1. 비슷한 뉴스를 선정하는 방법
문자 → 숫자 → 벡터
👉 벡터는 좌표평면 위에 올릴 수 있게 하는 one-hot Encoding 방식을 사용
 단어가 존재하면 1, 단어가 존재하지 않으면 0으로 인식
단어가 존재하면 1, 단어가 존재하지 않으면 0으로 인식
- 벡터 스페이스 : 각각의 글자들이 어떤 인덱스를 포함하는지 정의해 놓은 공간
- Bag of words : 단어별로 인덱스를 부여하여 한 문장(or 문서)의 단어의 개수를 vector로 표현

2. Distance measure
-
Euclidian distance
피타고라스 정리로 두 점 사이의 직선의 거리 측정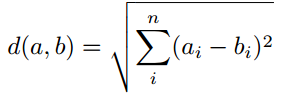
-
Cosine distance
두 점 사이의 각도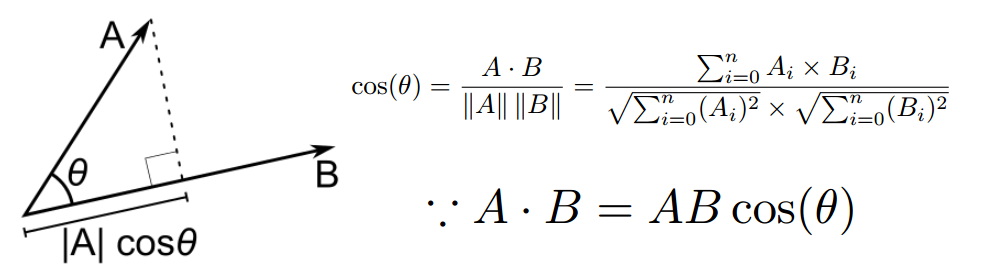
Code Process
1) 파일 불러오기
def get_file_list(dir_name):
return os.listdir(dir_name)
if __name__ == "__main__":
dir_name = "news_data"
file_list = get_file_list(dir_name)
file_list = [os.path.join(dir_name, file_name) for file_name in file_list]news_data 폴더 안에 있는 file_name을 가져온다.
파일을 가져온 다음 실제로 위치되어 있는 file_list안에 넣어준다.
os.path.join : 윈도우나 맥과 같은 OS에 맞춰서 \ or /를 기준으로 경로 설정
2) 파일을 읽기
def get_conetents(file_list):
y_class = []
X_text = []
class_dict = {
1: "0", 2: "0", 3:"0", 4:"0", 5:"1", 6:"1", 7:"1", 8:"1"}
for file_name in file_list:
try:
f = open(file_name, "r", encoding="cp949")
category = int(file_name.split(os.sep)[1].split("_")[0])
y_class.append(class_dict[category])
X_text.append(f.read())
f.close()
except UnicodeDecodeError as e:
print(e)
print(file_name)
return X_text, y_classencoding="cp949" 윈도우즈, encoding="utf-8" 맥 or 리눅스
filename.split(os.sep)[1] : 파일 경로를 \로 나눴을 때의 only 파일명
✔ 여기서 파일명은 1파일명.txt로 설정되어 있기 때문에 _로 나눈 0번째 값, 즉 1~8까지의 값이 category에 저장된다.
y_class : 파일들 중 축구인지 야구인지를 나누는 0or1의 값을 들어오게 한다.
(80개의 file 카테고리에서 0~39는 0, 40~79는 1의 값이 들어온다.)
X-text : 80개 파일 이름이 저장되어 있다.
3) 단어사전(corpus) 만들기 + 단어별 index 만들기
👉 같은 단어들도 있기 때문에 split 한 후 소문자로 바꿔주고
같은 단어들을 모으기 위해 set으로 묶어준다.
👉 dict를 사용해 index를 만들어준다.
def get_cleaned_text(text):
import re
text = re.sub('\W+',
''
, text.lower() )
return text
def get_corpus_dict(text):
text = [sentence.split() for sentence in text]
clenad_words = [get_cleaned_text(word) for words in text for word in words]
from collections import OrderedDict
corpus_dict = OrderedDict()
for i, v in enumerate(set(clenad_words)):
corpus_dict[v] = i
return corpus_dictget_cleaned_text(text) : 의미 없는 문장보호 제거
corpus dict : 문장 안에 있는 모든 단어의 개수가 몇 개인지 나타낸다.
4) 만들어진 인덱스로 문서별로 Bag of words vector 생성
👉 어떠한 단어를 포함하고 있는지 벡터로 표현된다.
def get_count_vector(text, corpus):
text = [sentence.split() for sentence in text]
word_number_list = [[corpus[get_cleaned_text(word)] for word in words]
for words in text]
X_vector = [[0 for _ in range(len(corpus))] for x in range(len(text))]
for i, text in enumerate(word_number_list):
for word_number in text:
X_vector[i][word_number] += 1
return X_vectortext에서 split으로 나눠진 단어들을 뽑아 two-dimensional형태로 만들어준 다음 word를 추출한다.
word_number_list : 각 문서들마다 어떤 단어들이 연속적으로 나열되어 있는지를 보여주는 list
X_vector : 벡터를 만들어주는 방법으로 모두 0으로 만들어준다.
text라는 단어의 list에서 해당 문서에 단어가 있으면 벡터를 1씩 추가한다.
5) 비교하고자 하는 문서 비교하기
👉cosine-similarity를 사용하여 얼마나 유사한지 값으로 표현
import math
def get_cosine_similarity(v1,v2):
"compute cosine similarity of v1 to v2: (v1 dot
v2)/{||v1||*||v2||)"
sumxx, sumxy, sumyy = 0, 0, 0
for i in range(len(v1)):
x = v1[i]; y = v2[i]
sumxx += x*x
sumyy += y*y
sumxy += x*y
return sumxy/math.sqrt(sumxx*sumyy)v1, v2 : 하나의 문서에 대한 벡터 표현 (여기서 총 4302개의 벡터)
for문 : cosine-similarity 수식을 코드화
6) 비교 결과 정리하기
def get_similarity_score(X_vector, source):
source_vector = X_vector[source]
similarity_list = []
for target_vector in X_vector:
similarity_list.append(
get_cosine_similarity(source_vector, target_vector))
return similarity_list
def get_top_n_similarity_news(similarity_score, n):
import operator
x = {i:v for i, v in enumerate(similarity_score)}
sorted_x = sorted(x.items(), key=operator.itemgetter(1))
return list(reversed(sorted_x))[1:n+1]similarity_score : 얼마나 근접한지 숫자로 나타낸다
similarity_news : 가장 근접한 값 10개를 뽑아준다.
7) 성능 측정하기
def get_accuracy(similarity_list, y_class, source_news):
source_class = y_class[source_news]
return sum([source_class == y_class[i[0]] for i in similarity_list]) /
len(similarity_list)
for i in range(80):
source_number = i
similarity_score = get_similarity_score(X_vector, source_number)
similarity_news = get_top_n_similarity_news(similarity_score, 10)
accuracy_score = get_accuracy(similarity_news, y_class, source_number)
result.append(accuracy_score)
print(sum(result) / 80)