
📌 사용 환경
Python 3.10.2
conda 24.9.0
JupyterLab 4.2.5
- 함수 구조
- 인수 형식
- 변수 유효 범위
- 내장함수
- Lamda
⭐ 1. 함수
매우 중요한 내용이다. 이 부분을 제대로 이해하지 못한다면 진행이 안되기 때문에 반드시 잘 숙지하자.
arr=[1,2,3,4]
지금까지 이런 데이터를 가지고 뭔가 작업을 하기 위해서 반복문, 조건문 등을 이용해서 원하는 데이터를 뽑아왔었다.
그러면 지금까지 한 것은 데이터를 살펴본 것이다.
아래 코드를 보자.
a=10
b=20
c=a+b이런것도 기능이고
x=50
y=60
z=x+y이 것도 기능이다.
그런데 보면 이 둘은 똑같이 합을 출력하는 것으로 기능이 겹친다.
그래서 이를 하나의 기능을 묶어 놓은 것이 함수다.
함수(i,j){
...
}이렇게 하나의 블럭으로 묶어서 함수를 만들어서 이를 사용하는 것이다.
x=50
y=60
함수(x,y)앞서 컬렉션에 대해 글을 정리했는데, 컬렉션의 종류는 다른 언어는 30-40개 정도인데, 파이썬은 적다. 쉽다.
하지만 함수는 다르다. 다른 언어는 3가지 정도이지만, 파이썬은 함수가 7가지 정도의 방법이 있다. 매우 중요하다.
함수는, 데이터의 기능들을 모아 놓은 것으로, 입력값을 가지고 어떤 일을 수행한 다음 그 결과물을 내어놓는 것이다.
2. 함수를 사용하는 이유
for i in range(1, 11, 1):
print("hahaha")
...
...
...지금까지 이런 걸 배웠는데
...
...
...
print("hahaha")
...
...
print("hahaha")이렇게 중간중간 다른 내용들이 쭉 있는 경우 for문을 쓸 수 없다.
그래서 이런 경우에 함수를 만든다.
def disp(): # 출력을 담당하는 기능의 함수 **정의** -> 이 부분에 매개변수도 없음
print("hahaha")그래서 이제는 아래와 같이 사용 가능하다.
...
...
...
disp() # 이렇게 이름을 불러줄 때, 값이 없음(인수가 없음)
...
...
disp()즉 함수를 사용하는 이유는 반복되는 부분이 있을 경우 '반복적으로 사용되는 가치 있는 부분'을 하나로 묶어서 '어떤 입력값을 주었을 때 어떤 결과값을 돌려준다' 라는 식의 함수로 작성하는 것이 현명하다.
또, 프로그램의 흐름을 파악하기 좋고 오류 발생 지점도 찾기 쉽다.
3. 함수의 종류
- 내장함수: 파이썬 기본적으로 제공하는 함수(print(), type(), input() 등) 이다.
- 사용자 정의 함수: 프로그램 안에서 필요한 기능을 사용자가 직접 만들어서 사용하는 함수이다.
다른 모듈(package)함수: 다른 파이썬 파일에서 정의한 함수나 패키지의 함수이다.
(import하여 사용, 날짜함수, 파일함수 등)
4. 함수의 구조
예를 들면 과일에는 사과, 배, 수박 등이 있는데 믹서기로 갈면 다 각각 주스들이 나온다.
즉 과일이 입력, 믹서기가 함수, 주스가 출력이 된다.
def blender(fruit):
code1
code2
return juice
blender("딸기")용어를 잘 알아두자.
def: define으로 함수를 정의할(만들) 때 사용하는 예약어이다.blender: 함수의 이름으로 임의로 설정한다.fruit: 매개변수(parameter)로 함수에 입력으로 전달되는 값을 받는 변수이다.return: 함수의 결과값을 돌려주는(반환) 명령어다.blender(): 함수를 호출하는 부분으로()안에 들어가는 것은 인수(Argument)라고 한다.
즉, blender라는 함수의 fruit라는 매개변수로 "딸기"라는 인수를 보내고, 그 결과 값을 함수를 호출한 부분으로 돌려줘야 하는데, 그 return 값이 juice 인 것이다.
5. 기본 함수 형태
- 인수, 매개, 리턴 - X
- 인수, 매개 - O / 리턴 - X
- 인수, 매개 - X / 리턴 - O
- 인수, 매개, 리턴 - O
- 입력값: 인수(argument)/매개변수(parameter)
- 출력값: return
5.1 인수, 매개, 리턴 - X
- C언어 표현: Call By Name
- 입력값: 인수(argument)/매개변수(parameter) - X
- 출력값: return - X
def func_name(): # 정의
code1
code2
func_name() # 호출함수 정의 - 사용자 정의 함수
# 정의 - 사용자 정의 함수
def disp():
print("Hello", end=" ") # 파이썬 내장 함수
# 호출
disp()
# ✅ 출력 결과
# Hello5.2. 인수, 매개 - O / 리턴 - X
- C언어 표현: Call By Value
- 입력값: 인수(argument)/매개변수(parameter) - O
- 출력값: return - X
a=10
b=20
c=a+b
...
...
...
x=30
y=77
z=x+y
...
...
i=80
j=90
k=i+j이런 경우를 위해서 함수를 하나 만들어 놓자.
def plus(a,b):
print(a+b)a=10
b=20
plus(a,b)
...
...
...
x=30
y=77
plus(x,y)
...
...
plus(80,90)이렇게 인수(argument)를 넘겨주고 매개변수(parameter)가 받는 모습,
즉 함수를 호출할때 값을 넘겨주니까 call by value 라고 한다.
# 함수 정의
def star(a):
for i in range(a):
print("*", end=" ")
print()
# 함수 호출
star(10)
# ✅ 출력 결과
# * * * * * * * * * * ⭐ 파이썬의 특징
파이썬은 모든 자료 구조가 다 된다.
def aa(num): ... ... aa(1) aa("a") aa(1,2) aa([1,2,3,4,5]) aa((1,2,3)) aa({"aa":"aa", "bb":"bb"})이런것들이 그동안 다 잘됐었다.
다른 언어들은 이게 안된다.
def plus(int a, int b):이런식으로 타입을 정해줘야한다.그런데 파이썬은 된다. 그 이유는 파이썬은 동적 타입 언어이자 reference(참조) 타입이기 때문이다.
그래서 데이터 타입을 따로 명시하지 않아도 되며 변수에 어떤 값을 할당하느냐에 따라 그 타입이 결정된다.
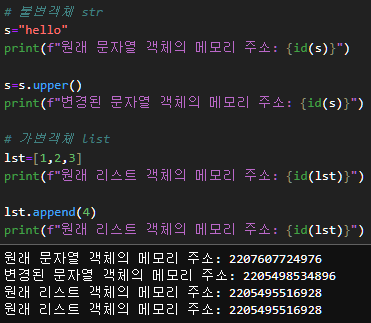
물론 함수 부의 매개변수(parameter)가 2개일 경우에는 인수(argument)도 2개를 넘겨주는 것은 맞춰주어야 한다.또, 파이썬은 reference 타입으로 변수에 실제 값을 저장하는 것이 아닌 값이 저장된 메모리 주소를 참조하는데, 이는 불변 객체와 가변 객체에 대해서 조금 이해를 해야한다.
불변 객체로는 int, str, tuple이 있고,
가변 객체로는 list, dictionary, set가 있는데,
이 둘에서 메모리 주소 참조 부분에서 차이를 보인다.지난 method 부분에서 정리했듯이 method를 이용하여 값에 수정과 같은 영향을 주면 실제 데이터의 값에도 영향을 미치는 것을 알 수 있었다.
그런데 실제로는 불변 객체에서 제공하는 method들은 새로운 객체를 반환하는 방식으로 동작한다. 그렇기 때문에 불변성을 유지할 수 있다.
즉, 불변 객체는 값을 변경하는 method가 없고 변경된 값들은 실제로는 변경이 아닌 새로운 객체를 생성한 후에 값을 반환하여 바인딩 되는 것이다.
반대로 가변 객체는 값을 변경해도 같은 객체를 reference하고 있기 때문에, 값이 변경되면 모든 변수에 영향을 미친다.
이 부분은 아래 그림을 참조해서 기억해두자.
# 정의 # 모든 자료형(자료구조)로 호출이 다 된다. def disp(a): print(a, type(a)) # 호출 disp(10) disp(55.5) # ✅ 출력 결과 # 10 <class 'int'> # 55.5 <class 'float'>다른 언어들은 이런게 안되고 파이썬과 자바스크립트만 가능하다.
⭐ Return 값
지금까지 위 Call By Name(인수,매개,리턴-X)과 Call By Value(인수,매개-O / 리턴-X) 이 경우에서는
# 정의 def disp(a): print(a, type(a)) # 호출 disp(10) # ✅ 출력 결과 # 10 <class 'int'>이런 결과값을 받았었는데, 이는 Jupyter에서 제공하는 display기능 때문에 값을 출력하게 됐다.
그런데 이를 만약 print()함수를 붙여서 출력하면
10 <class 'int'> None이 출력된다.
그 이유는 함수에서는 return의 값을 명시하지 않으면 기본적으로 None을 반환하기 때문이다.따라서 다음으로 나오는 Call By Return(인수,매개-X / 리턴-O)과 Call By Value ~ Return(인수,매개,리턴-O)은 리턴 값이 정해져있기 때문에
print()를 붙여서 결과를 볼 수 있다.
5.3. 인수, 매개 - X / 리턴 - O
- C언어 표현: Call By Return
- 입력값: 인수(argument)/매개변수(parameter) - X
- 출력값: return - O
def aa():
return "apple"그런데 return값이 있을 때는,x=aa() 이런식으로 return 값을 받아줄 변수가 있어야 한다.
그 다음에 print를 찍어보면 된다. print(x)
# 정의
def name():
return "My name is Julian"
# 호출
irum=name()
irum
# print()를 이용하면
print(name())
# ✅ 출력 결과
# 'My name is Julian'
# My name is Julian5.4. 인수, 매개, 리턴 - O
- C언어 표현: Call By Value~Return
- 입력값: 인수(argument)/매개변수(parameter) - O
- 출력값: return - O
이도 Call By Return과 마찬가지로 return값이 있을 때는,x=plus() 이런식으로 return 값을 받아줄 변수가 있어야 한다.
그 다음에 print를 찍어보면 된다.
def plus(a,b)
return a + b
y=plus(3,4)
print(y)
# ✅ 출력 결과
# 7# 정의
def add(a,b):
return a+b
# 호출
c=add(1,2)
print(c)
# ✅ 출력 결과
# 3⭐ tuple을 이용한 여러개의 리턴값
파이썬에서만 가능하다.# 정의 def swap(a, b): return b, a # 호출 c, d=swap(10,20) print(c, d) # ✅ 출력 결과 # 20 10
6. 인수의 다양한 형태
- 키워드 인수
- 기본 인수
- 가변 인수
- 키워드 가변 인수
6.1. 키워드 인수
- 함수 실행(호출)시 설정
가독성 향상
매개변수의 이름을 명시하므로, 함수 호출 시 코드의 의도를 더 명확하게 전달
일반(위치) 인수와 사용하면 매개변수의 순서와 역할을 이해하기 어려움
키워드 인수를 사용하면 어떤 값이 어떤 매개변수에 전달되는지 쉽게 이해할 수 있음
인수형식에는 키워드 인수, 기본값(default)인수, 가변 인수, 키워드 가변 인수 4가지 형식이 있다.
일반(위치) 인수는 일반적으로 지금까지 해온 것과 같이 함수를 호출하면서 인수를 전달하는 형식들을 말하기 때문에 따로 작성하지 않았다.
키워드 인수는 함수 호출 시 인수가 많아서 전달하기 힘들 때 주로 사용한다.
def abc(kor, eng, mat, name, bunho, height):
...abc(70,80,90,"홍길동",101,170)이렇게 호출할 수 있는데,
만약 함수 정의 부분이 한참 위에 있고, 시간이 지나서 확인해보면 아 이게 뭐였지? 하는 생각이 들 수 있다. 또는 매개변수의 수가 너무 많아서 헷갈릴때가 있다. 그래서 이 키워드 인수가 나온다.
abc(kor=70,eng=80,mat=90,name="홍길동",bunho=101,height=170)이렇게 쓴다.
인수의 이름을 명시(지정)해서 전달하기 때문에 함수 호출에 있어서 순서가 바뀌어도 상관 없다.
다른 언어들은 함수 정의할 때 def abc(int kor, float eng) 이런식으로 자료형 또는 클래스를 지정해주어서, 만약 호출 부분에서 이를 잘못하면 에러 메세지를 출력하여 실수할 일이 거의 없다.
그런데 파이썬은 그게 아니다. 파이썬은 자료형 선언을 안하고 모든 자료형을 다 받는다.
그래서 데이터가 잘못 들어왔을때, 잡아낼 수 있는 방법이 없다.
그래서 이 키워드 인수를 사용한다.
단, 일반(위치) 인수와 키워드 인수를 혼합하여 사용할 때는 일반 인수 뒤에 키워드 인수를 작성해야 한다.
즉 함수를 호출할 때 x(a,b) 일때, a=1, 1 은 안되고, 1, a=1은 가능하다.
코드를 보면서 좀 더 알아보자.
# call by value~return
def plus(a,b):
return a+b
plus(1,2) # 일반(위치) 인수
plus(a=3,b=4) # 키워드 인수
# ✅ 출력 결과
# 3
# 7여기까지는 기본적인 부분인데, 다양한 형태로 키워드 인수를 호출하는 방법들이 있다.
# 명시를 해주었기 때문에 순서가 바뀌어도 가능하다.(하지만 뭐 굳이 사용할 필요는 없다.)
plus(b=5,a=6)
# 일반(위치) 인수와, 키워드 인수의 혼합
# b는 반드시 명시를 해야하니까 사용한 것이다.
# 이 데이터는 반드시 넣어주어야 한다. 이럴 경우 확실하게 하기 위해 사용한다.
# 그런데 만약 이 순서가 바뀐다면? ERROR가 발생한다.
# 즉 혼합시 일반(위치) 인수는 **반드시** 키워드 인수보다 앞에 있어야 한다.
plus(7,b=8)
plus(a=9,10)
✅ 출력 결과
# 11
# 15
6.2 기본값(default) 인수
- 함수의 정의시 설정
함수 호출 시 인수 값을 전달하지 않을 경우 인수의 기본값 지정이 가능하다.
자주 바뀌지 않는 데이터는 기본값을 통해 처리한다.
기본값 정의하는 인수는 인수목록의 뒤쪽에 위치해야 한다.
기본값을 가지는 인수의 개수는 제약이 없다.
파이썬 문서 - print() 에서 print() 함수를 보면 다음과 같은 구조를 가진다.
print(*objects, sep=' ', end='\n', file=None, flush=False)
그래서 우리가 print()로 출력하면 기본적으로 여러 값이 있을 때 구분자(sep)로 띄어쓰기를 해주고,
출력을 마치는 마지막 값(end)으로 개행문자(\n)로 설정되어 있기 때문에 한 줄씩 띄어졌던 것이다.
이런게 default 인수다.
우리가 구분자(sep)를 ,(콤마)로 지정해주기 위해서 print(..., sep=",") 로 지정해 줄 수 있었고, 마지막 값(end)으로 띄어쓰지 않게 하기 위해 print(..., end=" ")와 같이 지정해 줄 수 있었다.
즉 print() 함수 내부에서 default로 지정해 준 내용은 함수를 호출할때 인수로 따로 지정해 주지 않았을 때 출력이 되는 것이며, 만약 인수를 지정해 준다면 해당 매개변수로 값을 지정해 주는 것이다.
개인적으로 default 매개변수 값이라고 하면 이해가 좀 더 잘 될텐데 아쉽다.
이런 부분에 좀 더 익숙해 지려면 파이썬 문서 - 내장함수 부분을 참고하자.
코드를 보면서 좀 더 알아보자.
def plus(a, b=1, c=3):
print("a=%d, b=%d, c=%d" %(a,b,c))
return a+b+c
plus(10)
# ✅ 출력 결과
# a=10, b=1, c=3
# 14- default로 잡혀있긴 하지만 값에 치환이 가능하다.
plus(10, 20)
plus(10, 20, 30)
# ✅ 출력 결과
# a=10, b=20, c=3
# 33
# a=10, b=20, c=30
# 60- default 인수가 좋은 점
def calc(start, end, step=2):
plus=0
for num in range(start, end+1, step): # 원하는 값은 입력하는 값까지 더하는 것이기 때문에 +1로 설정함
plus += num
return plus
calc(1, 100)
calc(5, 200)
# ✅ 출력 결과
# 2500
# 9996default 인수가 좋은 이유는 치환이 가능하기 때문이다.
만약 증감을 2씩 하는 것으로 그대로 이용하다가.
이번에는 4로 하고 싶다면 치환을 이용하면 된다.
calc(1, 100, 5)
# ✅ 출력 결과
# 970- 우선순위로 인한 에러
def melon(a=1, b, c=3):
pass이런 경우 일반(위치) 인수가 우선순위가 더 높기 때문에 에러가 발생한다.

따라서 아래와 같이 바꿔야 한다.
def melon(b, a=1, c=3)6.3 가변 인수
- 함수의 정의 시 설정
정의된 인수 개수가 아닌 여러개(n개) 인수를 받기 위한 인수다.
인수명 앞에*기호를 붙인다.
가변인수는 위치 인수 뒤에 작성하며, 1개만 존재 가능하다.
가변인수로 받은 값들은 모두 튜플의 요소로 처리되어 for...in 문으로 처리 가능하다.
여러(n개) 전달해 처리하고 싶을 때, tuple 형태로 전달한다.
앞서 print() 함수에서 print(*objects, sep=' ', end='\n', file=None, flush=False)를 다시보면
*objects 이 부분이 가변 인수이다.
그리고 가장 앞에 있어도 오류가 없는 이유는 일반(위치) 인수가 없기 때문이다.
print() 함수에 여러 값들을 넣으면 다 이 *objects 인 가변 인수로 들어가게 되고 튜플의 요소로 들어가게 된다.
def calc(num, *values):
print("num=%d, value=%s" %(num, values))
print(type(num), type(values)) # 타입을 잘 보자
plus=0
for val in values:
plus += val
return plus + num이제 함수를 호출하면서 타입을 잘 보자
calc(1)
calc(1,2)
calc(1,2,3,4)
# ✅ 출력 결과
# num=1, value=()
# <class 'int'> <class 'tuple'>
# num=1, value=(2,)
# <class 'int'> <class 'tuple'>
# 3
# num=1, value=(2, 3, 4)
# <class 'int'> <class 'tuple'>
# 10이와 같이 나머지는 튜플로 처리되는 모습을 볼 수 있다.
대신 이 calc(1,2,3,4) 이런 코드를 보고 함수 정의 부분에 매개변수가 4개라고 착각할 수 있기 때문에 항상 함수 정의부를 먼저 봐야한다.
6.4. 키워드 가변 인수
- 함수의 정의 시 설정
여러(n개)의 키워드 인수 전달 시 인수의 이름과 값을 쌍으로 사전형(dictionary)으로 전달한다.
인수명 앞에**기호를 붙인다.
인수 하나로 여러 개의 키워드 이름과 값을 한번에 받는 것이 가능하다.
가변인수는 인수의 마지막에 작성한다. (위치 인수, 키워드 인수, 가변 인수)
키워드 인수와 헷갈릴 수 있다.
하지만 이는 어쩔 수 없이 함수 정의부를 봐야 한다.
따라서 **가 있으면 dictionary 형태 라고 생각해야 한다.
def dic_test(**num):
print(type(num))
for val in num.values():
print(val)
dic_test(a=1,b=2,c=3)
dic_test(name="짱구", school="떡잎유치원")
# ✅ 출력 결과
# <class 'dict'>
# 1
# 2
# 3
# <class 'dict'>
# 짱구
# 떡잎유치원이를 좀 더 활용하면
def average(name, **scores):
total = 0
num_subject = len(scores)
for key, value in scores.items():
total += value
if num_subject > 0:
avg = total / num_subject
else:
avg = 0
return "%s의 평균 점수는 %.2f입니다." %(name, avg)
result = average("Julian", kor=95, math=90, english=85)
print(result)
# ✅ 출력 결과
# Julian의 평균 점수는 90.00입니다.6.5. 혼합 인수
혼합일 경우의 순서(우선순위)
함수 정의: 일반(위치), 기본값(default), 가변, 키워드 가변
함수 호출: 일반(위치), 키워드, 가변, 키워드 가변
def func(a, b=2, *c, **d):
print(a, b, c, d)
func(1)
func(10,20,30)
func(10,20,name="julian",age=20)
✅ 출력 결과
# 1 2 () {}
# 10 20 (30,) {}
# 10 20 () {'name': 'julian', 'age': 20}7. 변수의 유효 범위(Variable Scope)
지역변수(local)와 전역변수(global)
다른 언어들 중에는 global이랑 local이 철저하게 분리되는 언어들이 있기도 하지만,
파이썬에서는 파일 단위로 데이터를 던지는 경우가 많이 없기는 하다.
변수의 유효 범위(variable scope)라고 하는데, 변수가 선언된 위치에 따라 해당 변수가 영향을 미치는 범위가 달라진다.
지역변수(local)는 함수 내에서 선언된 변수를 말하며, 해당 함수 내에서만 접근할 수 있다.
반대로 전역변수(global)는 함수 외부에서 선언된 변수로, 어디에서든 접근 가능하다.
이 전역변수는 함수 내에서도 global 키워드를 붙여서 선언할 수 있으며 이 경우는 함수 내부에 있더라도 접근 가능하다.
a="전역변수"
def func():
b="지역변수"
print(a)
print(b)
print(a)
# ✅ 출력 결과
# 전역변수이렇게 전역변수는 범위가 전체이기 때문에 접근이 가능하지만, 만약 지역변수에 접근한다면?
print(b)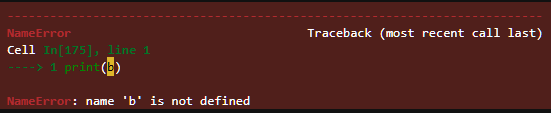
이렇게 지역변수를 불러올 수 없기 때문에 에러가 발생한다.
그렇다면 함수 안의 변수에 접근하려면 어떻게 할까? global을 붙여준다.
def func2(x): # 매개변수도 물론 local 변수이다.
global y
y="전역변수"
z="지역변수"
print(x,y,z)단 전역 변수를 선언할 때는 global y = 10 이런식으로는 사용하지 못한다. 에러가 발생한다. 반드시 global y를 따로 선언하고 그 이후에 값을 할당해줘야 한다.
def func2_test(x):
global y = "전역변수"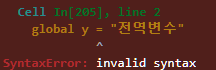
이제 다시 func2로 돌아와서 출력해보자.
print(y)
func2("매개변수")
# ✅ 출력 결과
전역변수
매개변수 전역변수 지역변수8. 내장 함수
파이썬에서 기본적으로 제공하는 함수
파이썬 설치 시, 자동으로 설치되고 실행(메모리 로드)된다.
print(), input(), type(), max(), min(), sorted() 같은 것들이 있다.
파이썬 - 내장함수 참고
전체를 다 외울수는 없다. 필요시에 문서를 참고하면서 가져다 써야한다.
대신 어떻게 동작하는지 내부 구조들이 있을때, 그 내부 구조를 보고 어느 정도 이해할 수 있어야 하기 때문에 몇가지를 알아보자.
8.1. abs(x)
- 입력받은 수를 절대값으로 반환하는 함수
만약 사용자 정의 함수였다면 이렇게 만들었을 것이다.
def abs(x):
절대값처리
return x
abs(-10)이를 내장 함수인 abs()를 사용하면 다음과 같다.
abs(10)
abs(-10)
# ✅ 출력 결과
# 10
# 10그런데 abs() 함수의 내부를 보면 아래와 같이 써있다.
Signature: abs(x, /)
Docstring: Return the absolute value of the argument.
Type: builtin_function_or_method
그런데 x는 알겠는데 /는 무슨 뜻인지 모르겠다.
이는 사실 일반(위치) 인수만 받겠다는 뜻이다.
확인하려면 다음과 같다.
먼저 테스트를 위해 func라는 이름의 함수를 만드는데 매개변수로 x와 /를 넣어보자.
# def sub(x):
def sub(x,/):
passsub(10)이는 문제없이 지나가지만
sub(x=10)
이렇게 키워드 인수로 전해주면 에러가 발생한다.
그렇다면 abs()로 다시 테스트해보면?
abs(x=10)
이렇게 에러가 발생한다. 그러니 이런 내장함수에 숨겨져 있는 부분들을 잘 보는게 중요하다.
8.2. chr(i)
- 아스키 코드(숫자)를 입력받아 문자를 출력하는 함수
입력하는 데이터들이 메모리로 들어가는 과정은 그냥 들어가는 거라고 생각할 수 있지만 사실 다음과 같다.
만약 10이라는 숫자를 입력한다면? 2진수(0과 1의 조합) 로 변환하여 들어가고,
A라는 문자는 아스키 코드로 65로 그리고 65가 다시 2진수(0과 1의 조합) 로 변환되어 들어간다.
그래서 이런 아스키 코드를 보기 위한 함수가 chr()이다.
chr(97)
chr(65)
# ✅ 출력 결과
# 'a'
# 'A'8.3. dir()
변수와 함수, 객체 리스트를 출력한다.
scope에서 정의된 변수, 함수, 객체 리스트를 출력한다.
객체란 클래스에서 파생된 것들이다.
객체의 대표적인 예로는 list, string, dictionary, set, tuple 같은 것들이 있다.
그런데 문서를 찾아보면
dir()과 dir(object)의 두 개가 있다.
dir()은 Call By Name으로, 현재 정의되어 있는 객체하고 리스트가 호출되는 것이고,
dir(object)는 객체명을 넣어주면 되는 것이다.
리스트의 경우 다음과 같다.
# 리스트
dir([1,2,3]) # list: 컬렉션, 객체(변수,함수(메서드))
# 딕셔너리
dir({"1":"a"}) #dictionary: 컬렉션, 객체(변수,함수(메서드))
# ✅ 출력 결과
# ['__add__',
# '__class__',
# '__contains__',
# '__delattr__',
# ...
# ['__class__',
# '__contains__',
# '__delattr__',
# '__delitem__',
# '__dir__',
# ...8.4. divmod(a, b)
- 2개의 숫자를 입력받아 a를 b로 나눈 몫과 나머지를 튜플 형태로 반환한다.
print("몫:", 5//2)
print("나머지:", 5%2)
# 몫과 나머지를 같이 출력하는 `divmod()` 라는 함수가 존재한다.
print("몫과 나머지:", divmod(5,2))
# ✅ 출력 결과
# 몫: 2
# 나머지: 1
# 몫과 나머지: (2, 1)8.5. ⭐ enumerate(iterable)
- 인덱스 값을 포함한 객체를 반환한다. 일반적으로 for문과 함께 자주 사용한다.
# 리스트
num=[1,2,3,4,5]
print(num)
# 하나씩 뽑기
for val in num:
print(val, end=" ")
# ✅ 출력 결과
# [1, 2, 3, 4, 5]
# 1 2 3 4 5- enumerate는 인덱스 값도 함께 뽑아준다.
for idx, val in enumerate(num):
print(idx, val)
# ✅ 출력 결과
# 0 1
# 1 2
# 2 3
# 3 4
# 4 5enumerate()의 내부를 보면
Init signature: enumerate(iterable, **start=0**)
Docstring:
Return an enumerate object.
iterable
an object supporting iteration
The enumerate object yields pairs containing a count (from start, which
defaults to zero) and a value yielded by the iterable argument.
enumerate is useful for obtaining an indexed list:
(0, seq[0]), (1, seq[1]), (2, seq[2]), ...
Type: type
Subclasses: 이렇게 나와 있는데 start=0은? 디폴트 인수다.
그러면 만약 2번부터 출력하고 싶다면 아래와 같이 사용하면 된다.
for idx, val in enumerate(num, 2):
print(idx, val)
# ✅ 출력 결과
# 2 1
# 3 2
# 4 3
# 5 4
# 6 58.6. int(x)
- 문자열 형태의 숫자나 소수점에 있는 숫자등을 정수로 반환한다.
print(int('3'))
# ✅ 출력 결과
# 3int()의 내부를 보면
Init signature: int(self, /, *args, **kwargs)가 있는데,
이걸 보면 self -> 이는 객체 지향 프로그래밍에서의 인스턴스를 가리키는 참조를 말한다.
이는 클래스 쪽에서 좀 더 다루겠다.
print(int(3.14))
# ✅ 출력 결과
# 38.7. round(num, ndigits=None)
- 반올림 해주는 함수다.
- (필수, 선택적)
나중에 예측쪽으로 가면 보통 0~1 사이의 값들이 나오는데 1에 수렴할 수록 예측을 잘했다고 하는 것이다.
근데 0.1231312311321312313131 이렇게 많다면? round함수를 사용한다.
(round(num,[ndigits]) []는 생략해도 된다는 뜻)
print(round(5.56))
print(round(5.56,1)) # 둘째 자리에서 반올림함
# ✅ 출력 결과
# 6
# 5.68.8. isinstance(object, classinfo)
class Person: #클래스명
pass
p=Person() #클래스 객체 만들기(생성자)
# 이때 isinstance는 걔가 Person이라는 클래스에서 만들어진 애니? 라는 말
isinstance(p, Person)
# ✅ 출력 결과
# True- 이런게 언제 유용할까?
num=[1,2,3,"a","b",25.7]
type(1), type("a"), type(25.7)
# ✅ 출력 결과
# (int, str, float)여기서 타입을 찍으면 각각 int, str, float이라고 나온다.
근데 이들을 num=[1,2,3,"a","b",25.7] 라는 리스트로 묶었다.
그런데 여기서 만약 숫자만 뽑아서 연산하고 싶다면? 그러면, "a"와 "b"는 빼야하는데, 그럴때 쓰는게 isinstance다.
sum = 0 # 만약 합한 값을 원한다면
for val in num:
if isinstance(val, (int, float)):
print(val)
sum == val
print(sum)
# ✅ 출력 결과
# 1
# 2
# 3
# 45.6
# 51.6if isinstance(val, (int, float)):로 현재 요소가 int 또는 float인지 검사한다.
9. ⭐ 람다(Lambda) 함수
- 함수를 생성할 때 사용하는 예약어
- def와 동일한 역할
- 익명의 함수로(함수명 없음) 한 줄로 간결하게 만들 때 사용한다.
- 일회성으로 필요한 경우에 사용하며, 함수를 정의하고 호출하는 과정을 줄여준다.
변수에 값을 할당해주는 것처럼 사용한다.
함수이름 = lambda 매개변수1, 매개변수2, ... : 매개변수를 사용한 표현식
즉 함수이름 = labda input : output 이다.
이 람다(Lambda) 함수는 정말 자주 쓰이기 때문에 앞으로의 글에서 필요할 때마다 추가 설명을 할 것이다.
그렇다면 이 람다(Lambda) 함수는 언제 쓸까?
def abc():
...
...지금까지 이렇게 10줄이 넘어가지 않았는데, 만약 함수가 1줄처럼 짧고 한번쓰고 버려진다면?
그럴때 람다 함수를 사용한다.
예를들어 키보드의 a라는 키를 눌렀을때, b라는 키를 눌렀을때 이런 경우나 마우스를 올렸을때와 같은 이벤트에서 많이 쓰인다.
def add1(x,y):
return x+y
add1(1,2)
# ✅ 출력 결과
# 3이를 lambda로 바꾸면
add2=lambda x, y : x + y
add2(3,4)
# ✅ 출력 결과
# 7곱셈 연산으로 생각하면
def mul1(x):
return x**2이런 함수를 lambda로 하여 간단하게 한 줄로 바꿀 수 있다.
mul2=lambda x : x**2
mul2(2)
# ✅ 출력 결과
# 4그런데 만약 이 과정중에 if문이나 else 같은 것들로 들어가면 그냥 함수를 만드는 것이 낫다.
그렇지 않으면 오히려 한 줄안에 다 표현하면서 더 복잡해지며 가독성이 떨어지게 된다.
💪 코드 작성 퀴즈
Q1. func1 함수를 작성하시오.
- 조건
- func1은 매개변수와 인수를 사용하지만 리턴값은 없다.
- 호출 예시:func1(5, 10)
- 출력 예시:입력된 값: 5, 10
A1.
def func1(x,y):
print("입력된 값: %d, %d" %(x, y))
func1(5,10)Q2. func2 함수를 작성하시오.
- 조건
- func2는name을 인수로 받는 함수이며, 기본값으로는"User"를 설정한다.- func2는 인수 name을 받아 인사말을 출력한다.
- 기본(위치) 인수를 사용하라.
- 호출 예시:
func2("Julian") - 출력 예시:
안녕하세요, Julian님
A2.
def func2(name="User"):
print("안녕하세요, %s님" %(name))
# User 출력을 원할 경우: func2()
func2("Julian") Q3. func3 함수를 작성하시오.
- 조건
- func3는 여러 개의 숫자를 받아 합을 반환한다.- 가변 인수를 사용하라.
- 호출 예시:
func3(1, 2, 3, 4) - 출력 예시:
합: 10
A3.
def func3(*num):
total = 0
for i in num:
total += i
print("합: %d" % (total))
func3(1,2,3,4)Q4. func4 함수를 작성하시오.
- 조건
- divmod()를 사용하라.- 호출 예시:
func4(10, 3) - 출력 예시:
몫: 3, 나머지: 1
- 호출 예시:
A4.
def func4(a, b):
x, y = divmod(a, b)
print(f"몫: {x}, 나머지: {y}")
func4(10, 3)Q5. func5 함수를 작성하시오.
- 조건
- func5는 lambda 함수다.- 호출 예시:
func5(10,4) - 출력 예시:
6
- 호출 예시:
A5.
func5 = lambda x, y : x-y
print(func5(10,4))Q6. func6 함수를 작성하시오.
- 조건
- total이라는 전역 변수를 10으로 설정한다.- func6 함수 내부에서 total을 5로 설정하고, 그 값을 2배로 곱한다.
- 호출 예시:
total = 10
func6() - 출력 예시:
함수 내 total: 15
전역 total: 10
A6.
total = 10 # 전역 변수
def func6():
total = 5 # 지역 변수
total *= 3
print("함수 내 total: %d" %(total))
func6()
print("전역 total: %d" %(total))