queue에 원소를 넣어서 방문 처리할 때 초기 원소의 값이 1인 경우에 한해서만 BFS를 진행한다.
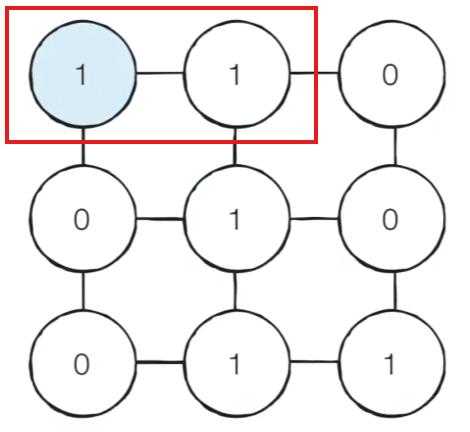
-
상하좌우로 탐색을 진행하면서 옆의 노드로 방문하게 되고 이제 해당 노드까지의 거리는 2라고(본 문제에서 시작위치와 마지막 위치를 포함해서 거리를 잰다고 했으니) 기록한다.
-
이어서 2도 queue에 담기게 되고 다시 2 노드를 꺼낸 다음에 마찬가지로 상하좌우로 연결되어 있는 노드를 확인해서 인접한 노드까지 방문을 수행한다.
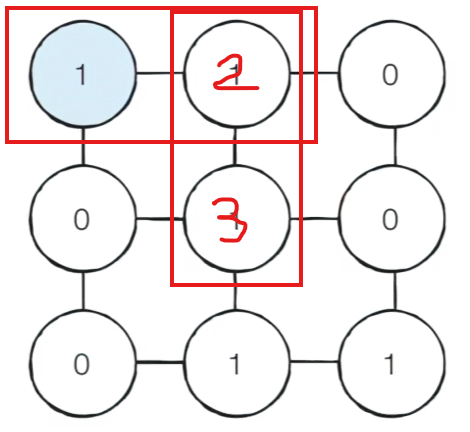
그래서 해당 노드를 queue에 넣을 때 방문 처리를 수행한 다음에 이 노드까지는 거리가 3인 것으로 기록하는 방식으로 매번 새로운 노드를 방문할 때 그 이전 노드까지의 최단 거리에 +1 한 값을 기록하도록 한다.
-
시작 위치에서 BFS를 수행했을 때 다음과 같이 최단 경로의 값들이 거리가 멀어질 수록 +1 씩 증가하는 형태로 변경되고, 결과적으로 마지막 위치에 기록되어 있는 최단 거리 값을 출력하도록 만들면 정답이 된다.
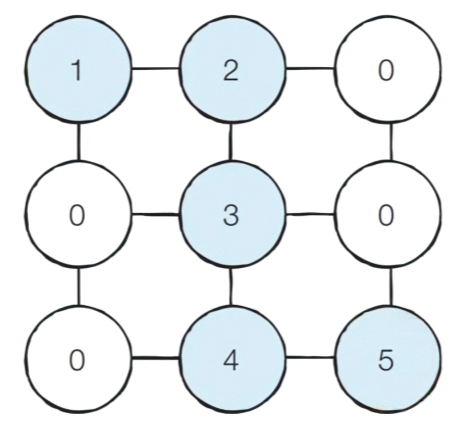
-
1.4.2.2. ⭐ 코드로 확인
from collections import deque
def bfs(x, y):
queue = deque()
# (x, y) 튜플 데이터 담기
queue.append((x, y))
# 큐가 비어질 때 까지 bfs를 수행하는데,
while queue:
# 반복할때마다 큐에서 하나의 원소를 꺼내서
x, y = queue.popleft()
# 현재 위치에서 상하좌우 확인한다.
for i in range(4):
nx = x+dx[i]
ny = y+dy[i]
# 이제 연결된 위치가 공간 벗어난 경우는 제외하고
if nx < 0 or nx >= N or ny < 0 or ny >= M:
continue
# 또한 몬스터(0)가 존재하는 경우도 제외하도록 한다.
if graph[nx][ny] == 0:
continue
"""
그래서 결과적으로 해당 노드를 처음 방문할 때만 최단 거리를 기록하도록 한다.
바로 직전 노드 위치에서의 최단 거리 값에 +1 만큼을 더한 값을 넣어줄 수 있도록 한다.
다음으로 이동할 위치까지는 +1 만큼 더 먼 곳이기 때문에
queue에 데이터를 넣으면서 거리 값을 +1 증가시킬 수 있다.
"""
if graph[nx][ny] == 1:
graph[nx][ny] = graph[x][y]+1
queue.append((nx, ny))
# 그리고서 bfs를 수행한 뒤에 가장 오른쪽 아래까지의 최단 거리 반환하면 정답 판정
return graph[N-1][M-1]
N, M = map(int, input().split())
graph = []
for i in range(N):
graph.append(list(map(int, input())))
# 상하좌우 방향 벡터
dx = [-1, 1, 0, 0]
dy = [0, 0, -1, 1]
# BFS를 수행한 결과 출력
print(bfs(0, 0))