
📌 사용 환경
Python 3.10.2
conda 24.9.0
JupyterLab 4.2.5
1. 튜플(Tuple)
- 읽기 전용 List
- 선언
- 함수
- 활용
컬렉션 자료형 중 순서형의 문자열(str), 리스트(List)에 이어 마지막 튜플(tuple)이다.
튜플은 오직 유일하게 파이썬에만 있는 자료형으로, 반드시 알아야 하는 개념이다.
알고리즘 시험을 볼 때 보통 배열 기반으로 하기는 하지만, 리스트(List)와 튜플(Tuple), 집합(set), 딕셔너리(dictionary) 등을 이용하는 방법도 잘 알아야 한다.
1.1. vs 리스트(List)
튜플(Tuple)은 리스트(List)의 읽기 전용이다.
그런데 리스트와의 차이점은 읽기 전용은 튜플은 수정과 삭제가 되지 않는다는 점이다.
근데 그렇다면 수정이 가능한 리스트(List)가 당연히 좋다고 생각이 들지만, 사실 튜플이 존재하는 이유가 있다.
프로그램이 실행되는 동안 값을 유지해야 한다면 튜플을 사용하고,
수시로 값을 변경해야 한다면 리스트를 사용한다.
메모리에 데이터가 들어가는데,
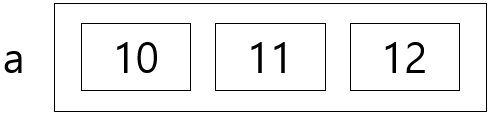
a에 10, 11, 12가 순차적으로 들어가고 특정 위치의 값을 변경하려고 할때, 바로 바꾸는 것이 아닌 메모리 안에서 여러 과정을 거쳐서 수정한다. 이는 메모리를 사용함으로써 시간을 잡아먹으며 비효율적이다.
예를 들어 회원가입을 할때 ID, PW, 주소 등이 각 필드에 들어간다. A라는 사람 한 줄, B라는 사람 한 줄 이런식으로 들어가는데, 중간에 한명이 탈퇴를 했을 때, 혹은 새로운 회원이 가입했다고 하면 한줄 추가해줘야 한다. 이를 레코드 중심 언어라고 하며 수시로 들어갔다 나왔다 해야한다.
그래서 서버 관리하는 입장에서 이게 유동적이어야 한다.
하지만 머신러닝은 아니다.
만약 200x300 사이즈의 이미지를 보고 고양이인지 강아지인지 구분해야한다고 할 때, 이럴때 특정 행이 빠지지 않는다.
여기서 특정 행이 빠지면 고양이의 코가 사라지는 등의 문제가 일어나기 때문이다.
그렇다면 이는 완성된 형태에서 하는 것이다.
즉 리스트(list)는 앞선 회원가입과 같은 수정이 자주 일어날 때 사용되며,
튜플(tuple)은 이미지와 같이 변하지 않는 값들에서 사용된다.
따라서, 튜플(tupe)은 리스트(list)보다 메모리 사용이 효율적이다.
1.2. tuple 선언
# 튜플(tuple)은 `()`를 이용
a=(1,2,'a','b')
print(a, type(a))
# ✅ 출력 결과
# (1, 2, 'a', 'b') <class 'tuple'>하지만 튜플은 요소 값이 1개 일때
,(콤마)를 붙이지 않으면 인티저가 나온다.
1+2==(1+2)이고 1 == (1) 이기 때문에 integer로 받아들인다.따라서 콤마를 붙여서 t=(1,) 이런 식으로 사용해야 한다.
b=(1) print(b, type(b)) b2=(1,) print(bb, type(b2)) # ( ) 괄호를 생략해도 된다. b3=1,2,3,4 print(b3, type(b3)) # ✅ 출력 결과 # 1 <class 'int'> # (1,) <class 'tuple'> # (1, 2, 3, 4) <class 'tuple'>
1.3. indexing & slicing
이 부분은 계속 똑같으니 자세히 알아보지는 않겠다.
인덱스와 슬라이싱 처럼 찾아 가는 것이 String과 List와 동일하다.
print(b3[0])
print(b3[1:3])
# ✅ 출력 결과
# 1
# (2, 3)그런데 이 인덱싱과 슬라이싱은 계속 반복해서 공부하고 잘 알아야 한다.
나중에 데이터 분석쪽으로 가면, csv 파일을 가져오면 행단위로 데이터를 가져오고
열 단위로 속성들이 있을 것이다.
A라는 사람의 이름, 나이, 연봉, 월 지출액, ... 등이 들어갈 것인데, 행을 골라서 쓸일은 없다.
그런데 열단위로 기준으로 해서 행을 뽑을 일은 있다. 그때 인덱싱과 슬라이싱을 이용해서 가져온다.
만약 행은 전체 다 뽑아오고 열은 2열부터 5열 까지 뽑아온다? [2:5] 이런 식으로 뽑아온다. 예를 들어 연봉이 몇 이상인 사람을 뽑아와야 하는데, 그 연봉만 뽑으면 안되니까, 이름같은 거는 뽑아야 하니까.
e=('a','b',('ab','cd'))
print(e[2])
print(e[2][0])
print(e[2][1])
# ✅ 출력 결과
# ('ab', 'cd')
# ab
# cd1.4. tuple 연산
추가 삭제만 안될 뿐 다른 객체들(str, list)과 동일하다.
x=(3,4)
y=(5,6)
print(x+y)
print(x*3)
print(4 in x)
print(4 not in y)
# ✅ 출력 결과
# (3, 4, 5, 6)
# (3, 4, 3, 4, 3, 4)
# True
# False1.5. tuple method
다시 한번 말하지만 너무도 많은 메서드들이 존재하기 때문에 자세한 부분은 파이썬 문서 - tuple을 참고하면서 필요시 찾아서 사용하자.
# tuple method
z=(10,20,30,40,10,50,60)
print(z.index(50))
print(z.count(10))
# 파이썬 내장함수
print(len(z))
print(max(z), min(z))
print(sorted(z))
print(sorted(z, reverse=True))
# ✅ 출력 결과
# 5
# 2
# 7
# 60 10
# [10, 10, 20, 30, 40, 50, 60]
# [60, 50, 40, 30, 20, 10, 10]
1.7. ⭐ tuple의 강점(핵심)
1.7.1. packing, unpacking
- packing: 하나의 변수에 여러개의 값을 넣는 것
- unpacking: packing된 변수에서 여러개의 값을 꺼내 오는 것
packing은 하나의 변수에 여러 개의 값을 넣는 것이다. 물론 다른 것들도 여러 개를 넣는데, unpacking 과정에서 차이를 보인다.
num=(1,2,3)
print(num[0])
# ✅ 출력 결과
# 1리스트는 a=[1,2,3,4] 일때, a[0], a[1] 이런식으로 요소를 추출해야 한다.
tuple도 물론 이렇게 인덱스로 찾아갈 수 있지만, unpacking이라는 것이 존재한다.
unpacking은 packing된 변수에 여러 개의 값을 꺼내 온다.
그리고 이런게 파이썬에만 있는 튜플의 강점이다.
one, two, three = num
print(num, type(num))
print(one, type(one)) # 하나씩 뽑아오니 integer
print(two, type(two))
print(three, type(three))
print(one, two, three)
# ✅ 출력 결과
# (1, 2, 3) <class 'tuple'>
# 1 <class 'int'>
# 2 <class 'int'>
# 3 <class 'int'>
# 1 2 3실질적으로는 아래와 같이 사용한다.
city, lat, long=('Seoul', 7.541, 126.986) # () 생략 가능, `city, lat, long='Seoul', 7.541, 126.986`
print(city, lat, long)
# ✅ 출력 결과
# Seoul 7.541 126.9861.7.2 치환에 자유롭다
x=1
y=2
print(x,y)
# ✅ 출력 결과
# 1 2원래 다른 언어에서 값을 치환하고자 한다면 다음과 같이 해야한다.
변수 y와 x의 값을 서로 바꾸고 싶다면 새로운 변수(temp)를 먼저 선언해야 한다.
그 후 새로운 변수(temp)에 x의 값을 할당하고 y의 값을 x에 할당하여 치환시킨 후,
다시 새로운 변수(temp)에 할당된 값을 y에 할당해 주어야 한다.
temp=x
x=y
y=temp
print(x,y)
# ✅ 출력 결과
# 2 1하지만 파이썬의 튜플(tuple)은 이 치환에 자유롭다.
x,y=1,2
print("현재 x, y 값:", x, y)
x,y=y,x
print("치환한 x, y값:", x, y)
# ✅ 출력 결과
# 현재 x, y 값: 5 10
# 치환한 x, y값: 10 5💪 코드 빈칸 채우기 퀴즈
Q1. 실행 결과를 보고 빈칸을 채워 코드를 완성 시켜라.
data = ____A____
first_name, last_name, age = ____B____
print(f"Name: {first_name} {last_name}, Age: {age}")Name: 신 짱구, Age: 30A1. A: ('신', '짱구', 10) / B: data
Q2. 실행 결과를 보고 빈칸을 채워 코드를 완성 시켜라.
t1 = (1,2,3)
t2 = ____A____
result = t1 + t2
print(result * 2)(1, 2, 3, 3, 2, 1, 1, 2, 3, 3, 2, 1)A2. A: (3,2,1)
Q3. 튜플에 banana 가 있는지 확인하는 코드의 실행 결과를 보고 빈칸을 채워 코드를 완성 시켜라.
fruits = ('apple', 'banana', 'orange')
result = ____A____
print(result)TrueA3. A: 'banana' in fruits
Q4. 실행 결과를 보고 빈칸을 채워 코드를 완성 시켜라.
num = (10, 20, 30, 10, 30, 50, 70)
index_of_30 = num.____A____(30)
count_of_20 = num.____B____(20)
print("첫 번째 30의 인덱스 위치는 %d 입니다." %(index_of_30))
print("20의 개수는 %d 개 입니다." %(count_of_20))첫 번째 30의 인덱스 위치는 2입니다.
20의 개수는 1개 입니다.A4. A: index / B: count
Q5. 실행 결과를 보고 빈칸을 채워 코드를 완성 시켜라
fruits = ('apple', 'banana', 'orange')
print(____A____)
print(____B____)
print(____C____) apple
('banana', 'orange')
('orange', 'banana', 'apple')A5. A: t[0] / B: t[1:] / C: t[::-1]
